Python数据处理笔记04--pandas常用方法
Python数据处理笔记01--numpy数组操作
Python数据处理笔记02--numpy矩阵操作
Python数据处理笔记03--pandas数据结构
声明:本文环境为Windows10+Google Browser+jupyter notebook ,长文预警
一、数据读取与写入
二、描述性统计方法
三、迭代与遍历
四、排序
五、缺失值处理
一、数据读取与写入
- Pandas支持常用的文本格式数据(csv、json、html、剪切板)、二进制数据(excel、hdf5格式、Feather格式、Parquet格式、Msgpack、State、SAS、pkl)、SQL数据(SQL、谷歌BigQuery云数据)等。
- 一般情况下,读取文件的方法以pd.read_开头,而写入文件的方法以pd.to_开头
| 数据类型 | 描述符 | 读方法 | 写方法 |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_csv | to_csv |
| text | 剪切板 | read_clipboard | to_clipboard |
| 二进制 | Excel | read_excel | to_excel |
| 二进制 | HDF5 | read_hdf | to_hdf |
| 二进制 | PKL | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
下面来结合实例看一下:
# 示例1,读入剪切板数据,写入csv,转换为json、html、excel等格式
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
# 粘贴板内容,复制前先把注释符去掉
# A B C
# x*1 4 p
# y*2 5 q
# z*3 6 r
# 从剪切板读取数据
df1 = pd.read_clipboard()
# 把数据放入到粘贴板中,数据可以直接粘贴到excel文件中
df1.to_clipboard()
# 读写csv文件,可以取消index
df1.to_csv('df1.csv')
df1.to_csv('df1_noIndex.csv',index=False)
# 转化为json格式
df1.to_json('df1.json')
# 转化为html格式
df1.to_html('df1.html')
# 转化为excel格式
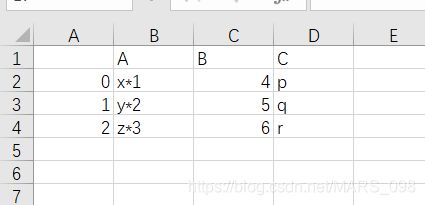
df1.to_excel('df1.xlsx')第一步:我们复制的是上面实例中粘贴板的内容,复制前把前面的#去掉(jupyter notebook快捷键Ctrl+/可同时对多行进行注释或解注释),新建一个excel工作表,粘贴复制内容(注意:粘贴之前要运行一下代码),是这样的
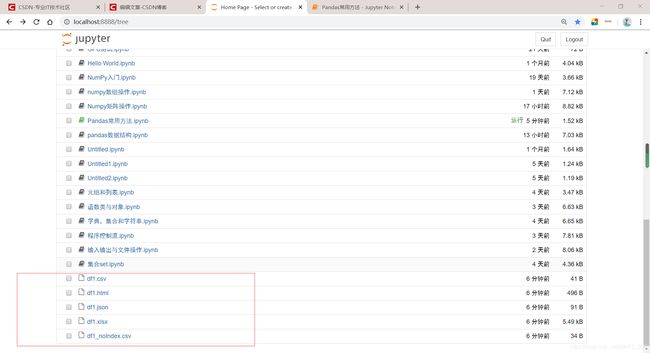
第二步:上一步只是验证,此时我们打开jupyter notebook根目录,就是在浏览器刚打开jupyter notebook的那个页面会发现,多出来了5个文件,如下:这就是我们写入粘贴板内容时生成的,依次打开如下
df.csv文件:可用excel文件打开
df1.html文件:
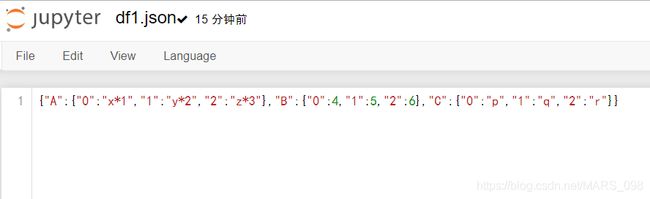
df1.json文件,类似一个嵌套的字典,还记不,外层键值为列的属性名称,内层键值为行的索引
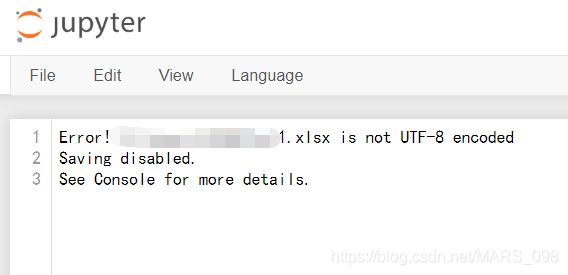
df1.xlsx文件:这里显示的不是UTF-8编码(自行谷歌UTF-8),保存出错,不着急,往下看
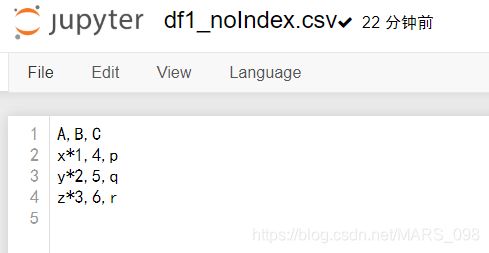
df1_noIndex.csv文件:无索引文件
注意,这里只有json和html文件用网页打开算是显示正常的,另外三个我们可以打开文件,在File--Download下载,此时再用excel文件打开们就能正常显示,如下,
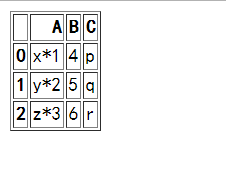
df1.csv文件:
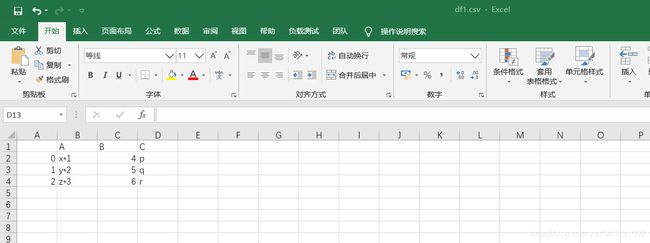
df1.xlsx文件:
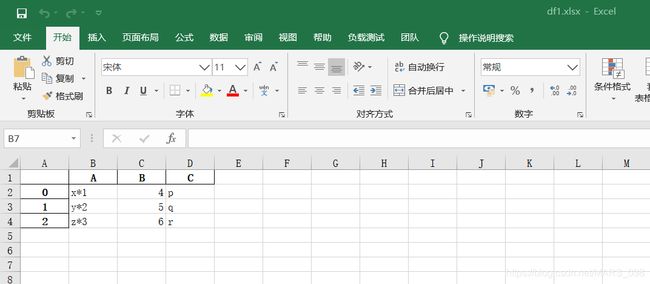
df1_noIndex.csv文件:
数据读取函数read_csv示例:
- read_csv()
- 自定义索引:可指定csv文件中的一列来使用index_col定制索引
- dtype:数据类型转换
- skiprows:跳过指定行数
# 示例,read_csv()
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
# S.No Name Age City Salary
# 1 Tome 28 Toronto 20000
# 2 Lee 32 HongKong 3000
# 3 Steven 43 BayArea 8300
# 4 Ram 38 Hyderabac 3900
# 从剪切板读取数据
df1 = pd.read_clipboard()
df1.to_csv('temp.csv',index=False)
df = pd.read_csv("temp.csv")
print(df)
首先:我们按照上面的方法根据剪切板内容生成一个temp.csv不带索引的文件,在jupyter notebook文件夹中,这里按说可以自己做一个excel文档,然后指明文件的绝对路径即可,但是本人没有调试成功。
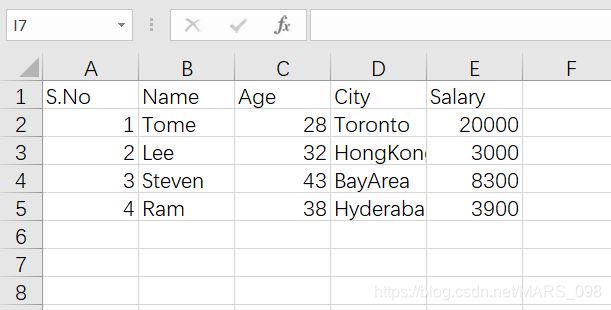
打开看一下,

我们仍然Download这个csv文件用excel打开看一下:是这样的
然后就是这段程序的运行结果:附jupyter notebook真实运行状态图
S.No Name Age City Salary
0 1 Tome 28 Toronto 20000
1 2 Lee 32 HongKong 3000
2 3 Steven 43 BayArea 8300
3 4 Ram 38 Hyderabac 3900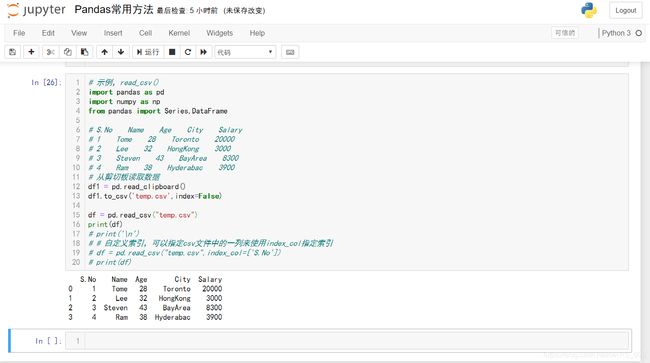
2、此时运行结果还是带有默认的索引项的,我们可以自定义索引:可指定csv文件中的一列来使用index_col定制索引,如下:
# 自定义索引,可以指定csv文件中的一列来使用index_col指定索引
df = pd.read_csv("temp.csv",index_col=['S.No'])
print(df)运行结果:
Name Age City Salary
S.No
1 Tome 28 Toronto 20000
2 Lee 32 HongKong 3000
3 Steven 43 BayArea 8300
4 Ram 38 Hyderabac 39003、dtype:数据类型转换
# 示例转换器 dtype
df = pd.read_csv("temp.csv",dtype={'Salary':np.float64}) # 将Salary这一列转换为浮点型数
print(df)
print(df.dtypes)运行结果:
S.No Name Age City Salary
0 1 Tome 28 Toronto 20000.0
1 2 Lee 32 HongKong 3000.0
2 3 Steven 43 BayArea 8300.0
3 4 Ram 38 Hyderabac 3900.0
S.No int64
Name object
Age int64
City object
Salary float64
dtype: object此时将修改过的csv文件内容赋给df对象,但是temp.csv文件中并没有改变,接着往下看
看这个示例,使用names参数指定第一行标题的名称,这里有5个列,所以我们指定五个,但是如果我们指定的多了或者少了会怎么样,自行尝试(提示:多了会补默认Nan值,少的话会从最右边列开始补,尝试一下吧)
# 示例:使用names参数指定标题的名称
df = pd.read_csv("temp.csv",names=['a','b','c','d','e'])
print(df)运行结果:
a b c d e
0 S.No Name Age City Salary
1 1 Tome 28 Toronto 20000
2 2 Lee 32 HongKong 3000
3 3 Steven 43 BayArea 8300
4 4 Ram 38 Hyderabac 3900观察可以看到,标题名称附加了自定义名称,但文件中的标题还没有消除,现在使用header参数来删除它,如果标题不是第一行,则将行号传递给标题,这将跳过前面的行
df = pd.read_csv("temp.csv",names=['a','b','c','d','e'],header=0)
print(df)运行结果:
a b c d e
0 1 Tome 28 Toronto 20000
1 2 Lee 32 HongKong 3000
2 3 Steven 43 BayArea 8300
3 4 Ram 38 Hyderabac 3900
4、skiprows跳过指定的行数
df = pd.read_csv("temp.csv",skiprows=2)
print(df)运行结果:
2 Lee 32 HongKong 3000
0 3 Steven 43 BayArea 8300
1 4 Ram 38 Hyderabac 3900
二、描述性统计方法
- Pandas提供了几个统计和描述性方法,方便从宏观的角度去了解数据集,例如count()用于统计非空数据的数量
- 除了统计类的方法,Pandas还提供了很多计算类的方法,比如sum()用于计算数值数据的总和,mean()用于计算数值数据的平均值;median()用于计算数值数据的算术中值
| 函数 | 描述 |
|---|---|
| count() |
非空观测数量 |
| sum() | 所有值之和 |
| mean() | 所有值得平均值 |
| median() | 所有值的中位数 |
| mode() | 值得模值 |
| std() | 值得标准偏差 |
| min() | 所有值中的最小值 |
| max() | 所有值中的最大值 |
| abs() | 绝对值 |
| prod() | 数组元素的乘积 |
| cumsum() | 累积总和 |
| cumprod() | 累计乘积 |
>> 描述性统计方法示例
这里创建一个字典,字典里面的三个值均为Series对象,还记得Series不?通俗讲可以理解为一个一维的数组,不记得请翻看另一篇文章《Python数据处理笔记--pandas数据结构》
# 示例3 描述性统计方法
import pandas as pd
import numpy as np
# Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
# Create a DataFrame
df = pd.DataFrame(d)
print(df,'\n')
print(df.sum(),'\n') # 列求和,默认axis=0
print(df.sum(1),'\n') # 行求和,axis=1
print(df.mean(),'\n') # 求均值
print(df.std(),'\n') # 标准差运行结果:
Name Age Rating
0 Tom 25 4.23
1 James 26 3.24
2 Ricky 25 3.98
3 Vin 23 2.56
4 Steve 30 3.20
5 Minsu 29 4.60
6 Jack 23 3.80
7 Lee 34 3.78
8 David 40 2.98
9 Gasper 30 4.80
10 Betina 51 4.10
11 Andres 46 3.65
Name TomJamesRickyVinSteveMinsuJackLeeDavidGasperBe...
Age 382
Rating 44.92
dtype: object
0 29.23
1 29.24
2 28.98
3 25.56
4 33.20
5 33.60
6 26.80
7 37.78
8 42.98
9 34.80
10 55.10
11 49.65
dtype: float64
Age 31.833333
Rating 3.743333
dtype: float64
Age 9.232682
Rating 0.661628
dtype: float64
include参数是用于产地关于什么列需要考虑用于总结的西药信息的参数,获取值列表,默认情况下是“数字值”。
object - 汇总字符串列;number - 汇总数字列;all - 将所有列汇总在一起(不应该将其作为列表值传递)。
print(df.describe(include=['number'])) # 统计信息摘要
Age Rating
count 12.000000 12.000000
mean 31.833333 3.743333
std 9.232682 0.661628
min 23.000000 2.560000
25% 25.000000 3.230000
50% 29.500000 3.790000
75% 35.500000 4.132500
max 51.000000 4.800000三、迭代与遍历
- pandas对象之间的基本迭代的行为取决于类型,当迭代一个系列Series时,它被视为数组式,基本迭代产生这些值。其他数据结构如:DataFrame,遵循类似管理迭代对象的键
- 简而言之,基本迭代(对于i在对象中)产生:
》Series - 值
》DataFrame - 列标签
- 要遍历数据帧(DataFrame)中的行,可以使用以下函数:
- > iteritems() - 迭代(key,value)对
- > iterrows() - 将行迭代为(索引,系列Series)对
- > itertuples() - 以namedtuples的形式迭代行
>> 我们直接来看示例,一定要自己动手写,根据代码和执行结果理解:
# 迭代DataFrame
import pandas as pd
import numpy as np
N=5
# 创建一个DataFrame对象
df = pd.DataFrame({
'D':pd.date_range(start='2019-01-01',periods=N,freq='M'), # 生成一个时间序列,2019-01-01开始按月增加
'x':np.linspace(0,stop=N-1,num=N), # 0~N-1的等差数列,依次增长
'y':np.random.rand(N), # 随去获取N个0~1之间的数
'z':np.random.choice(['Low','Medium','High'],N).tolist(), # 每次随机从三个变量里选一个
})
print(df,'\n')
for col in df: # 打印列
print(col)运行结果:创建了一个DataFrame对象df,仍然是以字典形式,,看注释,每个列元素的生成方式
D x y z
0 2019-01-31 0.0 0.618659 Medium
1 2019-02-28 1.0 0.671869 High
2 2019-03-31 2.0 0.336678 Low
3 2019-04-30 3.0 0.913115 Medium
4 2019-05-31 4.0 0.513041 High
D
x
y
z# 遍历 iteritems()将每个列作为名称,将索引和值作为键和迭代为Series对象
df = pd.DataFrame(np.random.rand(4,3),columns=['col1','col2','col3'])
print(df,'\n')
for key,value in df.iteritems(): # 按列逐个输出,列名作为对象名,索引仍做索引,每一列值做元素
print(key,value)运行结果:
col1 col2 col3
0 0.351817 0.516699 0.755996
1 0.123171 0.341288 0.069656
2 0.035014 0.139880 0.554374
3 0.246066 0.280162 0.538182
col1 0 0.351817
1 0.123171
2 0.035014
3 0.246066
Name: col1, dtype: float64
col2 0 0.516699
1 0.341288
2 0.139880
3 0.280162
Name: col2, dtype: float64
col3 0 0.755996
1 0.069656
2 0.554374
3 0.538182
Name: col3, dtype: float64# iterrows()返回迭代器,产生每个索引值以及包含每行数据的序列
df = pd.DataFrame(np.random.rand(4,3),columns=['col1','col2','col3'])
print(df,'\n')
for row_index,row in df.iterrows(): # 以原对象索引值作为名称,以列作为现在索引,按行输出元素值
print(row_index,row)运行结果:
col1 col2 col3
0 0.685810 0.953328 0.758930
1 0.896686 0.631734 0.393782
2 0.370163 0.184430 0.192256
3 0.521607 0.414214 0.762245
0 col1 0.685810
col2 0.953328
col3 0.758930
Name: 0, dtype: float64
1 col1 0.896686
col2 0.631734
col3 0.393782
Name: 1, dtype: float64
2 col1 0.370163
col2 0.184430
col3 0.192256
Name: 2, dtype: float64
3 col1 0.521607
col2 0.414214
col3 0.762245
Name: 3, dtype: float64# itertuples()方法将尾DataFrame中的每一行返回一个产生一个命名元组的迭代器。元组的第一个元素将是行相对应索引值,而剩余的是行值
df = pd.DataFrame(np.random.rand(4,3),columns=['col1','col2','col3'])
print(df,'\n')
for row in df.itertuples():
print(row)运行结果:
col1 col2 col3
0 0.021024 0.443600 0.592920
1 0.239633 0.011077 0.035136
2 0.705938 0.641901 0.704332
3 0.082288 0.291061 0.664905
Pandas(Index=0, col1=0.021023865673096442, col2=0.4436001195181499, col3=0.5929198136189546)
Pandas(Index=1, col1=0.23963302806893394, col2=0.01107657079492419, col3=0.03513646347749866)
Pandas(Index=2, col1=0.7059380170946893, col2=0.6419005344921521, col3=0.7043319799665725)
Pandas(Index=3, col1=0.08228792675417018, col2=0.29106069685704894, col3=0.664905361616411)
1
四、 排序
- 按索引排序:使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。默认情况下,按照升序对标签进行排序。
- 按数值排序:sort_values()是按值排序,接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
- 排序顺序:通过将布尔值传递给升序参数ascending,可以控制排序顺序。
- 按行或列排序:通过设置axis参数为0或1,为0时逐行排序,为1时逐列排序,默认为0
看示例,再说一遍,自己写一遍代码,结合结果分析代码运行原理
# 排序
unsorted_df = pd.DataFrame(np.random.rand(10,2),index=[1,4,6,2,3,5,9,8,0,7],columns = ['A','B']) # 创建未排序对象
print(unsorted_df,'\n') # 输出原始对象内容
sorted_df = unsorted_df.sort_index(ascending = True) # 按索引升值排序
print(sorted_df,'\n')
sorted_df = unsorted_df.sort_values(by = 'B') # 按‘B’列的值升值排序
print(sorted_df,'\n')运行结果:
A B
1 0.470111 0.238733
4 0.655264 0.241514
6 0.755948 0.025186
2 0.598773 0.308900
3 0.733848 0.619318
5 0.604223 0.376280
9 0.318006 0.317412
8 0.491932 0.106121
0 0.720623 0.010012
7 0.354665 0.514121
A B
0 0.720623 0.010012
1 0.470111 0.238733
2 0.598773 0.308900
3 0.733848 0.619318
4 0.655264 0.241514
5 0.604223 0.376280
6 0.755948 0.025186
7 0.354665 0.514121
8 0.491932 0.106121
9 0.318006 0.317412
A B
0 0.720623 0.010012
6 0.755948 0.025186
8 0.491932 0.106121
1 0.470111 0.238733
4 0.655264 0.241514
2 0.598773 0.308900
9 0.318006 0.317412
5 0.604223 0.376280
7 0.354665 0.514121
3 0.733848 0.619318 五、缺失值处理
- 缺失值主要是指数据丢失的现象,也就是数据集中的某一块数据不存在。
- 除了原始数据集就已经存在缺失值以外,当我们用到索引对齐(reindex(),选择等)方法时,也容易认为导致缺失值的产生。
- 缺失值处理包括:
> 缺失值标记
> 缺失值填充
> 缺失值插值
- Pands为了更方便地检测缺失值,将不同类型数据的缺失均采用NaN标记。这里的NaN代表Not a Number,仅仅是一个标记。
【缺失值处理】
- Pandas中用于标记缺失值主要用到两个方法,分别是:isnull()和notnull(),顾名思义就是<是缺失值>和<不是缺失值>。默认会返回布尔值用于判断。
# 缺失值处理
df3 = pd.DataFrame(np.random.rand(4,3),index=['a','c','e','f'],columns=['one','two','three'])
print('原始:\n',df3,'\n')
df3 = df3.reindex(['a','b','c','d','e','f','g'])
print('reindex后:\n',df3,'\n')
print(df3['one'].isnull(),'\n') # 缺失值标记
print(df3['one'].notnull(),'\n')运行结果:
原始:
one two three
a 0.888623 0.802737 0.138467
c 0.405872 0.558627 0.331860
e 0.673195 0.556458 0.656575
f 0.040185 0.573415 0.224451
reindex后:
one two three
a 0.888623 0.802737 0.138467
b NaN NaN NaN
c 0.405872 0.558627 0.331860
d NaN NaN NaN
e 0.673195 0.556458 0.656575
f 0.040185 0.573415 0.224451
g NaN NaN NaN
a False
b True
c False
d True
e False
f False
g True
Name: one, dtype: bool
a True
b False
c True
d False
e True
f True
g False
Name: one, dtype: bool 【缺失值处理】
- Pandas提供了各种方法来清除缺失的值。fillna()函数可以通过几种方法用非空数据“填充”NaN值。
# 用标量替换NaN
print("NaN replaced with '0':")
print(df3.fillna(0))运行结果:
NaN replaced with '0':
one two three
a 0.199738 0.298480 0.530142
b 0.000000 0.000000 0.000000
c 0.050568 0.584598 0.750135
d 0.000000 0.000000 0.000000
e 0.434987 0.905749 0.704368
f 0.930295 0.569068 0.603164
g 0.000000 0.000000 0.000000# 向后填充
print(df3.fillna(method = 'backfill')) # 即将缺失值设为与后面一个值相同运行结果:
one two three
a 0.199738 0.298480 0.530142
b 0.050568 0.584598 0.750135
c 0.050568 0.584598 0.750135
d 0.434987 0.905749 0.704368
e 0.434987 0.905749 0.704368
f 0.930295 0.569068 0.603164
g NaN NaN NaN【缺失值处理】
- 丢弃缺少的值:如果只想排除少的值,则使用dropna函数和axis参数。默认情况下,axis=0,如果行内的任何值是NaN,那么整个行被丢弃
print(df3,'\n') # 输出原始值
print(df3.dropna(),'\n') # 丢弃含NaN值的行
print(df3.dropna(axis=1)) # 丢弃含NaN值的列运行结果:
one two three
a 0.199738 0.298480 0.530142
b NaN NaN NaN
c 0.050568 0.584598 0.750135
d NaN NaN NaN
e 0.434987 0.905749 0.704368
f 0.930295 0.569068 0.603164
g NaN NaN NaN
one two three
a 0.199738 0.298480 0.530142
c 0.050568 0.584598 0.750135
e 0.434987 0.905749 0.704368
f 0.930295 0.569068 0.603164
Empty DataFrame
Columns: []
Index: [a, b, c, d, e, f, g]【缺失值处理】
- 替换缺失(或通用)值:用一些具体的值取代一个通用的值或缺失值。用标量替换NaN和使用fillna()函数等效。
# 替换通用数据或者缺失值
df4 = pd.DataFrame({'one':[10,20,30,40,50,2000],'two':[1000,0,30,40,50,60]})
print(df4,'\n')
print(df.replace({1000:10,2000:60}))运行结果:
one two
0 10 1000
1 20 0
2 30 30
3 40 40
4 50 50
5 2000 60
one two
0 10 10
1 20 0
2 30 30
3 40 40
4 50 50
5 60 60
本章内容有些概念不太容易理解,所以在此提醒,结合代码,多写,多练,我也是小白,一起加油。