MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based VQA 论文阅读 From CVPR 2022
MuKEA:基于视觉问答(VQA)的多模态知识抽取与积累
论文下载:https://arxiv.org/abs/2203.09138
github代码:https://github.com/AndersonStra/MuKEA
一、研究背景
结合外部知识的VQA任务( Knowledge based VQA)需要AI能够利用到超出输入图像、问题之外的额外知识。近年来,尽管一些KB-VQA的方法取得了一定成果,但离像人类一样利用知识的能力仍相去甚远。
外部知识能够辅助AI进行知识推理,从而得到更为准确的答案。何在跨模态场景中有效的表征和利用知识是KB-VQA的核心问题。当前许多方法的问题在于只利用了文本相关的的知识库,例如ConceptNet和DBpedia,而对于视觉知识、高阶谓词表达的知识利用较少。这导致在一些研究在利用结构化知识图谱/半结构化知识库的方法中,尽管数据是高质量的知识,也有大规模的人工标注,但其中的信息被限制在定义好的,能被自然语言或一阶谓词(first-order predicate)的所描述的三元组中,因此这些知识库很难表征高阶谓词(high-orderd predicate)和多模态知识。

例如在图中,通过外部的知识图谱(a)能够得到摩托车的结构信息(first-order predicate),但当问题问到“摩托车是什么牌子”,这类需要结合图片中摩托车图标,才能回答出KAWASAKI的知识(high-orderd predicate),利用结构化知识图谱就会出错。再例如,通过视觉场景(b),人类能够判断场景的地点在伦敦,而通过知识图谱很难判断。如何抽取和积累这些多模态知识,并且同时发挥到传统知识图谱知识推理的优点,是很重要的
现有的模型框架大都基于一个“retrive and read” 的流程:
- 首先,在知识库中搜寻与question实体相关的facts,然后直接在知识图谱上进行推理;
- 或者是将知识图谱含有隐式知识的embedding与图像和问题的embedding进行fusion后再分类出一个answer,这样的流程依赖图像识别的object label准确度,又通过label在知识库中检索相关实体,不可避免地会导致级联误差传播。
- 还有基于隐式知识的端到端的模型,但这样的方法往往只捕获到image-question-answer的共现关系(co-occurence),而非更高级的知识。
作者主要的工作有:
- 提出了一个end-to-end的多模态知识表征学习框架:用三元组的形式将不可表达的多模态知识建模,再利用现有的知识库提供补充的知识
- 探索了域内(in-domain)和域外(out-domain)知识积累的预训练-微调策略,能够自动进行知识积累和答案预测,摆脱了“retrive and read”的模式,从而避免了误差级联传播
- 在两个经典的KB-VQA数据集:OK-VQA, KRVQA上超越了当前SOTA
二、模型框架
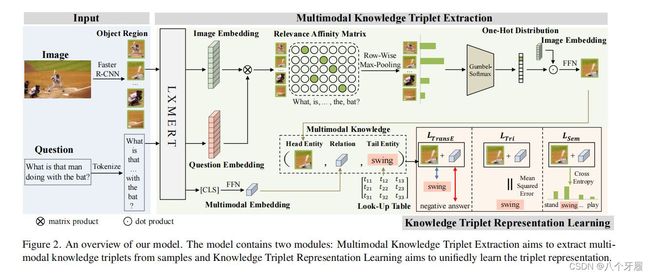
输入图像 I I I ,问题 q q q,抽取三元组形式 ( h , r , t ) (h,r,t) (h,r,t)的多模态知识,头实体 ( h ) (h) (h)为基于问题关注的图片内容, r r r为其和问题的隐式关系,尾实体 ( t ) (t) (t)为答案,端到端地进行知识推理。
图像和问题编码
预训练的Vision-Language模型能够对不同模态的模态间(intra-model)和跨模态(cross-model)隐式关系很好地建模,所以使用了预训练模型对图像和问题进行编码。
对于图像 I I I,用预训练模型 F a s t e r R − C N N Faster R-CNN FasterR−CNN 进行目标检测,得到预选的objects,每张图检测 K = 36 K=36 K=36 个,每个 object 由视觉特征向量 f f f(维度 d f = 2048 df=2048 df=2048)和空间特征向量 b b b(维度 d b = 4 db=4 db=4)表示
对于问题 q q q 用预训练的 W o r d P i e c e WordPiece WordPiece 对其token化,得到 D D D 个token
然后将 f f f, b b b, t o k e n token token 一同送入预训练的Vison-Language模型 L X M E R T LXMERT LXMERT,得到所有检测目标(objects)的 image embedding V (Kxdv,dv=768),和问题的 token embedding Q(Dxdv)
头实体抽取
头实体定义为: 与question最相关的object。首先通过余弦点积计算每个object embedding与每个token embedding 的相似度,得到相似度矩阵 A A A,其中 W 1 W1 W1 、 W 2 W2 W2 为可学习权重
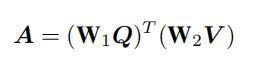
然后选出与问题最相关的objects。首先对 A A A 中的每一行做maxpoolin,得到object对整个问题的相似度。
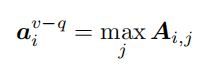
值得注意的是,由于 L X M E R T LXMERT LXMERT 预训练模型对图像中 objects 之间的隐式关系很好地进行了建模,所以所选出来的object embedding是蕴含了视觉上下文语义的,这对VQA任务来说是很好的线索。
然后基于 a v − q a^{v-q} av−q 使用hard attetion而不是soft attention选出头实体。Hard attention为多模态表征提供了更为稳定和可解释的视觉内容,并且更有助于通过实体链接来结合现有的知识图谱。
这里使用了 G u m b e l − s o f t m a x Gumbel-softmax Gumbel−softmax,得到one-hot的类别分布,每个object的attetion权重计算如下,其中 g i g_i gi是从 G u m b e l ( 0 , 1 ) Gumbel(0,1) Gumbel(0,1)分布中独立同分布(i.i.d)采样的:
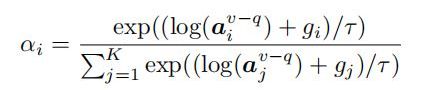
最后每个object 的表征 v i v_i vi 结合attention 权重 α i α_i αi 经过前馈网络后得到头实体的表征 h h h
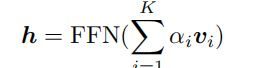
关系抽取
不同于一般的,关系描述为first-order predicate的知识图谱,文章定义的多模态知识三元组中的关系是一种复杂的隐式关系(implicit relation),对应了观察到的视觉特征和问题特征之间的关系。
由于 L X M E R T LXMERT LXMERT通过分层的transfomer捕获了vision 和question的隐式关系,于是将最后一层的CLS token取出,再经过FFN,作为关系的表征 r r r。
尾实体抽取
将查询得到的answer作为尾实体。
- 训练阶段,用ground truth 的answer训练尾实体的表征 t t t
- 推理阶段,将KB-VQA任务定义为多模态知识图谱补全问题,全局地在我们的神经多模态知识库中预测尾实体作为answer
训练方法
由于三元组的每个部分都包含了不同模态的、复杂语义的信息,文章首先用知识库中的answer维护了一个随机初始化的查找表(look-up table),查找表中包含了groud truth 的answer以及错误的answer作为负样本,其次定义了三个 l o s s loss loss 来弥合异质性语义间隙:

- TripleTransE,作为知识结构性保持约束,对正样本和负样本的loss,具体结构为triple loss
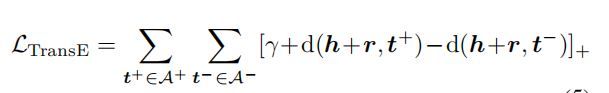
- Triple consistency,transE的问题在于,一旦正样本对的距离比负样本对之间的距离小 γ γ γ(margin)时,模型会停止训练。为了让三元组embedding更好地拟合严格的知识图谱拓扑关系,定义了MSE形式的loss:

- Sematic consistency,训练模型选出查找表 T T T 中的ground truth answer,采用 cross entropy:
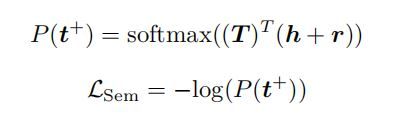
最后三种loss相加进行训练

知识积累与预测
文章通过两个步骤来逐步地进行知识积累
- 在VQA2.0数据集上进行预训练,积累基础视觉领域的知识
- 在下游KB-VQA任务数据上进行微调,积累更复杂的特定领域的多模态知识
推理阶段,将answer prediction视作是多模态知识图谱补全任务:输入image与question,得到二者的embedding,将两者相加得到隐式的answer向量 t t t,再在查找表 T T T中搜索与之距离最相近的尾实体向量,对应的尾实体便是推理出的answer。

三、实验
数据集:
- OK-VQA:包含14000个问题,涵盖了10种知识类别。所有问题都是人工标注的,所以没有固定的问题模板或知识库,这正需要探索广泛的开放的知识资源。
- KRVQA,KRVQA是迄今为止最大的基于知识的VQA数据集。 它能够评估进行模型基于外部知识的多步推理能力。为了进行公平比较,用top-1准确度进行评估
OK-VQA:
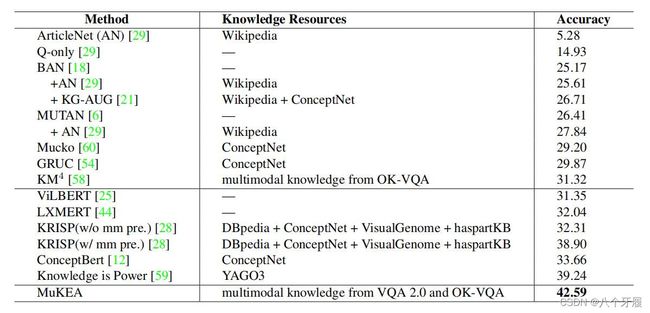
模型超过了在外部知识库上进行 “retrive and read” 的方法,作者推测是MuKEA避免了误差的级联传播;也超过了隐式知识预训练的SOTA模型,例如KM4,作者推测是MuKEA捕获到了多模态的高阶谓词的知识。
KRVQA:

实验分为俩部分,需要结合外部知识的问题(KB-related)和不需要外部知识的(KB-not-related)。有趣的是,在 KB-not-related 的实验结果上,MuKEA仍然超出了其他模型的表现,作者分析这类视觉主导的问题也需要桥接起 low-level 的视觉内容 和 high-level 的语义内容,才会获得更好的结果。