一文了解Clickhouse
ClickHouse是什么
ClickHouse是一个存储计算一体的工具,其与spark,flink等大数据框架不同的在于它有自己的存储层,在数据压缩,存储上做了更多的优化,所以导致它在某些数据处理能力上比其他工具快上了不少,毕竟一般框架只是在计算层面上下功夫做优化。
为什么选择ClickHouse
ClickHouse有非常多的特点,但这里我只选择我认为比较重要的说:
- 灵活多变:分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
- 存储优化:首先与普通数据库存储不同在于,它采用列式存储,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。其次因为采用了列式存储一列数据的类型一般都是一样的,所以在数据压缩上,效果更好,这样就可以将数据存储空间压缩的更小,可以存更多的数据,也意味着可以在内存中放更多的数据,那么速度自然就更快。上述存储优化前提都是基于采用其merge tree为引擎的,它还有其他引擎应对特殊情况,比如integrations引擎可以获取外部数据等等
- 计算快:ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。ClickHouse不仅将数据按列存储,而且按列进行计算。ClickHouse实现了向量执行引擎,对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。

ClickHouse怎么读写
ClickHouse数据写入时直接落盘,同时也就省略了传统的写redo日志阶段。ClickHouse是依赖于ZooKeeper做异步的磁盘文件同步.
ClickHouse存储中的最小单位是DataPart,一次批量写入的数据会落盘成一个DataPart。DataPart内部的数据存储是完全有序的状态(按照表定义的order by排序),这种有序存储就是一种默认聚簇索引可以用来加速数据扫描。ClickHouse也会对DataPart进行异步合并,
其合并也是用来解决两个问题:
1)让数据存储更加有序;
2)完成主键数据变更。
DataPart在合并存储数据时表现出的是merge-sorted的方式,合并后产生的DataPart仍然处于完全有序状态。
高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
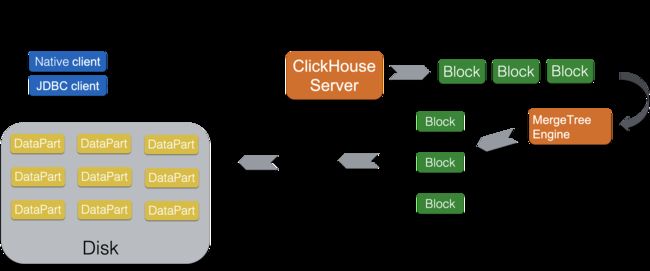
关于clickhouse的读能力,首先关乎到其计算能力,clickhouse的计算引擎特点则是极致的向量化,完全用c++模板手写的向量化函数和aggregator算子使得它在聚合查询上的处理性能达到了极致。配合上存储极致的并行扫描能力,轻松就可以把机器资源跑满。
ClickHouse是完全列式的存储计算引擎,而且是以有序存储为核心,在查询扫描数据的过程中,首先会根据存储的有序性、列存块统计信息、分区键等信息推断出需要扫描的列存块,然后进行并行的数据扫描,像表达式计算、聚合算子都是在正规的计算引擎中处理。从计算引擎到数据扫描,数据流转都是以列存块为单位,高度向量化的。
ClickHouse,只有一个面向IO的UnCompressedBlockCache和系统的PageCache,ClickHouse立足于分析查询场景,分析场景下的数据和查询都是多变的,查询结果等Cache都不容易命中,所以ClickHouse的做法是始终围绕磁盘数据,具备良好的IO Cache能力。
clickhouse的分布式系统每台机器都是相对独立了可以去做查询,同时可以任意扩展副本到服务器上。

在读数据时,它会分发子查询给各个机器,然后汇总进行查询

ClickHouse是否支持大数据量
clickhouse的存储就决定了其支持海量数据,具体存储过程如下图:
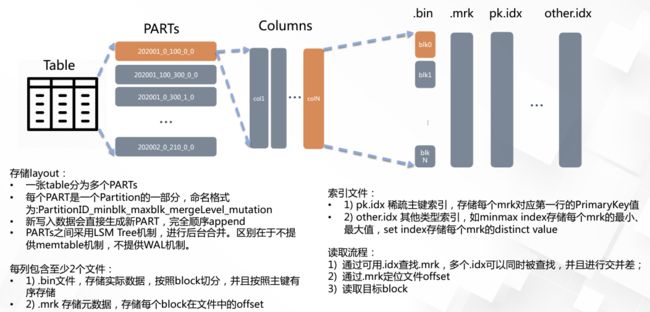
需要注意的是稀疏主键索引就是,它将每列数据按照index granularity(默认8192行)进行划分(分成图中的block),每个index granularity的开头第一行被称为一个mark行。(这里有点像操作系统中虚拟内存的页表那种概念,也就是图中的.mrk)主键索引存储该mark行对应的primary key的值。对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重
ClickHouse是否支持定时淘汰
可以前提是使用merge-tree表引擎
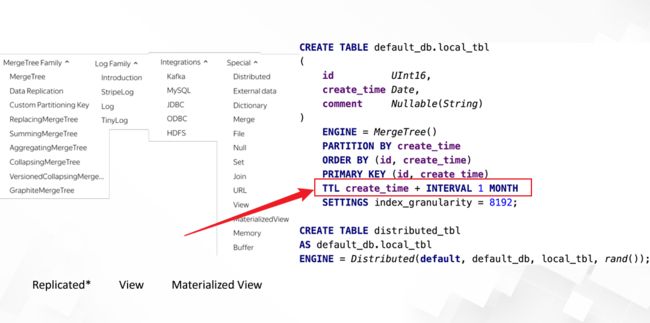
数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
- 在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
- 对partition进行TTL管理,淘汰过期的分区数据。
数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
在建表的时候可以自定义TTL时间:
ClickHouse的优势、劣势
高性能读取
-
数据有序存储:任意表达式SORTBY,灵活适应业务
-
稀疏索引:Block级别、任意表达式、多种索引类型
高吞吐写入
-
LSMtree:200MB/S
-
线性拓展:P2P架构、多点可写
-
多种Sharding策略:rand/任意表达式hash/自定义比例
-
支持Delete/Update高压缩比
-
列存:定长存储、词典编码
-
列级压缩算法、丰富的编码算法
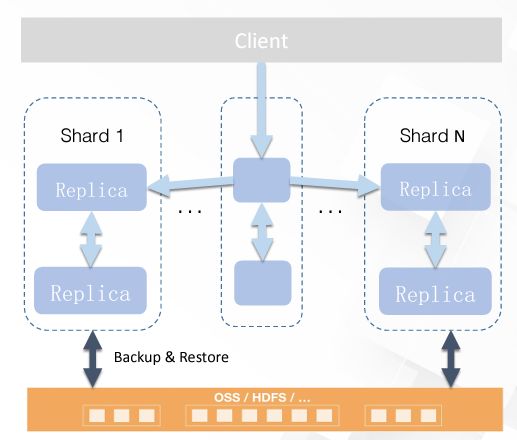
高可用存储
-
任意副本数量
-
Multi-Master多点可写、多点可查、双向同步
-
不同shard支持不同副本数
分析场景下(where过滤后的记录数较多),ClickHouse凭借极致的列存和向量化计算会有更加出色的并发表现。
ClickHouse并发处理能力立足于磁盘吞吐
ClickHouse更加适合低成本、大数据量的分析场景,它能够充分利用磁盘的带宽能力。
有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务,ClickHouse 并不是强项。
ClickHouse测试对比
关于ck和mysql,hive的测试对比
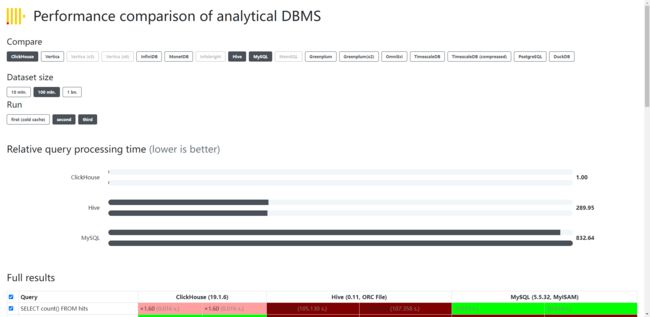
https://clickhouse.com/benchmark/dbms/#[100000000,[%22ClickHouse%22,%22Hive%22,%22MySQL%22],[%221%22,%222%22]]
ClickHouse同类对比Doris,Hologres
doris是百度开源的,其基于内存计算速度更快,holo是阿里配套的解决方案,可以直接基于maxcompute存储,同时支持列存储和行存储,更加灵活,但同行吐槽在flink读kafka写入holo,用flink消费holo的binglog场景性能可能没那么高,clickhouse是性价比较高,它尽可能的去压榨服务器的资源。
阅读相关文章:
官方文档:https://clickhouse.com/docs/zh
微信ck实时数仓实践:https://baijiahao.baidu.com/s?id=1717387409459384676&wfr=spider&for=pc
深入理解什么是LSM-Tree:https://blog.csdn.net/u010454030/article/details/90414063
clickhouse和Elasticsearch的对比:https://developer.aliyun.com/article/783804?spm=5176.20128342.J_6302206100.2.27137ba2a3mxh2&groupCode=clickhouse
details/90414063
clickhouse和Elasticsearch的对比:https://developer.aliyun.com/article/783804?spm=5176.20128342.J_6302206100.2.27137ba2a3mxh2&groupCode=clickhouse
clickhouse表引擎简介:https://developer.aliyun.com/article/762461?spm=5176.20128342.J_6302206100.3.27137ba2a3mxh2&groupCode=clickhouse