Multi-Modal Knowledge Graph Construction andApplication: A Survey

摘要
近年来知识工程的兴起,其特征是知识图的快速发展。然而,现有的知识图大多用纯符号表示,这损害了机器理解真实世界的能力。知识图的多模态化是实现人级机器智能不可避免的关键步骤。这项工作的结果是多模态知识图(MMKGs)。本文首先给出了多模态任务的定义,然后对多模态任务和多模态技术进行了初步探讨。在此基础上,系统回顾了mmkg建设和应用面临的挑战、进展和机遇,并详细分析了不同解决方案的优缺点。我们用与mmkg相关的开放研究问题来完成这项调查。
1.介绍
近年来知识工程的兴起,其特征是知识图的快速发展。知识图本质上是一个大型语义网络,包含实体、概念作为节点,它们之间的各种语义关系作为边。知识图在文本理解、推荐系统和自然语言问答等广泛的现实应用中有着巨大的价值。创建了越来越多的知识图谱,涵盖常识知识(例如Cyc [1], ConceptNet[2]),词汇知识(例如WordNet [3], BabelNet[4]),百科知识(例如Freebase [5], DBpedia [6], YAGO [7], WikiData [8], CN-Dbpedia[9]),分类学知识(例如Probase[10])和地理知识(例如GeoNames[11])。
近年来,由于应用程序对多模态知识引导需求的快速增长,知识图谱的多模态化及其应用蓬勃发展。
但目前还缺乏对这一新兴领域的研究进展、挑战和机遇的系统综述。本文希望填补这一空白,系统地综述MMKG相关研究的最新进展:1)构建。mmkg的建设可以从两个相反的方向进行。一种是从图像到符号,即用KG为单位的符号标记图像;另一种是从符号到图像,即从KG中的接地符号到图像。在构建部分,我们将系统地介绍将各种符号知识(包括实体、概念、关系和事件)与它们对应的两个相反方向的图像相关联的挑战、进展和机遇。2)应用程序。mmkg的应用可以大致分为两类,一类是针对mmkg本身的质量或集成问题的In-MMKG应用,另一类是mmkg可以帮助的一般多模态任务out - mmkg应用。在应用部分,我们将介绍如何将mmkg应用于几个经过充分研究的多模式任务。
综上所述,我们是第一个对现有的由文本和图像组成的mmkg的工作进行全面调查的人。为了提升此次调查的价值,我们注重确保以下特点:1)全面调查。我们系统全面地回顾了MMKG建设和应用的现有工作。2)深刻的分析。我们分析了MMKG建设中不同解决方案的优缺点,并讨论了MMKG何在各种下游应用中发挥作用。3)显示的机会。我们不仅指出了MMKG建设的一些潜在机遇,还列出了MMKG未来的发展方向。
调查的其余部分组织如下:第二节给出了mmkg的定义和初步说明。第三节对mmkg建设的挑战、进展和机遇进行了全面回顾,而第四节则介绍了mmkg如何应用于一些经过充分研究的多模式应用中。第五部分回顾了MMKG的一些未决问题,并强调了有前景的未来方向。第6节最后对本文进行了总结。
2.定义和前提
本节首先定义了kg的两种表示方式,然后回顾了一些关于多模式任务和技术的初步介绍,然后讨论mmkg与现有多模式任务和技术之间的联系。
2.1MMKG的定义和表示

现有的mmkg研究工作主要采用两种不同的方法来表示mmkg。一种方法是将多模态数据(本次调查中的图像)作为实体或概念的特定属性值,如图1(a)所示。

另一种方法将多模态数据作为kg的实体,如图1(b)所示。


- 包含:一个图像实体在视觉上通过图像的相对位置包含另一个图像实体。
- 附近:一个图像实体在视觉上靠近另一个图像实体。
- sameAs:两个不同的图像实体指向同一个实体。
- 相似的:两个图像实体在视觉上彼此相似。
此外,在N-MMKGs中,图像通常被抽象为许多图像描述符,这些描述符通常被概括为图像实体在像素级的特征向量,如灰色直方图描述符(GHD)、定向梯度直方图描述符(HOG)、颜色布局描述符(CLD)等。例如,在表1b中,Eiffel Tower in Paris.jpg. hog是Paris.jpg中Eiffel Tower图像的描述符之一,并以矢量的形式存在。这些图像描述符被很好地解释,因此图像之间的关系可以通过简单的计算(例如。通过图像描述符向量的内积获得图像相似度)
表2列出了由文本和图像构建的主流MMKG的详细信息,包括MMKG类型、多模态知识、源资源、候选资源、质量控制、规模、每个实体的图像等。

2.2多模态技术的初步研究
MMKG的构建和应用与现有的计算机视觉(CV)多模态研究有很大关系。在此,我们简要地回顾了一些已有研究的多模态任务、多模态学习技术,以及多模态预训练语言模型的重要研究进展。
2.2.1Multi-Modal Tasks
一般来说,模态指的是某事物存在、经历或完成的特定方式。在计算机科学和人工智能中,如果一个问题涉及多模态数据,我们就说它具有多模态特征。为了从多模态数据[27]中获得知识或理解,多模态任务集成并建模了多种交际模式。下面列出了一些基于图像和文本的多模式任务示例:
Image Captioning:图像标题的目的是为给定的图像[28],[29]生成描述性标题。
Visual Grounding:视觉接地的目的是在给定的图像[30],[31]中找到具有指定描述的物体。
Visual Question Answering (VQA):VQA的目的是在相关图像[32],[33]的帮助下,为文本问题生成文本答案。
Cross-Modal Retrieval:有两种典型的跨模态检索任务,包括通过文本[34]、[35]搜索图像,以及通过图像[36]、[37]搜索文本。
2.2.2Multi-Modal Learning
多模态学习主要侧重于建模多模态之间的对应关系来理解多模态数据,面临以下一些基本挑战:
1)多模式表示。多模态表示利用多模态的潜在互补性来学习特征表示。现有的努力要么将多模态投射到一个具有VGG[39]、ResNet[40]的统一空间[38],要么在其自身的向量表达空间中表示每个单一模态,满足某些约束,如线性相关[41]。
2)多模态T翻译。多模式翻译学习从一种模式的源实例翻译到另一种模式的目标实例。基于实例的翻译模型通过字典[37],[42]在不同的模态之间建立起桥梁,而生成翻译模型则建立了一个更灵活的模型,可以将一个模态转换为另一个[43],[44]。
3)Multi-modal Alignment。多模态对齐旨在寻找不同模态之间的对应关系。它既可以直接应用于一些多模态任务如视觉接地,也可以作为多模态预训练语言模型[45]中的预训练任务。
4)多模式融合。多模态融合是指将来自不同模态的信息连接起来进行预测[27]的过程,其中运用门控跨模态注意[46]、自底向上注意[47]等各种注意机制,对跨模态模块中不同类型特征之间的相互作用进行建模
5) Multi-modal Co-Learning。多模态联合学习的目的是通过协同利用其他模态的资源来缓解某一模态的资源不足问题。
2.2.3多模态预训练语言模型
基于具有文本对的大规模无监督多模态数据集,最近的许多工作都在学习多模态预训练语言模型,其中包括一些设计好的自监督预训练任务,包括掩模语言模型、句子图像对齐、掩模区域标签分类、掩模区域特征回归、掩模对象预测等[45]。多模态预训练语言模型已经证明了它们在改进许多下游任务[48],[49],[50],[51],[52]方面的有效性。
根据基于transformer的不同模态融合过程,多模态预训练语言模型可分为单流模型和双流模型。单流模型,如VLBERT[53]和vit[50],将所有模态信息输入到单个Transformer编码器中,由自注意模块进行融合,并同时学习不同模态数据在同一编码器中的这些表示。两流模型,如LXMERT[54],将不同的模态信息输入到它们自己的编码器中,并通过一个额外的交叉注意模块将来自不同模态编码器的这些表示融合在一起。最终的输出表示不仅包含跨模态交互,而且还保留了每个模态中的交互。
2.3讨论
虽然已经有很多人在用多模态学习技术和多模态预训练语言模型来处理各种多模态任务,但引入多模态知识来帮助提高现有多模态任务的性能仍然是一个新兴的趋势。一般来说,mmkg可以从以下方面使这些下游任务受益。
MMKG提供了足够的背景知识来丰富实体和概念的表示,特别是对于长尾实体和概念。例如,引入辅助常识知识,增强图像和文本的表示能力,提高了图像-文本匹配[16]的性能。
MMKG使我们能够理解图像中看不见的物体。看不见的物体对基于统计的模型提出了巨大的挑战。符号知识通过提供关于不可见对象的符号信息或建立可见对象与不可见对象之间的语义关系来缓解这一困难。例如,使用外部符号知识来指导生成带有并行标题[55]的未见的新颖视觉对象的标题。
MMKG支持多模态推理。例如,构建OK-VQA数据集[56],其中只包含需要外部知识资源才能回答的问题,用于测试VQA模型的推理能力。
MMKG通常提供多模态数据作为附加特征,以弥合一些NLP任务中的信息鸿沟。以实体识别为例,一张图像可以提供足够的信息来识别“Rocky”是狗的名字还是人的名字[57]。
综上所述,在没有大规模MMKG的支持下,以往使用多模式信息的努力仍然是有限的。我们预计,当大规模高质量MMKG可用时,许多任务可以进一步改进。
3.构建
MMKG构建的实质是将传统KG中的符号知识,包括实体、概念、关系等,与它们对应的图像联系起来。完成该任务有两种相反的方法:(1)用KG单位的符号标记图像,(2)将KG单位的符号接地到图像上。我们分别在3.1节和3.2节阐述了两类解决方案
3.1 From Images to Symbols: Labeling Images
CV社区已经开发了许多图像标注解决方案,可以利用这些解决方案对带有KG知识符号的图像进行标注。大多数图像标记解决方案学习从图像内容到各种各样的标签集的映射,包括对象、场景、实体、属性、关系、事件和其他符号。学习过程由人工标注的数据集监督,这需要人群工作者绘制边界框,并对图像或图像的区域进行标注,如图2所示。
我们构建了一些著名的基于图像的视觉知识提取系统,如表2a所示,可以利用这些系统通过图像标记来构建MMKGs。根据被链接符号的类别,将图像与符号链接的过程可分为几个细分任务:视觉实体/概念提取(第3.1.1节)、视觉关系提取(第3.1.2节)和视觉事件提取(第3.1.3节)。
3.1.1可视化实体/概念提取
视觉实体(或概念)提取是对图像中的目标视觉对象进行检测和定位,然后用KG符号对这些目标视觉对象进行标记。
挑战:
这项任务的主要挑战在于如何在没有大规模的、细粒度的、注释良好的概念和实体图像数据集的情况下学习有效的细粒度提取模型。虽然CV中有丰富的标注良好的图像数据,但这些数据集几乎都是粗粒度的概念图像,不能满足MMKG构建对细粒度概念和实体的图像标注数据的要求。
进展:
现有的视觉实体/概念提取方法大致可分为两类:1)物体识别方法,通过对被检测物体的区域进行分类,对视觉实体/概念进行标记;2)视觉基础法,通过将标题中的单词或短语映射到最相关的区域,为一个视觉实体/概念贴上标签。
1) Object Recognition Methods:
在早期的工作中,用户和研究人员提供的图像通常比较简单,一张图像中只有一个物体,可以通过分类模型进行处理。但现实生活中的图像可能过于复杂,无法用一个标签来表示,因此我们需要给不同的视觉单元贴上不同的标签。
为了区分图像中的几个视觉实体,需要预先训练的检测器和分类器用它们在图像中的位置标记视觉实体(以及属性和场景)。这些检测器由监督数据训练,这些数据来自公共图像-文本数据集[20](如MSCOCO [62], Flickr30k [63], Flick30k Entities[64]和Open Images[65])或预标记的种子图像[19]。在检测期间,检测器捕获可能对象的一组区域建议,并挑出实际包含对象的建议。在各种检测器(如基于MTCNN的人脸检测器和基于fast - rcnn的车辆检测器)检测到的位置上,经过预先训练的分类器识别具有实体级(如BMW 320)或概念级(如Car)标签的候选视觉对象。
由于大量的重复,被识别的对象不被直接视为视觉实体。许多对象是相同实体在不同视点、位置、姿势和外观上的重复实例。因此,通过选择最具代表性的视觉对象来生成一个视觉实体。最常见的方法是将图像的6个区域聚类,其中每个聚类的中心被视为一个新的视觉实体[20]
监督解决方案的缺点很明显,它们只能生成有限数量的标签。如果自动标记解决方案要支持大量的标签(例如数十亿个实体),它需要大量的预处理工作,例如预定义的规则、预先确定的可识别实体列表、预先训练的细粒度检测器和分类器等,这降低了解决方案[20]的可伸缩性。
2) Visual Grounding Methods:
在视觉实体提取中,训练检测器需要大量带边界框的标记数据和固定概念集的预定义模式[66],难以用于大规模的视觉知识获取。幸运的是,网络上有大量的图片-标题对。新闻网站)对视觉知识的提取进行弱监督,而不依赖于标记的边界框。因此,视觉实体提取问题简化为一个开放域的视觉接地问题,其目的是定位标题中每个短语对应的图像区域,从而获得图像中带有标签的视觉对象。
在从弱监督图像-标题对中提取信息时,我们通常直接选择给定单词的活动像素作为基于空间热图的视觉对象区域(例如图3中的热图)。在同一语义空间中共享文本和图像表示的情况下,可以通过基于注意力的方法和基于显著性的方法作为跨模态权重来学习每个短语的热图,如图4所示。在训练时,基于显著性的方法直接将像素对给定短语的敏感度作为通过梯度计算得到的热图值。基于注意的方法将交叉模态相关性作为热图的值,这比基于显著性的方法更受欢迎。例如,GAIA[20]中的热图是根据标题中提到的每个实体的图像区域之间的相似度生成的,而[67]中的热图是根据图像区域之间的相似度和可能的事件参数角色类型生成的。在测试时,对热图进行阈值设置,以获得可视对象的合适边界框。如果在KGs中已有的视觉实体/概念的边界框与新的边界框没有重叠,则该边界框将被创建为新的视觉实体或概念。
 图3:GAIA[20]中单词Soldier和Boats的热图。像素和单词的相关性越高,像素的颜色就越温暖。
图3:GAIA[20]中单词Soldier和Boats的热图。像素和单词的相关性越高,像素的颜色就越温暖。
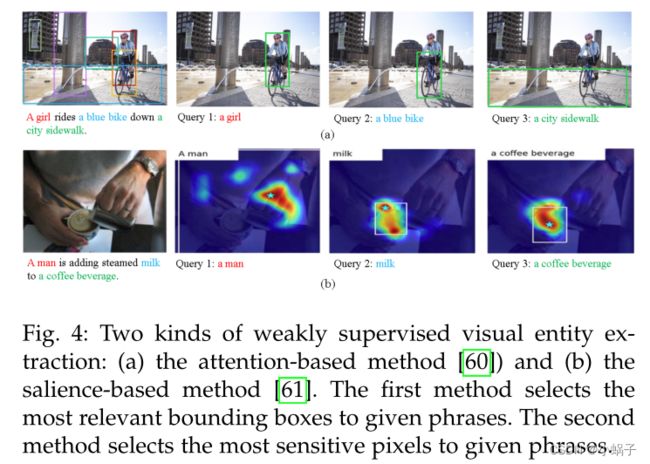 图4:两种弱监督视觉实体提取方法:(a)基于注意的方法[60])和(b)基于显著性的方法[61]。第一种方法选择与给定短语最相关的边界框。第二种方法选择对给定短语最敏感的像素。
图4:两种弱监督视觉实体提取方法:(a)基于注意的方法[60])和(b)基于显著性的方法[61]。第一种方法选择与给定短语最相关的边界框。第二种方法选择对给定短语最敏感的像素。
虽然面向开放域的视觉接地不依赖带边界框的标记数据,但在实际应用中,由于不匹配,仍然需要人工验证。一些努力试图在训练阶段增加对常见概念、关系和事件论点的约束,以增加监督信息。MMKG[20]施工相关工作中,目视接地精度小于70%。通过视觉基础定位的视觉对象可以是实体(如巴拉克·侯赛因·奥巴马)、概念(如地点、汽车、石头)、属性(如奥巴马)。(红色,短)。然而,图像和文本语义尺度的不一致可能导致不正确的匹配。例如,部队可能被映射为几个穿着军装的人,乌克兰(国家)可能被映射为乌克兰国旗,两者都是相关的,但并不等价。
机会:
随着2.3节中提到的多模态预训练语言模型的出现,强大的表示能力为提取公共实体和概念带来了更多机会。图像斑块与单词的映射可以直接在模型的自注意映射中可视化,无需额外的训练。ViLT[50]预测的一个例子如图5所示。事实证明,在数亿网络规模的图像-文本数据上训练的多模态预训练语言模型(如CLIP[68])在著名人物和地标建筑上具有很高的准确性[69],这将在构建MMKG人物或建筑时减少大量的数据收集和模型训练工作量。一些预先训练的视觉转换器模型已经具有很强的视觉对象分割能力,即使在高度模糊的情况下也会关注前景对象,如DINO[70],这将提高定位视觉对象和对齐跨模态知识的性能。
4.应用
在对MMKG建设进行系统回顾之后,本节将探讨MMKG中的知识如何应用于各种下游任务并使其受益。为了快速概述,表5列出了一些主流应用程序任务、它们的基准数据集以及mmkg带来的优势。我们将此类任务分为(i) kg内应用程序(第4.1节)和(ii) kg外应用程序(第4.2节),讨论如下。
4.1 In-MMKG Applications
In-MMKG应用程序是指在MMKG范围内执行的任务,其中已经学习了实体、概念和关系的嵌入。因此,在介绍MMKG内应用之前,我们简要介绍了MMKG中知识的分布式表示学习,也称为MMKG内嵌。
基本上,MMKG嵌入模型是由传统公斤嵌入模型,即基于距离模型[133],这考虑到实体和尾巴实体相同的三联体应该关闭在投影空间,和翻译模型,TransE[134]及其变异[135],[136],[137],它应当符合假设:t≈h + r·h t, r是分别的向量表示实体,尾巴三联体的实体和关系。在处理多模态数据时,还有两个额外的问题:如何有效地编码图像中所包含的视觉知识和信息,以及如何融合不同模态的知识。1)视觉编码器。尽管已有许多现成的CV图像信息编码技术,但随着深度学习的发展,卷积神经网络中的隐藏特征是MMKG表示中使用的主要图像嵌入方法[138]、[139]、[140],而其他显式的视觉特征如灰色直方图描述符(GHD)、定向梯度描述符直方图(HOG)、颜色布局描述符(CLD)等很难在MMKG表示中得到利用。2)知识融合。为了融合多模态的知识嵌入,人们考虑了多种融合方式,包括简单拼接、多模态嵌入的平均以及基于归一化或加权的奇异值分解(SVD)和主成分分析(PCA)[139]。有些方法[139]将融合结果直接作为MMKG嵌入,而另一些方法[140]则在设计良好的目标函数上进一步训练单模态表示。
接下来,我们将介绍四种深入研究的inMMKG应用,包括链路预测、三重分类、实体分类和实体对齐。
4.2 Out-of-MMKG Applications
KG外应用程序指的是下游应用程序,它们不受mmkg边界的限制,但可以由mmkg辅助。本文以多模态命名实体识别与实体链接、可视化问题解答、图像-文本匹配、多模态生成和多模态推荐系统等应用为例进行了介绍。我们没有对这些任务的所有解决方案进行系统的回顾,而是主要介绍如何使用mmkg。
4.2.1多模态实体识别与链接
基于纯文本的命名实体识别已经得到了广泛的研究。实体提及的模糊性和多样性一直是关键挑战。最近的研究考虑采用NER从图像所附文本中检测实体,定义为多模态NER (MNER)[57],[117],其中图像可以为实体识别提供必要的补充信息。MMKG在MNER中发挥着重要作用,它提供了描述不同类型实体的视觉特征,使得MNER模型能够更好地利用文本所附图像的视觉特征进行实体识别。例如,[149]提出在mmkg中使用图像的背景知识来帮助捕获图像的深层特征,以避免来自浅特征的错误。
给定一个带有图像的文本,多模态实体链接(MEL)使用文本和视觉信息将文本中的模糊提及映射到知识库(KB)中的实体[150]。尽管一些早期的工作将MEL基于传统的KG作为知识库,但最近越来越多的工作倾向于使用mmkg作为链接的知识库。MEL以两种方式利用MMKG中的图像知识:(1)提供实体提及的应链接到的目标实体;(2)利用多模态数据学习每个实体的分布式表示,然后用它来度量提及与实体之间的相关性。使用图像的视觉信息有助于捕捉提及和实体之间的关系[150],[151],但与图像无关的部分也可能成为噪声,对提及和实体的表示学习都带来负面影响。为了消除副作用,提出了一种基于预定义阈值的两阶段图像和文本相关机制来过滤无关图像,并利用多重注意机制通过查询提及候选实体周围的多跳实体来捕获提及表示和实体表示中的重要信息[118]。
4.2.2 Visual Question Answering
视觉答题(Visual question answer, VQA)是一项具有挑战性的任务,不仅需要对问题进行准确的语义解析,还需要对给定图像中不同物体和场景之间的相关性进行深入理解。在大多数近期的VQA基准数据集中,如GQA[119]、OK-VQA[56]和KVQA[121],很多问题都需要结合外部知识进行视觉推理。新提出的VQA任务弥合了人类可以很容易地结合来自不同模式的知识来回答视觉查询的差异。例如,在“哪个美国总统与这里看到的毛绒玩具有关?”,如果检测出图像中的毛绒玩具是“泰迪熊”,通过KG推断出的答案将是“西奥多·罗斯福”,他通常被称为“Teddy Roosevelt”,泰迪熊因此被命名为[56]
提取视觉概念之间的关系和理解问题中的语义信息是VQA的两个关键问题。然而,如果不结合更多关于各种模态的知识,它就无法通过语义解析和匹配,仅对图像-问题-回答三元组进行推理,也难以推广到更复杂的情况[122]。MMKG有助于解决问题,提高答案的可解释性。首先,MMKG提供了关于已命名实体及其在图像中的关系的知识,这将导致更深入的视觉内容理解。其次,MMKG中结构化的符号知识使其能够更明确地进行推理过程和预测最终答案。
最近的一些努力[152]将不同的KGs与不同种类的VQA知识相结合,包括单模KGs,如DBpedia[6]、ConceptNet[2]和hasPart KB[153]用于分类和常识知识,以及MMKG可视化基因组[59]用于可视化数据。MMKG中的视觉符号信息以图结构的信息传递视觉概念之间的关系,为通过图网络推理问题提供了有力的证据。此外,MMKG中保存的显式语义知识有助于精炼答案,使其更具解释性和通用性[154]。MMKG保存并统一了不同模态的表征,极大地有利于跨模态的关系推理。