保姆级Gmapping算法介绍到复现
目录
1.前言
2.Gmmaping算法介绍
2.1Gmapping的前世今生
2.1.1降低粒子数量
2.1.2缓解粒子耗散和多样性丢失
2.2Gmapping算法的优缺点
3.Gmapping算法源代码的安装与编译
3.1安装依赖库
3.2下载Gmapping源代码
3.2.1方法一:
3.2.2方法二:
4.下载数据集
5.数据集测试
6.Gmapping算法launch文件各参赛含义
7.附录:Gmapping常用名词通俗解释
7.1粒子滤波
7.2粒子退化、重采样、粒子多样性
8.后记
1.前言
本文主要是学习SLAM过程中,记录下我复现Gmapping算法的过程,包括我遇到的各种问题,以便后续自己复习,也希望能对大家有所帮助,在此,也感谢很多CSDN的前辈的文章,给了我很多帮助,在此致谢。
2.Gmmaping算法介绍
Gmapping是一个基于2D激光雷达使用RBPF算法完成二维栅格地图构建的SLAM算法,在介绍时,为了对新手友好,我将不讲太多理论的知识和相关数学公式的推导,尽量用通俗易懂的话语帮助各位理解,如果后续读者需要研究相关理论知识,可以去看Gmapping的论文和网上很多大神的讲解。
2.1Gmapping的前世今生
完整的SLAM问题是在给定传感器数据的情况下,同时进行机器人位姿和地图的估计问题。然而,现实的情况是这样的,如果需要得到一个精确的位姿需要与地图进行匹配,如果需要得到一个好的地图,需要有精确的位姿才能做到,显然这是一个相互矛盾的问题。
为了解决这一问题,FastSLAM算法独辟蹊径,采用RBPF方法,将SLAM算法分解成两个问题:一个是机器人定位问题,另一个是已知机器人位姿进行地图构建的问题。
FastSLAM算法中的机器人轨迹估计问题使用的是粒子滤波方法(先建图,再定位)。由于使用的是粒子滤波,每一个粒子都包含了机器人的轨迹和对应的环境地图。将不可避免的带来两个问题。第一个问题,当环境大或者机器人里程计误差大时,需要更多的粒子才能得到较好的估计,这是将造成内存爆炸;第二个问题,粒子滤波避免不了使用重采样,以确保当前粒子的有效性,然而重采样带来的问题就是粒子耗散和粒子多样性的丢失。由于这两个问题出现,导致FastSLAM算法理论上可行,实际上却不能实现。针对以上问题Gmapping提出了两种针对性的解决方法:降低粒子数量和缓解粒子消散。
2.1.1降低粒子数量
目的:通过降低粒子数量的方法大幅度缓解内存爆炸。
方法一:直接采用极大似然估计的方式,根据粒子的位姿的预测分布和地图的匹配程度,通过扫描匹配粒子的最优位姿参数,就用该位姿参数,直接当作新粒子的位姿。
方法二:Gmapping算法通过最近一帧的观测(scen),把泊松分布限制在一个狭小的有效区域。然后在正常的对泊松分布进行采样。
2.1.2缓解粒子耗散和多样性丢失
Gmapping算法采用粒子滤波算法对移动机器人轨迹进行估计,必然少不了粒子重采样的过程。随着采样次数的增多,会出现所有粒子都从一个粒子复制而来,这样粒子的多样性就完全丧失了。所以,问题不能解决,只能从减少重采样的思路走。Gmapping提出选择性重采样的方法,根据所有粒子自生权重的离散程度(也就是权重方差)来决定是否进行粒子重采样的操作。
总结:Gmapping是基于FastSLAM算法将RBPF方法变成现实。
2.2Gmapping算法的优缺点
优点:Gmapping可以实时构建室内环境地图,在小场景中计算量少。且地图精度较高,对激光雷达扫描频率要求较低
缺点:随着环境的增大,构建地图所需的内存和计算量就会变得巨大,所以Gmapping不适合大场景构图。
3.Gmapping算法源代码的安装与编译
这里用的是Ubuntu18.04
3.1安装依赖库
sudo apt-get install libsdl1.2-dev
sudo apt install libsdl-image1.2-dev
3.2下载Gmapping源代码
3.2.1方法一:
sudo apt-get install ros-melodic-gmapping注意:1.上述命令中,如果你的Ubuntu版本是16.04,需要将melodic换成kinetic,melodic对应的 Ubuntu版本对应的是18.04。
2.方法一虽然操作时候安装没有问题,但在建图测试时有时候会出现问题,需要重新进行源码安装。
3.2.2方法二:
第一步:在主目录下创建一个文件,命名为gmapping(这个名字随意),再在gmapping文件夹下面创建src编译空间 
在src目录下打开终端,创建工作空间,输入
catkin_init_workspace第二步:下载Gmapping源代码
git clone https://github.com/ros-perception/openslam_gmapping
git clone https://github.com/ros-perception/slam_gmapping.git
git clone https://github.com/ros-planning/navigation.git
git clone https://github.com/ros/geometry2.git
git clone https://github.com/ros-planning/navigation_msgs.git
下载完后,效果如图
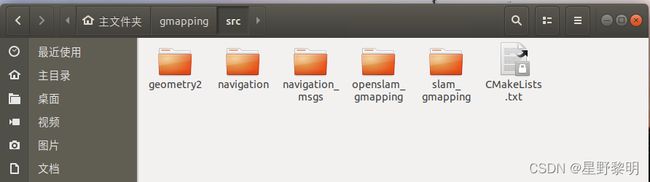
注意: 有时候会出现下载不了的情况,如下图 这种情况一般都是网速的问题,可以将下载命令重复多试几次。

第三步:编译,返回到gmapping目录下,打开终端,输入
catkin_make_isolated![]()
注意:不用catkin_make编译的原因是因为下载的源代码之间的功能包可能存在互相依赖的问题,在同时编译的时候会报错。
4.下载数据集
百度网盘自取
链接:https://pan.baidu.com/s/1o5n10WIBEhYXUUuioURKXQ?pwd=28jn
提取码:28jn
下载后,将数据集放在gmapping目录下,如图
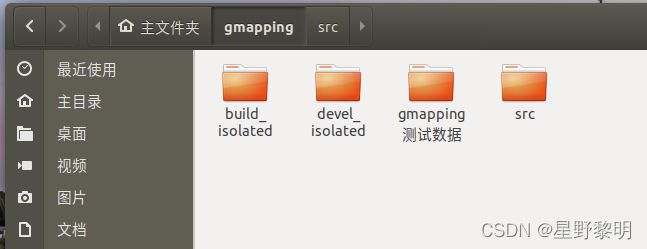
5.数据集测试
第一步:打开一个终端,输入
roscore第二步:另开一个终端,输入
rosparam set use_sim_time true//设置ROS 启用重放数据中的时间而非本机时间,因为在默认情况下ros使用Ubuntu系统的时间,即当前时间。由于我们重放的文件是历史文件,它记录的是历史时间,所以需要设置ROS 从现在起开始启用模拟时间。
rosrun gmapping slam_gmapping scan:=base_scan //启动gmapping,并监听scan_base topic 发来消息。
注意:1.第二行命令~$ rosrun gmapping slam_gmapping scan:=base_scen 中的gmapping不是你创建的文件夹的名字,而是你下载的gmapping源代码的功能包的名字,你就算创建的文件夹叫“abc(或者其他什么)”,第二行照样这样写。
2.第二行命令是用来监听话题消息的,你还没有运行相关话题,所以此时该命令下面没有任何消息,是正常的。 只有当你运行功能包,这下面才会有信息显示。

第三步:在数据集文件下创建终端,输入
rosbag play basic_localization_stage.bag //这个basic_localization_stage.bag是我的数据包里的,如果是别的数据包,只需要将名字即basic_localization_stage.bag换了即可。
注意:这个命令对应的是我发的链接的数据集,如果是其他数据集,记得将后面数据包的名字换一下

第四步:再新开一个终端,打开可视化界面
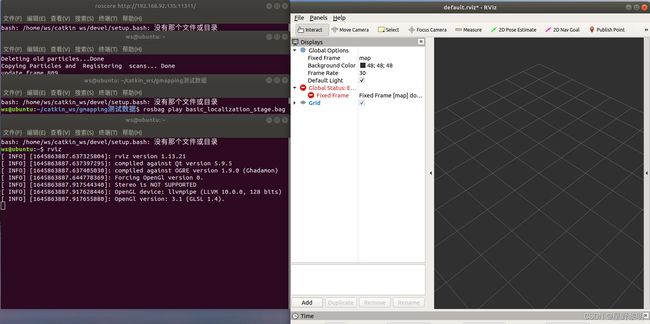
注意:此时的可视化界面是没有图像的,需要调参数
第五步:调节参数,打开可视化界面左下角的Add,选中map,打开map选项,选中Topic选项里面的/map,这样图像就出来了。
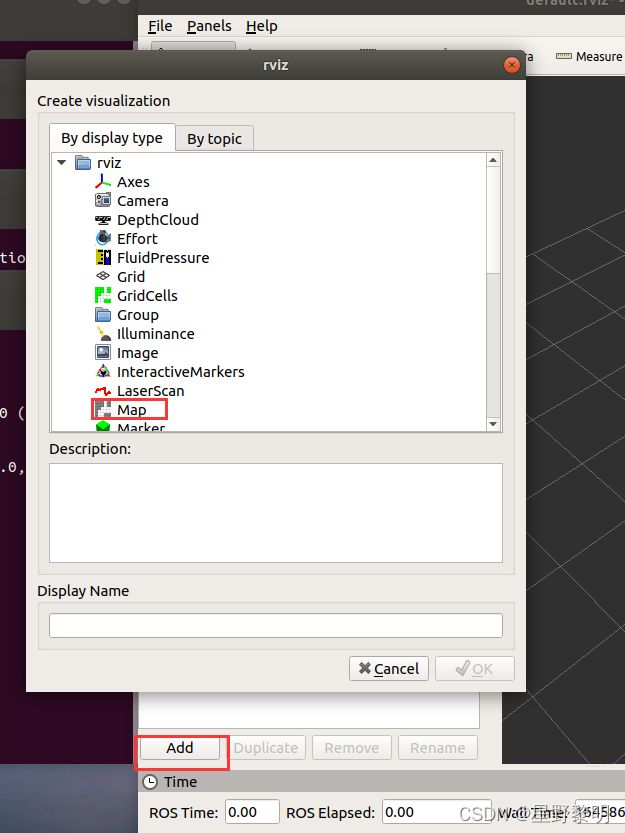
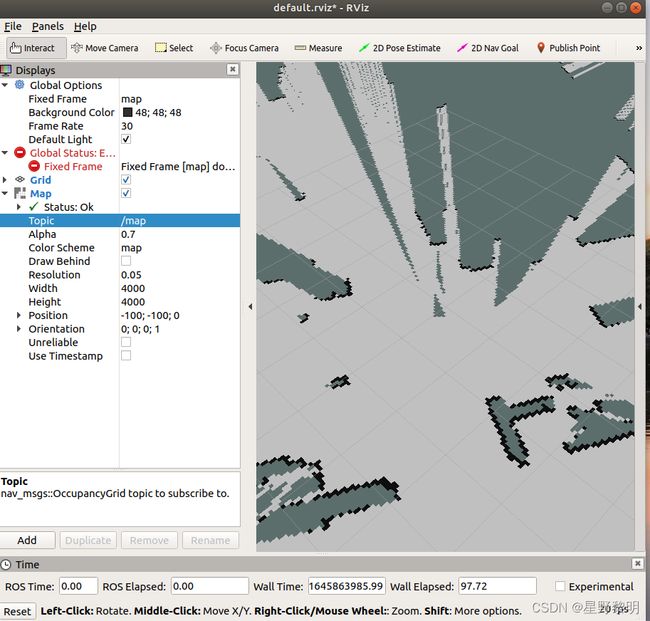
做到此步就已经算是对Gmapping算法复现成功了。
6.Gmapping算法launch文件各参赛含义
在这方面CSDN上面已经有很多大神对此做了很详细的介绍了,所以我就不班门弄斧了,这里我推荐一篇我看过的文章,写的很全面了
https://blog.csdn.net/qq_42037180/article/details/100819788
7.附录:Gmapping常用名词通俗解释
在学习的过程中我发现有很多人对于粒子滤波,重采样,粒子多样性,粒子退化这些概念有些模糊,为此我在看到的文章中发现有人对此做了一个类比,通俗易懂,在此分享给大家。
7.1粒子滤波
从知乎上看到的一个有趣的解释。
简单来说,在机器人定位问题中,我们想要估计机器人的位置和姿态。
最初,我们完全不知道机器人在哪,那就索性假设机器人以同等的概
率出现在地图上的任意一个位置。比如,假如地图是整个中国,那么
机器人就等可能地出现在北京、上海、广州、哈尔滨等地。于是我们
就可以用一个粒子代表一个机器人可能出现的位置。现在,机器人说
话了,它说它感觉特别冷,雪落在了它洁白的脖子上。于是,我当即
排除了长江以南的城市,南方怎么可能下雪呢!机器人系上围脖,继
续向前走。没走几步,它又抱怨道,“今天空气质量可真不怎么样,
我的双目都要失明了。”显然,它是遇到了雾霾天,这种天气在北方某
帝都倒是挺常见的。它点亮了IR主动光探测,雾霾天上路多加小心总
没有错。转眼间,机器人来到一个庞大的建筑物面前,这里人声鼎沸,
还有遍地的商贩在叫卖着不知什么东西。它借助自身廉价的激光雷达
小心翼翼地在人群中穿梭。突然,它若有所思地停了下来,似乎发现
了一个美丽的秘密。虽然外面寒冬凌冽,这里却如春天般富有生机,
到处洋溢着绿色的海洋。人声此起彼伏,它依稀听出了五个字,“国
安是冠军”...在上面的例子中,“我”作为机器人的大脑,根据机器人
的感受,可以得出如下推理。机器人发现下雪了,那么可以确定机器
人应该在北方的某个城市。接着,机器人遇到了雾霾天,那么说明该
城市的空气质量很差,这就进一步把搜索范围缩小到了某几个重点空
气污染城市。最后,机器人听到的五个字“国安是冠军”,彻底让我锁
定了它所在的城市——“北京”。这就是一个形象的粒子滤波案例。机器
人不断地通过运动、观测的方式,获取周围环境信息,逐步降低自身
位置的不确定度,最终得到准确的定位结果。附上该文章链接:https://www.guyuehome.com/14967
7.2粒子退化、重采样、粒子多样性
这里回答一下什么是粒子退化:
粒子退化主要指正确的粒子被丢弃和粒子多样性减小,而频繁重采样则加剧了
正确的粒子被丢弃的可能性和粒子多样性减小速率。这里先涉及一下重采样的知识,我
们知道在执行重采样之前会计算每个粒子数的权重,有时会因为环境相似度高或是由于
噪声的影响会使接近正确状态的粒子数权重较小而错误状态的粒子的权重反而会大。重
采样是依据粒子权重来重新采粒子的,这样正确的粒子就很有可能会被丢弃,频繁的重
采样更加剧了正确但权重较小粒子被丢弃的可能性。这也就是粒子退化原因之一。
另外一个原因就是频繁重采样导致的粒子多样性减小速率加大,什么是粒子多
样性呢?就是粒子的不同,就像最开始有十个粒子,如果发生重采样后其中有两个粒子
共享一个父亲,而上一次十个粒子中,其中一个粒子没有孩子则说明粒子多样性减小。
再通俗点解释,比如兔子生兔子这个问题。我们的笼子只能装十个兔子,所以在任意时
刻我们只能有十只兔子,但兔子是会繁殖的,那么怎么办呢?索性把长的不好看的兔子
干掉(这里的好看就是粒子权重,好看的权重就高不好看的权重就低,哈哈作者就是这
么任性)。让好看的兔子多生一只补充干掉的兔子。我们假设兔子一月繁殖一回,这样
的话在多年后这些兔子可能就都是一个兔子的后代。就是说兔子们的DNA都是一样的了,
也就是兔子DNA的多样性减小。为什么频繁执行重采样会使粒子多样性减小呢,这就好
比我兔子一月繁殖一会我可能五年后这些兔子的才会共有一个祖先。但如果让兔子一天
繁殖一会呢?可能一个月后这些兔子就全是最开始一只兔子的后代了,兔子们的DNA就
成一样了。因此为了防止粒子退化就要减少重采样的次数。附上该文章链接:https://www.codetd.com/article/3003143
8.后记
看到这里,其实Gmapping这个算法我已经介绍的很全面了,几乎综合了网上我看到的所有关于Gmapping的文章。后续我也会对其他经典的SLAM算法进行复现和介绍,包括视觉,激光,以及视觉和激光的融合。如果感兴趣的读者觉得我写的还不错,麻烦点个三连吧(点赞、收藏、关注),谢谢大家。