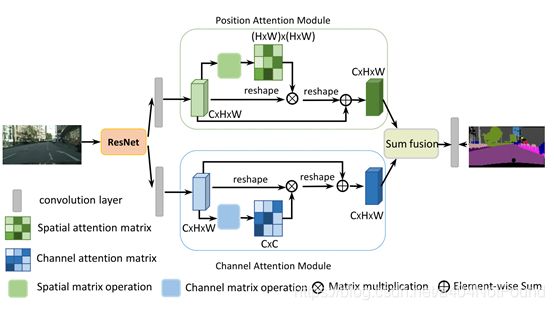
DANet核心内容翻译
双注意力机制:
位置注意力模块:使用自监督机制捕获特征映射任意两个位置之间的空间依赖。对于特定位置的特征,通过加权求和聚合所有位置的特征来更新,权重由相应两个位置之间的特征相似性决定。任意两个具有相似特征的位置可以互相提升,不管距离多远。
通道注意力模块。:捕获任意两个通道间的依赖,对所有通道映射加权求和来更新每个通道映射
ResNet把特征图缩小到原来的1/8,之后进行如下处理:
- 生成空间注意力矩阵,其为特征的任意两个像素之间的空间关系建模
- 注意力矩阵和原始特征相乘。
- 将如上矩阵相乘的结果矩阵与原始特征上的元素相加,来获取反映长范围上下文的最终表征
对于通道注意力模块,与空间注意力相似,只是第一步在通道维计算通道注意力矩阵
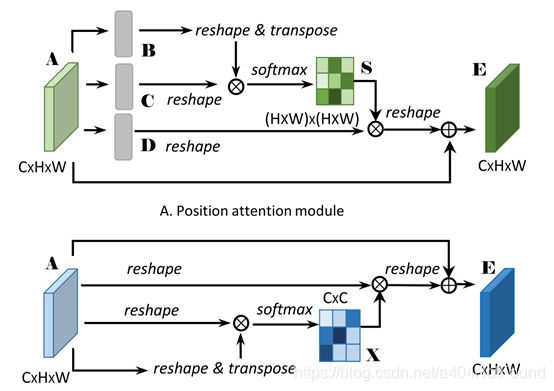
3.2位置注意力模块:
给定局部特征A(CxHxW),我们首先将其放入一个卷积层来生成两个新特征映射B和C(B和C的形状为CxHxW),接着把他们变形为CxN,其中N=HxW,它是像素数量。然后我们在C的转置和B之间使用矩阵相乘,再应用softmax层来计算空间注意力映射S(NxN)
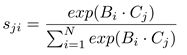
其中sji衡量了第i个位置对第j个位置的影响。两个位置的特征表示越相似,它们之间的相关性就越强。
同时,我们将特征A放入卷积层来生成新特征映射D(CxHxW)并变形为CxN。接着在D和转置后的S使用矩阵相乘,并将结果变形为CxHxW。最终,我们通过放缩参数α乘它,并与A元素级相加来获取最终输出E(CxHxW)如下:
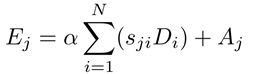
其中α以0初始化并逐渐学习来分配更多权重。可以由上式推导出每个位置的结果特征E为贯穿所有位置的特征和原始特征的加权求和。因此,它具有全局上下文视野并根据空间注意力矩阵选择性地聚合上下文。相似语义特征实现了相互增益,增强了类间紧凑型和语义一致性。
3.3通道注意力模块
每个高层次特征的通道映射可以视作特定类别的响应,不同语义响应相互关联。通过探索通道映射间的相互依赖,我们可以强调相互依赖的特征映射并提升特定语义的特征表示。因此,我们建立了一个通道注意力模块来显式地对通道间的相互依赖关系建模。
通道注意力模块的结构如图所示。与位置注意力模块不同的是,我们直接从原始特征A(CxHxW)计算通道注意力映射X(CxC)。特别地,我们将A变形成(CxN),接着将A与A的转置使用矩阵乘法。最终我们使用softmax曾来获取通道注意力映射X(CxC):
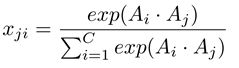
其中xji衡量了第i个通道对第j个通道的影响。而且,我们对X的转置和A使用矩阵乘法并将结果变形成CxHxW。然后我们使用放缩参数β乘结果并与A逐元素相加获得最终输出E(CxHxW)
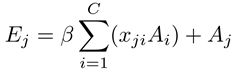
其中β从0逐渐学得权重。上式表明每个通道的最终特征是所有通道特征和原始特征的加权求和,它对特征映射间大范围语义依赖建模。它帮助提升特征可辨性。
代码网址https://github.com/junfu1115/DANet
encoding/models/danet.py
class DANet(BaseNet):
def __init__(self, nclass, backbone, aux=False, se_loss=False, norm_layer=nn.BatchNorm2d, **kwargs):
super(DANet, self).__init__(nclass, backbone, aux, se_loss, norm_layer=norm_layer, **kwargs)
self.head = DANetHead(2048, nclass, norm_layer)
def forward(self, x):
imsize = x.size()[2:]
_, _, c3, c4 = self.base_forward(x)
x = self.head(c4)
x = list(x)
x[0] = upsample(x[0], imsize, **self._up_kwargs) #sasc_output (PAM和CAM融合)
x[1] = upsample(x[1], imsize, **self._up_kwargs) #sa_output (单PAM)
x[2] = upsample(x[2], imsize, **self._up_kwargs) #sc_output (单CAM)
#全部上采样到了与原图相同大小
outputs = [x[0]]
outputs.append(x[1])
outputs.append(x[2])
return tuple(outputs)
class DANetHead(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer):
super(DANetHead, self).__init__()
inter_channels = in_channels // 4
self.conv5a = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv5c = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.sa = PAM_Module(inter_channels)
self.sc = CAM_Module(inter_channels)
self.conv51 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv52 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv6 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv7 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv8 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
def forward(self, x):
feat1 = self.conv5a(x)
sa_feat = self.sa(feat1)
sa_conv = self.conv51(sa_feat)
sa_output = self.conv6(sa_conv)
feat2 = self.conv5c(x)
sc_feat = self.sc(feat2)
sc_conv = self.conv52(sc_feat)
sc_output = self.conv7(sc_conv)
feat_sum = sa_conv+sc_conv
sasc_output = self.conv8(feat_sum)
output = [sasc_output]
output.append(sa_output)
output.append(sc_output)
return tuple(output)
encoding/nn/attention.py
class PAM_Module(Module):
""" Position attention module"""
#通过转置求矩阵乘积的形式求注意力矩阵,计算每个像素点与其他像素点的相关性。
#相关性高则乘以较大系数来增强其表达,相关性低则乘以较小的系数抑制其表达。
#但是经历了若干非线性变换后,谁知道原始特征映射被变成什么样了?
#尤其是为了减小计算量而缩小通道这个操作是否会导致特征丢失?
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x #可能是为了防止乘了一个特别小的系数后,某些特征被过分抑制,最后再加上x
return out
class CAM_Module(Module):
#该模块是通过转置求矩阵乘积的形式求出各个通道间相关性(相似度)
#由于是自身的转置与自身相乘,因此相同的通道其乘积必然最大,相似度最高
#对于相似度较高的通道,乘以小系数来削弱,相似性较低的通道乘以大系数加强其表达
#个人对这种操作持怀疑态度
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
通过阅读代码,resnet之后的操作如下
Resnet最后一层输出的特征映射C4通道为2048,将其输入到DANetHead中得到x:
c4经卷积核3×3,通道512的conv5a提特征并降低通道并BN+ReLU,生成feat1
feat1输入到PAM模块中,得到sa_feat:
使用卷积核1×1,通道64的query_conv降低feat1的通道,将每个map的像素展开成若干向量,并交换通道和像素维度(C×N变为N×C),生成proj_query。
使用卷积核1×1,通道64的key_conv降低feat1的通道,将每个map的像素展开成若干向量,生成proj_key。
对proj_query与proj_key进行batch matrix multiply(N×C×C×N)生成energy(N×N)
对energy求softmax,生成attention
使用卷积核1×1,通道512的value_conv对feat1做非线性映射,将每个map的像素展开成若干向量,生成proj_value。
对proj_value与转置后的(仍为N×N)attention进行batch matrix multiply(C×N×N×N)生成out(C×N)。
将out重新恢复成C×H×W的形式。
将out乘上一个可变参数gamma,再与feat1相加得到新的out
使用卷积核3×3,通道512的conv51将sa_feat卷积并BN+ReLU,生成sa_conv
使用卷积核1×1,通道数为输出类别个数,dropout为0.1的的conv6将sa_conv卷积,生成sa_output。
c4经卷积核3×3,通道512的conv5c提特征并降低通道并BN+ReLU,生成feat2。
feat2输入到CAM模块中,得到sc_feat:
将feat2的像素展开成C×N的形式,得到proj_query
将feat2的像素展开成C×N的形式,并交换通道和像素维度(C×N变为N×C),生成proj_key
对proj_query与proj_key进行batch matrix multiply(C×N×N×C)生成energy(C×C)
使用energy中最大的元素减去energy中所有元素,得到energy_new
对energy_new求softmax,生成attention
将feat2的像素展开成C×N的形式,得到proj_value
对attention与proj_value进行batch matrix multiply(C×C×C×N)生成out(C×N)
将out重新恢复成C×H×W的形式
将out乘上一个可变参数gamma,再与feat1相加得到新的out
使用卷积核3×3,通道512的conv52将sc_feat卷积并BN+ReLU,生成sc_conv
使用卷积核1×1,通道数为输出类别个数,dropout为0.1的的conv7将sc_conv卷积,生成sc_output。
将sa_conv与sc_conv相加得到feat_sum
使用卷积核1×1,通道数为输出类别个数,dropout为0.1的的conv8将feat_sum卷积,生成sasc_output。
将sasc_output、sa_output和sc_output三组输出append在一起,以tuple输出
将x转化为列表
将x[0]、x[1]和x[2](sasc_output、sa_output和sc_output)上采样到原图大小
将x[0]、x[1]和x[2]三组输出append在一起,以tuple输出。