【论文】ReDet:A Rotation-equivariant Detector for Aerial Object Detection
源码地址:GitHub - csuhan/ReDet: Official code of the paper "ReDet: A Rotation-equivariant Detector fyor Aerial Object Detection" (CVPR 2021)
摘要
1. 针对的问题
- 航天影像的目标分布方向是任意的,需要更多的参数解码方向信息
- 普通的CNN不能明确地对方向的变化进行建模,需要大量的旋转增强数据来训练检测器。
2. 本文研究内容
- 提出了一个ReDet检测器,明确的对旋转等变性和旋转不变性进行解码
- 将旋转等变网络和检测器相结合,用于提取旋转等变特征和后续的方向预测
- 设计了具有旋转不变性的ROI(RiROI),可以根据RoI的方向自适应地从旋转等变特征中提取旋转不变性的特征
一、引言
1. 研究思路
本研究提出了一个旋转等变检测器,用于从旋转等变的特征中提取旋转不变的特征。
旋转等变性:变化特征图和变化原图效果一致
旋转不变性:影像或特征图旋转之后提取的信息结果是不变的
2. 主要方法
(1)旋转等变特征提取:将旋转等变网络引入骨干网络中,生成旋转等变的特征,可以直接准确地预测方向,减少方向变量建模的复杂性;
(2)旋转不变特征提取:因为RRoI warping不能从旋转等变特征中提取旋转不变特征,因此本研究采用旋转不变的RoI Align (RiRoI Align)。它可以根据空间维度上的RRoI边界框对区域特征进行wrap操作,通过循环切换方向通道和特征插值对方向维度上特征进行对齐。
3. 主要贡献
(1)为高质量的航空目标检测设计了一个旋转等变检测器,能够同时对旋转等变性和旋转不变性进行解码;
(2)设计了一个用于从旋转等变特征中提取旋转不变特征的 RiRoI Align,可以同时在空间维度和方向维度上生成旋转不变的特征;
(3)本研究的方法精度高超过了现有方法,并实现了模型大小和精度的更优平衡。
二、相关工作
1. 旋转目标检测
(1)采用大量具有不同方向、尺寸和长宽比的旋转anchors,提高了计算复杂性;
(2)部分方法致力于改进目标表示或特征表示。
2. 旋转等变网络
为了在更多方向上实现旋转等方差,有些方法通过插值重采样滤波器,而其他方法使用谐波作为滤波器,在连续域产生等等变特征,不过这些方法大多是在分类任务上取得了显著效果。
3. 旋转不变性的目标检测
(1)CNN在旋转不变性建模上表现很差,因此需要更多参数来对旋转信息进行解码;
(2)目标检测需要实例级别的旋转不变特征,因此部分方法将RoI warping拓展到了 RRoI warping,但仍然难以提取旋转不变性的特征。
三、预备知识
(1)等变是一种性质,即对输入进行变换会以可预测的方式产生特征上的变换
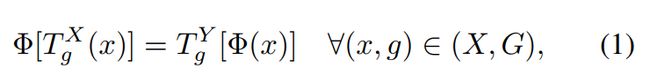
对输入进行变换后再函数操作的结果与先对输入进行函数操作再变换的结果一致
(2)CNN具有平移等变性
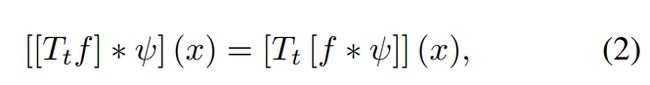
先对特征影像进行变换再卷积操作和对特征影像先卷积再变换操作的结果一致
(3)旋转等变性
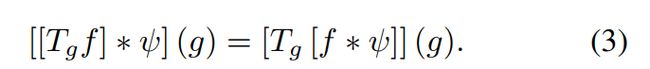
先对特征影像进行旋转再卷积操作和对特征影像先卷积再旋转操作的结果一致
1. 旋转等变网络
(1)旋转等变网络是一堆具有更高权值共享程度(如平移和旋转)的旋转等变层组成。
(2)如果对输入 进行
进行![]() 旋转变换之后再输入网络
旋转变换之后再输入网络 ,那么旋转变换
,那么旋转变换![]() 可以被整个网络所保留
可以被整个网络所保留
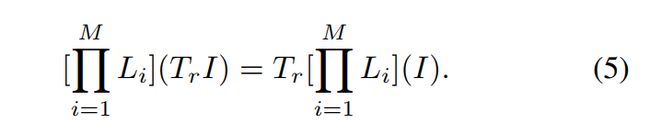
2. 旋转不变特征
(1)旋转不变性:如果对输入进行任何的旋转变换,都不会引起输出的变化,就可以说该输出特征具有旋转不变性。
(2)旋转不变特征可以分为三个层级:影像级、实例级和像元级。这里主要关注实例级。
(3)如果![]() 和
和 ![]() 分别表示输入影像I和特征图
分别表示输入影像I和特征图 的RoI,即
的RoI,即![]() ,
,![]() 为旋转不变的水平框,
为旋转不变的水平框,![]() 是与方向θ有关的倾斜框,那么对于影像的RoI,旋转等变性可以被表示为:
是与方向θ有关的倾斜框,那么对于影像的RoI,旋转等变性可以被表示为:
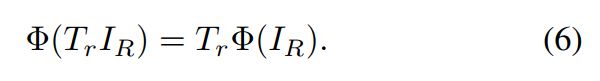
(4)如果将HRoI ![]() 认作是影像I中RRoI
认作是影像I中RRoI ![]() 的旋转不变表示,那么
的旋转不变表示,那么![]() 可以被认为是对应特征空间中
可以被认为是对应特征空间中 ![]() 的旋转不变表示。
的旋转不变表示。
(5)旋转变化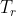 通常是方向
通常是方向 的函数:
的函数:![]() ,我们可以采用RRPN 或者 R-CNN来学习RRoI的方向变量θ以及变换
,我们可以采用RRPN 或者 R-CNN来学习RRoI的方向变量θ以及变换![]() 。最终,旋转不变特征
。最终,旋转不变特征 ![]() 可以通过逆变换
可以通过逆变换![]() 得到:
得到:
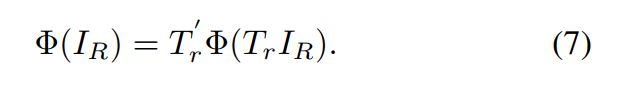
四、旋转等变检测器
首先,采用旋转等变网络作为骨干来提取旋转等变的特征
其次,直接在旋转等变的特征图上使用RRoI Align不能获得旋转不变的特征,因此本研究采用 RiRoI Align从旋转等变特征图中对每个Roi提取旋转不变的特征
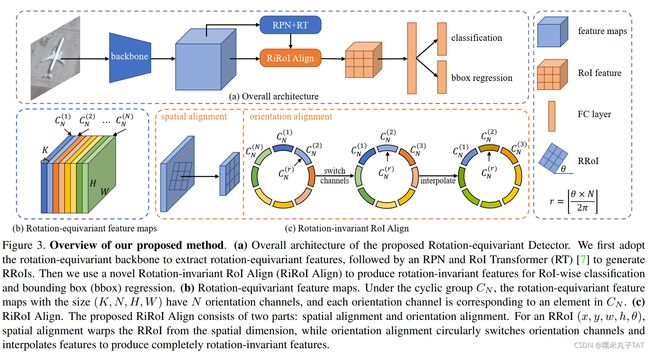
1. 旋转等变的Backbone
(1)以带有FPN的ResNet为基线,实现了一个旋转等变骨干,即具有ReFPN的旋转等变ResNet (ReResNet)。
- 在e2cnn基础上,用旋转等变网络重新实现了主干的所有层,包括卷积、池化、归一化、非线性等。(考虑到计算开销,ReResNet和ReFPN仅与离散群等价)
- 大小为
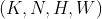 的旋转等变特征图有
的旋转等变特征图有 个方向通道,每个方向通道的特征图对应一个
个方向通道,每个方向通道的特征图对应一个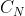 中的元素
中的元素
(2)旋转等变骨Backbone的优势
- 更高等级的权重共享:不同方向的特征图共享带有不同旋转变换的相同滤波器
- 丰富的方向信息:对于固定方向的输入影像,旋转等变骨干网络可以产生多方向的特征图
- 更小的模型量:保持与基准模型相同计算量的同时,由于有旋转的权重共享,我们的旋转等变骨干网络大大减少了模型量,只有1/N的参数
2. 旋转不变的RoI Align(RiRoI Align)
(1)空间Alignment:空间对齐将RRoI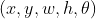 从特征图f中wrap出来,产生空间维度上的旋转不变性区域特征
从特征图f中wrap出来,产生空间维度上的旋转不变性区域特征![]() ,这与RRoI对齐一致。
,这与RRoI对齐一致。
(2)方向Alignmen:为了确保不同方向的RRoIs能够产生旋转不变的特征,本文在方向维度上进行方向对齐。因为旋转等变只在离散的空间上实现了,所以当![]() 时,需要对特征进行插值。
时,需要对特征进行插值。
(3)与RRoI Align+MaxPool相比:方向池化在分类任务中应用更多。对于特征图的每个位置,方向池化只保留具有最强响应的方向信息,其他方向的特征均被舍弃。但是,在目标识别中,无论方向响应是强是弱,都是不可忽视的。因此,在本研究的 RiRoI Align中,所有方向的特征都被保留并align。
五、实验分析
1. 数据集
- 15类的DOTA-v1.0, 16类的DOTA-v1.5,1024×1024,步长为824,随机水平翻转
- HRSC2016舰船检测数据集,重采样到(800,512),随机水平翻转
2. 实验配置
(1) ImageNet预训练
(2) Fine-Tune
- RPN阶段每个位置12anchors,512个RoIs按1:3的正负比进行训练;
- 在测试时,NMS前有10000个RoIs(每个金字塔层有2000个),NMS保留2000个RoIs;
- 优化函数为SGD。
3. 消融实验(在DOTA-1.5上进行测试)
(1)旋转等变骨干网络:比较了不同的Backbone结构以及不同的检测网络。
- 与ResNet50相比,因为减少了参数两,ReResNet50的分类精度有所降低,但其检测的mAP更高。
- 具有ReResNet50+ReFPN的Faster R-CNN OBB 和RetinaNet OBB都比其相同配置的网络更优秀。
(2)RiRoI Align的有效性:与RRoI Align相比效果有了显著提高
- RRoI Align+MaxPool会导致mAP的明显下降,表明在旋转框检测中,方向池化是不理想的
- RiRoI Align能够获得更高的mAP
(3)与旋转增广相比:数据增广之后需要的模型收敛时间更长
- 尽管我们的方法在1x sche下不没有超过旋转增广后的基础模型,但保留了同等参数量的ReDet∗的mAP提高了2.59%,而只增加了18%的训练时间。此外,带有旋转增广的2x 基准模形比我们的ReDet∗高0.68,但它需要两倍的训练时间。
(4)其他数据集上的表现(模型泛化能力测试)
- 将ReDet 应用在 DOTA-v1.0 和 HRSC2016上,结果都比基准模型更优。
4. 与现有模型相比
(1)DOTA-v1.0结果:超过所有单尺度模型和大多数多尺度模型。
(2)DOTA-v1.5结果:优于RetinaNetOBB, Faster R-CNN OBB, Mask R-CNN 以及 HTC 等模型,尤其是在小目标和大尺度目标上,表现更好
(3)HRSC-2016结果:优秀!