【CTR】ESMM:多任务联合学习
作者:阿泽(阿泽的学习笔记)
本文介绍阿里妈妈广告算法团队发表于 2018 年 SIGIR 一篇论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》。
传统的 CVR 通常会面临样本选择偏差和数据稀疏两大的问题,从而使得模型训练变得相当困难。本文作者提出 ESMM 算法,通过定义新型多任务联合训练的方式,以全新的视角对 CVR 进行建模。
通过淘宝推荐系统的实验表明,ESMM 的性能明显优于其他算法。
看到这里,大家可能有很多疑问:
CVR 预估任务中,样本选择偏差是什么问题?
ESMM 是怎样多任务训练的,又是如何联合训练的?
带着问题,我们来阅读以下内容。
Introduction
post-click conversion rate 翻译过来就是:点击后转化率,也就是说 CVR 是建立在用户点击的基础上的进行的。
作者将用户的行为简化为:曝光->点击->转换三个步骤,三者的区别如下图所示:
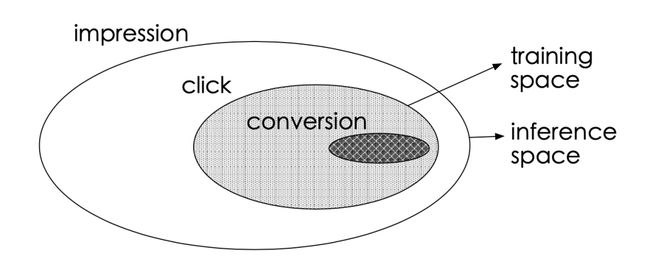
传统的 CVR 任务中,工程师通常将以点击未购买的样本作为负样本,而点击购买的样本作为正样本,并以此训练模型,将其部署到线上使用。
但这样的训练方式有一个问题,模型是针对点击的商品进行训练的,而线上数据集大部分都是未点击的,此时便会出现样本选择偏差(sample selection bias,SSB) 的问题。
此外,点击商品本身就非常少,所以通过这种方式构建的数据集还会面临数据稀疏(data sparsity,DS) 的问题。
SSB 问题会影响模型的泛化性能,而 DS 问题会影响模型的拟合。
现有的一些研究试图去解决这些问题,比如说:建立基于不同特征的分层估计器,并将其与 LR 模型相结合来解决 DS 问题,或者利用对未曝光未点击的样本做采样来缓解 SSB 问题。这些策略在一定程度上可以消除 SSB 和 DS 问题,但都显得不够优雅,并且也都不能真正解决 CVR 建模中的问题。
上述策略的一大关键在于没有考虑到 CTR 和 CVR 的顺序动作信息,而阿里妈妈的同学通过充分利用用户操作的顺序性提出了 ESMM 算法,该方法能够同时解决 SSB 和 DS 问题。
ESMM 中引入了两个辅助任务,分别是 CTR 和点击后转换的 CTCVR 任务。ESMM 并不是直接使用曝光样本来训练 CVR,而是利用 的关系,CTCVR 和 CTR 都可以通过曝光的样本进行训练,而 CVR 作为中间变量可以由 CTR 和 CTCVR 估算得到。因此,通过这种方法算出的 CVR 也适用于整个样本空间(与线上分布一致),这便解决了 SSB 问题。此外,CVR 和 CTR 共享网络表征,由于后者的训练样本更多,所以也可以减轻 DS 问题。
ESMM
接下来,我们来看 ESMM 的具体做法。
我们将上面的式子写具体,对于给定的曝光样本 x,我们可以得到 CTCVR 的概率:
基于这种关系,我们联合 Embedding 和 MLP 网络设计了 ESMM 架构:

ESMM 借鉴多任务学习的思想,将模型分为左右两个模块,左边是我们需要的 CVR 模块,右边是 CTR 和 CTCVR 辅助训练模块,恰当的引入了用户操作的顺序性,同时消除了 CVR 建模出现的两个问题。
值得注意的是,CVR 和 CTR 任务采用相同的特征输入并共享 Embedding Layer,CTR 任务中由于具有大量训练样本,可以对模型进行充分训练,这种参数共享的方式,可以降低数据稀疏带来的影响。
另外,pCVR 只是一个中间变量,受到上面公式的约束,而 pCTR 和 pCTCVR 才是 ESMM 中实际训练的主要因素。(可以这样理解,CVR 模型是没有监督信号的,而 CTR 和 CTCVR 都是有监督信号的,最后利用公式约束得到 CVR 模型。)
所以,对于给定曝光的样本,我们同时可以得到 CVR、CTR 和 CTCVR。
可能有同学会有疑问,为什么要通过公式进行约束,而不直接通过 pCTCVR/pCTR 来得到 pCVR。作者也做了这样的实验,但是结果并不好,主要原因在于 pCTR 通常非常小,除以一个非常小的数会引起数值不稳定,所以 ESMM 采用了乘法公式进行约束,而不是直接通过除法得到结果。
我们来看下 ESMM 的损失函数,由具有监督信息的 CVR 和 CTCVR 任务组成:
其中, 和 分别是 CTR 和 CVR 网络的参数; 为交叉熵损失函数。
Experiments
来看一下实验部分:
所有数据集是从淘宝日志中整理抽取出来的生产环境的数据集(Product Dataset),并且从中进行随机采样(1%)作为公共数据集(Public Dataset),同时也开源了这部分公共数据集。两个数据集的信息如下所示:

下图为不同模型在公共数据集中的表现:

其中 ESMM-NS 为 ESMM 的精简版,没有 Embedding Layer 的参数共享。
可以看到两个版本的 ESMM 在不同任务下的效果都取得了 SOTA 的成绩。
再看一下不同模型在生产数据集上的表现:

ESMM 模型在不同大小的数据集上都是处于领先地位的。
Code
放上 ESMM 的核心代码:
1#-*- coding: UTF-8 -*-
2import tensorflow as tf
3from tensorflow.python.estimator.canned import head as head_lib
4from tensorflow.python.ops.losses import losses
5
6def build_deep_layers(net, params):
7 # 构建隐藏层
8 for num_hidden_units in params['hidden_units']:
9 net = tf.layers.dense(net, units=num_hidden_units, activation=tf.nn.relu,
10 kernel_initializer=tf.glorot_uniform_initializer())
11 return net
12
13def esmm_model_fn(features, labels, mode, params):
14 net = tf.feature_column.input_layer(features, params['feature_columns'])
15 last_ctr_layer = build_deep_layers(net, params)
16 last_cvr_layer = build_deep_layers(net, params)
17
18 head = head_lib._binary_logistic_or_multi_class_head(
19 n_classes=2, weight_column=None, label_vocabulary=None, loss_reduction=losses.Reduction.SUM)
20 ctr_logits = tf.layers.dense(last_ctr_layer, units=head.logits_dimension,
21 kernel_initializer=tf.glorot_uniform_initializer())
22 cvr_logits = tf.layers.dense(last_cvr_layer, units=head.logits_dimension,
23 kernel_initializer=tf.glorot_uniform_initializer())
24 # 核心思想在这里:
25 ctr_preds = tf.sigmoid(ctr_logits)
26 cvr_preds = tf.sigmoid(cvr_logits)
27 ctcvr_preds = tf.multiply(ctr_preds, cvr_preds)
28 optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate'])
29 ctr_label = labels['ctr_label']
30 cvr_label = labels['cvr_label']
31
32 user_id = features['user_id']
33 click_label = features['label']
34 conversion_label = features['is_conversion']
35
36
37 if mode == tf.estimator.ModeKeys.PREDICT:
38 predictions = {
39 'ctr_preds': ctr_preds,
40 'cvr_preds': cvr_preds,
41 'ctcvr_preds': ctcvr_preds,
42 'user_id': user_id,
43 'click_label': click_label,
44 'conversion_label': conversion_label
45 }
46 export_outputs = {
47 'regression': tf.estimator.export.RegressionOutput(predictions['cvr_preds'])
48 }
49 return tf.estimator.EstimatorSpec(mode, predictions=predictions, export_outputs=export_outputs)
50
51 else:
52 ctr_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=ctr_label, logits=ctr_logits))
53 ctcvr_loss = tf.reduce_sum(tf.losses.log_loss(labels=cvr_label, predictions=ctcvr_preds))
54 loss = ctr_loss + ctcvr_loss # loss这儿可以加一个参数,参考multi-task损失的方法
55
56 train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
57 return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)Conclusion
一句话总结:作者提出了一种用于 CVR 建模的多任务联合训练方法——ESMM,其充分利用了用户点击、转换的顺序性,并借助 CTR 和 CTCVR 两个辅助任务来训练 ESMM 模型,并通过三者的关系约束得到 CVR 模型。ESMM 模型可以很好的解决传统 CVR 建模中出现的样本选择偏差和数据稀疏的两大难题,并在真实数据集中取得 SOTA 的优秀表现。
此外,ESMM 模型中子网络也可以替换成其他更先进的模型,从而吸收其他模型的优势,进一步提升学习效果。
Reference
Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
github:x-deeplearning
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读

整理不易,还望给个在看!