【Transformers】第 8 章 :使Transformers高效生产
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
意图检测作为案例研究
创建性能基准
通过知识蒸馏使模型更小
用于微调的知识蒸馏
预训练的知识蒸馏
创建知识蒸馏培训师
选择一个好的学生初始化
使用 Optuna 找到好的超参数
对我们的蒸馏模型进行基准测试
通过量化使模型更快
对我们的量化模型进行基准测试
使用 ONNX 和 ONNX 运行时优化推理
使用权重修剪使模型更稀疏
深度神经网络中的稀疏性
权重修剪方法
幅度修剪
运动修剪
结论
在前面的章节中,您已经了解了如何微调转换器以在各种任务中产生出色的结果。但是,在许多情况下,准确性(或您正在优化的任何指标)是不够的;如果最先进的模型太慢或太大而无法满足应用程序的业务需求,那么它就不是很有用。一个明显的替代方法是训练更快、更紧凑的模型,但模型容量的减少通常伴随着性能的下降。那么,当您需要一个快速、紧凑但高度精确的模型时,您能做些什么呢?
在本章中,我们将探讨四种互补技术,可用于加速预测并减少 Transformer 模型的内存占用:知识蒸馏、量化、 修剪和使用开放神经网络交换 (ONNX) 格式和 ONNX 进行图优化运行时 (ORT)。我们还将了解如何将其中一些技术结合起来以产生显着的性能提升。例如,这是 Roblox 工程团队在他们的文章 “我们如何扩展 Bert 以在 CPU 上服务 1+ 十亿每日请求”中采用的方法,如图 8-1所示发现结合知识蒸馏和量化使他们能够将 BERT 分类器的延迟和吞吐量提高 30 倍以上!
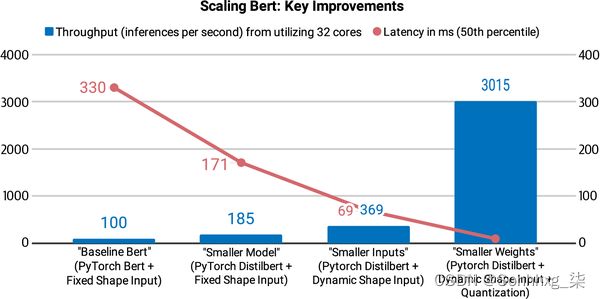
图 8-1。Roblox 如何通过知识蒸馏、动态填充和权重量化来扩展 BERT(照片由 Roblox 员工 Quoc N. Le 和 Kip Kaehler 提供)
为了说明与每种技术相关的好处和权衡,我们将使用意图检测作为案例研究;这是基于文本的助手的重要组成部分,其中低延迟对于保持实时对话至关重要。在此过程中,您将学习如何创建自定义训练器、执行高效的超参数搜索,并了解如何使用 Transformers 实施前沿研究。让我们潜入吧!
意图检测作为案例研究
假设我们正在尝试为我们公司的呼叫中心构建一个基于文本的助手,以便客户可以请求他们的帐户余额或进行预订,而无需与人工代理交谈。为了了解客户的目标,我们的助手需要能够将各种自然语言文本分类为一组预定义的动作或 意图。例如,客户可能会发送如下关于即将到来的旅行的消息:
嘿,我想从 11 月 1 日到 11 月 15 日在巴黎租一辆车,我需要一辆 15 座的面包车
我们的意图分类器可以自动将其归类为租车意图,然后触发动作和响应。为了在生产环境中保持稳健,我们的分类器还需要能够处理超出范围的查询,其中客户进行不属于任何预定义意图的查询,并且系统应该产生回退响应. 例如图 8-2所示的第二种情况,客户提出一个关于运动的问题(超出范围),文本助手错误地将其归类为已知范围内的意图之一,并返回发薪日响应。在第三种情况下,文本助手已经过训练,可以检测超出范围的查询(通常标记为单独的类),并告知客户它可以回答哪些主题。
图 8-2。人类(右)和基于文本的助手(左)之间的三次个人理财交流(由 Stefan Larson 等人提供)
作为基线,我们微调了一个基于 BERT 的模型,该模型在 CLINC150 数据集上实现了大约 94% 的准确度。1该数据集包括 22,500 个范围内查询,涉及 150 个意图和 10 个领域(如银行和旅游),还包括 1,200 个属于某个oos意图类的范围外查询。在实践中,我们也会收集自己的内部数据集,但使用公共数据是快速迭代并产生初步结果的好方法。
首先,让我们从 Hugging Face Hub 下载我们经过微调的模型,并将其包装在用于文本分类的管道中:
from transformers import pipeline
bert_ckpt = "transformersbook/bert-base-uncased-finetuned-clinc"
pipe = pipeline("text-classification", model=bert_ckpt)现在我们有了一个管道,我们可以传递一个查询来从模型中获取预测的意图和置信度分数:
query = """Hey, I'd like to rent a vehicle from Nov 1st to Nov 15th in
Paris and I need a 15 passenger van"""
pipe(query)[{'label': 'car_rental', 'score': 0.549003541469574}]
太好了,car_rental意图是有道理的。现在让我们看看创建一个基准,我们可以使用它来评估我们的基准模型的性能。
创建性能基准
与其他机器学习模型一样,在生产环境中部署转换器需要在几个约束之间进行权衡,最常见的是:2
Model performance
我们的模型在反映生产数据的精心设计的测试集上表现如何?当犯错的成本很大时(并且最好通过人工参与来减轻),或者当我们需要对数百万个示例进行推理并且对模型指标的微小改进可以转化为总体上的巨大收益时,这一点尤其重要。
Latency
我们的模型能以多快的速度提供预测?我们通常关心处理大量流量的实时环境中的延迟,例如 Stack Overflow 如何需要一个分类器来快速 检测网站上不受欢迎的评论。
Memory
我们如何部署需要千兆字节磁盘存储和 RAM 的 GPT-2 或 T5 等十亿参数模型?内存在移动或边缘设备中发挥着特别重要的作用,在这些设备中,模型必须在不访问强大的云服务器的情况下生成预测。
未能解决这些限制可能会对您的应用程序的用户体验产生负面影响。更常见的是,运行可能只需要处理几个请求的昂贵云服务器会导致成本激增。为了探索如何使用各种压缩技术优化这些约束中的每一个,让我们首先创建一个简单的基准来测量给定管道和测试集的每个数量。下面的类给出了我们需要的框架:
class PerformanceBenchmark:
def __init__(self, pipeline, dataset, optim_type="BERT baseline"):
self.pipeline = pipeline
self.dataset = dataset
self.optim_type = optim_type
def compute_accuracy(self):
# We'll define this later
pass
def compute_size(self):
# We'll define this later
pass
def time_pipeline(self):
# We'll define this later
pass
def run_benchmark(self):
metrics = {}
metrics[self.optim_type] = self.compute_size()
metrics[self.optim_type].update(self.time_pipeline())
metrics[self.optim_type].update(self.compute_accuracy())
return metrics我们已经定义了一个optim_type参数来跟踪我们将在本章中介绍的不同优化技术。我们将使用该run_benchmark()方法收集字典中的所有指标,键由optim_type.
现在让我们通过计算测试集上的模型精度来为这个类的骨骼添加一些内容。首先,我们需要一些数据进行测试,所以让我们下载用于微调基线模型的 CLINC150 数据集。我们可以使用Datasets 从 Hub 获取数据集,如下所示:
from datasets import load_dataset
clinc = load_dataset("clinc_oos", "plus")在这里,plus配置是指包含超出范围的训练示例的子集。CLINC150 数据集中的每个示例都包含text列中的一个查询及其相应的意图。我们将使用测试集对我们的模型进行基准测试,因此让我们看一下数据集的一个示例:
sample = clinc["test"][42]
sample{'intent': 133, 'text': 'transfer $100 from my checking to saving account'}
features意图作为 ID 提供,但我们可以通过访问数据集的属性轻松获取到字符串的映射(反之亦然) :
intents = clinc["test"].features["intent"]
intents.int2str(sample["intent"])'transfer'
现在我们对 CLINC150 数据集中的内容有了基本的了解,我们来compute_accuracy()实现 PerformanceBenchmark. 由于数据集在意图类之间是平衡的,我们将使用准确性作为我们的指标。我们可以使用数据集加载此指标,如下所示:
from datasets import load_metric
accuracy_score = load_metric("accuracy")准确度度量期望预测和参考(即,基本事实标签)是整数。我们可以使用管道从text字段中提取预测,然后使用str2int() 我们intents对象的方法将每个预测映射到其对应的 ID。以下代码在返回数据集的准确性之前收集列表中的所有预测和标签。让我们也将它添加到我们的PerformanceBenchmark类中:
def compute_accuracy(self):
"""This overrides the PerformanceBenchmark.compute_accuracy() method"""
preds, labels = [], []
for example in self.dataset:
pred = self.pipeline(example["text"])[0]["label"]
label = example["intent"]
preds.append(intents.str2int(pred))
labels.append(label)
accuracy = accuracy_score.compute(predictions=preds, references=labels)
print(f"Accuracy on test set - {accuracy['accuracy']:.3f}")
return accuracy
PerformanceBenchmark.compute_accuracy = compute_accuracy接下来,让我们使用 torch.save()PyTorch 中的函数将模型序列化到磁盘来计算模型的大小。在底层,torch.save()使用 Python 的pickle模块,可用于保存从模型到张量到普通 Python 对象的任何内容。在 PyTorch 中,推荐的保存模型的方法是使用 its state_dict,这是一个 Python 字典,将模型中的每一层映射到其可学习的参数(即权重和偏差)。让我们看看state_dict我们的基线模型中存储了什么:
list(pipe.model.state_dict().items())[42]('bert.encoder.layer.2.attention.self.value.weight',
tensor([[-1.0526e-02, -3.2215e-02, 2.2097e-02, ..., -6.0953e-03,
4.6521e-03, 2.9844e-02],
[-1.4964e-02, -1.0915e-02, 5.2396e-04, ..., 3.2047e-05,
-2.6890e-02, -2.1943e-02] ,
[-2.9640e-02, -3.7842e-03, -1.2582e-02, ..., -1.0917e-02,
3.1152e-02, -9.7786e-03],
...,
[-1.5116e -02, -3.3226e-02, 4.2063e-02, ..., -5.2652e-03,
1.1093e-02, 2.9703e-03],
[-3.6809e-02, 5.6848e-02, -2.6544e -02, ..., -4.0114e-02,
6.7487e-03, 1.0511e-03],
[-2.4961e-02, 1.4747e-03, -5.4271e-02, ..., 2.0004e-02 ,
2.3981e-02, -4.2880e-02]]))
我们可以清楚地看到,每个键/值对对应于 BERT 中的特定层和张量。所以如果我们保存我们的模型:
torch.save(pipe.model.state_dict(), "model.pt")然后我们可以使用Path.stat()Python pathlib模块中的函数来获取有关底层文件的信息。特别是,Path("model.pt").stat().st_size会给我们以字节为单位的模型大小。让我们将它们放在 compute_size()函数中并将其添加到PerformanceBenchmark:
import torch
from pathlib import Path
def compute_size(self):
"""This overrides the PerformanceBenchmark.compute_size() method"""
state_dict = self.pipeline.model.state_dict()
tmp_path = Path("model.pt")
torch.save(state_dict, tmp_path)
# Calculate size in megabytes
size_mb = Path(tmp_path).stat().st_size / (1024 * 1024)
# Delete temporary file
tmp_path.unlink()
print(f"Model size (MB) - {size_mb:.2f}")
return {"size_mb": size_mb}
PerformanceBenchmark.compute_size = compute_size最后让我们实现这个time_pipeline()函数,以便我们可以计算每个查询的平均延迟时间。对于此应用程序,延迟是指将文本查询输入管道并从模型返回预测意图所需的时间。在引擎盖下,管道还标记了文本,但这比生成预测快了大约一千倍,因此对整体延迟的贡献可以忽略不计。测量代码片段执行时间的一种简单方法是使用perf_counter()Pythontime模块中的函数。此函数比函数具有更好的时间分辨率time.time(),非常适合获得精确的结果。
我们可以perf_counter()通过传递我们的测试查询并计算开始和结束之间的时间差(以毫秒为单位)来为我们的管道计时:
from time import perf_counter
for _ in range(3):
start_time = perf_counter()
_ = pipe(query)
latency = perf_counter() - start_time
print(f"Latency (ms) - {1000 * latency:.3f}")Latency (ms) - 85.367 Latency (ms) - 85.241 Latency (ms) - 87.275
这些结果在延迟方面表现出相当大的差异,并表明每次运行代码时,通过管道计时一次会产生截然不同的结果。因此,我们将收集多次运行的延迟,然后使用结果分布来计算平均值和标准差,这将使我们了解值的分布。以下代码完成了我们需要的工作,并包含一个在执行实际定时运行之前预热 CPU 的阶段:
import numpy as np
def time_pipeline(self, query="What is the pin number for my account?"):
"""This overrides the PerformanceBenchmark.time_pipeline() method"""
latencies = []
# Warmup
for _ in range(10):
_ = self.pipeline(query)
# Timed run
for _ in range(100):
start_time = perf_counter()
_ = self.pipeline(query)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
print(f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}")
return {"time_avg_ms": time_avg_ms, "time_std_ms": time_std_ms}
PerformanceBenchmark.time_pipeline = time_pipeline为简单起见,我们将使用相同的query值对所有模型进行基准测试。通常,延迟取决于查询长度,一个好的做法是使用模型在生产环境中可能遇到的查询对模型进行基准测试。
现在我们的PerformanceBenchmark课程已经完成,让我们试一试吧!让我们从对我们的 BERT 基线进行基准测试开始。对于基线模型,我们只需要传递我们希望对其执行基准测试的管道和数据集。我们将在perf_metrics字典中收集结果以跟踪每个模型的性能:
pb = PerformanceBenchmark(pipe, clinc["test"])
perf_metrics = pb.run_benchmark()Model size (MB) - 418.16 Average latency (ms) - 54.20 +\- 1.91 Accuracy on test set - 0.867
现在我们有了一个参考点,让我们看看我们的第一个压缩技术:知识蒸馏。
笔记
平均延迟值将根据您运行的硬件类型而有所不同。例如,您通常可以通过在 GPU 上运行推理来获得更好的性能,因为它支持批处理。就本章而言,重要的是模型之间延迟的相对差异。一旦我们确定了性能最佳的模型,我们就可以探索不同的后端,以在需要时减少绝对延迟。
通过知识蒸馏使模型更小
知识蒸馏是一种通用方法,用于训练较小的学生模型以模仿较慢、较大但表现更好的教师的行为。最初于 2006 年在集成模型的背景下引入3,后来在 2015 年的一篇著名论文中得到普及,该论文将该方法推广到深度神经网络并将其应用于图像分类和自动语音识别。4
鉴于使用不断增加的参数计数(在撰写本文时最大的参数计数超过一万亿个)预训练语言模型的趋势,5知识蒸馏也已成为压缩这些巨大模型并使它们更适合构建实用的流行策略应用程序。
用于微调的知识蒸馏
那么知识是如何在培训过程中真正从老师“提炼”或转移给学生的呢?对于诸如微调之类的监督任务,主要思想是通过教师的“软概率”分布来增加基本事实标签,从而为学生提供补充信息以供学习。例如,如果我们的基于 BERT 的分类器将高概率分配给多个意图,那么这可能表明这些意图在特征空间中彼此靠近。通过训练学生模仿这些概率,目标是提炼出教师所学的一些“黑暗知识” 6——即仅从标签中无法获得的知识。
从数学上讲,它的工作方式如下。假设我们将输入序列x提供给教师以生成 logits 向量(X) = [z1(X),...,zN(X)]。我们可以通过应用 softmax 函数将这些 logit 转换为概率:
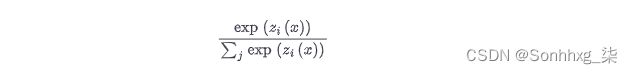
然而,这并不是我们想要的,因为在许多情况下,老师会给一个班级分配一个高概率,而所有其他班级的概率都接近于零。 发生这种情况时,教师不会提供超出真实标签的额外信息,因此我们通过在应用 softmax 之前使用温度超参数T缩放 logits 来“软化”概率: 7
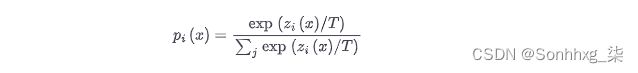
如图 8-3所示,较高的T值 会在类上产生更柔和的概率分布,并揭示更多关于教师为每个训练示例学习的决策边界的信息。什么时候吨=1我们恢复原始的 softmax 分布。

图 8-3。one-hot 编码的硬标签(左)、softmax 概率(中)和软化类别概率(右)的比较
由于学生也产生软化概率 qi(X)就其本身而言,我们可以使用 Kullback-Leibler (KL)散度来衡量两个概率分布之间的差异:

通过 KL 散度,我们可以计算出在近似教师与学生的概率分布时损失了多少。这使我们能够定义知识蒸馏损失:

在哪里T^2是一个归一化因子,用于解释软标签产生的梯度大小为1/T^2. 对于分类任务,学生损失是蒸馏损失与通常的交叉熵损失的加权平均值大号C和基本事实标签:

在哪里一个是控制每个损失的相对强度的超参数。整个流程示意图如图8-4所示;在推理时将温度设置为 1 以恢复标准的 softmax 概率。

图 8-4。知识蒸馏过程
预训练的知识蒸馏
知识蒸馏也可以在预训练期间使用,以创建一个通用的学生,随后可以在下游任务上进行微调。在这种情况下,教师是一个像 BERT 一样的预训练语言模型,它将其关于掩码语言建模的知识传递给学生。例如,在 DistilBERT 论文中,8掩蔽语言建模损失大号米l米增加了知识蒸馏的术语和余弦嵌入损失 Lcos=1-cos(Hs,Ht)对齐教师和学生之间隐藏状态向量的方向:

由于我们已经有了一个微调的 BERT-base 模型,让我们看看如何使用知识蒸馏来微调一个更小更快的模型。为此,我们需要一种方法来增加交叉熵损失大号ķD学期。幸运的是,我们可以通过创建自己的教练来做到这一点!
创建知识蒸馏培训师
为了实现知识蒸馏,我们需要在 Trainer基类中添加一些东西:
-
新的超参数一个和T,它们控制蒸馏损失的相对权重以及标签的概率分布应该平滑多少
-
微调的教师模型,在我们的例子中是基于 BERT 的
-
一种新的损失函数,将交叉熵损失与知识蒸馏损失相结合
添加新的超参数非常简单,因为我们只需要子类化TrainingArguments并将它们包含为新属性:
from transformers import TrainingArguments
class DistillationTrainingArguments(TrainingArguments):
def __init__(self, *args, alpha=0.5, temperature=2.0, **kwargs):
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature对于训练器本身,我们需要一个新的损失函数。实现这一点的方法是Trainer对方法进行子类化和覆盖 compute_loss()以包含知识蒸馏损失项 大号ķD:
import torch.nn as nn
import torch.nn.functional as F
from transformers import Trainer
class DistillationTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher_model = teacher_model
def compute_loss(self, model, inputs, return_outputs=False):
outputs_stu = model(**inputs)
# Extract cross-entropy loss and logits from student
loss_ce = outputs_stu.loss
logits_stu = outputs_stu.logits
# Extract logits from teacher
with torch.no_grad():
outputs_tea = self.teacher_model(**inputs)
logits_tea = outputs_tea.logits
# Soften probabilities and compute distillation loss
loss_fct = nn.KLDivLoss(reduction="batchmean")
loss_kd = self.args.temperature ** 2 * loss_fct(
F.log_softmax(logits_stu / self.args.temperature, dim=-1),
F.softmax(logits_tea / self.args.temperature, dim=-1))
# Return weighted student loss
loss = self.args.alpha * loss_ce + (1. - self.args.alpha) * loss_kd
return (loss, outputs_stu) if return_outputs else loss让我们稍微解压一下这段代码。当我们实例化时, DistillationTrainer我们teacher_model会与已经针对我们的任务进行微调的老师进行争论。接下来,在该 compute_loss()方法中,我们从学生和教师中提取 logits,按温度对其进行缩放,然后使用 softmax 对其进行归一化,然后将它们传递给 PyTorch 的nn.KLDivLoss() 函数以计算 KL 散度。一个怪癖 nn.KLDivLoss()是它期望以对数概率形式的输入和作为正常概率的标签。这就是为什么我们使用该F.log_softmax()函数对学生的 logits 进行归一化,而教师的 logits 则使用标准的 softmax 转换为概率。中的 reduction=batchmean参数nn.KLDivLoss()指定我们在批次维度上平均损失。
小费
您还可以使用Transformers 库的 Keras API 执行知识蒸馏。为此,您需要实现一个覆盖
train_step()test_step()、compile()和tf.keras.Model()方法的自定义Distiller类。有关如何执行此操作的示例,请参阅Keras 文档。
选择一个好的学生初始化
现在我们有了自定义培训师,您可能遇到的第一个问题是我们应该为学生选择哪种预培训语言模型?一般来说,我们应该为学生选择一个更小的模型来减少延迟和内存占用。文献中的一个很好的经验法则是,当教师和学生的模型类型相同时,知识蒸馏的效果最好。9一个可能的原因是,不同的模型类型,比如 BERT 和 RoBERTa,可能有不同的输出嵌入空间,这会阻碍学生模仿老师的能力。在我们的案例研究中,教师是 BERT,因此 DistilBERT 是初始化学生的自然候选者,因为它的参数减少了 40%,并且已被证明在下游任务上取得了很好的结果。
首先,我们需要对查询进行标记和编码,所以让我们从 DistilBERT 实例化标记器并创建一个简单的tokenize_text()函数来处理预处理:
from transformers import AutoTokenizer
student_ckpt = "distilbert-base-uncased"
student_tokenizer = AutoTokenizer.from_pretrained(student_ckpt)
def tokenize_text(batch):
return student_tokenizer(batch["text"], truncation=True)
clinc_enc = clinc.map(tokenize_text, batched=True, remove_columns=["text"])
clinc_enc = clinc_enc.rename_column("intent", "labels")在这里,我们已经删除了该text列,因为我们不再需要它,并且我们还将该intent列重命名为,labels 以便培训师可以自动检测到它。10
现在我们已经处理了我们的文本,接下来我们需要做的是compute_metrics()为我们的DistillationTrainer. 我们还将把我们所有的模型推送到 Hugging Face Hub,所以让我们从登录我们的帐户开始:
from huggingface_hub import notebook_login
notebook_login()接下来,我们将定义在训练期间要跟踪的指标。正如我们在性能基准测试中所做的那样,我们将使用准确性作为主要指标。accuracy_score()这意味着我们可以在compute_metrics()我们将包含 的函数中重用我们的函数DistillationTrainer:
def compute_metrics(pred):
predictions, labels = pred
predictions = np.argmax(predictions, axis=1)
return accuracy_score.compute(predictions=predictions, references=labels)在这个函数中,来自序列建模头的预测以 logits 的形式出现,因此我们使用该np.argmax()函数来找到最自信的类别预测并将其与真实标签进行比较。
接下来我们需要定义训练参数。为了热身,我们将设置一个=1看看 DistilBERT 在没有老师发出任何信号的情况下表现如何。11然后我们将我们的微调模型推送到一个名为 的新存储库 distilbert-base-uncased-finetuned-clinc,所以我们只需要在 的output_dir参数中指定它DistillationTrainingArguments:
batch_size = 48
finetuned_ckpt = "distilbert-base-uncased-finetuned-clinc"
student_training_args = DistillationTrainingArguments(
output_dir=finetuned_ckpt, evaluation_strategy = "epoch",
num_train_epochs=5, learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size, alpha=1, weight_decay=0.01,
push_to_hub=True)我们还调整了一些默认超参数值,例如 epoch 数、权重衰减和学习率。接下来要做的是初始化一个学生模型。由于我们将使用训练器进行多次运行,因此我们将创建一个 student_init()函数来在每次新运行时初始化模型。当我们将此函数传递给 时DistillationTrainer,这将确保我们每次调用该train()方法时都初始化一个新模型。
我们需要做的另一件事是为学生模型提供每个意图和标签 ID 之间的映射。这些映射可以从我们在管道中下载的基于 BERT 的模型中获得:
id2label = pipe.model.config.id2label
label2id = pipe.model.config.label2id有了这些映射,我们现在可以使用我们在第3章和第4AutoConfig章中遇到的类帽创建自定义模型配置。让我们使用它为我们的学生创建一个配置,其中包含有关标签映射的信息:
from transformers import AutoConfig
num_labels = intents.num_classes
student_config = (AutoConfig
.from_pretrained(student_ckpt, num_labels=num_labels,
id2label=id2label, label2id=label2id))在这里,我们还指定了我们的模型应该期望的类的数量。然后我们可以将此配置提供给AutoModelForSequenceClassification类的from_pretrained() 功能,如下所示:
import torch
from transformers import AutoModelForSequenceClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def student_init():
return (AutoModelForSequenceClassification
.from_pretrained(student_ckpt, config=student_config).to(device))现在我们已经拥有了蒸馏训练器所需的所有成分,所以让我们加载教师并进行微调:
teacher_ckpt = "transformersbook/bert-base-uncased-finetuned-clinc"
teacher_model = (AutoModelForSequenceClassification
.from_pretrained(teacher_ckpt, num_labels=num_labels)
.to(device))distilbert_trainer = DistillationTrainer(model_init=student_init,
teacher_model=teacher_model, args=student_training_args,
train_dataset=clinc_enc['train'], eval_dataset=clinc_enc['validation'],
compute_metrics=compute_metrics, tokenizer=student_tokenizer)
distilbert_trainer.train()| Epoch | 训练损失 | 验证损失 | 准确性 |
|---|---|---|---|
| 1 | 4.2923 | 3.289337 | 0.742258 |
| 2 | 2.6307 | 1.883680 | 0.828065 |
| 3 | 1.5483 | 1.158315 | 0.896774 |
| 4 | 1.0153 | 0.861815 | 0.909355 |
| 5 | 0.7958 | 0.777289 | 0.917419 |
与基于 BERT 的教师达到的 94% 相比,验证集上 92% 的准确率看起来相当不错。现在我们已经对 DistilBERT 进行了微调,让我们将模型推送到 Hub,以便我们以后可以重用它:
distilbert_trainer.push_to_hub("Training completed!")现在我们的模型安全地存储在 Hub 上,我们可以立即在管道中使用它来进行性能基准测试:
finetuned_ckpt = "transformersbook/distilbert-base-uncased-finetuned-clinc"
pipe = pipeline("text-classification", model=finetuned_ckpt)然后我们可以将此管道传递给我们的PerformanceBenchmark类以计算与此模型相关的指标:
optim_type = "DistilBERT"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())Model size (MB) - 255.89 Average latency (ms) - 27.53 +\- 0.60 Accuracy on test set - 0.858
为了将这些结果与我们的基线进行比较,让我们创建一个准确度与延迟的散点图,每个点的半径对应于磁盘上模型的大小。以下函数执行我们需要的操作,并将当前优化类型标记为虚线圆圈,以帮助与之前的结果进行比较:
import pandas as pd
def plot_metrics(perf_metrics, current_optim_type):
df = pd.DataFrame.from_dict(perf_metrics, orient='index')
for idx in df.index:
df_opt = df.loc[idx]
# Add a dashed circle around the current optimization type
if idx == current_optim_type:
plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,
alpha=0.5, s=df_opt["size_mb"], label=idx,
marker='$\u25CC$')
else:
plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,
s=df_opt["size_mb"], label=idx, alpha=0.5)
legend = plt.legend(bbox_to_anchor=(1,1))
for handle in legend.legendHandles:
handle.set_sizes([20])
plt.ylim(80,90)
# Use the slowest model to define the x-axis range
xlim = int(perf_metrics["BERT baseline"]["time_avg_ms"] + 3)
plt.xlim(1, xlim)
plt.ylabel("Accuracy (%)")
plt.xlabel("Average latency (ms)")
plt.show()
plot_metrics(perf_metrics, optim_type)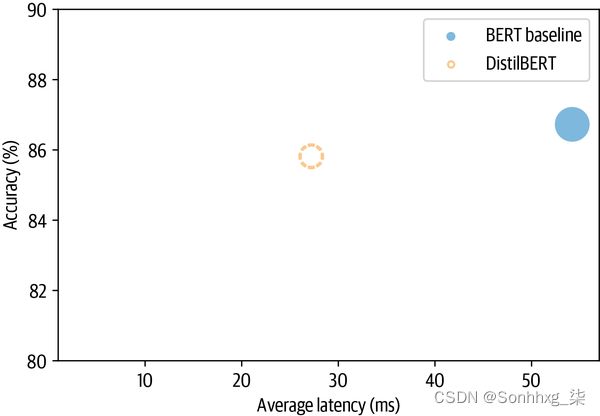
从图中我们可以看到,通过使用更小的模型,我们设法显着降低了平均延迟。而这一切的代价只是精度降低了 1% 以上!让我们看看我们是否可以通过包括老师的蒸馏损失并找到好的值来缩小最后一个差距一个和 T。 _
使用 Optuna 找到好的超参数
找到好的价值一个和T,我们可以在 2D 参数空间上进行网格搜索。但更好的选择是使用Optuna 12,它是专为此类任务设计的优化框架。Optuna 根据通过多次试验优化的目标函数来制定搜索问题。例如,假设我们希望最小化 Rosenbrock 的“香蕉函数”:
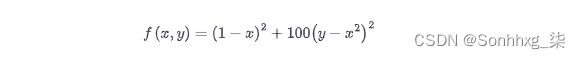
这是一个著名的优化框架测试用例。如图 8-5所示 ,该函数的名称来自曲线轮廓,并且在(x,y)=(1,1). 寻找山谷是一个简单的优化问题,但收敛到全局最小值却不是。

图 8-5。两个变量的 Rosenbrock 函数图
在 Optuna 中,我们可以找到最小值F(x,y)通过定义一个objective()返回值的函数 F(x,y):
def objective(trial):
x = trial.suggest_float("x", -2, 2)
y = trial.suggest_float("y", -2, 2)
return (1 - x) ** 2 + 100 * (y - x ** 2) ** 2该trial.suggest_float对象指定要从中均匀采样的参数范围;Optuna 还分别为整数和分类参数提供suggest_int和 。suggest_categoricalOptuna 收集多个试验作为一项研究,因此要创建一个,我们只需将objective()函数传递给study.optimize()如下:
import optuna
study = optuna.create_study()
study.optimize(objective, n_trials=1000)研究完成后,我们可以找到以下最佳参数:
study.best_params{'x':1.003024865971437,'y':1.00315167589307}
我们看到,经过一千次试验,Optuna 设法找到了合理接近全局最小值的x和y值。要在 Transformers 中使用 Optuna ,我们使用类似的逻辑,首先定义我们希望优化的超参数空间。此外一个 和T,我们将包括训练时期的数量 如下:
def hp_space(trial):
return {"num_train_epochs": trial.suggest_int("num_train_epochs", 5, 10),
"alpha": trial.suggest_float("alpha", 0, 1),
"temperature": trial.suggest_int("temperature", 2, 20)}使用 运行超参数搜索Trainer非常简单;我们只需要指定要运行的试验次数和优化的方向。因为我们想要尽可能高的精度,所以我们在训练器direction="maximize"的hyperparameter_search()方法中指定并传递超参数搜索空间,如下所示:
best_run = distilbert_trainer.hyperparameter_search(
n_trials=20, direction="maximize", hp_space=hp_space)该hyperparameter_search()方法返回一个BestRun对象,其中包含最大化的目标值(默认情况下,所有指标的总和)以及它用于该运行的超参数:
print(best_run)BestRun(run_id='1', objective=0.927741935483871,
hyperparameters={'num_train_epochs': 10, 'alpha': 0.12468168730193585,
'temperature': 7})
这个值一个告诉我们大部分训练信号来自知识蒸馏项。让我们用这些值更新我们的训练参数并运行最终的训练运行:
for k,v in best_run.hyperparameters.items():
setattr(student_training_args, k, v)
# Define a new repository to store our distilled model
distilled_ckpt = "distilbert-base-uncased-distilled-clinc"
student_training_args.output_dir = distilled_ckpt
# Create a new Trainer with optimal parameters
distil_trainer = DistillationTrainer(model_init=student_init,
teacher_model=teacher_model, args=student_training_args,
train_dataset=clinc_enc['train'], eval_dataset=clinc_enc['validation'],
compute_metrics=compute_metrics, tokenizer=student_tokenizer)
distil_trainer.train();| Epoch | 训练损失 | 验证损失 | 准确性 |
|---|---|---|---|
| 1 | 0.9031 | 0.574540 | 0.736452 |
| 2 | 0.4481 | 0.285621 | 0.874839 |
| 3 | 0.2528 | 0.179766 | 0.918710 |
| 4 | 0.1760 | 0.139828 | 0.929355 |
| 5 | 0.1416 | 0.121053 | 0.934839 |
| 6 | 0.1243 | 0.111640 | 0.934839 |
| 7 | 0.1133 | 0.106174 | 0.937742 |
| 8 | 0.1075 | 0.103526 | 0.938710 |
| 9 | 0.1039 | 0.101432 | 0.938065 |
| 10 | 0.1018 | 0.100493 | 0.939355 |
值得注意的是,我们已经能够训练学生与老师的准确性相匹配,尽管它的参数数量几乎只有一半!让我们将模型推送到 Hub 以供将来使用:
distil_trainer.push_to_hub("Training complete")对我们的蒸馏模型进行基准测试
现在我们有了一个准确的学生,让我们创建一个管道并重做我们的基准测试,看看我们在测试集上的表现如何:
distilled_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
pipe = pipeline("text-classification", model=distilled_ckpt)
optim_type = "Distillation"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())Model size (MB) - 255.89 Average latency (ms) - 25.96 +\- 1.63 Accuracy on test set - 0.868
为了将这些结果放在上下文中,让我们也用我们的plot_metrics()函数将它们可视化:
plot_metrics(perf_metrics, optim_type)
正如预期的那样,模型大小和延迟与 DistilBERT 基准相比基本保持不变,但准确度有所提高,甚至超过了教师的表现!解释这一令人惊讶的结果的一种方法是,教师可能没有像学生那样系统地进行微调。这很好,但我们实际上可以使用一种称为量化的技术进一步压缩我们的蒸馏模型。这是下一节的主题。
通过量化使模型更快
我们现在已经看到,通过知识蒸馏,我们可以通过将信息从老师转移到较小的学生来减少运行推理的计算和内存成本。量化采用不同的方法;它不是减少计算次数,而是通过使用低精度数据类型(如 8 位整数 (INT8) 而不是通常的 32 位浮点数 (FP32) 来表示权重和激活)来提高计算效率。减少位数意味着生成的模型需要更少的内存存储,并且使用整数运算可以更快地执行矩阵乘法等操作。值得注意的是,这些性能提升可以在几乎没有准确性损失的情况下实现!
浮点数和定点数入门
今天的大多数转换器都使用浮点数(通常是 FP32 或 FP16 和 FP32 的混合)进行了预训练和微调,因为它们提供了适应不同范围的权重、激活和梯度所需的精度。像 FP32 这样的浮点数表示一个 32 位序列,这些位序列按照符号、指数和有效数进行分组。符号决定数字是正数还是负数,而有效数字对应于有效数字的数量,这些数字使用某个固定基数的指数进行缩放(通常为二进制 2 或十进制 10)。
例如,数字 137.035 可以通过以下算法表示为十进制浮点数:
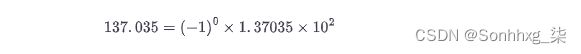
其中 1.37035 是有效数,2 是以 10 为底的指数。通过指数,我们可以表示范围广泛的实数,小数点或二进制点可以放置在相对于有效数字的任何位置(因此名称为“浮动-观点”)。
然而,一旦模型被训练,我们只需要前向传递来运行推理,因此我们可以降低数据类型的精度,而不会过多影响精度。对于神经网络,通常对低精度数据类型使用定点格式,其中实数表示为B位整数,这些整数由相同类型的所有变量的公共因子缩放。例如,137.035 可以表示为按 1/1,000 缩放的整数 137,035。我们可以通过调整比例因子来控制定点数的范围和精度。
量化背后的基本思想是,我们可以通过映射它们的范围来“离散化”每个张量中的浮点值f [fmax,fmin]变成一个更小的[qmax,qmin] 的定点数 q, 并在两者之间线性分布所有值。在数学上,这种映射由以下等式描述:

其中比例因子小号是一个正浮点数和常数从具有相同的类型 q并且被称为零点,因为它对应于浮点值的量化值F=0. 请注意,映射需要仿射,以便我们在对定点数进行去量化时返回浮点数。13转换示意图如图 8-6所示。

图 8-6。将浮点数量化为无符号 8 位整数(由 Manas Sahni 提供)
现在,transformer(以及更普遍的深度神经网络)是量化的主要候选者的主要原因之一是权重和激活值倾向于在相对较小的范围内取值。这意味着我们不必将所有可能的 FP32 数字压缩到,比如说,28=256INT8 表示的数字。为了看到这一点,让我们从我们的蒸馏模型中挑选一个注意力权重矩阵并绘制值的频率分布:
import matplotlib.pyplot as plt
state_dict = pipe.model.state_dict()
weights = state_dict["distilbert.transformer.layer.0.attention.out_lin.weight"]
plt.hist(weights.flatten().numpy(), bins=250, range=(-0.3,0.3), edgecolor="C0")
plt.show()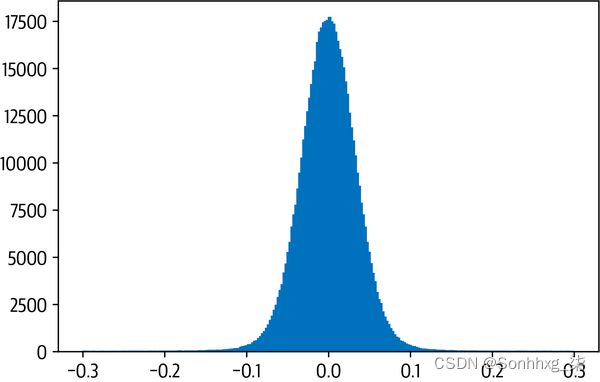
正如我们所看到的,权重的值分布在小范围内 [-0.1,0.1] 大约为零。现在,假设我们想把这个张量量化为一个有符号的 8 位整数。在这种情况下,我们的整数可能值的范围是 [qmax,qmin] = [-128,127]。零点与 FP32 的零点重合,按上式计算比例因子:
zero_point = 0
scale = (weights.max() - weights.min()) / (127 - (-128))为了获得量化的张量,我们只需要反转映射 q=f/S+Z,钳位值,将它们四舍五入到最接近的整数,并使用以下函数Tensor.char()以torch.int8数据类型表示结果:
(weights / scale + zero_point).clamp(-128, 127).round().char()tensor([[ -5, -8, 0, ..., -6, -4, 8],
[ 8, 3, 1, ..., -4, 7, 0],
[ -9, -6, 5, ..., 1, 5, -3],
...,
[ 6, 0, 12, ..., 0, 6, -1],
[ 0, -2, -12, ..., 12, -7, -13],
[-13, -1, -10, ..., 8, 2, -2]], dtype=torch.int8)
太好了,我们刚刚量化了我们的第一个张量!在 PyTorch 中,我们可以通过将quantize_per_tensor() 函数与量化数据类型一起使用来简化转换,该数据类型torch.qint针对整数算术运算进行了优化:
from torch import quantize_per_tensor
dtype = torch.qint8
quantized_weights = quantize_per_tensor(weights, scale, zero_point, dtype)
quantized_weights.int_repr()tensor([[ -5, -8, 0, ..., -6, -4, 8],
[ 8, 3, 1, ..., -4, 7, 0],
[ -9, -6, 5, ..., 1, 5, -3],
...,
[ 6, 0, 12, ..., 0, 6, -1],
[ 0, -2, -12, ..., 12, -7, -13],
[-13, -1, -10, ..., 8, 2, -2]], dtype=torch.int8)
图 8-7中的图非常清楚地显示了由仅精确映射一些权重值并舍入其余部分所引起的离散化。

图 8-7。量化对变压器权重的影响
为了完善我们的小分析,让我们比较计算两个权重张量与 FP32 和 INT8 值的乘积需要多长时间。对于 FP32 张量,我们可以使用 PyTorch 的漂亮@运算符将它们相乘:
%%timeit
weights @ weights393 µs ± 3.84 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
对于量化张量,我们需要QFunctional包装类,以便我们可以使用特殊torch.qint8数据类型执行操作:
from torch.nn.quantized import QFunctional
q_fn = QFunctional()这个类支持各种基本操作,比如加法,在我们的例子中,我们可以对量化张量的乘法进行计时,如下所示:
%%timeit
q_fn.mul(quantized_weights, quantized_weights)23.3 µs ± 298 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
与我们的 FP32 计算相比,使用 INT8 张量几乎快 100 倍!通过使用专门的后端来有效地运行量化算子,可以获得更大的收益。在本书写作之时,PyTorch 支持:
-
支持 AVX2 或更高版本的 x86 CPU
-
ARM CPU(通常在移动/嵌入式设备中找到)
由于 INT8 数字的位数比 FP32 数字少四倍,因此量化还可将内存存储需求减少多达四倍。Tensor.storage()在我们的简单示例中,我们可以通过使用函数和getsizeof() Pythonsys模块中的函数来比较权重张量及其量化表亲的底层存储大小来验证这一点:
import sys
sys.getsizeof(weights.storage()) / sys.getsizeof(quantized_weights.storage())3.999633833760527
对于全尺寸转换器,实际压缩率取决于量化的层(正如我们将在下一节中看到的,通常只有线性层会被量化)。
那么量化有什么问题呢?更改我们模型中所有计算的精度会在模型计算图中的每个点处引入小的干扰,这会复合并影响模型的性能。量化模型有多种方法,各有利弊。对于深度神经网络,通常有三种主要的量化方法:
动态量化
当使用动态量化时,训练期间没有任何变化,并且仅在推理期间执行自适应。与我们将讨论的所有量化方法一样,模型的权重在推理时间之前被转换为 INT8。除了权重,模型的激活也被量化。这种方法是动态的,因为量化是动态发生的。这意味着可以使用高度优化的 INT8 函数计算所有矩阵乘法。在这里讨论的所有量化方法中,动态量化是最简单的一种。然而,通过动态量化,激活以浮点格式写入和读取到内存。整数和浮点之间的这种转换可能是性能瓶颈。
静态量化
我们可以通过预先计算量化方案来避免转换为浮点数,而不是动态计算激活的量化。静态量化通过在推理时间之前观察数据的代表性样本上的激活模式来实现这一点。计算出理想的量化方案,然后保存。这使我们能够跳过 INT8 和 FP32 值之间的转换并加快计算速度。但是,它需要访问良好的数据样本并在管道中引入了一个额外的步骤,因为我们现在需要在执行推理之前训练和确定量化方案。静态量化还有一个方面没有解决:训练和推理期间的精度之间的差异,这导致模型的指标性能下降(例如,
量化感知训练
通过对 FP32 值的“假”量化,可以在训练期间有效地模拟量化的效果。在训练期间不使用 INT8 值,而是将 FP32 值四舍五入以模拟量化的效果。这是在前向和后向传递期间完成的,并且在模型度量方面比静态和动态量化提高了性能。
使用转换器运行推理的主要瓶颈是与这些模型中大量权重相关的计算和内存带宽。出于这个原因,动态量化是目前 NLP 中基于 Transformer 模型的最佳方法。在较小的计算机视觉模型中,限制因素是激活的内存带宽,这就是为什么通常使用静态量化(或在性能下降太明显的情况下进行量化感知训练)的原因。
在 PyTorch 中实现动态量化非常简单,只需一行代码即可完成:
from torch.quantization import quantize_dynamic
model_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt).to("cpu"))
model_quantized = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)在这里,我们传递给quantize_dynamic()全精度模型,并在该模型中指定要量化的 PyTorch 层类集。参数指定目标精度,dtype可以是 fp16或qint8。一个好的做法是选择您可以容忍的与评估指标相关的最低精度。在本章中,我们将使用 INT8,我们很快就会看到它对我们模型的准确性几乎没有影响。
对我们的量化模型进行基准测试
现在我们的模型已经量化,让我们通过基准测试并可视化结果:
pipe = pipeline("text-classification", model=model_quantized,
tokenizer=tokenizer)
optim_type = "Distillation + quantization"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())Model size (MB) - 132.40 Average latency (ms) - 12.54 +\- 0.73 Accuracy on test set - 0.876
plot_metrics(perf_metrics, optim_type)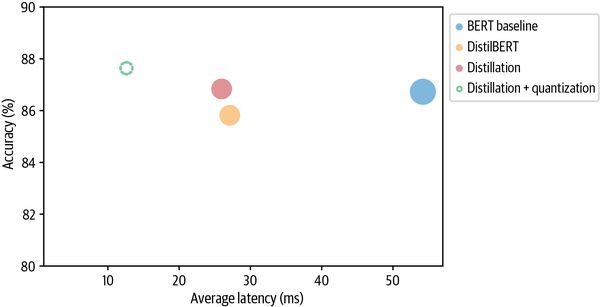
很好,量化模型的大小几乎是我们蒸馏模型的一半,甚至还略微提高了准确性!让我们看看我们是否可以使用称为 ONNX 运行时的强大框架将优化推向极限。
使用 ONNX 和 ONNX 运行时优化推理
ONNX是一种开放标准,它定义了一组通用的运算符和一种通用的文件格式,以在包括 PyTorch 和 TensorFlow 在内的各种框架中表示深度学习模型。14当模型导出为 ONNX 格式时,这些运算符用于构建计算图(通常称为中间表示),表示通过神经网络的数据流。图 8-8显示了基于 BERT 的此类图的示例,其中每个节点接收一些输入,应用类似AddorSqueeze,然后将输出馈送到下一组节点。
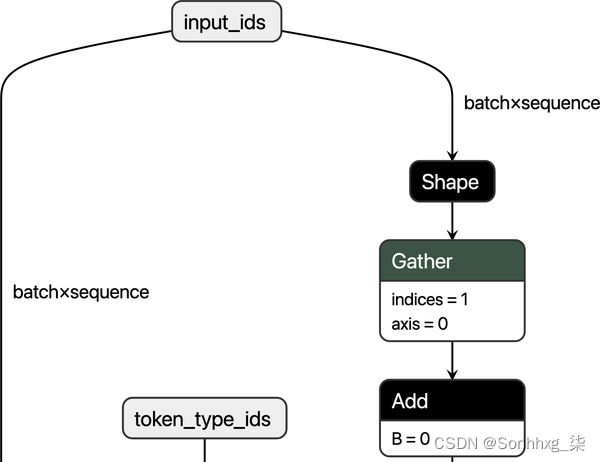
图 8-8。基于 BERT 的 ONNX 图的一部分,在 Netron 中可视化
通过使用标准化的运算符和数据类型公开图形,ONNX 可以轻松地在框架之间切换。例如,在 PyTorch 中训练的模型可以导出为 ONNX 格式,然后在 TensorFlow 中导入(反之亦然)。
ONNX 真正闪耀的地方在于它与专用加速器(如ONNX Runtime或简称 ORT)结合使用。15 ORT 提供了通过算子融合和常量折叠等技术优化 ONNX 图的工具,16并定义了执行提供程序的接口 ,允许您在不同类型的硬件上运行模型。这是一个强大的抽象。图 8-9显示了 ONNX 和 ORT 生态系统的高级架构。

图 8-9。ONNX 和 ONNX 运行时生态系统的架构(由 ONNX 运行时团队提供)
要查看 ORT 的实际效果,我们需要做的第一件事是将我们的提炼模型转换为 ONNX 格式。Transformers 库有一个名为的内置函数convert_graph_to_onnx.convert(),可通过以下步骤简化流程:
-
将模型初始化为
Pipeline. -
通过管道运行占位符输入,以便 ONNX 可以记录计算图。
-
定义动态轴以处理动态序列长度。
-
保存带有网络参数的图形。
要使用此功能,我们首先需要 为 ONNX设置一些OpenMP环境变量:
import os
from psutil import cpu_count
os.environ["OMP_NUM_THREADS"] = f"{cpu_count()}"
os.environ["OMP_WAIT_POLICY"] = "ACTIVE"OpenMP 是为开发高度并行化的应用程序而设计的 API。OMP_NUM_THREADS环境变量设置用于 ONNX 运行时并行计算的线程数,同时 指定OMP_WAIT_POLICY=ACTIVE等待线程应该处于活动状态(即,使用 CPU 处理器周期)。
接下来,让我们将蒸馏模型转换为 ONNX 格式。在这里我们需要指定参数 pipeline_name="text-classification",因为在转换期间convert()将模型包装在Transformerspipeline()函数中。除了model_ckpt,我们还通过 tokenizer 来初始化管道:
from transformers.convert_graph_to_onnx import convert
model_ckpt = "transformersbook/distilbert-base-uncased-distilled-clinc"
onnx_model_path = Path("onnx/model.onnx")
convert(framework="pt", model=model_ckpt, tokenizer=tokenizer,
output=onnx_model_path, opset=12, pipeline_name="text-classification")ONNX 使用运算符集将不可变的运算符规范组合在一起,因此opset=12对应于特定版本的 ONNX 库。
现在我们已经保存了模型,我们需要创建一个InferenceSession实例来为模型提供输入:
from onnxruntime import (GraphOptimizationLevel, InferenceSession,
SessionOptions)
def create_model_for_provider(model_path, provider="CPUExecutionProvider"):
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
session = InferenceSession(str(model_path), options, providers=[provider])
session.disable_fallback()
return sessiononnx_model = create_model_for_provider(onnx_model_path)现在,当我们调用 时onnx_model.run(),我们可以从 ONNX 模型中获取类 logits。让我们用测试集中的一个例子来测试一下。由于 from 的输出convert()告诉我们 ONNX 只需要 input_idsandattention_mask作为输入,我们需要label 从示例中删除该列:
inputs = clinc_enc["test"][:1]
del inputs["labels"]
logits_onnx = onnx_model.run(None, inputs)[0]
logits_onnx.shape(1, 151)
一旦我们有了logits, 我们可以通过获取 argmax 轻松获得预测的标签:
np.argmax(logits_onnx)61
这确实与基本事实标签一致:
clinc_enc["test"][0]["labels"]61
ONNX 模型与text-classification 管道不兼容,因此我们将创建自己的类来模仿核心行为:
from scipy.special import softmax
class OnnxPipeline:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def __call__(self, query):
model_inputs = self.tokenizer(query, return_tensors="pt")
inputs_onnx = {k: v.cpu().detach().numpy()
for k, v in model_inputs.items()}
logits = self.model.run(None, inputs_onnx)[0][0, :]
probs = softmax(logits)
pred_idx = np.argmax(probs).item()
return [{"label": intents.int2str(pred_idx), "score": probs[pred_idx]}]然后我们可以在我们的简单查询上测试它,看看我们是否恢复了 car_rental意图:
pipe = OnnxPipeline(onnx_model, tokenizer)
pipe(query)[{'label': 'car_rental', 'score': 0.7848334}]
太好了,我们的管道按预期工作。下一步是为 ONNX 模型创建性能基准。PerformanceBenchmark在这里,我们可以通过简单地覆盖 compute_size()方法并保持compute_accuracy()和 time_pipeline()方法保持不变来构建我们对类所做的工作。我们需要重写该 compute_size()方法的原因是我们不能依赖state_dictand torch.save()来测量模型的大小,因为从onnx_model 技术上讲,它是一个 ONNXInferenceSession对象,它无法访问 PyTorch 的属性nn.Module。无论如何,生成的逻辑很简单,可以按如下方式实现:
class OnnxPerformanceBenchmark(PerformanceBenchmark):
def __init__(self, *args, model_path, **kwargs):
super().__init__(*args, **kwargs)
self.model_path = model_path
def compute_size(self):
size_mb = Path(self.model_path).stat().st_size / (1024 * 1024)
print(f"Model size (MB) - {size_mb:.2f}")
return {"size_mb": size_mb}通过我们的新基准,让我们看看我们的蒸馏模型在转换为 ONNX 格式时的表现:
optim_type = "Distillation + ORT"
pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type,
model_path="onnx/model.onnx")
perf_metrics.update(pb.run_benchmark())Model size (MB) - 255.88 Average latency (ms) - 21.02 +\- 0.55 Accuracy on test set - 0.868
plot_metrics(perf_metrics, optim_type)
值得注意的是,转换为 ONNX 格式并使用 ONNX 运行时为我们的蒸馏模型(即图中的“蒸馏”圆圈)提高了延迟!让我们看看我们是否可以通过在混合中添加量化来挤出更多的性能。
与 PyTorch 类似,ORT 提供了三种量化模型的方法:动态、静态和量化感知训练。正如我们对 PyTorch 所做的那样,我们将对我们的蒸馏模型应用动态量化。在 ORT 中,量化是通过quantize_dynamic() 函数应用的,该函数需要到 ONNX 模型的路径进行量化,将量化后的模型保存到的目标路径,以及将权重降低到的数据类型:
from onnxruntime.quantization import quantize_dynamic, QuantType
model_input = "onnx/model.onnx"
model_output = "onnx/model.quant.onnx"
quantize_dynamic(model_input, model_output, weight_type=QuantType.QInt8)现在模型已经量化,让我们通过我们的基准运行它:
onnx_quantized_model = create_model_for_provider(model_output)
pipe = OnnxPipeline(onnx_quantized_model, tokenizer)
optim_type = "Distillation + ORT (quantized)"
pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type,
model_path=model_output)
perf_metrics.update(pb.run_benchmark())Model size (MB) - 64.20 Average latency (ms) - 9.24 +\- 0.29 Accuracy on test set - 0.877
plot_metrics(perf_metrics, optim_type)
与从 PyTorch 量化(蒸馏 + 量化 blob)获得的模型相比,ORT 量化将模型大小和延迟减少了约 30%。原因之一是 PyTorch 只优化了nn.Linear模块,而 ONNX 也量化了嵌入层。从图中我们还可以看到,与我们的 BERT 基线相比,将 ORT 量化应用于我们的蒸馏模型提供了几乎三倍的增益!
这结束了我们对加速变压器进行推理的技术的分析。我们已经看到,量化等方法通过降低表示的精度来减小模型大小。另一种减小尺寸的策略是完全删除一些权重。这种技术称为权重剪枝,它是下一节的重点。
使用权重修剪使模型更稀疏
到目前为止,我们已经看到知识蒸馏和权重量化在生成更快的推理模型方面非常有效,但在某些情况下,您可能还会对模型的内存占用有很大的限制。例如,如果我们的产品经理突然决定我们的文本助手需要部署在移动设备上,那么我们需要我们的意图分类器占用尽可能少的存储空间。为了完善我们对压缩方法的调查,让我们看看如何通过识别和删除网络中最不重要的权重来减少模型中的参数数量。
深度神经网络中的稀疏性
如图 8-10所示,剪枝背后的主要思想是在训练期间逐渐移除权重连接(以及潜在的神经元),使模型逐渐变得稀疏。生成的修剪模型具有较少数量的非零参数,然后可以以紧凑的稀疏矩阵格式存储。修剪也可以与量化相结合以获得进一步的压缩。
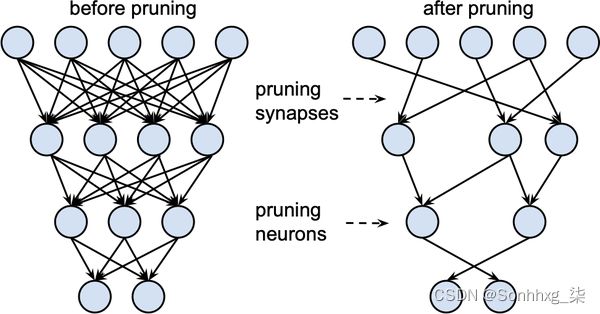
图 8-10。修剪前后的权重和神经元(宋涵提供)
权重修剪方法
在数学上,大多数权重修剪方法的工作方式是计算矩阵重要性分数,然后选择顶部ķ权重百分比:

有效,ķ作为一个新的超参数来控制模型中的稀疏程度——即零值权重的比例。较低的值ķ对应于稀疏矩阵。根据这些分数,我们可以定义一个掩码矩阵 掩盖权重在Wij在带有一些输入的前向传递期间Xi并有效地创建一个稀疏的激活网络ai:

正如诙谐的“Optimal Brain Surgeon”论文中所讨论的,每种修剪方法的核心17 是一组需要考虑的问题:
-
应该消除哪些权重?
-
应如何调整剩余权重以获得最佳性能?
-
如何以计算有效的方式完成这种网络修剪?
这些问题的答案说明了分数矩阵如何 是计算出来的,所以让我们从最早和最流行的剪枝方法之一开始:幅度剪枝。
幅度修剪
顾名思义,幅度剪枝根据权重的大小计算分数 =∣Wij∣1≤j,j≤n 然后从 =Topķ(). 在文献中,通常以迭代方式应用幅度修剪,首先训练模型以了解哪些连接是重要的,然后修剪最不重要的权重。18然后重新训练稀疏模型并重复该过程,直到达到所需的稀疏度。
这种方法的一个缺点是它对计算的要求很高:在修剪的每一步,我们都需要训练模型以使其收敛。因此,通常最好逐渐增加初始稀疏度si(通常为零)到最终值 sf经过一些步骤 ñ:19

这里的想法是更新二进制掩码每一个 D吨允许掩蔽权重在训练期间重新激活并从修剪过程引起的任何潜在准确性损失中恢复的步骤。如图 8-11所示 ,三次因子意味着权重剪枝率在早期阶段(当冗余权重的数量很大时)最高,并逐渐减小。

图 8-11。用于修剪的三次稀疏调度程序
幅度修剪的一个问题是它实际上是为纯监督学习而设计的,其中每个权重的重要性与手头的任务直接相关。相比之下,在迁移学习中,权重的重要性主要由预训练阶段决定,因此幅度修剪可以删除对微调任务很重要的连接。最近,Hugging Face 研究人员提出了一种称为运动修剪的自适应方法——让我们来看看。20
运动修剪
运动修剪背后的基本思想是在微调过程中逐渐去除权重,使模型逐渐变得稀疏。关键的新颖之处在于权重和分数都是在微调过程中学习的。因此,运动修剪中的分数不是直接从权重派生的(如幅度修剪),而是任意的,并且像任何其他神经网络参数一样通过梯度下降来学习。这意味着在后向传播中,我们还跟踪损失的梯度L关于分数Sij.
一旦学习了分数,就可以直接使用生成二进制掩码 =Topķ().21
运动修剪背后的直觉是,从零开始“移动”最多的权重是最重要的要保留的权重。换句话说,在微调期间正权重增加(负权重反之亦然),这相当于说随着权重远离零,分数增加。如图 8-12所示 ,这种行为不同于幅度修剪,后者选择离零最远的那些作为最重要的权重 。

图 8-12。幅度修剪(左)和运动修剪(右)期间移除的权重的比较
两种修剪方法之间的这些差异在剩余权重的分布中也很明显。如图 8-13所示 ,幅度剪枝产生两个权重簇,而运动剪枝产生更平滑的分布。
在撰写本书时, Transformers 不支持开箱即用的修剪方法。幸运的是,有一个名为 Neural Networks Block Movement Pruning的漂亮库实现了许多这些想法,如果内存限制是一个问题,我们建议检查一下。

图 8-13。幅度剪枝 (MaP) 和运动剪枝 (MvP) 的剩余权重分布
结论
我们已经看到,优化在生产环境中部署的转换器涉及到两个维度的压缩:延迟和内存占用。从微调模型开始,我们通过 ORT 应用蒸馏、量化和优化来显着减少这两者。特别是,我们发现 ORT 中的量化和转换以最少的努力获得了最大的收益。
尽管剪枝是减少 Transformer 模型存储大小的有效策略,但当前的硬件并未针对稀疏矩阵运算进行优化,这限制了该技术的实用性。然而,这是一个活跃的研究领域,当本书上架时,许多这些限制可能已经解决。
那么从这里到哪里呢?本章中的所有技术都可以适用于其他任务,例如问答、命名实体识别或语言建模。如果您发现自己难以满足延迟要求,或者您的模型耗尽了您所有的计算预算,我们建议您试一试。
在下一章中,我们将从性能优化转向探索每个数据科学家最糟糕的噩梦:处理很少或没有标签。