【定量分析、量化金融与统计学】R语言线性回归(2):一元线性回归实例
目录
一、前言
二、逐步讲解r语言程序
1.导入数据集并查看数据集的基本情况
2.查看数据分布情况
3.查看自变量因变量的散点图,判断线性关系
4.添加线性模型
5.回归,并查看回归的基本数据项
6.假设检验 F检验 ANOVA
7.预测与残差
8.残差
9.结论
10.模型的修正
一、前言
上次说了基本理论,今天说说例子:
我们用的数据集是啤酒的每周销量数据集:
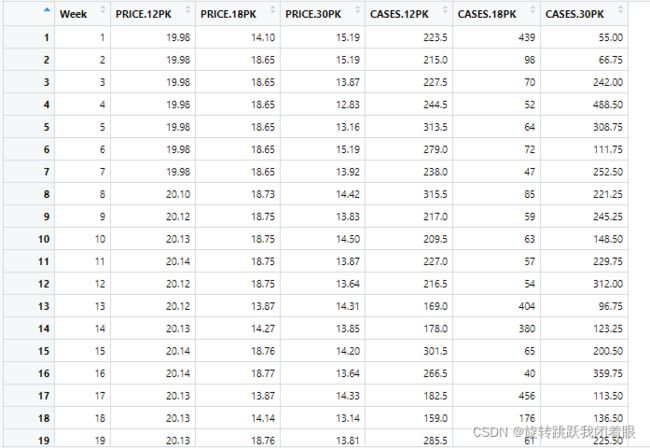
二、逐步讲解r语言程序
1.导入数据集并查看数据集的基本情况
x=read.csv(file.choose(), header=TRUE)
names(x)
summary(x)结果:

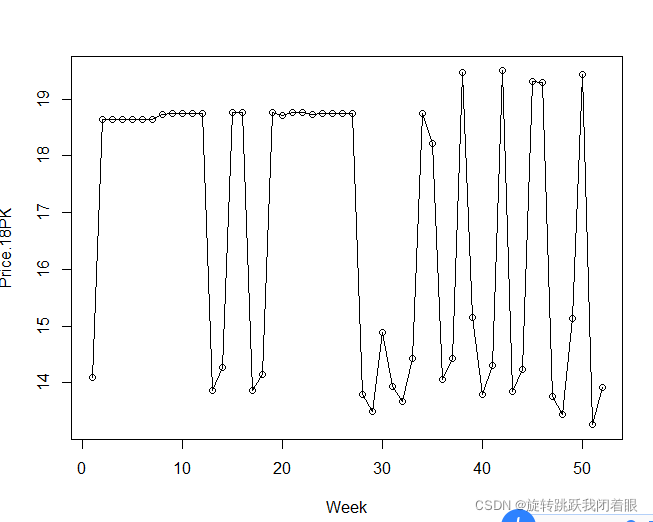
2.查看数据分布情况
plot(x$Week,x$PRICE.18PK,xlab="Week",ylab="Price.18PK")
lines(x$PRICE.18PK)结果:

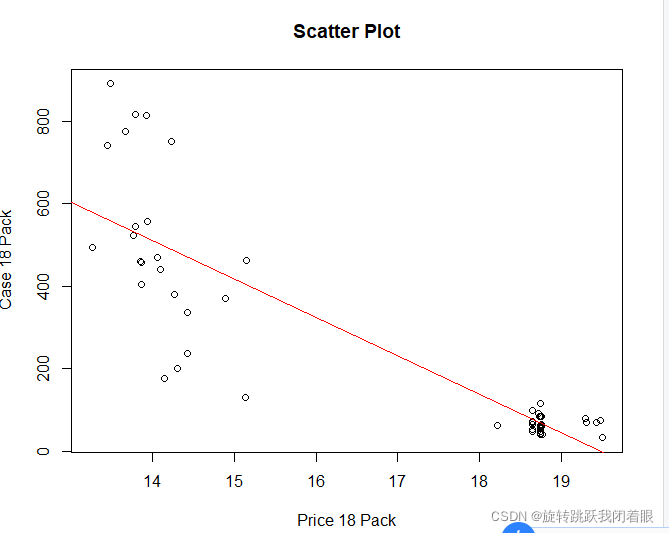
3.查看自变量因变量的散点图,判断线性关系
plot(x$PRICE.18PK,x$CASES.18PK, xlab="Price 18 Pack"
, ylab="Case 18 Pack", main="Scatter Plot")结果:

4.添加线性模型
fitModel<-lm(CASES.18PK~PRICE.18PK, data=x)
abline(fitModel, col="red")结果:
5.回归,并查看回归的基本数据项
regResult<-summary(fitModel)
regResult结果:
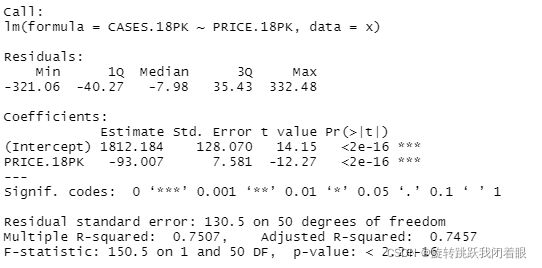
我们可以看到各种数据,这些数据讲用来判断这个模型是否合理。
6.假设检验 F检验 ANOVA
summary.aov(fitModel)结果:

相关性非常显著。
7.预测与残差
residualData<-resid(fitModel)
predicted<-predict(fitModel)
plot(predicted,residualData, xlab="Predicted Values", ylab="Residuals", col="red")结果: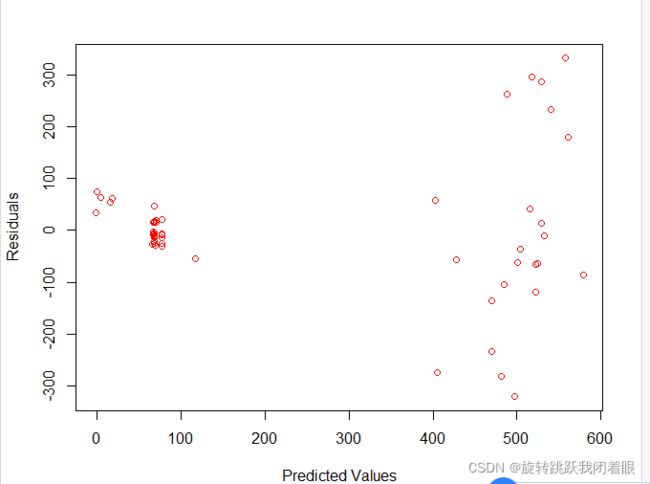
我们发现,这个拟合模型是有问题的
问题在于:当做出更大的预测时,该模型会产生更大的误差
回归模型中的一个假设是,不管自变量的值如何,误差在所有点上都应该有相同的方差。
因此,残差应表现为均值为零的正态分布
但是,这个模型显然在大预测值时过于离散了。这就是异方差的证据!!
对所有预测水平的方差不相同的误差!就叫做异方差问题!
8.残差
plot(x$Week,residualData)
abline(0, 0, col="red")结果:
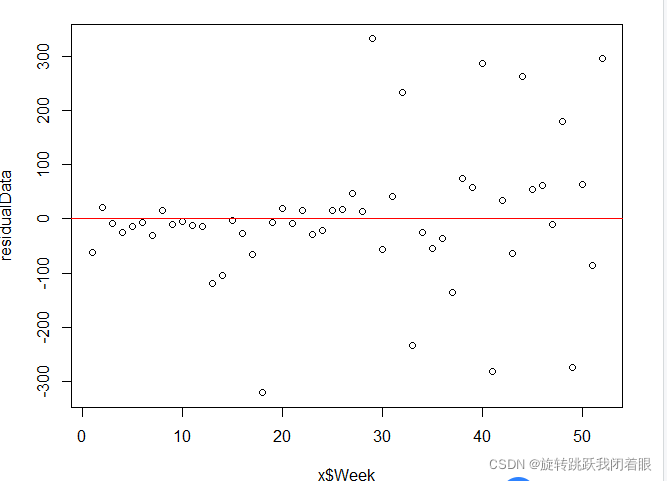
我们又发现一个问题,显然,在时间序列上,前半年的残差明显低于后半年,那么,我们可以说,这个啤酒厂在下半年出现了销量暴涨的事件,或者这个公司存在明显的人为控制销量的事情,这是不自然的。大部分的价格操纵和销售飙升都发生在下半年!
我们希望我们的残差是平缓的,而不是发散的

9.结论
在如此大的价格范围内,啤酒销量和啤酒价格之间的关系显然不是线性的。该模型违反了误差的同方差和正态分布假设。
并不是所有具有高R2值的模型都是好的!
10.模型的修正
- 添加新变量
- 将数据设置为子集
一个标准的方法是在拟合回归模型之前,对自变量和因变量都应用自然对数转换。
当一个简单的线性回归模型被拟合到记录变量上时,斜率系数表示因变量的预测百分比变化/自变量的百分比变化,而不管它们当前的水平。
因此,预计自变量的较大变化将导致边际效应的复合,而不是它们的线性外推。
install.packages("dplyr")
library("dplyr")
x<-mutate(x,ln_CASES.18PK=log10(x$CASES.18PK),ln_PRICE.18PK=log10(x$PRICE.18PK))
fitModel1<-lm(ln_CASES.18PK~ln_PRICE.18PK, data=x)
summary(fitModel1)
residualData<-resid(fitModel1)
predicted<-predict(fitModel1)
plot(predicted,residualData, xlab="Predicted Values", ylab="Residuals", col="red")
x<-mutate(x,ln_PRICE.12PK=log10(x$PRICE.12PK), ln_PRICE.30PK=log10(x$PRICE.30PK))
fitModel2<-lm(ln_CASES.18PK~ln_PRICE.18PK+ln_PRICE.12PK+ln_PRICE.30PK,data=x)
summary(fitModel2)结果:

R2更好了!
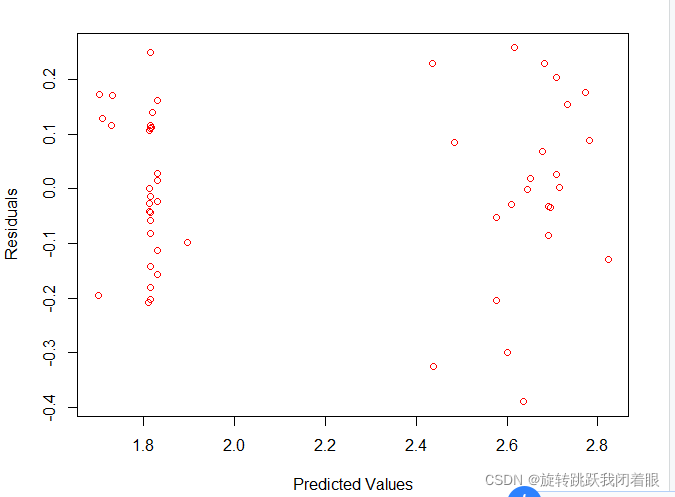
误差的方差更均匀地分布在所有的预测值上。
当然我们也可以加入其他的变量,让模型更好。这里就不多说了。