泰坦尼克号可视化数据分析报告
上一节已经用用逻辑回归算法预测泰坦尼克号人员存活情况,但是不了解什么样的人容易存活;因此,用数据分析方法继续探究数据背后隐藏的秘密,并用数据可视化方法展示出来。
目录
- 提出问题
- 理解数据
- 采集数据
- 导入数据
- 查看数据
- 数据清洗
- 数据处理
- 幸存率与家庭类别
- 幸存率与头衔
- 幸存率与年龄
- 幸存率与客舱等级
- 幸存率与性别
- 幸存率与登船港口
1. 提出问题
什么样的人更容易存活?
2. 理解数据
2.1 采集数据
点击此链接进入kaggle的titanic项目下载数据集
2.2 导入数据
#导入处理数据包
import numpy as np
import pandas as pd
train=pd.read_csv('E:\\titanic\\train.csv')
print('训练数据集:',train.shape)
训练数据集: (891, 12)
2.3 查看数据集信息
2.3.1 查看数据集前几行数据
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
2.3.2 查看数值型数据的描述性统计信息
train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
Age列有714个数据,说明有缺失值;
Fare票价最低是0元,说明有异常值。
2.3.3 查看数据每一列的数据总和和数据类型
train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 66.2+ KB
发现Age、Cabin和Embarked有缺失值,需要进行数据清洗
3. 数据清洗
3.1 缺失值处理
3.1.1 数值型缺失值处理,简单的方法用平均值代替
train['Age']=train['Age'].fillna(train['Age'].mean())
3.1.2 字符串型缺失值处理
3.1.2.1 Embarked缺失值处理
Embarked只缺失两个值,可用最多的值代替
train['Embarked'].value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
#S最多,选择用S来填充缺失值
train['Embarked']=train['Embarked'].fillna('S')
3.1.2.2 Cabin缺失值处理
因Cabin缺失值较多,选择用U(Uknow)来填充
train['Cabin']=train['Cabin'].fillna('U')
#查看缺失值处理后的结果
train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 891 non-null object
11 Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 66.2+ KB
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | U | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | U | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | U | S |
3.2 异常值处理
#查看Fare等于0的有多少个
train[train['Fare']==0].shape[0]
15
只有15个比较少,选择保留不做处理
4. 数据分析
数据库里有10个指标与乘客信息有关
其中以下三个指标不进行分析:
Ticket(票号):无法分类,没有参考价值;Fare(票价):票价由客舱等级决定,不必重复分析;Cabin(客舱号):缺失值数量太多,没有分析价值。
下面对家庭类别、头衔、年龄、客舱等级、性别、登船港口6个指标分别进行分析
4.1 家庭类别与生存率的关系
4.1.1 家庭分组
#存放家庭信息
familyDf = pd.DataFrame()
'''
家庭人数=同代直系亲属数(Parch)+不同代直系亲属数(SibSp)+乘客自己
(因为乘客自己也是家庭成员的一个,所以这里加1)
'''
familyDf[ 'FamilySize' ] = train[ 'Parch' ] + train[ 'SibSp' ] + 1
'''
家庭类别:
小家庭Family_Single:家庭人数=1
中等家庭Family_Small: 2<=家庭人数<=4
大家庭Family_Large: 家庭人数>=5
'''
# 定义家庭分组用的函数
def familyGroup(FS):
if FS==1:
return 'Family_Single'
elif 2<=FS<=4:
return 'Family_Small'
else:
return 'Family_Large'
#map函数主要作用是使用自定义函数
familyDf['FamilyCategory'] = familyDf['FamilySize'].map(familyGroup)
familyDf.head()
| FamilySize | FamilyCategory | |
|---|---|---|
| 0 | 2 | Family_Small |
| 1 | 2 | Family_Small |
| 2 | 1 | Family_Single |
| 3 | 2 | Family_Small |
| 4 | 1 | Family_Single |
将得到的familyDf分组添加到train数据集中
train = pd.concat([train,familyDf],axis=1)
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | FamilyCategory | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | U | S | 2 | Family_Small |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 | Family_Small |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | U | S | 1 | Family_Single |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 2 | Family_Small |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | U | S | 1 | Family_Single |
4.1.2 汇总家庭类别与是否幸存的人数
DataFrame的pivot_table方法可用于汇总统计,类似于Excel的数据透视表,参数如下:
- 第1个参数:需要汇总统计的数据源
- index : 透视表的行索引,必要参数,如果我们想要设置多层次索引,使用列表[ ]
- values : 对目标数据进行筛选,默认是全部数据,我们可通过values参数设置我们想要展示的数据列
- columns :透视表的列索引,非必要参数,同index使用方式一样
- aggfunc :对数据聚合时进行的函数操作,默认是求平均值,也可以sum、count等
- margins :额外列,在最边上,默认是对行列求和
- fill_value : 对于空值进行填充
- dropna : 默认开启去重
# 汇总统计家庭类别与是否幸存的人数
FamilyCgDf = pd.pivot_table(train,
index='FamilyCategory',
columns='Survived',
values='PassengerId',
aggfunc='count')
FamilyCgDf
| Survived | 0 | 1 |
|---|---|---|
| FamilyCategory | ||
| Family_Large | 52 | 10 |
| Family_Single | 374 | 163 |
| Family_Small | 123 | 169 |
# 汇总统计家庭类别与是否幸存的人数
FamilyCgDf_1 = pd.pivot_table(train,
index='FamilyCategory',
columns='Survived',
values='FamilySize',
aggfunc='count')
FamilyCgDf_1
| Survived | 0 | 1 |
|---|---|---|
| FamilyCategory | ||
| Family_Large | 52 | 10 |
| Family_Single | 374 | 163 |
| Family_Small | 123 | 169 |
4.1.3 汇总统计家庭类别的存活率
DataFrame的div函数用于数据框除以其他元素后的值,主要有2个参数:
- other:标量 (scalar),序列(sequence),Series或DataFrame,任何单个或多个元素数据结构或类似列表的对象。
- axis:0 或‘index’, 1 或‘columns’,是否通过索引 (0 or‘index’) 或列(1 或‘columns’)进行比较。对于Series输入,轴匹配Series索引。
# div函数用法1:除以同一个值
FamilyCgDf.div(10)
| Survived | 0 | 1 |
|---|---|---|
| FamilyCategory | ||
| Family_Large | 5.2 | 1.0 |
| Family_Single | 37.4 | 16.3 |
| Family_Small | 12.3 | 16.9 |
# div函数用法2:根据不同索引,除以不同值
otherS = pd.Series([10,100,1000],index=['Family_Large','Family_Single','Family_Small'])
FamilyCgDf.div(otherS,axis='index')
| Survived | 0 | 1 |
|---|---|---|
| FamilyCategory | ||
| Family_Large | 5.200 | 1.000 |
| Family_Single | 3.740 | 1.630 |
| Family_Small | 0.123 | 0.169 |
以上代码表示FamilyCgDf数据框的3行索引的值分别除以10、100和1000。 同理,可设置索引的值分别除以所在行的求和值:
# 汇总统计家庭类别与是否幸存的比例
FamilyCgDf2 = FamilyCgDf.div(FamilyCgDf.sum(axis=1),axis=0)
FamilyCgDf2
| Survived | 0 | 1 |
|---|---|---|
| FamilyCategory | ||
| Family_Large | 0.838710 | 0.161290 |
| Family_Single | 0.696462 | 0.303538 |
| Family_Small | 0.421233 | 0.578767 |
上面数据框的两列分别表示各个家庭类别的死亡率和幸存率,这里只获取幸存率:
# 获取家庭类别的幸存率
FamilyCgDf_rate = FamilyCgDf2.iloc[:,1]
FamilyCgDf_rate
FamilyCategory
Family_Large 0.161290
Family_Single 0.303538
Family_Small 0.578767
Name: 1, dtype: float64
4.1.4 幸存率与家庭类别的可视化分析
可视化需要用到matplotlib包,先导入相关包:
%matplotlib inline
# 导入可视化包
import matplotlib.pyplot as plt
使用Python建立可视化图表的步骤主要有:
- 创建画板
- 创建画纸,图表都建立在画纸上
- 选择画纸,绘制图表
- 设置图表参数
- 显示图表
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
'''
subplot()方法里面传入的三个数字
前两个数字代表要生成几行几列的子图矩阵,第三个数字代表选中的子图位置
subplot(1,2,1)生成一个1行2列的子图矩阵,当前是第一个子图
'''
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
FamilyCgDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向显示
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Family')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Family and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper right')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
FamilyCgDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向显示
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Family')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Family and Survived Rate')
# 显示图表
plt.show()
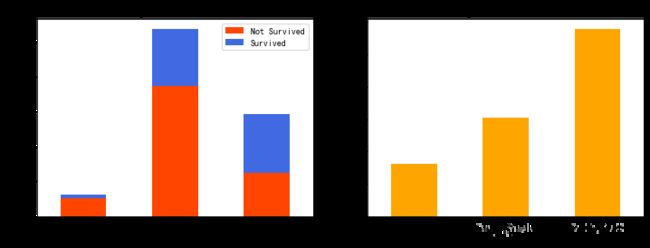
在人数上,单身人士最多,其次是小家庭,最少的是大家庭;
在幸存率方面,人数最少的大家庭幸存率最低,小家庭的幸存率最高,其次是单身人士。
4.2 头衔与生存率的关系
4.2.1 头衔分组
首先定义一个函数,用于从乘客姓名中获取头衔:
'''
定义函数:从姓名中获取头衔
'''
def getTitle(name):
str1=name.split(',')[1] #Mr. Owen Harris
str2=str1.split('.')[0] #Mr
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
str3 = str2.strip()
return str3
利用该函数获取每位乘客的头衔,并汇总统计所有头衔的数量:
# 存放提取后的特征
titleDf = pd.DataFrame()
# map函数:对Series每个数据应用自定义的函数计算
titleDf['Title'] = train['Name'].map(getTitle)
# 所有头衔及其数量
titleDf['Title'].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Mlle 2
Col 2
Mme 1
Jonkheer 1
Sir 1
Lady 1
Capt 1
Ms 1
the Countess 1
Don 1
Name: Title, dtype: int64
由于头衔类别过多,且有些头衔数量很少,这里将头衔重新归为6大类,定义如下:
- Officer:政府官员
- Royalty:王室(皇室)
- Mr:已婚男士
- Mrs:已婚妇女
- Miss:年轻未婚女子
- Master:有技能的人/教师
然后,建立姓名中头衔与6大类的映射关系,并用map函数完成转换:
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
# map函数:对Series每个数据应用自定义的函数计算
titleDf['Title'] = titleDf['Title'].map(title_mapDict)
将刚得到的头衔分组添加到数据集train中:
train = pd.concat([train,titleDf],axis=1)
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | FamilyCategory | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | U | S | 2 | Family_Small | Mr |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 | Family_Small | Mrs |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | U | S | 1 | Family_Single | Miss |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 2 | Family_Small | Mrs |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | U | S | 1 | Family_Single | Mr |
4.2.2 汇总统计不同头衔与是否幸存的人数
TitleDf = pd.pivot_table(train,
index='Title',
columns='Survived',
values='PassengerId',
aggfunc='count')
TitleDf
| Survived | 0 | 1 |
|---|---|---|
| Title | ||
| Master | 17 | 23 |
| Miss | 55 | 129 |
| Mr | 436 | 81 |
| Mrs | 26 | 101 |
| Officer | 13 | 5 |
| Royalty | 2 | 3 |
4.2.3 汇总统计不同头衔的幸存率
# 汇总统计不同头衔与是否幸存的比例
TitleDf2 = TitleDf.div(TitleDf.sum(axis=1),axis=0)
TitleDf2
| Survived | 0 | 1 |
|---|---|---|
| Title | ||
| Master | 0.425000 | 0.575000 |
| Miss | 0.298913 | 0.701087 |
| Mr | 0.843327 | 0.156673 |
| Mrs | 0.204724 | 0.795276 |
| Officer | 0.722222 | 0.277778 |
| Royalty | 0.400000 | 0.600000 |
# 获取不同头衔的幸存率
TitleDf_rate = TitleDf2.iloc[:,1]
TitleDf_rate
Title
Master 0.575000
Miss 0.701087
Mr 0.156673
Mrs 0.795276
Officer 0.277778
Royalty 0.600000
Name: 1, dtype: float64
4.2.4 幸存率与头衔的可视化分析
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
TitleDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Title')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Title and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper right')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
TitleDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Title')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Title and Survived Rate')
# 显示图表
plt.show()
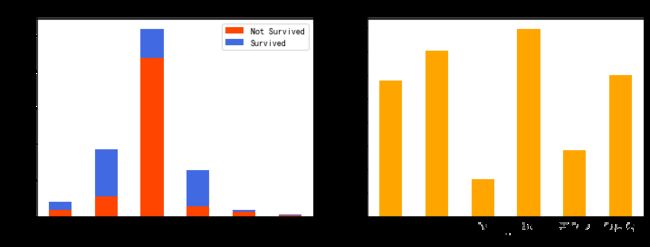
头衔分类中人数最多的是已婚男士,未婚女士和已婚女士次之,其他头衔的只占少数;
幸存率方面,已婚男士最低,政府官员也较低,已婚女士和未婚女士的幸存率最高。
4.3 年龄与幸存率的关系
4.3.1 年龄分组
'''
年龄分组:
儿童(Children):0-13
青年(Youth):14-30
中年(Middle-aged):30-60
老年(The old):60以上
'''
# 定义年龄分组函数
def ageCut(a):
if a<=13:
return 'Children'
elif 13<a<=30:
return 'Youth'
elif 30<a<=60:
return 'Middle-aged'
else:
return 'The old'
#if 条件为真的时候返回if前面内容,否则返回后面的内容
train['AgeCategory'] =train['Age'].map(ageCut)
train[['AgeCategory','Age' ]].head()
| AgeCategory | Age | |
|---|---|---|
| 0 | Youth | 22.0 |
| 1 | Middle-aged | 38.0 |
| 2 | Youth | 26.0 |
| 3 | Middle-aged | 35.0 |
| 4 | Middle-aged | 35.0 |
4.3.2 汇总统计不同年龄段与是否幸存的人数
AgeDf = pd.pivot_table(train,
index='AgeCategory',
columns='Survived',
values='PassengerId',
aggfunc='count',
fill_value=0)
AgeDf
| Survived | 0 | 1 |
|---|---|---|
| AgeCategory | ||
| Children | 29 | 42 |
| Middle-aged | 164 | 119 |
| The old | 17 | 5 |
| Youth | 339 | 176 |
4.3.3 汇总统计不同年龄段的幸存率
# 汇总统计不同年龄与是否幸存的比例
AgeDf2 = AgeDf.div(AgeDf.sum(axis=1),axis=0)
AgeDf2
| Survived | 0 | 1 |
|---|---|---|
| AgeCategory | ||
| Children | 0.408451 | 0.591549 |
| Middle-aged | 0.579505 | 0.420495 |
| The old | 0.772727 | 0.227273 |
| Youth | 0.658252 | 0.341748 |
# 获取不同年龄段的幸存率
AgeDf_rate = AgeDf2.iloc[:,1]
AgeDf_rate
AgeCategory
Children 0.591549
Middle-aged 0.420495
The old 0.227273
Youth 0.341748
Name: 1, dtype: float64
4.3.4 幸存率与年龄的可视化分析
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
AgeDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Age')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Age and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper left')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
AgeDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Age')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Age and Survived Rate')
# 显示图表
plt.show()
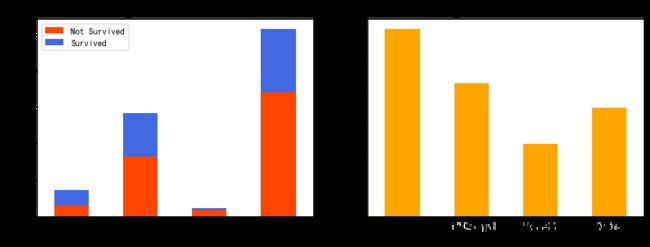
青年人数最多,中年人次之,儿童人数较少,老年人最少;
儿童的幸存率最高,中年人次之,老年人的最低。
4.4 客舱等级与幸存率的关系
4.4.1 汇总统计不同客舱等级与是否幸存的人数
PclassDf = pd.pivot_table(train,
index='Pclass',
columns='Survived',
values='PassengerId',
aggfunc='count')
PclassDf
| Survived | 0 | 1 |
|---|---|---|
| Pclass | ||
| 1 | 80 | 136 |
| 2 | 97 | 87 |
| 3 | 372 | 119 |
4.4.2 汇总统计不同客舱等级的幸存率
# 汇总统计不同客舱等级与是否幸存的比例
PclassDf2 = PclassDf.div(PclassDf.sum(axis=1),axis=0)
PclassDf2
| Survived | 0 | 1 |
|---|---|---|
| Pclass | ||
| 1 | 0.370370 | 0.629630 |
| 2 | 0.527174 | 0.472826 |
| 3 | 0.757637 | 0.242363 |
# 获取不同客舱等级的幸存率
PclassDf_rate = PclassDf2.iloc[:,1]
PclassDf_rate
Pclass
1 0.629630
2 0.472826
3 0.242363
Name: 1, dtype: float64
4.4.3 幸存率与客舱等级的可视化分析
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
PclassDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Pclass')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Pclass and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper left')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
PclassDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Pclass')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Pclass and Survived Rate')
# 显示图表
plt.show()
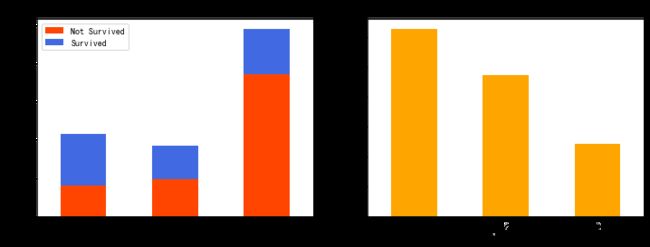
三等舱的人数最多,一等舱和二等舱人数相差不多;
一等舱幸存率最高,二等舱次之,三等舱最低。
4.5 性别与幸存率的关系
4.5.1 汇总统计不同性别与是否幸存的人数
SexDf = pd.pivot_table(train,
index='Sex',
columns='Survived',
values='PassengerId',
aggfunc='count')
SexDf
| Survived | 0 | 1 |
|---|---|---|
| Sex | ||
| female | 81 | 233 |
| male | 468 | 109 |
4.5.2 汇总统计不同性别的幸存率
# 汇总统计不同性别与是否幸存的比例
SexDf2 = SexDf.div(SexDf.sum(axis=1),axis=0)
SexDf2
| Survived | 0 | 1 |
|---|---|---|
| Sex | ||
| female | 0.257962 | 0.742038 |
| male | 0.811092 | 0.188908 |
# 获取不同性别的幸存率
SexDf_rate = SexDf2.iloc[:,1]
SexDf_rate
Sex
female 0.742038
male 0.188908
Name: 1, dtype: float64
4.5.3 幸存率与性别的可视化分析
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
SexDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Sex')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Sex and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper left')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
SexDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Sex')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Sex and Survived Rate')
# 显示图表
plt.show()

乘客性别以男性为主,大约是女性的两倍;
男性的幸存率比女性低很多,不及女性的三分之一。
4.6 登船港口与幸存率的关系
4.6.1 汇总统计不同登船港口与是否幸存的人数
EmbarkedDf = pd.pivot_table(train,
index='Embarked',
columns='Survived',
values='PassengerId',
aggfunc='count')
EmbarkedDf
| Survived | 0 | 1 |
|---|---|---|
| Embarked | ||
| C | 75 | 93 |
| Q | 47 | 30 |
| S | 427 | 219 |
4.6.2 汇总统计不同登船港口的幸存率
# 汇总统计不同登船港口与是否幸存的比例
EmbarkedDf2 = EmbarkedDf.div(EmbarkedDf.sum(axis=1),axis=0)
EmbarkedDf2
| Survived | 0 | 1 |
|---|---|---|
| Embarked | ||
| C | 0.446429 | 0.553571 |
| Q | 0.610390 | 0.389610 |
| S | 0.660991 | 0.339009 |
# 获取不同登船港口的幸存率
EmbarkedDf_rate = EmbarkedDf2.iloc[:,1]
EmbarkedDf_rate
Embarked
C 0.553571
Q 0.389610
S 0.339009
Name: 1, dtype: float64
4.6.4 幸存率与登船港口的可视化分析
# 创建画板并设置大小
fig = plt.figure(1)
plt.figure(figsize=(12,4))
# 创建画纸(子图)
#创建画纸,并选择画纸1
ax1 = plt.subplot(1,2,1)
# 在画纸1绘制堆积柱状图
EmbarkedDf.plot(ax=ax1,#选择画纸1
kind='bar',#选择图表类型
stacked=True,#是否堆积
color=['orangered','royalblue'] #设置图表颜色
)
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Embarked')
# y坐标轴文本
plt.ylabel('Num')
# 图表标题
plt.title('Embarked and Survived Num')
# 设置图例
plt.legend(labels=['Not Survived','Survived'],loc='upper left')
# 选择画纸2
ax2 = plt.subplot(1,2,2)
# 在画纸2绘制柱状图
EmbarkedDf_rate.plot(ax=ax2,kind='bar',color='orange')
# x坐标轴横向
plt.xticks(rotation=360)
# x坐标轴文本
plt.xlabel('Embarked')
# y坐标轴文本
plt.ylabel('Survived Rate')
# 图表标题
plt.title('Embarked and Survived Rate')
# 显示图表
plt.show()

乘客绝大部分都是从Southampton登船,同时Southampton登船的乘客幸存率也最低;幸存率最高的是从Cherbourg登船的乘客。
5. 总结
5.1 家庭类别:
小家庭的幸存率最高,人数最少的大家庭反而幸存率最低。
5.2 头衔:
已婚男士人数最多,但他们的幸存率最低,未婚女士和已婚女士人数虽然人数也多,幸存率却最高。
5.3 年龄:
乘客以青年人为主,但儿童的幸存率最高,说明当时逃生时儿童优先;老年人的人数少,幸存率也低,可能是由于老人行动不便,来不及逃生。
5.4 客舱等级:
三等舱的人数最多,但幸存率从一等舱到三等舱依次下降,票价越高,幸存率越高,说明上层阶级有更大的逃生机会。
5.5 性别:
乘客性别以男性为主,大约是女性的两倍;男性的幸存率比女性低很多,不及女性的三分之一,反映当时逃生时女士优先的原则。
5.6 登船港口:
从三个港口上船的乘客中,Southampton港口的最多,可能是泰坦尼克号出发港口的原因;同时Southampton港口登船的乘客幸存率最低,可能是因为从该港口登船的乘客数量巨大,且身份来自不同阶层;而从Cherbourg登船的乘客幸存率最高。
综上,如果当时有一个小女孩,在父母陪伴下从Cherbourg港口登船,且乘坐的是一等舱,那么她从那次海难中幸存的概率最大;反之,带着一大家子亲戚从Southampton港口登船,乘坐在三等舱的男性老人,能够幸存的概率最小。