特征点检测与匹配相关论文梳理(持续更新)
前言
按时间先后梳理一下特征点检测与匹配相关的深度学习论文,arXiv 的时间为第一稿提交时间。
这些论文大多数写了单独的详解,但有些杂乱,并补充了一些需要深入看代码的细节。本文将对每一篇论文用简介、网络结构、损失三个部分来概括,其中简介部分包含核心创新点及个人理解;网络结构部分包含整个输入到输出的过程;损失包含数据集、训练等细节。
应用领域:
特征点检测与匹配的目的是得到两幅图像的对应关系,这是许多更复杂的视觉任务的关键步骤:三维重建(3D reconstruction)、SfM(Structure-from-Motion,一种三维重建方法)、视觉定位(visual localisation)、即时定位与地图构建(Simultaneous Localization and Mapping,SLAM,一边绘制陌生环境地图一边导航,如扫地机器人)、相机运动估计(camera motion estimation)、姿态估计(pose estimation)等。
任务简介:
传统方法通常将这个任务分为两个部分:检测和匹配。检测是从图像中提取出特征点的位置和描述符,位置为 ( x , y ) (x,y) (x,y) 坐标,描述符为 n n n 维特征向量。匹配是根据两幅图像检测到特征点计算匹配结果,并且会排除异常值,也就是筛掉错误的匹配结果。
这使得深度学习方法的任务有所不同:
(1)只做检测:输入一幅图像,输出特征点坐标及其描述符。
(2)只做匹配:输入特征点坐标及其描述符,输出匹配结果。相关论文只看了 SuperGlue,已经和图像相关任务大不相同,其输入已经脱离了原始的图像信息,而且其最终的匹配效果比较依赖检测的结果。
(3)检测+匹配:输入一对图像,输出匹配结果。也就是做成 end-to-end,但因为在测试时也涉及计算大量特征相似度,开销会比较大。
目前,针对不同的训练数据,模型的训练方式大致分为两种,个人将其称为强监督和弱监督(和传统意义的有所不同)。不管是哪一种方式,训练集一般都会想方设法得到一对图像的匹配关系,有了匹配关系自然可以训练特征向量相似,从而得到描述符;而他们的不同就在于特征点位置,强监督通过一些办法在原始图像上就标注出特征点的位置,所以像强监督一样学习就行了;弱监督的特征点位置是未知的,通过设定一些规则和网络中间的输出得到特征点。
论文
1. SuperPoint(2018 CVPR)
arXiv:2017.12.20
标题:SuperPoint: Self-Supervised Interest Point Detection and Description
任务:检测
论文地址
代码地址
博客地址
简介:
目前看到唯一使用自监督训练的方法。个人理解自监督就是先人工生成一批数据,这些数据通常不自然,但是标签准确。在这个人工数据上训练后,模型可以在真正的自然图像上得到结果。通过一些方法(传统算法,先验知识,已有模型等)优化这个结果作为标签来迭代训练模型。
因为简单几何结构的特征点非常明确,所以用它们作为第一批种子数据训练模型,然后在真实图像上结合 Homographic Adaptation 的策略不断迭代。
网络结构:
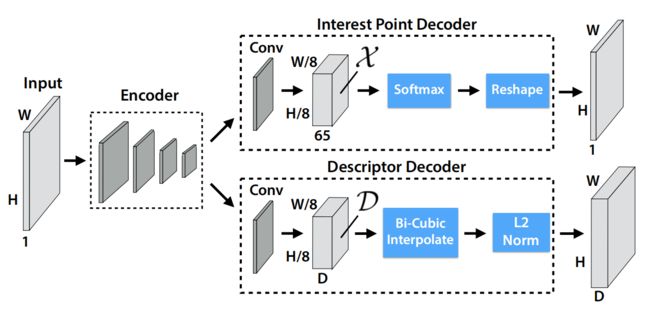
输入一幅图像,先是一个特征提取网络,然后接两个分支。一个分支卷积后用 softmax 得到得分图,用 NMS 可以得到特征点的坐标和置信度。另一个分支卷积后用 L2-Norm 得到特征图,特征点对应的特征向量为描述符。
损失:
自监督训练起来和强监督一样,可以用常见的损失。特征点坐标用交叉熵损失,描述符用 hinge loss。
2. NC-Net(2018 NIPS)
arXiv:2018.10.24
标题:Neighbourhood Consensus Networks
任务:检测 + 匹配
论文和代码地址
博客地址
简介:
较早的 end-to-end 模型,也就是检测与匹配一起完成。核心创新是使用了 4D 卷积。
网络结构:
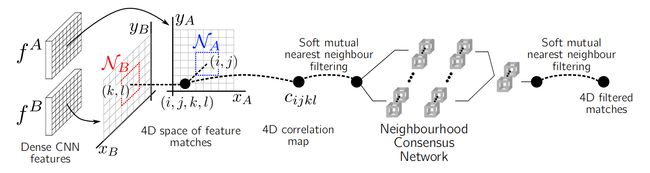
输入一对图像 I A , I B I_A,I_B IA,IB
(1)经过特征提取网络得到两幅特征图 f A ( b , d , h A , w A ) , f B ( b , d , h B , w B ) f^A(b,d,h_A,w_A),f^B(b,d,h_B,w_B) fA(b,d,hA,wA),fB(b,d,hB,wB)
(2)计算全局相似度,得到相似度张量 ( b , 1 , h A , w A , h B , w B ) (b,1,h_A,w_A,h_B,w_B) (b,1,hA,wA,hB,wB)
(3)soft mutual nearest neighbour filtering,给相似度乘上一个系数,系数具体计算方式见博客,大致就是 c ∗ ( c / c a m a x ) ∗ ( c / c b m a x ) c*(c / c_{a_{max}}) * (c / c_{b_{max}}) c∗(c/camax)∗(c/cbmax), c c c 是两个点的相似度, c a m a x c_{a_{max}} camax 是另一幅图中所有点与 a 的相似度的最大值。
(4)neighbourhood consensus network,由3个 4D 卷积组成的网络,用来过滤匹配
(5)soft mutual nearest neighbour filtering,再来一次得到最终的相似度张量,也就是匹配结果
损失:
采用弱监督损失,只知道两幅图像是否是能够匹配的一对图像。利用相似度张量和 softmax 可以得到匹配结果和匹配得分,当两幅图像可以匹配时最大化匹配得分,反之最小化匹配得分。
3. D2-Net(2019 CVPR)
arXiv:2019.05.09
标题:D2-Net: A Trainable CNN for Joint Description and Detection of Local Features
任务:检测
论文地址
代码地址
博客地址
简介:
D2-Net 用 MegaDepth 作为训练集,通过图像的深度信息可以得到图像对之间的部分像素级对应关系。有了图像对的像素级对应关系,可以比较容易地训练网络使提取的特征可以正确匹配,特征自然就是描述符,剩下的问题就是确定哪些特征可以作为特征点。
判定特征点的规则参考了传统算法,网络提取的特征图为 ( b , d , h , w ) (b,d,h,w) (b,d,h,w),也就是每个像素都用一个 d d d 维的特征向量表示。这里设计了两个得分:
(1)通道得分,就是这个 d d d 维向量的每个值除以向量中的最大值
(2)局部得分,就是 d d d 维向量的每个值与其周围的 n × n n\times n n×n 个特征值算 softmax
这两个得分相乘就代表了特征向量中每个特征值的得分,从而构成得分向量;得分向量中的最大值代表了这个像素的得分,从而构成图像的得分图。得分图中每个得分在总分中的占比决定了该像素是否为特征点。
网络结构:
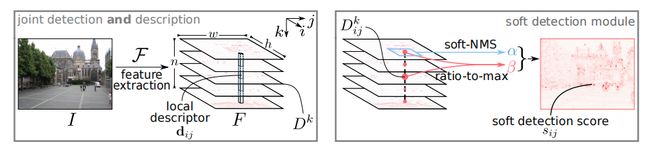
用 VGG16 做特征提取网络,后面就是个计算得分图的自定义计算。
损失:
对于一对匹配点,损失是最小化它们的特征向量差异,并最大化一定范围以外与其特征差异最小的特征之间的差异。将这个损失乘上其得分在所有匹配点得分中的占比作为最终的损失。
4. R2D2(2019 NIPS)
arXiv:2019.06.14
标题:R2D2: Repeatable and Reliable Detector and Descriptor
任务:检测
论文地址
代码地址
博客地址
简介:
针对 D2-Net 的改进,提出了两个概念重复性和可靠性。重复性代表一个特征点在一幅图像中能检测出来,在另一幅图像中也要能检测出来;可靠性代表特征点的描述符能正确匹配上。之前的方法着重于重复性而忽略了可靠性,主要针对重复纹理的特征点(树叶、大楼窗户、海浪等),虽然特征明显但是特征相似度高,容易造成错误的匹配。
网络结构:
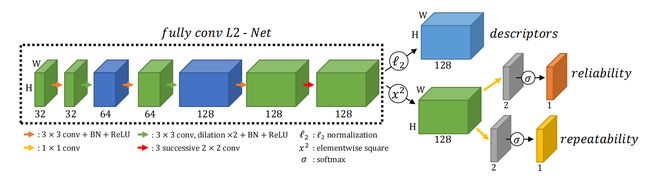
用 L2-Net 作为特征提取网络,并把其中下采样的地方用扩展卷积替代,使每个阶段的特征图都保持原图分辨率。
得到的特征图后面有两个分支,第一个做一个 L2-Norm 作为描述符,第二个先做一个平方计算,然后再有两个分支。这两个分支结构一样,先用 1 × 1 1 \times 1 1×1 卷积将特征维度降到 2,再用 softmax 计算得到得分图。一个得分图为重复性得分(检测得分),另一个为可靠性得分(特征得分)。
回看博客发现缺失了如何从这两个得分确定是否为特征点的细节,这里自定义了一个 NMS,具体效果是当某个像素的重复性得分在局部范围内最大,且两个得分都超过设定的阈值就认为是特征点。另外 softmax 的输出按理输入维度是2,输出维度也是2,这里其实是只取了维度为1的值,所谓的得分也就是做了个二分类,这也是为什么要用 1 × 1 1 \times 1 1×1 卷积将特征维度降到 2。
损失:
训练数据是用自定义的单应性变换和颜色变换生成的图像对,以及通过一些方法计算光流的图像对,总之有图像对之间的像素级对应关系作为 ground truth。
损失分为两个部分,重复性损失和可靠性损失,对应两个得分图:
(1)重复性损失
先根据标签把两个重复性得分对齐,理论上对齐后的得分图应该是很相似的。做法是把得分图按 N × N N \times N N×N 的大小划分成多个可重叠的 patches,最大化每个对应的 patches 得分的余弦相似度。同时为了不让得分都相同,加了个正则化项,最大化每个 patches 得分的最大值与平均值的差。
(2)可靠性损失
论文中的公式应该是写错了,按照代码的公式为 l o s s = 1 − a p ∗ r e l − ( 1 − r e l ) ∗ 0.5 loss = 1 - ap*rel - (1-rel)*0.5 loss=1−ap∗rel−(1−rel)∗0.5,其中 a p ap ap 是平均精度,具体计算的代码有点复杂没看完,按论文描述大概就是算以一个像素为中心的局部区域匹配结果的准确度; r e l rel rel 为该像素的可靠性得分。也就是说当 a p < 0.5 ap<0.5 ap<0.5 时得分应该降低,反之得分提高。
这个损失的设计使得模型能够得到想要的可靠性,因为即使一个特征点特征明显,重复性得分高,但匹配困难就会降低可靠性得分,这样就可以在综合得分时让重复性次优的特征点作为最终检测到的点。
5. ASLFeat(2020 CVPR)
arXiv:2020.03.23
标题:ASLFeat: Learning Local Features of Accurate Shape and Localization
任务:检测
论文地址
代码地址
博客地址
简介:
这篇论文感觉偏向刷指标,在 D2-Net 的基础上做改进,有效使用了一些现有的方法:
(1)用了 DCN 卷积,也就是卷积的采样点并不是方方正正的 3 × 3 3\times3 3×3,而有一定的自由度,可以适应图像的视角变化、几何变换,并且对这个自由度做了合理的几何约束,提高了性能;
(2)多尺度融合,这里融合的方法与常见的特征融合做预测不同,是多个层级都预测得分图后,将多个得分图加权求和做融合;
(3)略微修改了检测得分的定义,D2-Net 用的是占最大值的比例和 softmax,这里参考 R2D2 中的峰值思想全都改成了与均值的差异。
网络结构:

特征提取网络是 L2-Net,做了一些改动,具体细节没有太多意思,主要就是实现简介中的改进。
损失:
训练数据是通过深度信息获取的 ground truth,也就是有像素级的对应关系。损失和 D2-Net 的目的一样,只是具体公式做了些改动。
6. Sparse-NCNet(2020 ECCV)
arXiv:2020.04.22
标题:Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
任务:检测 + 匹配
论文地址
代码地址
简介:
针对 NC-Net 的改进,速度提高10倍以上,内存消耗降低20倍以上,且不降低性能。代码中构建网络用了很多 MinkowskiEngine,暂不细看。
网络结构:

(1) f A = F ( I A ) , f B = F ( I B ) f^{A}=F\left(I^{A}\right), f^{B}=F\left(I^{B}\right) fA=F(IA),fB=F(IB)
输入一对图像 I A , I B I_A,I_B IA,IB,经过特征提取网络得到两幅特征图 f A ( b , d , h A , w A ) , f B ( b , d , h B , w B ) f^A(b,d,h_A,w_A),f^B(b,d,h_B,w_B) fA(b,d,hA,wA),fB(b,d,hB,wB)
(2) c i j k l A → B = { ⟨ f i j : A , f k l : B ⟩ if f k l : B within K-NN of f i j : A 0 otherwise c_{i j k l}^{A \rightarrow B}=\left\{\begin{array}{ll} \left\langle f_{i j:}^{A}, f_{k l:}^{B}\right\rangle & \text { if } f_{k l:}^{B} \text { within K-NN of } f_{i j:}^{A} \\ 0 & \text { otherwise } \end{array}\right. cijklA→B={⟨fij:A,fkl:B⟩0 if fkl:B within K-NN of fij:A otherwise , c A B = c A → B + c B → A c^{A B}=c^{A \rightarrow B}+c^{B \rightarrow A} cAB=cA→B+cB→A
计算稀疏相似度张量,与 NC-Net 计算全局相似度张量不同,Sparse-NCNet 只保留每个像素相似度前 K 个结果,也就是从 h × w × h × w h \times w \times h \times w h×w×h×w 至少降到 h × w × K × 2 h \times w \times K \times 2 h×w×K×2
(3) c ~ A B = N ^ ( c A B ) \tilde{c}^{A B}=\hat{N}\left(c^{A B}\right) c~AB=N^(cAB), N ^ ( c A B ) = N ( c A B ) + ( N ( ( c A B ) T ) ) T \hat{N}\left(c^{A B}\right)=N\left(c^{A B}\right)+\left(N\left(\left(c^{A B}\right)^{T}\right)\right)^{T} N^(cAB)=N(cAB)+(N((cAB)T))T
N ( ⋅ ) N(\cdot) N(⋅) 为4D卷积,输入图像的顺序不影响输出结果
(4) ( ( i , j ) , ( k , l ) ) a match if { ( i , j ) = argmax ( a , b ) c ~ a b k l A B , or ( k , l ) = argmax ( c , d ) c ~ i j c d A B ((i, j),(k, l)) \text { a match if }\left\{\begin{array}{l} (i, j)=\underset{(a, b)}{\operatorname{argmax}} \tilde{c}_{a b k l}^{A B}, \text { or } \\ (k, l)=\underset{(c, d)}{\operatorname{argmax}} \tilde{c}_{i j c d}^{A B} \end{array}\right. ((i,j),(k,l)) a match if ⎩⎪⎨⎪⎧(i,j)=(a,b)argmaxc~abklAB, or (k,l)=(c,d)argmaxc~ijcdAB
NC-Net 中的 soft mutual nearest neighbour filtering 对稀疏张量的效果不明显,就用了 argmax 来计算输出匹配(按照惯例总感觉公式中的 or 应该是 and,暂时没根据代码验证)。
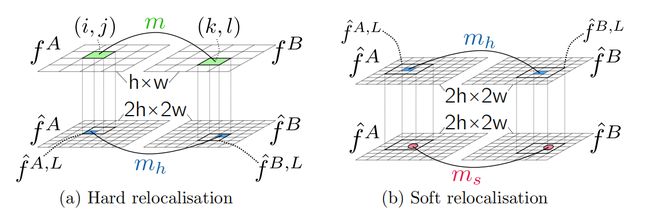
另外,论文中设计了一个 Two-stage relocalisation module 来提高匹配精度。先把图像上采样2倍提取特征得到细特征 f ^ : 2 h × 2 w \hat{f}:2h \times 2w f^:2h×2w,细特征用 max-pooling 下采样得到粗特征 f : h × w f:h \times w f:h×w。粗特征经过之前的步骤得到匹配 ( i , j , k , l ) (i,j,k,l) (i,j,k,l),每个像素在细特征图上对应 2 × 2 2\times2 2×2的区域,于是通过(a)步骤细化为蓝色的匹配(大致就是8个特征里面最匹配的两个);(b)步骤进一步细化,对蓝色匹配为中心的 3 × 3 3\times3 3×3 区域计算 softargmax,计算坐标的偏移量,从而得到最终的匹配结果。
损失:
按 NC-Net 的方法训练网络。
7. DualRC-Net(2020 NIPS)
arXiv:无
标题:Dual-Resolution Correspondence Networks
任务:检测 + 匹配
论文地址
代码地址
博客地址
简介:
在 NC-Net 的基础上做的改进,基本就是以 NC-Net 的输出在更高分辨率的特征图上再做一次匹配,得到更精细的匹配结果。
网络结构:
先按照 NC-Net 的流程得到一个匹配得分图,挑出一些 I a I_a Ia 得分高的点在高分辨率特征图上再做一次匹配,并把两个匹配得分结合起来得到与其匹配的 I b I_b Ib 点;再把这些 I b I_b Ib 上的点按相同流程做一次匹配,保留相同的匹配结果再按匹配得分得到最终结果。有点绕,具体细节见博客。
损失:
数据集提供两幅图像的稀疏对应点集,也就是 n n n 对点。训练的时候提取出这些点与另一幅图所有点的匹配得分,根据 ground truth 可以生成一个 one-hot 向量与匹配得分做 MSE,事实上就是当分类问题,具体细节还是看博客。
8. Patch2Pix(2021 CVPR)
arXiv:2020.12.03
标题:Patch2Pix: Epipolar-Guided Pixel-Level Correspondences
任务:检测 + 匹配
论文地址
代码地址
博客地址
简介:
Patch2Pix 是在现有匹配结果的基础上进一步细化的模块,利用初步的匹配结果和不同层级的特征图,结合了一些目标检测的思想,使匹配更精准并排除错误匹配。
网络结构:
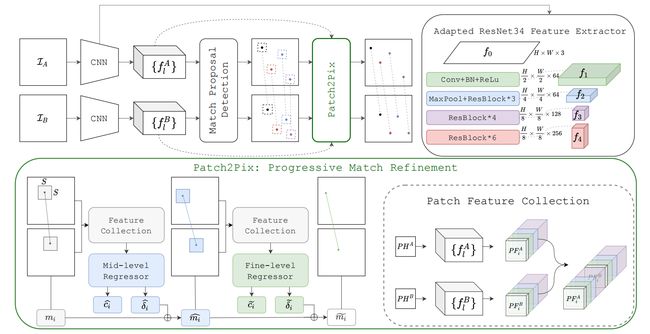
输入一对图像,用 ResNet-34 提取特征,将 f 4 f_4 f4 输入到 NC-Net 的匹配层中得到最初的 patch-level 匹配结果,并将每一对匹配扩充为8对匹配来增加搜索范围,具体扩充方式见博客。之后对于每一对匹配,把2个点的特征图拼接到一起输入细化网络。每个点具体特征图的获取方式是将 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3 上采样至原图分辨率,然后以该点为中心取 f 0 , f 1 , f 2 , f 3 f_0,f_1,f_2,f_3 f0,f1,f2,f3 上 16 × 16 16\times16 16×16 大小的特征图拼接到一起,特征图并非是线性插值的上采样,而是每个特征对应的感受野取相同的值。
细化网络的输入为2个 ( N , 3 + 64 + 64 + 128 , 16 , 16 ) (N,3+64+64+128,16,16) (N,3+64+64+128,16,16) 的特征,先把2个特征拼到一起 ( N , 518 , 16 , 16 ) (N,518,16,16) (N,518,16,16),输入到一个卷积网络,输出 ( N , 512 , 1 , 1 ) (N,512,1,1) (N,512,1,1),然后输入到全连接网络,输出 ( N , 5 ) (N,5) (N,5)。前四个对应两个点坐标的偏移量,最后是置信度,从而得到 mid-level 的匹配结果和置信度。将 mid-level 的匹配结果再做一次同样的流程,得到 fine-level 的匹配结果和置信度。这边两个 level 的细化网络结构完全相同,代码中给出了共享参数的接口,但是作者没有用,不共享的精度应该更高。
卷积网络结构:
(0): Conv2d(518, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): MaxPool2d(kernel_size=8, stride=8, padding=0, dilation=1, ceil_mode=False)
全连接网络结构:
(0): Linear(in_features=512, out_features=512, bias=True)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Linear(in_features=512, out_features=256, bias=True)
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=5, bias=True)
损失:
损失分为两个部分,公式和一些加权项不重复了,详细见博客:
(1)分类损失
针对输出的两个置信度,用几何误差的阈值划分正负样本然后计算交叉熵作为损失。这里的 mid-level 计算的是 patch-level 的几何误差,同样 fine-level 的置信度计算 mid-level 的几何误差。也就是说这里的置信度是评估的上一级的匹配结果。
(2)对极损失
patch-level 的结果为正样本的 mid-level 的几何误差加上 mid-level 的结果为正样本的 fine-level 的几何误差。