FGSM实例:利用fgsm攻击RMB识别模型
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、模型训练总结回顾
二、对RMB分类模型进行fgsm攻击
1.fgsm原理
2.大致思路流程概述
1.求数据集中每个数据集的梯度(以供fgsm生成噪声)
2.通过fgsm,得到对抗样本数据集
3.检验fgsm攻击效果
3.设定扰动量epsilon和识别准确度accuracies
4.定义FGSM攻击函数(原理超级通俗)
5.具体攻击过程(仅展示思路,详细代码显示于文末)
6.攻击结果实例化
代码展示
成果展示
三.完整代码
总结
一、模型训练总结回顾
RMB识别模型的具体训练流程已在之前的文章详细叙述,故在此仅聊一聊大致思路
1.数据导入:(仅限导入本地已有的数据(已分类放置)的方法)
先使用Dataset(包含init,getitem,len函数),其中我们所需要设定的就是init函数和getitem函数。定义init函数,使其根据我们所输入的存储主路径将每一张图片的存储路径和图片类别存放于列表中。定义getitem函数(需要在DataLoader中通过index才能进行下述操作),使其能够根据列表中的路径提取图片信息,并执行我们所设定的transform函数,进行图片信息的变换。
再使用DataLoader,这一步不需要我们去定义什么,只需要输入Dataset并设定一些参数的值即可(如批大小,每个epoch是否乱序等等)
2.模型初定义
因为是继承了nn.Module这个父类的,所以我们只需要设定init函数和forward函数,其中init函数中设定自己想要的卷积层和线性层,结构如下:
self.conv1 = nn.Conv2d(输入层数, 输出层数, 卷积核大小) self.fc1 = nn.Linear(层数*长*宽, 想要的数值)(最终目的是缩小为分类的种类数,但不能直接一步成,必须分成几次达成)
而forward函数则是制定数据信息变化过程先是依次进行以下操作,直到无法继续缩小图片信息为止(长宽不满足执行条件)
out = F.relu(self.conv1(x)) (长宽减少,层数增加) 执行条件:满足卷积神将网络的计算公式: N=(W-F+2P)/S+1 其中N:输出大小 W:输入大小 F:卷积核大小 P:填充值的大小 S:步长大小 out = F.max_pool2d(out, 2) (长宽减半,层数不变) 执行条件:长宽为偶数
当无法继续缩小图片信息后,执行设定好的线性层即可。
3.定义损失函数和优化器
损失函数到没什么需要我们去操作的,直接用现成的就行。
优化器(optimizer)也直接用现成的,只需要设定以下学习率的大小即可。再将optimizer作为输入,放在scheduler中,同时再设定学习率下降策略,即学习率缩小倍数即可。
4.训练过程
定义数据集循环次数,每轮循环中,将数据集中的图片信息导入模型得到outputs,将该结果与实际结果导入loss函数,并进行backward,根据梯度,通过优化器改变图片每个信息点对应的权重值。比较outputs中的不同分类的数值,得出其中每张图片的最大可能分类(即预测结果),将其与实际情况比较,得出识别正确率。
二、对RMB分类模型进行fgsm攻击
1.fgsm原理
具体内容参考此链接,写的很详细 https://blog.csdn.net/qq_35414569
一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可)

图1 图二(噪声) 图三(对抗样本)
把图一喂给模型,模型告诉你57.7%的概率是熊猫,别看概率小,机器总会输出概率值最大的那个结果。随后把图二加入图一中,生成一张新的图三,把图三喂给模型,模型告诉你99.3%是金丝猴,但肉眼看依然是熊猫,这就是FGSM攻击方法
2.大致思路流程概述
前提:已有一个已经训练好的模型
1.求数据集中每个数据集的梯度(以供fgsm生成噪声)
将数据集代入模型,求得outputs,将结果与数据集实际类别输入到选定的loss函数中,进行backward,并将每张图片对应梯度收集入列表。
2.通过fgsm,得到对抗样本数据集
将数据集,收集的梯度列表,当前设定的扰动量输入定义的fgsm中,得到最终的对抗样本数据集
3.检验fgsm攻击效果
将抗样本数据集输入进模型中,得到攻击后的outputs,比较outputs中的不同分类的数值,得出其中每张图片的最大可能分类(即预测结果),统计该结果同实际类别的吻合度,得到收到攻击后的模型识别的准确度
3.设定扰动量epsilon和识别准确度accuracies
内容如图所示:
# 这里的扰动量先设定为几个值,后面可视化展示不同的扰动量影响以及成像效果
epsilons = [0, .05, .1, .15, .2, .25, .3, .35, .4]
# 将epsilons中的每个eps所对应的识别准确度放入列表中以供线形图展示
accuracies = list()4.定义FGSM攻击函数(原理超级通俗)
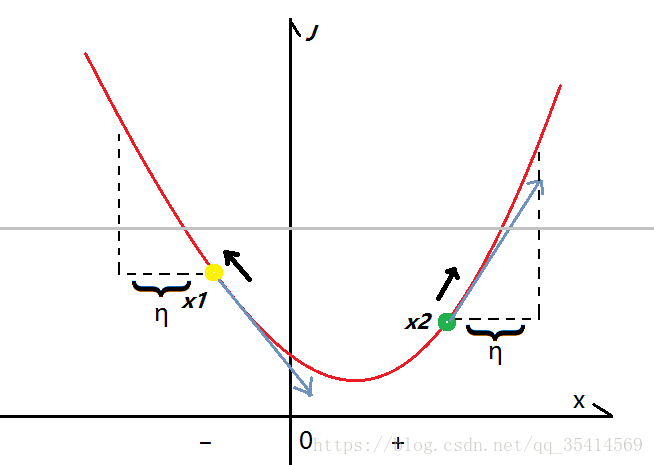
如图所示,我们可以假象为每个图片信息就是这根曲线上的点,该点对应的位置就会影响对其类别的判断,fgsm攻击的目的就是以尽可能小的移动幅度让该点尽可能的远离当前位置,故而就得顺着梯度最大的方向走,才能达到最佳效果,即让每个图片信息点所增加的噪声都能对其远离的行为产生正向作用。
对应代码及解释如下所示:
def fgsm_attack(image, epsilon, data_grad):
# 使用sign(符号)函数,将对x求了偏导的梯度进行符号化(正数为1,零为0,负数为-1)
sign_data_grad = data_grad.sign()
# 通过epsilon生成对抗样本
perturbed_image = image + epsilon * sign_data_grad
# 噪声越来越大,机器越来越难以识别,但人眼可以看出差别
# 做一个剪裁的工作,将torch.clamp内部大于1的数值变为1,小于0的数值等于0,防止image越界
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# 返回对抗样本
return perturbed_image5.具体攻击过程(仅展示思路,详细代码显示于文末)
1.设定循环的最大轮数
2.每一轮都将数据集中的一个batch的图片信息代入模型,求得outputs
3.通过outputs与图片实际类别,输入loss函数并进行backward,收集每张图片的梯度信息
4..将数据,梯度信息,设定的扰动量输入fgsm函数中,最终得到对抗样本数据。
5.可以设定当运行了几个batch时,显示当前的攻击信息(如显示当前多个batch计算得出的loss的平均值,对比预测结果与实际类别得出准确度等等)
6.攻击结果实例化
注意:x,y值必须是列表的形式
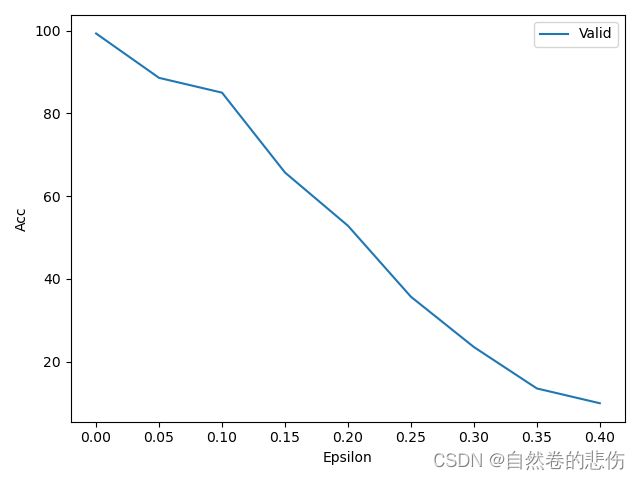
代码展示
valid_x = epsilons # 设定的几个eps
valid_y = accuracies # 每个eps对应的准确度
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('Acc')
plt.xlabel('Epsilon')
plt.show()成果展示
三.完整代码
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from PIL import Image
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
class LeNet(nn.Module):
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 5
LR = 0.001
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join(".", "RMB_data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
def fgsm_attack(image, epsilon, data_grad):
# 使用sign(符号)函数,将对x求了偏导的梯度进行符号化(正数为1,零为0,负数为-1)
sign_data_grad = data_grad.sign()
# 通过epsilon生成对抗样本
perturbed_image = image + epsilon * sign_data_grad
# 噪声越来越大,机器越来越难以识别,但人眼可以看出差别
# 做一个剪裁的工作,将torch.clamp内部大于1的数值变为1,小于0的数值等于0,防止image越界
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# 返回对抗样本
return perturbed_image
# 这里的扰动量先设定为几个值,后面可视化展示不同的扰动量影响以及成像效果
epsilons = [0, .05, .1, .15, .2, .25, .3, .35, .4]
# epsilons = [0, .05, .1, .15, .2, ]
accuracies = list()
for eps in epsilons:
loss_mean = 0.
correct = 0.
total = 0.
log_interval = 10
MAX_EPOCH = 3
for epoch in range(MAX_EPOCH):
net.train()
for j, data in enumerate(valid_loader):
inputs, labels = data
# 图像数据梯度可以获取
inputs.requires_grad = True
outputs = net(inputs)
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# 收集datagrad
data_grad = inputs.grad.data
# 调用FGSM攻击
perturbed_data = fgsm_attack(inputs, eps, data_grad)
# 对受扰动的图像进行重新分类
output = net(perturbed_data)
# 统计分类情况
_, final_pred = torch.max(output.data, 1) # 得到最大对数概率的索引
total += labels.size(0)
correct += (final_pred == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
valid_curve.append(loss.item())
if (j + 1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Validing:Epsilon: {:} Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
eps, epoch, MAX_EPOCH, j + 1, len(valid_loader), loss_mean, correct / total))
loss_mean = 0.
accuracies.append(correct / total * 100)
valid_x = epsilons
valid_y = accuracies
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('Acc')
plt.xlabel('Epsilon')
plt.show()
总结
本周学习了fgsm攻击的基本原理,并将之与之前学习的RMB识别模型进行结合(使用了原先选择的loss函数及训练好的模型),学有所获并详细记录了其中的思路流程。之后,会学习如何使用cifar-10和 imagenet数据集进行FGSM攻击,以及其他评价模型的指标等等。