【Pytorch基础教程22】肺部感染识别任务(模型微调实战)
学习总结
模型微调:迁移学习的应用场景,如在目标数据集上训练目标模型,将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
- 获取pytorch中的预训练模型,冻结预训练模型中所有参数;
- 然后模型微调:如替换ResNet最后的2层网络,返回一个新模型
文章目录
- 学习总结
- 一、任务介绍
- 二、步骤概览
- 三、具体流程
-
- 3.1 加载库和观察数据
- 3.2 迁移学习,微调模型
- 3.3 定义tensorboard writer的函数
- 3.4 训练结果
- Reference
一、任务介绍
数据集来源:https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia/download
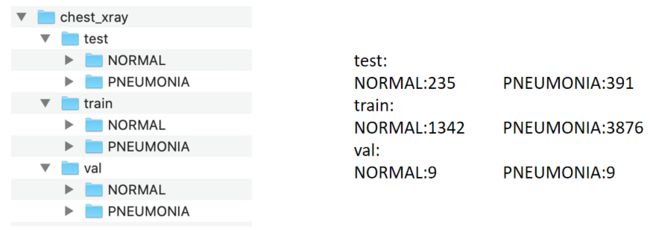
肺部感染识别任务,加载已经在imageNet上训练过的预训练模型ResNet,冻结中低层的参数(权重),将最后两层替换,微调参数,实现肺部感染的图片分类任务。说白了迁移学习,模型微调就是把拖拉机改装下零件,变成我们需要的变形金刚。
迁移学习(Transfer learning) 就是把已经训练好的模型参数迁移到新的模型来帮助新模型训练。
来回顾下ResNet网络:ResNet是为了解决梯度消失(由于在梯度计算的过程中是用的反向传播,所以需要利用链式法则来进行梯度计算,是一个累乘的过程。若每一个地方梯度都是小于1的,累乘后梯度会趋于0)的问题。
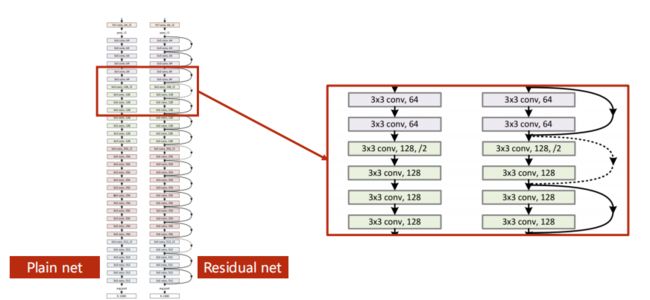
(1)residual block要求输入和输出的tensor维度相同。
(2)有的跳连接在上图汇总是虚线的,表示不一定做跳连接(因为维度不匹配的原因,无法跳跃后相加),所以需要做单独处理——如不做跳连接,或者在跳连接中做一个池化层,注意池化不改变通道数(上面栗子的正路是做一个卷积,起到/2效果)。
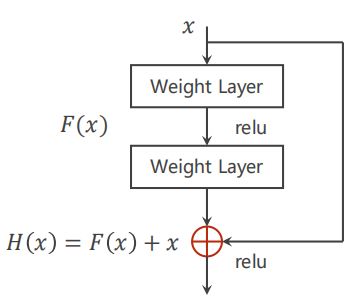
(3)构造网络的超参数和input、output的size需要计算好。为了检验网络是否正确,可以先对net简单测试(输入rand的tensor代入),如注释其他层,看前面层的结果和预期的tensor大小是否吻合,即【增量式开发】。
(4)卷积层中做的事,res是层间做的事。
代码如下,ResidualBlock和Net两个类变了,其余和之前没变。
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,
channels,
kernel_size = 3,
padding = 1)
self.conv2 = nn.Conv2d(channels,
channels,
kernel_size = 3,
padding = 1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
# x+y后再relu激活
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size = 5)
self.conv2 = nn.Conv2d(16, 32, kernel_size = 5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
二、步骤概览
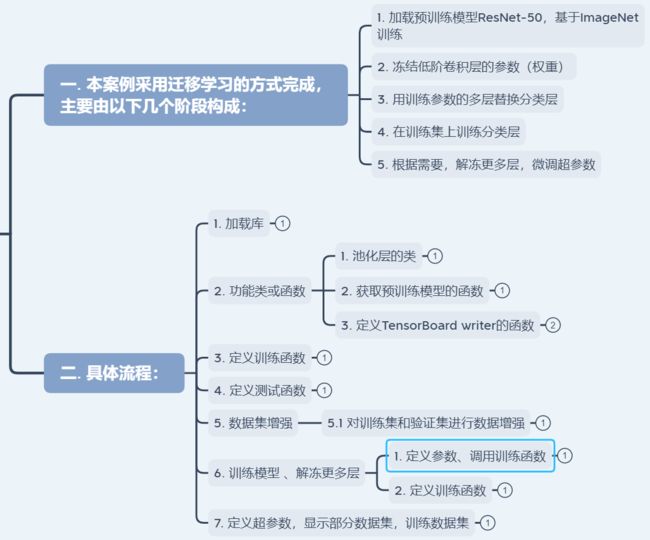
其中注意迁移学习的部分,我们直接拿torchvision.models.resnet50模型微调,首先冻结预训练模型中的所有参数,然后替换掉最后两层的网络(替换2层池化层,还有fc层改为dropout,正则,线性,激活等部分),最后返回模型。
三、具体流程
实验环境:NVIDIA GeForce RTX 3090,jupyter notebook。
3.1 加载库和观察数据
# 1 加入必要的库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, transforms, utils, models
import time
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.tensorboard.writer import SummaryWriter
import os
import torchvision
import copy
如果安装库较慢的童鞋可以加上清华源等。
另外如果需要在ubuntu上解压数据集压缩包,注意命令:
1、.tar 用 tar –xvf 解压
2、.gz 用 gzip -d或者gunzip 解压
3、.tar.gz和.tgz 用 tar –xzf 解压
4、.bz2 用 bzip2 -d或者用bunzip2 解压
5、.tar.bz2用tar –xjf 解压
6、.Z 用 uncompress 解压
7、.tar.Z 用tar –xZf 解压
8、.rar 用 unrar e解压
9、.zip 用 unzip 解压
了解我们数据集很重要,设置batch_size = 8,每次读取8张图片:
- 加载库,定义方法,显示图片。
- 定义超参数:如
batch_size、DEVICE等。 - 图片转换:如
transform,下面对train和val的字典形式进行操作,如:- 随机裁剪成300×300,
- 随机地水平方向旋转或拉伸
RandomHorizontalFlip(), - 随机中间裁剪
CenterCrop, - 并且使用官方的正则化方法
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])。 - 验证集
val的操作可以和train一样。
- 操作数据集:
- 文件直接拖到terminal也能直接知道文件路径。
- 加载train和val可以以字典形式,我们用列表推导式“同时”读取,最后以字典形式保存(ps:列表推导式比for循环快,这里还1句代替2句)。
- 为数据集创建一个迭代器,读取数据,也是字典形式,
x对应加载数据集的x。一般需要设置Shuffle和batch_size。 - 获取标签的类别名称(这里是感染和正常的情况),直接用
image_datasets['train'].classes即可。 - 最后一步:读取图片,注意用python的迭代器
iter把dataloader['train']变为一个可迭代对象,然后外层用next逐个读取,赋值给变量数据datas和标签targets。
# 1 加载库
import torch
import torch.nn as nn
from torchvision import datasets, transforms
import os
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import numpy as np
# 2 定义一个方法:显示图片
def image_show(inp, title=None):
plt.figure(figsize=(14, 3))
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
plt.show()
def main():
# 3 定义超参数
BATCH_SIZE = 8 # 每批处理的数据数量
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 4 图片转换
data_transforms = {
'train':
transforms.Compose([
transforms.Resize(300),
transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val':
transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
# 5 操作数据集
# 5.1 数据集路径
data_path = "chest_xray"
# 5.2 加载数据集train 和 val
image_datasets = { x : datasets.ImageFolder(os.path.join(data_path, x),
data_transforms[x]) for x in ['train', 'val']}
# 5.3 为数据集创建一个迭代器,读取数据
datalaoders = {x : DataLoader(image_datasets[x], shuffle=True,
batch_size=BATCH_SIZE) for x in ['train', 'val']}
# 5.3 训练集和验证集的大小(图片的数量)
data_sizes = {x : len(image_datasets[x]) for x in ['train', 'val']}
# 5.4 获取标签的类别名称: NORMAL 正常 --- PNEUMONIA 感染
target_names = image_datasets['train'].classes
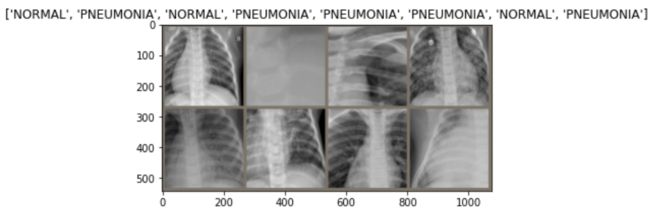
# 6 显示一个batch_size的图片(8张图片)
# 6.1 读取8张图片
datas, targets = next(iter(datalaoders['train']))
# 6.2 将若干张图片拼成一幅图像
out = make_grid(datas, nrow=4, padding=10)
# 6.3 显示图片
image_show(out, title=[target_names[x] for x in targets])
if __name__ == '__main__':
main()
- 为了好看哈哈,可以将8张图片拼起来(用
torchvision.utils的make_grid,还能设置图片之间的间隔padding) - 最后显示图片,直接用pytorch官网的
image_show了。
3.2 迁移学习,微调模型
模型微调:迁移学习的应用场景,如在目标数据集上训练目标模型,将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
- 获取pytorch中的预训练模型,冻结预训练模型中所有参数;
- 然后模型微调:如替换ResNet最后的2层网络,返回一个新模型
首先冻结预训练模型中的所有参数,然后替换掉最后两层的网络(替换2层池化层,还有fc层改为dropout,正则,线性,激活等部分),最后返回模型。
- 其中新的池化层,是两个
nn.AdaptiveAvgPool2d(size)拼接起来的(最后一个参数为1,表示是纵向维度的拼接)。 - 接着的原来的
fc层被替换,这里一坨层用的上节提到的nn.Sequential组合:- dropout一般写在正则化后,取参数0.5,丢掉一些神经元;
- 线性层处理后,加激活层和正则化。
# 8 更改池化层
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
size = size or (1, 1) # 池化层的卷积核大小,默认值为(1,1)
self.pool_one = nn.AdaptiveAvgPool2d(size) # 池化层1
self.pool_two = nn.AdaptiveAvgPool2d(size) # 池化层2
def forward(self, x):
return torch.cat([self.pool_one(x), self.pool_two(x), 1]) # 连接两个池化层
# 7 迁移学习:拿到一个成熟的模型,进行模型微调
def get_model():
model_pre = models.resnet50(pretrained=True) # 获取预训练模型
# 冻结预训练模型中所有的参数
for param in model_pre.parameters():
param.requires_grad = False
# 微调模型:替换ResNet最后的两层网络,返回一个新的模型
model_pre.avgpool = AdaptiveConcatPool2d() # 池化层替换
model_pre.fc = nn.Sequential(
nn.Flatten(), # 所有维度拉平
nn.BatchNorm1d(4096), # 256 x 6 x 6 ——> 4096
nn.Dropout(0.5), # 丢掉一些神经元
nn.Linear(4096, 512), # 线性层的处理
nn.ReLU(), # 激活层
nn.BatchNorm1d(512), # 正则化处理
nn.Linear(512,2),
nn.LogSoftmax(dim=1), # 损失函数
)
return model_pre
3.3 定义tensorboard writer的函数
这里比较特殊,为了保存成日志:
from torch.utils.tensorboard.writer import SummaryWriter
# 定义函数,获取Tensorboard的writer
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S")
writer = SummaryWriter('logdir/' + timestr)
return writer
这里的writer是为了tensorboard的可视化使用,一般的用法如下:
writer = SummaryWriter("../logs") #定义logs文件位置
writer.add_scalar("test_acc", total_accuracy, total_test_step) #添加名称,数据,step
writer.close() #关闭
#######################
# 在命令行:
tensorboard --logdir=logs
3.4 训练结果
训练了20min左右,结果很神奇的,先是accuracy慢慢升到0.88后,又降低到0.75了:
Epoch | Training Loss | Test Loss | Accuracy |
Test Loss : 0.7482, Accuracy : 0.7500
0 | 0.37546360227437947 | 0.7481886744499207 | 0.75 |
Test Loss : 0.4785, Accuracy : 0.8125
1 | 0.26250585539975774 | 0.4785425364971161 | 0.81 |
Test Loss : 0.6143, Accuracy : 0.8125
2 | 0.24647439648354016 | 0.614277184009552 | 0.81 |
Test Loss : 0.4550, Accuracy : 0.8750
3 | 0.22980742459834175 | 0.45500850677490234 | 0.88 |
Test Loss : 0.4762, Accuracy : 0.8750
4 | 0.22832605980867202 | 0.47616851329803467 | 0.88 |
Test Loss : 0.5090, Accuracy : 0.8125
5 | 0.22127203448984092 | 0.5090200304985046 | 0.81 |
Test Loss : 0.5329, Accuracy : 0.8125
6 | 0.2200799149982977 | 0.5329417586326599 | 0.81 |
Test Loss : 0.7185, Accuracy : 0.8125
7 | 0.20401323301827207 | 0.7185251116752625 | 0.81 |
Test Loss : 0.6448, Accuracy : 0.7500
8 | 0.21905418684930994 | 0.6448410749435425 | 0.75 |
Test Loss : 0.6633, Accuracy : 0.7500
9 | 0.2127879018557976 | 0.6633487343788147 | 0.75 |
Training complete in 20.00m 12.74s
全部代码和数据集已放在我的github中。
Reference
[1] Linux下如何解压.zip和.rar文件
[2] CNN模型调整总结(transforms.Compose、模型训练、模型指标等)