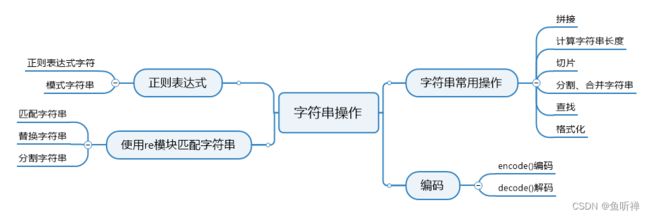
Python学习笔记-字符串
目录
一、字符串类型
二、字符串的常用操作
1.字符串拼接
2.计算字符串的长度
3.截取字符串
4.分割、合并字符串
4.1 分格字符串
4.2 多字符分割字符串
4.3 合并字符串
5.检索字符串
5.1 count()
5.2 index() 和rindex()
5.3 find()和rfind()
5.4 startswith()
5.5 endswith()
5.6 replace()
6. 去除字符
7.大小写转换
三、字符串格式化
1.%占位符格式化
2.format()格式化
2.1 基本格式
2.2 格式限定符
3.fstring()格式化
3.1 格式:
3.2 格式限定符
四、字符串编码
1.使用encode()方法编码
2.使用decode()方法解码
五、正则表达式
1.正则表达式字符
2.模式字符串
3.通过re模块使用正则表达式
3.1 re模块的基本方法
3.2 匹配字符串
3.2.1 使用match()方法进行匹配
3.2.2 Match对象
3.2.3 使用search()方法进行匹配
3.2.4 使用findall()方法进行匹配
3.3 替换字符串
3.4 使用正则表达式分割字符串
用来讲述python中关于字符串的操作,包括字符串操作,编码解码,正则表示式等。
一、字符串类型
- python中字符串属于不可变序列;
- 字符串可以用'内容',"内容",''内容'',""内容"",'''内容''',"""内容"""声明;
- 使用''' '''或""" """生命的字符串可以分多行写,一个引号或者2个引号的需要保持在同一行;
- 不同引号中可以嵌套,但是起始和终止的引号必须是一样的。
- 原生字符串标识:r或者R,可以将字符穿标识为原生字符串,不需要再添加转移字符,类似 与C#等语言中的@符号。
如下是常用转义字符:
| 转义字符 | 说明 |
| \ | 续行符 |
| \n | 换行符 |
| \0 | 空 |
| \t | 水平制表符,用于横向跳到下一制表位 |
| \" | 双引号 |
| \' | 单引号 |
| \\ | 一个反斜杠 |
| \f |
换页 |
| \0dd | 八进制数,dd代表的字符,如\012代表换行 |
| \xhh | 十六进制,hh代表的字符,如\x0a代表换行 |
二、字符串的常用操作
1.字符串拼接
格式:
字符串1 + 字符串2
注意:
拼接的如果不是字符串就会报错,需要将其他类型先转换到字符串。
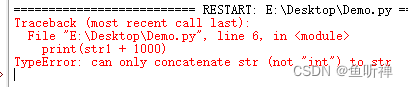
# _*_ coding:utf-8 _*_
str1 = "这是字符串1"
str2 = "这是字符串2"
num = 1000
print(str1 + 1000)结果:
将数字转成字符串后就可以正常了。
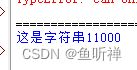
# _*_ coding:utf-8 _*_
str1 = "这是字符串1"
str2 = "这是字符串2"
num = 1000
print(str1 + str(num))结果:
2.计算字符串的长度
| 类型 | 长度 |
| 字母A-Z,a-z | 1个字节 |
| 数字0-9 | 1个字节 |
| .、*、空格的符号 | 1个字节 |
| 中文汉字 | 2~4字节 gbk格式占2个字节 utf-8格式占3个字节 |
示例:
# _*_ coding:gbk _*_
str1 = "人生苦短,我用python!"
print("gbk格式长度",len(str1))
print("utf-8格式长度",len(str1.encode())) #encode() 默认是utf-8格式
结果:

3.截取字符串
同序列一致,通过切片截取字符串。
格式:
[ start : end : step]
4.分割、合并字符串
4.1 分格字符串
语法:
list = str.split(sep, maxsplit) #从左往右分割
list = str.rsplit(sep, maxsplit) #从右往左分割
list = str.splitlines(keepends = false) #以换行符“\n”分割
- sep:用来分割的字符,",",空格等字符,默认值是空格;
- maxsplit:用来指定分割次数,没有设定或者-1表示没有限制;
- keepends :是否包含边界,False时返回的不包含边界,True时会保留行边界的分隔符
示例:
# _*_ coding:gbk _*_
str1 = "人生 苦短,我用 python!,今天 星期五,还没有 放假!"
print("字符串:",str1)
print("str1.split():",str1.split())
print("str1.split(" ",2):",str1.split(" ",2))
print("str1.split(","):",str1.split(","))
print("str1.split(",",1):",str1.split(",",2))结果:

4.2 多字符分割字符串
string自带的分割函数只能使用单一的字符串分割,若要使用多个字符串分割,可以使用re库的函数。
re.split(pattern, string[, maxsplit=0, flags=0])
- pattern:匹配的正则表达式
- string:要匹配的字符串
- maxsplit:分割次数,默认为0,不限制分割次数
- flags:标志位,用于控制正则表达式的匹配方式,如是否区分大消息,多行匹配等。
4.3 合并字符串
语法:
stringnew = string.join(iterable)
- string:合并时的字符串;
- iterable:可迭代对象,如,列表、元组;
示例:
# _*_ coding:gbk _*_
strlist = ["人生苦短","我天","今天星期五","还没有放假!"]
print("列表:",strlist)
print("\",\".join(strlist):",",".join(strlist))
结果:

5.检索字符串
5.1 count()
str.count(sub[,start[.end]])
- sub:用于检索的字符串
- start:起始搜索
- end:终点索引
- 返回的是sub在指定位置出现的次数
示例:
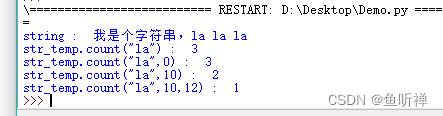
# _*_ coding:utf-8 _*_
str_temp = "我是个字符串,la la la"
print("string : ",str_temp)
print("str_temp.count(\"la\") : ", str_temp.count("la"))
print("str_temp.count(\"la\",0) : ", str_temp.count("la",0))
print("str_temp.count(\"la\",10) : ", str_temp.count("la",10))
print("str_temp.count(\"la\",10,12) : ", str_temp.count("la",10,12))
结果:
5.2 index() 和rindex()
str.index(sub[,start[.end]]) #从左往右找
str.rindex(sub[,start[.end]]) #从右往左找
注意:当字符串找不到时,抛出ValueError错误。
5.3 find()和rfind()
str.find(sub[,start[.end]]) #从左往右找
str.rfind(sub[,start[.end]]) #从右往左找
注意:包含时返回sub的索引位置,否则返回-1.
5.4 startswith()
str.startswith(prefix[, start[, end]])
判断字符串是否以prefix开头;
5.5 endswith()
str.endswith(suffix[, start[, end]])
判断字符串是否以suffix为结尾;
5.6 replace()
str.replace(old, new[, count])
- old:旧的字符串
- new:新的字符串
- count:替换次数
6. 去除字符
str.strip([chars]) # 从两边移除字符
str.lstrip([chars]) # 从左边移除字符
str.rstrip([chars]) # 从右边移除字符
默认移除空白(空格、制表符、换行符)。
7.大小写转换
str.lower() # 转换小写
str.upper() # 转换大写
三、字符串格式化
三种格式化方式:
- %占位符格式化
- format()方法格式化
- f-string
1.%占位符格式化
与C语言的格式化输出有点像,用%号占位
% flags width . precision typecode
- % :占位符标识
- flags: 为空 右对齐,- 左对齐
- width:输出字段宽度
- .precision:小数点后保留几位
- typecode:为必填项
- c :以字符形式输出,只输出一个字符
- s :输出字符串
- d/i :以带符号的十进制形式输出整数(正数不输出符号)
- f : 以小数形式输出单、双精度数,隐含输出6位小数
- o : 以八进制无符号形式输出整数
- e/E:以指数形式输出实数
- g/G:选用%f或%e格式中输出宽度较短的一种格式,不输出无意义的0
- x/X :以十六进制无符号形式输出整数(不输出前导符0x),用x则输出十六进制数的a~f时以小写形式输出,用X时,则以大写字母输出
- % :当字符串中存在格式化标志时,需要用 %%表示一个百分号
示例:
# _*_ coding:utf-8 _*_
num = 3.141592654
print("%20.2f"%num)
print("%0d"%num)
print("%10.2f%%"%(num/100))结果:

2.format()格式化
2.1 基本格式
string.format()
- string:格式化输出字符串,内部使用{}占位
- format():要输出的数据
- 格式与%相似,采用{}来替换%输出格式。
示例:
# _*_ coding:utf-8 _*_
print('"今天是星期{},天气{}".format("天","晴"):',"今天是星期{},天气{}".format("天","晴"))
print('"今天是星期{0},天气{1}".format("天","晴"):',"今天是星期{0},天气{1}".format("天","晴"))
print('"今天是星期{0},天气{0}".format("天","晴"):',"今天是星期{0},天气{0}".format("天","晴"))
print('"今天是星期{day},天气{weather}".format(day = "天", weather = "晴"):',"今天是星期{day},天气{weather}".format(day = "天", weather = "晴"))
结果:

2.2 格式限定符
其中{}中的可以结合格式限定符设置各种格式,用{:}声明格式:
- {:^n}:^、<、>分别是居中、左对齐、右对齐,后面带宽度
- :号后面带填充的字符,默认是空格
- 使用"."和数字定义数字精度格式
- b,d,o,x分别表示二进制、十进制、八进制、十六进制
- 用”,“作为金额的千位分隔符
示例:
# _*_ coding:utf-8 _*_
num = 1314.520
print('num:',"{:^10}".format(num))
print('"{:^10}".format(num):',"{:^10}".format(num))
print('"{:<10}".format(num):',"{:<10}".format(num))
print('"{:>10}".format(num):',"{:>10}".format(num))
print('"{:_^10}".format(num):',"{:_^10}".format(num))
print('"{:_<10}".format(num):',"{:_<10}".format(num))
print('"{:_>10}".format(num):',"{:_>10}".format(num))
print('"{:#^10}".format(num):',"{:#^10}".format(num))
print('"{:#<10}".format(num):',"{:#<10}".format(num))
print('"{:#>10}".format(num):',"{:#>10}".format(num))
print('"{:b}".format(int(num)):',"{:b}".format(int(num)))
print('"{:d}".format(int(num)):',"{:d}".format(int(num)))
print('"{:o}".format(int(num)):',"{:o}".format(int(num)))
print('"{:x}".format(int(num)):',"{:x}".format(int(num)))
print('"{:2.2f}".format(num):',"{:2.2f}".format(num))
print('"{:10.10f}".format(num):',"{:10.10f}".format(num))
print('"{:_^10.10f}".format(num):',"{:_^20.2f}".format(num))
# 结果如下:
num: 1314.52
"{:^10}".format(num): 1314.52
"{:<10}".format(num): 1314.52
"{:>10}".format(num): 1314.52
"{:_^10}".format(num): _1314.52__
"{:_<10}".format(num): 1314.52___
"{:_>10}".format(num): ___1314.52
"{:#^10}".format(num): #1314.52##
"{:#<10}".format(num): 1314.52###
"{:#>10}".format(num): ###1314.52
"{:b}".format(int(num)): 10100100010
"{:d}".format(int(num)): 1314
"{:o}".format(int(num)): 2442
"{:x}".format(int(num)): 522
"{:2.2f}".format(num): 1314.52
"{:10.10f}".format(num): 1314.5200000000
"{:_^10.10f}".format(num): ______1314.52_______3.fstring()格式化
3.1 格式:
f"字符串{}" 或 F”字符串{}“
- 使用f或F作为标识
- 字符串内部使用{}作为替换字段标识
- 字符串内部{}直接填入替换内容
- 相对更简洁明了
- {}中可以填入变量、内容、表达式
- {}内不允许输入\,若要包含需要先定义一个变量,然后再将变量填入
- {}外可以使用\转移
- 支持多行字符串替换
- 输入大括号需要使用{{和}}
3.2 格式限定符
{content:format}
常用格式如下:
| 符号 | 说明 | 备注 |
|---|---|---|
| ^、<、> | 分别是居中、左对齐、右对齐,后面带宽度 | {:^n} n是宽度 |
| :char | :号后面带填充的字符,默认是空格 | |
| "." | 数字定义数字精度格式. width.precision格式: width:指定宽度 precision:指定显示精度,格式为f,F,e,E和%时表示小数点后位数,格式为g和G时表示有效数字位数(小数点前位数+小数点后位数) |
适用于整数类型 |
| b,d,o,x,X | 二进制、十进制、八进制、十六进制小写字母、十六进制大写字母 注意:B、D、O不是格式符。 |
适用于整数类型 |
| ”,“ | 金额的千位分隔符 | |
| + | 负数前面添加(-),正数前面添加(+) | 仅适用于数字类型 |
| - | 负数前面添加(-),正数前面不加任何符号 | 仅适用于数字类型 |
| (空格) | 负数前面添加(-),正数前面加一个空格 | 仅适用于数字类型 |
| # | 切换数字显示方式,在数字面前显示进制符号,0b,0o,0x,0X | 仅适用于数字类型 |
| s | 普通字符串格式 | 适用于字符串 |
| c | 字符格式,按照unicode编码将整数转为对应字符 | 适用于整数 |
| e | 科学计数法格式,e表示x10^ | 适用于浮点数、复数、整数(会自动转为浮点数) |
| E | 科学计数法格式,E表示x10^ | 适用于浮点数、复数、整数(会自动转为浮点数) |
| f | 定点数格式,默认精度是6 | 适用于浮点数、复数、整数(会自动转为浮点数) |
| F | 与f等价,将nan和inf换成NAN和INF | 适用于浮点数、复数、整数(会自动转为浮点数) |
| g | 通用格式,小数用f,大数用e | 适用于浮点数、复数、整数(会自动转为浮点数) |
| G | 与g等价,但小数用F,大数用E | 适用于浮点数、复数、整数(会自动转为浮点数) |
| % | 百分比格式,数字自动乘以100后按照f格式排版,添加%作为后缀 | 适用于浮点数、整数(会自动转为浮点数) |
示例:
# _*_ coding:utf-8 _*_
num = 1314.520
day = "星期六"
print('num:',num)
print("day:",day)
print('f"num = {num},day = {day}":',f"num = {num},day = {day}")
print('f"""num = {num},day = {day}""":',f"""
num = {num}
day = {day}""")
print('f"num = {num:^20}":',f"num = {num:,}")
print('f"num = {num:^20}":',f"num = {num:^20}")
print('f"num = {num:<20}":',f"num = {num:<20}")
print('f"num = {num:>20}":',f"num = {num:>20}")
print('f"num = {int(num):b}":',f"num = {int(num):b}")
print('f"num = {int(num):d}":',f"num = {int(num):d}")
print('f"num = {int(num):o}":',f"num = {int(num):o}")
print('f"num = {int(num):x}":',f"num = {int(num):x}")
print('f"num = {int(num):X}":',f"num = {int(num):X}")
print('f"num = {int(num):#b}":',f"num = {int(num):#b}")
print('f"num = {int(num):#d}":',f"num = {int(num):#d}")
print('f"num = {int(num):#o}":',f"num = {int(num):#o}")
print('f"num = {int(num):#x}":',f"num = {int(num):#x}")
print('f"num = {int(num):#X}":',f"num = {int(num):#X}")
print('f"num = {num*1000:e}":',f"num = {num*1000:e}")
print('f"num = {str(num):s}":',f"num = {str(num):s}")
print('f"num = {0x12:c}":',f"num = {0x12:c}")
print('f"num = {0x38:c}":',f"num = {0x38:c}")
print('f"num = {0x21:c}":',f"num = {0x21:c}")
print('f"num = {num:E}":',f"num = {num:E}")
print('f"num = {num:f}":',f"num = {num:f}")
print('f"num = {num:F}":',f"num = {num:F}")
print('f"num = {num:g}":',f"num = {num:g}")
print('f"num = {num:G}":',f"num = {num:G}")
print('f"num = {num:%}":',f"num = {num:%}")
# 结果如下:
num: 1314.52
day: 星期六
f"num = {num},day = {day}": num = 1314.52,day = 星期六
f"""num = {num},day = {day}""":
num = 1314.52
day = 星期六
f"num = {num:^20}": num = 1,314.52
f"num = {num:^20}": num = 1314.52
f"num = {num:<20}": num = 1314.52
f"num = {num:>20}": num = 1314.52
f"num = {int(num):b}": num = 10100100010
f"num = {int(num):d}": num = 1314
f"num = {int(num):o}": num = 2442
f"num = {int(num):x}": num = 522
f"num = {int(num):X}": num = 522
f"num = {int(num):#b}": num = 0b10100100010
f"num = {int(num):#d}": num = 1314
f"num = {int(num):#o}": num = 0o2442
f"num = {int(num):#x}": num = 0x522
f"num = {int(num):#X}": num = 0X522
f"num = {num*1000:e}": num = 1.314520e+06
f"num = {str(num):s}": num = 1314.52
f"num = {0x12:c}": num =
f"num = {0x38:c}": num = 8
f"num = {0x21:c}": num = !
f"num = {num:E}": num = 1.314520E+03
f"num = {num:f}": num = 1314.520000
f"num = {num:F}": num = 1314.520000
f"num = {num:g}": num = 1314.52
f"num = {num:G}": num = 1314.52
f"num = {num:%}": num = 131452.000000%四、字符串编码
1.使用encode()方法编码
str.encode([encoding = "utf-8"][,errors = "strict"])
- 将字符串转换为二进制数据bytes
- encoding:编码规则,默认是utf-8,当只有一个参数时,可以省略“encoding=”,直接写编码格式。
- errors:错误处理方式
- strict:遇到非法字符抛出异常
- ignore:忽略错误
- replace:用"?"替换非法字符
- xmlcharrefreplace:使用xml的字符引用等,默认值为strict。
- GBK/GBK2312:一个字节表示英文字母,两个字节表示中文字符;
- UTF-8:一个字节表示英文字母,三个字节表示中文字符。
2.使用decode()方法解码
bytes.decode([encoding = "utf-8"][,errors = "strict"])
- 将二进制数据bytes转换为指定编码格式的字符串
- encoding:编码规则,默认是utf-8,当只有一个参数时,可以省略“encoding=”,直接写编码格式。
- errors:错误处理方式
- strict:遇到非法字符抛出异常
- ignore:忽略错误
- replace:用"?"替换非法字符
- xmlcharrefreplace:使用xml的字符引用等,默认值为strict。
- GBK/GBK2312:一个字节表示英文字母,两个字节表示中文字符;
- UTF-8:一个字节表示英文字母,三个字节表示中文字符。
示例:
# _*_ coding:utf-8 _*_
test_string = "今天是个好日子,明天就放假了,la la la"
print("string:",test_string)
print("")
strbytes = test_string.encode()
print("test_string.encode():",strbytes)
print("test_string.decode():",strbytes.decode())
print("")
strbytes = test_string.encode("utf-8")
print('test_string.encode("utf-8"):',strbytes)
print('test_string.decode("utf-8"):',strbytes.decode("utf-8"))
print("")
strbytes = test_string.encode("gbk")
print('test_string.encode("gbk"):',strbytes)
print('test_string.decode("gbk"):',strbytes.decode("gbk"))
# 结果如下:
string: 今天是个好日子,明天就放假了,la la la
test_string.encode(): b'\xe4\xbb\x8a\xe5\xa4\xa9\xe6\x98\xaf\xe4\xb8\xaa\xe5\xa5\xbd\xe6\x97\xa5\xe5\xad\x90\xef\xbc\x8c\xe6\x98\x8e\xe5\xa4\xa9\xe5\xb0\xb1\xe6\x94\xbe\xe5\x81\x87\xe4\xba\x86\xef\xbc\x8cla la la'
test_string.decode(): 今天是个好日子,明天就放假了,la la la
test_string.encode("utf-8"): b'\xe4\xbb\x8a\xe5\xa4\xa9\xe6\x98\xaf\xe4\xb8\xaa\xe5\xa5\xbd\xe6\x97\xa5\xe5\xad\x90\xef\xbc\x8c\xe6\x98\x8e\xe5\xa4\xa9\xe5\xb0\xb1\xe6\x94\xbe\xe5\x81\x87\xe4\xba\x86\xef\xbc\x8cla la la'
test_string.decode("utf-8"): 今天是个好日子,明天就放假了,la la la
test_string.encode("gbk"): b'\xbd\xf1\xcc\xec\xca\xc7\xb8\xf6\xba\xc3\xc8\xd5\xd7\xd3\xa3\xac\xc3\xf7\xcc\xec\xbe\xcd\xb7\xc5\xbc\xd9\xc1\xcb\xa3\xacla la la'
test_string.decode("gbk"): 今天是个好日子,明天就放假了,la la la
>>> 五、正则表达式
正则表达式用来匹配字符串。
1.正则表达式字符
| 分类 | 字符 | 说明 | 备注 |
|---|---|---|---|
| 行定位符 | ^ | 开始符,^+字符,表示以指定字符开始 | |
| $ | 结尾符,字符+$,表示以指定字符结尾 | ||
| 字符 | 没有起始或结尾符,表示字符可以出现在任何位置 | ||
| 元字符 | . | 匹配除换行符以外的任意字符 | 不能匹配换行符”\n“ |
| \w |
匹配字母、数字、下划线或汉字 | 不能匹配特殊字符 | |
| \W | 匹配除字母、数字、下划线或汉字以外的字符 | 匹配特殊字符,不能匹配字母、数字、下划线或汉字 | |
| \s | 匹配单个的空白符(包括tab键和换行符) | 匹配\t,\n、” “ | |
| \S | 除单个空白符(包括tab键和换行符)以外的所有字符 | ||
| \b | 匹配单词的开始或结束,单子的分界符通常是空格,标点符号或者换行符,\b字符表示以字符开始的单词,字符\b表示以字符结束的单词。 | ||
| \d | 匹配数字 | ||
| 限定符 | ? | 匹配前面的字符零次或一次 | |
| + | 匹配前面的字符一次或者多次 | ||
| * | 匹配前面的字符零次或多次 | ||
| {n} | 匹配前面的字符:=n次 | ||
| {n,} | 匹配前面的字符:>=n次 | ||
| {n,m} | 匹配前面的字符:n次 <= 次数 <= m次。 | ||
| 字符类 | [] | 用[]括起字符用来匹配指定的字符其中一个,可用”-“连接字符串范围。 [aeiou]表示匹配aeiou其中一个字符; [0-9]表示匹配一个数字; [a-z]表示匹配一个小写字母; [\u4e00-\u9fa5]表示匹配一个汉字。 |
|
| 排除字符 | ^ | 在[]中开头写”^“表示匹配一个不是括号中的字符 [^a-zA-Z]匹配一个不是字母的字符 |
|
| 选择字符 | | | 类似于或,用来匹配多个条件的其中一个 | |
| 转移字符 | \ | 类似字符串的转义字符,用来将特殊字符转化为普通字符 | |
| 分组字符 | () | 适用给小括号可以对判定进行分组 |
2.模式字符串
正则表达式在python中用作模式字符串用来皮牌字符串。
如匹配字母:
“[a-zA-z]”
注意作为模式字符串时需要对“\”等特殊符号进行转移才能正常识别:
如:
"\bA*" # 会识别为"\","b"两个字符开头
“\\bA” # 可以识别为以A开头的单词。
一般建议适用r或R标识字符串,避免要输入大量的转义字符。
r"\bA" # 可以识别为以A开头的单词。
3.通过re模块使用正则表达式
re模块是python用来实现正则表达式操作的模块,可以通过re模块的方法进行字符串处理,同时也可以进行正则表达式匹配。
使用re模块需要先导入模块:
import re若没有导入模块,直接使用时会报错。
3.1 re模块的基本方法
| 方法 | 说明 | 备注 |
|---|---|---|
| search() |
查找字符串 | |
| match() | 匹配字符串 | |
| findall() | 查找所有符合条件的字符串 | |
| complie() | 将模式字符串转为正则表达式 | |
3.2 匹配字符串
通常使用match(),search(),findall()等方法进行匹配。
3.2.1 使用match()方法进行匹配
match()方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None.
格式:
re.match(pattern,string,[flags])
- pattern:模式字符串,由要匹配的正则表达式转换而来
- string:要匹配的字符串
- flags:可选参数,标志位,用于控制匹配方式。
常用标志:
| 标志 | 说明 |
|---|---|
| A或ASCII | 对于\w,\W,\b,\B,\d,\D,\s和\S只进行ASCII匹配 |
| I或IGNORECASE | 不区分字母大小写 |
| M或MULTILINE | 将^和$用于包括整个字符串的开始和结尾的每一个行(默认情况下,仅适用于整个字符串的开始和结尾) |
| S或DOTALL | 使用(.)字符陪陪所有字符,包括\n(换行符) |
| X或VERBOSE | 忽略模式字符串中未转义的空格和注释 |
示例:
# _*_ coding:utf-8 _*_
import re
print(r're.match(r"\bhe","he sad hello word."):',re.match(r"\bhe","he sad hello word."))
print(r're.match(r"\bhe","he sad hello word.",re.A):',re.match(r"\bhe","he sad hello word.",re.A))
print(r're.match(r"\bhe","He sad hello word."):',re.match(r"\bhe","He sad hello word."))
print(r're.match(r"\bhe","Hello word he sad.",re.I):',re.match(r"\bhe","Hello word he sad .",re.I))
# 结果如下:
re.match(r"\bhe","he sad hello word."):
re.match(r"\bhe","he sad hello word.",re.A):
re.match(r"\bhe","He sad hello word."): None
re.match(r"\bhe","Hello word he sad.",re.I):
>>> 3.2.2 Match对象
Match对象包含匹配值的位置和匹配数据,常用方法如下
| 方法/属性 | 说明 | 备注 |
|---|---|---|
| start() | 获取匹配值的起始值 | |
| end() | 获取匹配值的结束位置 | |
| span() | 获取匹配位置的元组 | |
| group() | 获取匹配的数据 | |
| expand(self, /, template) | 返回通过对字符串模板进行反斜杠替换获得的字符串,就像sub()方法所做的那样。 | |
| string | 获取要匹配的字符串 |
示例:
# _*_ coding:utf-8 _*_ import re pattern = r"^he.*\w+" string = "he said hello word." match = re.match(pattern,string,re.I) print(r'match.start():',match.start()) print(r'match.end():',match.end()) print(r'match.span():',match.span()) print(r'match.string():',match.string) print(r'match.group():',match.group()) print(r'match.expand("\nare\nyou"):',match.expand("\nare\nyou")) # 结果 match.start(): 0 match.end(): 18 match.span(): (0, 18) match.string(): he said hello word. match.group(): he said hello word match.expand("\nare\nyou"): are you >>>
3.2.3 使用search()方法进行匹配
用于在整个字符串中搜索第一个匹配的值,如果在起始位置匹配成功,返回Match,否则返回None。
格式如下:
re.search(pattern,string,[flags])
- pattern:模式字符串,由要匹配的正则表达式转换而来
- string:要匹配的字符串
- flags:可选参数,标志位,用于控制匹配方式。
示例:
# _*_ coding:utf-8 _*_
import re
pattern = r"he\w+"
string = "he said hello word."
match = re.search(pattern,string)
print(match)
# 结果
3.2.4 使用findall()方法进行匹配
用于获取整个字符串中素有符合正则表达式的字符串,并以列表的形式返回。
格式如下:
re.findall(pattern,string,[flags])
- pattern:模式字符串,由要匹配的正则表达式转换而来
- string:要匹配的字符串
- flags:可选参数,标志位,用于控制匹配方式。
- 若存在分组时返回的是符合分组的结果,若要获取完整的匹配结果,需要给整个模式字符串添加一个分组表示,多个分组会返回所有匹配结果的元组列表。
示例:
# _*_ coding:utf-8 _*_
import re
# 只有一个分组
pattern = r"[1-9]{1,3}(\.[0-9]{1,3}){3}"
string = "192.168.1.0 127.0.0.1"
match = re.findall(pattern,string)
print(match)
# 多个分组,返回值是按照分组次序获得的元组
pattern = r"([1-9]{1,3}(\.[0-9]{1,3}){3})"
string = "192.168.1.0 127.0.0.1"
match = re.findall(pattern,string)
print("match result:",match)
print("type:",type(match))
结果:
['.0', '.1']
match result: [('192.168.1.0', '.0'), ('127.0.0.1', '.1')]
type: 3.3 替换字符串
可以使用re.sub()方法实现字符串替换。
re.sub(pattern, rep1, string, count, flags)
- pattern:模式字符串,由要匹配的正则表达式转换而来
- rep1:要替换的字符串
- string:要查找的原始字符串
- count:可选参数,表示替换的最大次数,默认值为0,表示替换所有匹配值。
- flags:可选参数,标志位,用于控制匹配方式。
示例:
# _*_ coding:utf-8 _*_
import re
pattern = r"(\.[0-9]{1,3}){3}"
string = "192.168.1.0 127.0.0.1"
match = re.sub(pattern,".x.x.x",string)
print(match)结果:
192.x.x.x 127.x.x.x3.4 使用正则表达式分割字符串
使用re.split()方法可以实现根据正则表达式继续宁分割字符串,并以列表形式返回。
re.split(pattern, string, [maxsplit], [flags])
- pattern:模式字符串,由要匹配的正则表达式转换而来
- string:要匹配的字符串
- maxsplit:可选参数,表示分割的最大次数
- flags:可选参数,标志位,用于控制匹配方式
示例:
# _*_ coding:utf-8 _*_
import re
pattern = r"[.]"
string = "192.168.1.0 127.0.0.1 星期天,星期一,晴天/雨天, 好的V不好"
pattern = r"[ ]"
match = re.split(pattern,string)
print(r'[ ]:',match)
pattern = r"[,]"
match = re.split(pattern,string)
print(r'[,]:',match)
pattern = r"[,]"
match = re.split(pattern,string)
print(r'[,]:',match)
pattern = r"[/]"
match = re.split(pattern,string)
print(r'[/]:',match)
pattern = r"[v]"
match = re.split(pattern,string)
print(r'[v]:',match)
pattern = r"[v]"
match = re.split(pattern,string,0,re.I)
print(r'[v]:',match)
pattern = r"[., ,/v]"
match = re.split(pattern,string)
print(r'[., ,/v]:',match)结果:
[ ]: ['192.168.1.0', '127.0.0.1', '星期天,星期一,晴天/雨天,', '好的V不好']
[,]: ['192.168.1.0 127.0.0.1 星期天,星期一', '晴天/雨天', ' 好的V不好']
[,]: ['192.168.1.0 127.0.0.1 星期天', '星期一,晴天/雨天, 好的V不好']
[/]: ['192.168.1.0 127.0.0.1 星期天,星期一,晴天', '雨天, 好的V不好']
[v]: ['192.168.1.0 127.0.0.1 星期天,星期一,晴天/雨天, 好的V不好']
[v]: ['192.168.1.0 127.0.0.1 星期天,星期一,晴天/雨天, 好的', '不好']
[., ,/v]: ['192', '168', '1', '0', '127', '0', '0', '1', '星期天', '星期一', '晴天', '雨天', '', '好的V不好']
>>>