python中dataframe某列按照指定批量索引修改其单元格内容
文章目录
- 1 需求
- 2 举例搬代码
- 3 突破进展
- 4 感想
1 需求
我有一份关于地理位置的数据,但是地理位置信息是用户填写的,所以五花八门都有,如下
location.xlsx

我需要根据另外一份一二三四五线城市数据,如下
city.xlsx

我想location.xslx的location列字符串中包含city.xlsx中city列数据字眼就在location.xslx中打上新的一列作为标签(城市维度)
2 举例搬代码
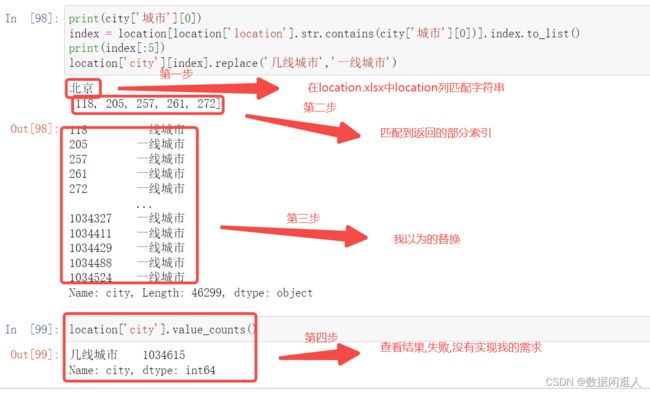
print(city['城市'][0])
index = location[location['location'].str.contains(city['城市'][0])].index.to_list()
print(index[:5])
location['city'][index].replace('几线城市','一线城市')
location['city'].value_counts()
1 这时我还想既然不能批量替换,查看replace是否有参数可以设置---->没有找到
2 想到对单个使用的apply与lambda方法,试试
location.iloc[index]['city'].apply(lambda x:'一线城市')
也不行,后来我觉得既然不能批量这样,那么我就是遍历弄就可以了,于是写了个循环,虽然时间久,但是解决了需求
for i in tqdm(range(len(city))):
index = location[location['location'].str.contains(city['城市'][i])].index.to_list()
for j in range(len(index)):
location['city'][index[j]] = city['几线城市'][i]
花费时间
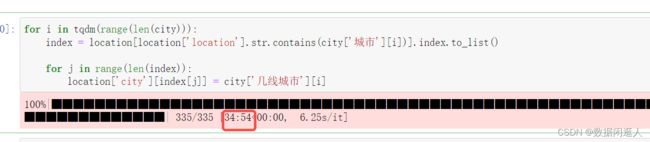
百万行数据,检索300多个城市,勉强还能接受
3 突破进展
是我觉悟不够高,今早睡醒突然想到,直接替换后覆盖就可以了,速度提高了10几倍,nice!
赶论文了~,还是来记录一下下
4 感想
多点往dataframe里面内置的一些批量操作函数,因为底层了解到很多事拿C实现,速度会快很多,不然有时候取数处理速度太慢,真的无语了,有兴趣可以看看我之前写的

python中DataFame一些性能优化的小小技巧