干货!面向开放世界的推荐系统:基于图结构学习的归纳式协同过滤
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
基于协同过滤的推荐模型通过将观察到的用户评分矩阵分解为两组嵌入因子(用户embedding和物品embedding)的内积,可以有效地估计潜在的用户兴趣并预测用户的未来行为。然而,特定于用户的嵌入因子只能以传导式(transductive)的方式学习,这使得推荐模型很难处理测试数据中的新用户。在现实场景中,推荐模型往往只能在有限时间窗口内收集的数据上训练,在未来的测试阶段则需要处理训练阶段未见的新用户。本文提出了一种可以实现归纳式学习的新型协同过滤方法。该方法包含两个表示学习模型:第一个模型遵循传统的矩阵分解方法,即对一组种子用户(key users)的评分矩阵进行分解,以获得他们对应的嵌入因子;第二个模型采用基于注意力机制的图结构学习方法,估计新的查询用户(query user)与种子用户之间的隐含关系,并通过图上的神经消息传递来归纳式的估计查询用户的嵌入表示。理论分析表明本文提出的模型可以保证与矩阵分解等价的表示能力。在5个公开数据集上的实验表明,我们的方法能够显著提升在具有少量行为数据的用户上的推荐性能,并且当模型仅在一部分用户上完成训练后可以有效迁移到新用户(不需要新的训练)。
本期AI TIME PhD直播间邀请到了上海交通大学博士吴齐天,带来分享——《基于图结构学习的归纳式协同过滤》。

上海交大博士生,导师为严骏驰教授,研究方向为机器学习与数据挖掘。在ICML/NeurIPS/KDD发表多篇一作论文,获评2021年百度AI新星。
01
背 景
推荐系统中的常见模型是基于矩阵分解的协同过滤模型(Collaborative Filtering,CF),用于处理一个用户-物品的评分矩阵。这里的评分矩阵有两种情况:显式反馈(explicit feedback)和隐式反馈(implicit feedback)。显示反馈表示矩阵的值是连续的,比如豆瓣的电影评分;隐式反馈表示矩阵中只有0和1两种值,其中1表示用户和物品发生了交互,比如用户观看了或者评论了某个物品,反之为0。
协同过滤模型将输入的矩阵分解为两部分,一部分是用户对应的user embeddings,另一部分是物品对应的item embedding。然后协同过滤模型通过使用user embedding和item embedding的交互来重构输入的观测矩阵。

协同过滤模型的缺点是对于训练集中没有出现过的用户无法进行处理,即它是一种传导式学习(transductive learning)的方法。具体地说,使用协同过滤模型只能假设训练集和测试集的用户是共享的,如果实际情况中出现了未在训练集中出现的用户,由于模型无法给出新用户的embedding,进而不能给出对新用户的预测值。我们称需要处理新用户的推荐系统为开放世界的推荐系统(open world recommendation)。这是一个被大量的现有工作所忽视的现实场景。

此外,与传导式学习(transductive learning)相对的是归纳式学习(inductive learning),主要思想是以数据样本共享的特征空间为输入空间,学习一个样本间共享的从输入到输出的映射,这样这个得到的映射函数就能成功泛化到新样本上。在推荐的场景下,归纳式学习可以通过以用户特征作为输入来实现。然而,基于特征的推荐模型会大大损失模型的表达能力,尤其是在仅能收集有限用户特征的情况下。比如两个年龄相似、职业相同的用户可能对电影的偏好完全不一样。
02
方 法
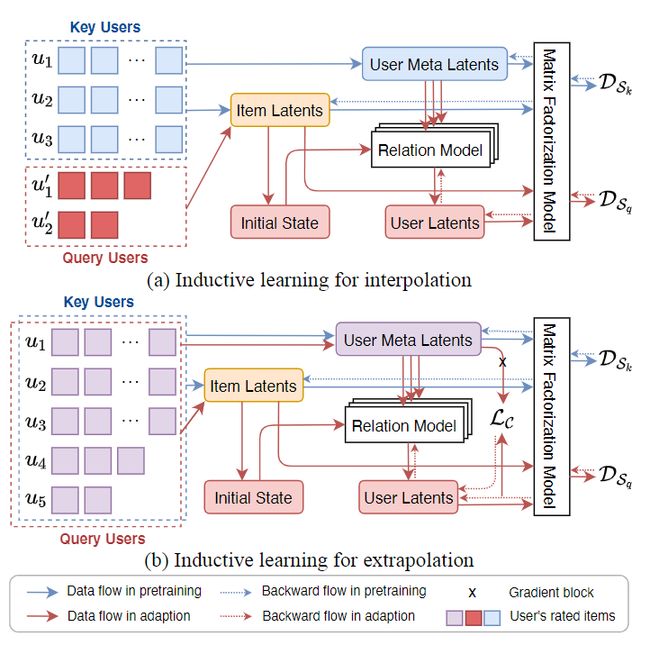
本文针对开始世界的推荐系统问题提出了一种归纳式协同过滤模型——Inductive Collaborative Filtering Model。该模型的主要思路包括以下3点:
将用户划分为两部分,种子用户(key user)和查询用户(query user),然后利用一部分用户的嵌入表示去计算另一部分用户的嵌入表示。
学习key user和query user之间的隐式图结构(latent graph)
通过在latent graph上实现由一部分用户到另一部分用户的信息传递,来归纳式的计算新用户的emdeddings。
以上思路的合理性来源于一个重要观察:在现实世界中,用户的兴趣和偏好存在一些相似性。虽然在开放世界中会有训练集中未出现的新用户,但其兴趣和行为总能与训练集中的用户具有一定程度的相似性,基于这种相似性,我们可以把用户之间的潜在联系构建为一个latent graph,基于这个graph就可以实现通过已有用户来预测新用户的兴趣爱好。

本文考虑了interpolation(模型可在新用户上训练,即查询用户与种子用户不同)和extrapolation(模型不能在新用户上训练,即查询用户与种子用户相同)两种情况下的归纳式学习。在这两种情况下,模型学习的过程包括预训练(pretraining)和适应(adaption)两阶段。预训练主要用于将key user的评分矩阵分解来学习种子用户的嵌入表示(称为meta embeddings)。而适应阶段则考虑优化了一个图结构学习模型,估计了从key user到query user之间的latent graph。
03
实 验
数据集:
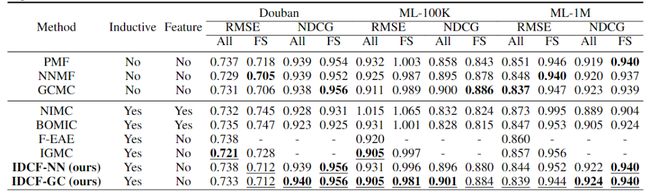
本文实验考虑了5个常见的推荐系统数据集,包括Douban、Movielens-100等,数据集情况如下图所示,其中Amazon-Books和Amazon-Beauty数据集包含隐式用户反馈,而Douban、Movielens-100K、Movielens-1M则包含显式反馈。

评价指标:
对于显式反馈数据集,使用RMSE和NDCG作为推荐排序的评价指标;对于隐式反馈的数据集,使用AUC和NDCG作为推荐排序的评价指标。
实验结果:
下图是显式反馈数据集的实验结果,RMSE越小,NDCG越大表示排序结果越好。
下图是隐式反馈数据集的实验结果,AUC越大表示模型排序结果越好。

今日视频推荐
整理:AI Timer
审核:吴齐天
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

点击“阅读原文”查看精彩回放