联邦学习笔记(三): 使用高阶keras API设计联邦学习神经网络模型
使用高阶keras API设计联邦学习神经网络模型
- 写在前面
- 数据预处理
- 创建客户端数据
- TFF神经网络模型设计
-
- 实现神经网络tf构造函数
- TFF封装TF神经网络代码函数
- 实现联邦平均算法
-
- 联邦平均算法初始化
- 训练与测试
- 测试结果
-
- 训练准确率
- 训练loss值
- 测试准确率
- 测试loss值
- 总结
写在前面
TFF框架是使用的时函数式编程,不要使用类对象去实现某些功能。在构建神经网络模型时与在TF中有很大不同。具体在下面TFF神经网络模型设计会详细阐述。
实验内容: 使用TFF框架实现对mnist数据集的联邦学习分类任务,并检测联邦学习效果。联邦学习中设定的客户端数量为固定的10个。
数据预处理
由于处理的是图片信息,所以都是一些常规的神经网络图片预处理流程。
代码:
#图像数据集处理
def preprocess(dataset):
#python函数嵌套,将dataset中的元素展平并返回
def batch_format_fn(element):
return collections.OrderedDict(x=tf.reshape(element['pixels'],[-1,784]) , y=tf.reshape(element['label'] , [-1,1]))
#将展平后的数据随机打乱,并组合成batch_size
return dataset.repeat(NUM_EPOCHS).shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE).map(batch_format_fn).prefetch(PREFETCH_BUFFER)
创建客户端数据
#生成10个固定的客户端
sample_clients = emnist_train.client_ids[0:NUM_CLIENTS]
#为这10个客户端生成训练数据集
federated_train_datasets =[preprocess(emnist_train.create_tf_dataset_for_client(x)) for x in sample_clients]
federated_test_datasets =[preprocess(emnist_test.create_tf_dataset_for_client(x)) for x in sample_clients]
#获取联邦学习神经网络输入数据的规格
input_spec = federated_train_datasets[0].element_spec
TFF神经网络模型设计
实现神经网络tf构造函数
TFF代码与TF代码很大一点不同在于,TFF代码不能直接调用神经网络模型对象进行实验。因为神经网络模型随着聚合和广播在不断变化。所以构造TFF神经网络模型第一步都是使用TF实现一个神经网络构造函数。
代码:
#神经网络模型
def create_keras_model( ):
return tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(784,)),
tf.keras.layers.Dense(10 , kernel_initializer='zeros'),
tf.keras.layers.Softmax(),
])
TFF封装TF神经网络代码函数
由于在TFF框架中,不能直接使用TF代码和python代码。这一点及其关键。所以TFF神经网络设计的第二步就是对TF神经网络进行封装。
代码:
def model_fn():
model = create_keras_model()
return tff.learning.from_keras_model(
keras_model =model,
input_spec=input_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
注意:
- 这里封装同样要写成一个函数的形式。
- 在
return之前要新创建一个模型,这一点也很关键。愿意在上一小节的红字中有解释。
实现联邦平均算法
fed_aver = tff.learning.build_federated_averaging_process(
model_fn,
#客户端优化器,只针对客户端本地模型进行更新优化
client_optimizer_fn=lambda : tf.keras.optimizers.SGD(learning_rate=client_lr),
#服务器端优化器,只针对服务器端全局模型进行更新优化
server_optimizer_fn=lambda : tf.keras.optimizers.SGD(learning_rate=server_lr)
)
注意: 这里tff.learning.build_federated_averaging_process传入的第一个参数是一个函数地址,而不是一个函数(不带括号)。
联邦平均算法初始化
state = fed_aver.initialize()
训练与测试
logdir_for_compression = "/tmp/logs/scalars/custom_model/"
summary_writer = tf.summary.create_file_writer(
logdir_for_compression)
with summary_writer.as_default():
#基础训练测试
for i in range(NUM_ROUND):
state , metrics = fed_aver.next(state , federated_train_datasets)
test_state , test_metrics = fed_aver.next(state , federated_test_datasets)
print('第', i , '轮训练模型loss:', metrics['train']['loss'] , '准确率:', metrics['train']['sparse_categorical_accuracy'] , '\n')
tf.summary.scalar('train_loss',metrics['train']['loss'], step=i)
tf.summary.scalar('train_acc',metrics['train']['sparse_categorical_accuracy'], step=i)
print('第', i , '轮测试模型loss:', test_metrics['train']['loss'] , '准确率:', test_metrics['train']['sparse_categorical_accuracy'] , '\n')
tf.summary.scalar('test_loss',test_metrics['train']['loss'], step=i)
tf.summary.scalar('test_acc',test_metrics['train']['sparse_categorical_accuracy'], step=i)
summary_writer.flush()
测试结果
训练准确率
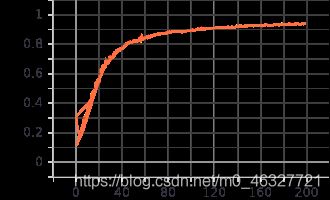
训练loss值
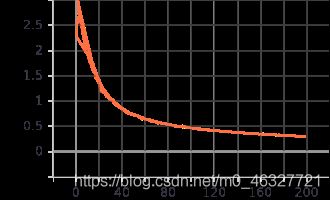
测试准确率
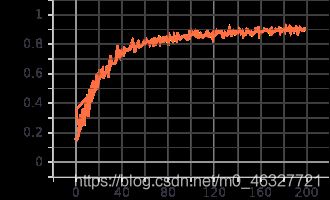
测试loss值
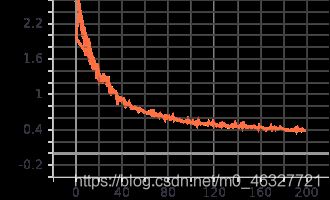
总结
把TFF当成一种全新的语言进行学习。其中的很多API还不知道怎么用,应当加强学习。