用人工智能判断红楼梦后40回是否是曹雪芹写的
本博文主要是用机器学习的方法判断红楼梦后四十回是不是曹雪芹写的
开发语言: Python3.6
开发工具: numpy,matplatlib,sklearn
相关算法: SVM
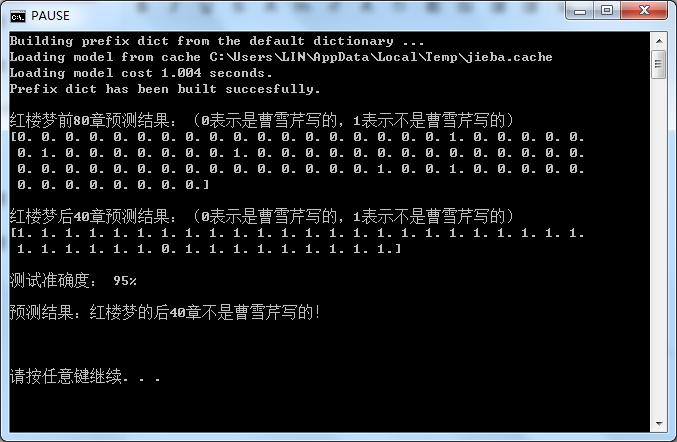
先放上预测结果,再慢慢分析设计步骤:
一. 设计思路
1. 整体设计思路
在已知了红楼梦前80回是曹雪芹写的基础下,为了验证后40回还是他写的,需通过学习前80章节的写作风格特色,从而根据对比前后风格的差别去判断。鉴于每一个作者的写作习惯和风格在一篇文章中基本不容易改变的特点,本次设计选前80回和后40回中的一些章节作为数据让机器去训练学习,然后通过训练之后的机器去预测每个章节的风格是属于前80回还是后40回,从而判定后40回的结果。
2. 设计步骤
<1> 为了使本次验证更具严谨性,我先把红楼梦分成三个部分,每部分各40章。然后利用jieba分词库拆分每一个部分,用算法提取每个部分出现词频最多的词,保存文档,手动去掉因为文章内容而造成前后出现次数差别大的人名,地名,专有名词等。
<2> 把<1>中的关键字整合在一起,按词频对它进行排序,筛选出现次数靠前的一部分作为特征向量。
<3> 对红楼梦的每一章节进行特征向量的提取,总共产生120个向量样本,每一个样本代表每一章的特征。
<4> 对数据进行PCA降维处理,得到的数据进行3D matplotlib绘图,对数据可视化处理。
<5> 选取前80回的15个样本和后40回的15个样本作为数据让机器训练。
<6> 最后把整个120章样本让训练好的机器进行预测,预测的结果如果后40回的风格和前80回风格截然不同,那么就推测的两部分是不同的人写的。
二. 分部设计
1. 三个部分生成的词频表进行整合后(截取了部分):
词频提取算法代码(Python)部分代码:
import jieba
import jieba.analyse
from collections import Counter
def word_split(TextPath, KeyWords_Num, KeyWords_Path, encoding = 'utf-8'):
#text = open(TextPath, encoding = 'gb18030').read() #文本出现gbk错误时用encoding='gb18030'
with open(TextPath, encoding = encoding) as fr: #使用with open 自动会调用close,以防止出错
text = fr.read()
seg_list = jieba.cut(text, cut_all = False)
keywords = Counter() #计值出现的次数,有key和val
for words in seg_list:
if len(words) > 1 and words != '\r\n':
keywords[words] += 1 #统计词频
with open(KeyWords_Path, 'w') as fr_keywords:
for (key,val) in keywords.most_common(KeyWords_Num):
fr_keywords.write(key + ' '*(6-len(key)) + str(val) + '\n' ) #保存关键词文本
return keywords.most_common(KeyWords_Num)2. 进行特征值处理后的样本(截取一部分)

整个样本是一个120*118的matrix , 每一行代表每一章样本,列向量是该样本的特征向量,这里只截取了一部分作为参考
这里展示下只展示部分关键代码:
def sample_build(FeaturesPath, ChapterLib, SavePath):
Sample = {}
Features = {}
with open(FeaturesPath) as fr: #把特征值文本存放在Features字典中
featuresline = fr.readlines()
for line in featuresline:
line = line.strip()
Features[line] = 0
for (num,val_chp) in ChapterLib.items(): #遍历每一个章节
FeaturesVector = []
Features_Tmp = Features.copy()
seg_list = jieba.cut(val_chp, cut_all = False) for words in seg_list:
index = Features_Tmp.get(words,-1)
if index != -1:
Features_Tmp[words] = Features_Tmp.get(words,-1) + 1 #每出现一次加1
for (key,val) in Features_Tmp.items():
FeaturesVector.append(val)
Sample[num] = FeaturesVector
with open(SavePath, 'w') as fr: #新建文本保存
for (key,val) in Sample.items():
fr.write(str(val) + '\n')
return Sample 3. 降维处理后,对数据进行3D matplotlib绘制,进行数据可视化,把抽样的样本放在空间中直观的展示出来。
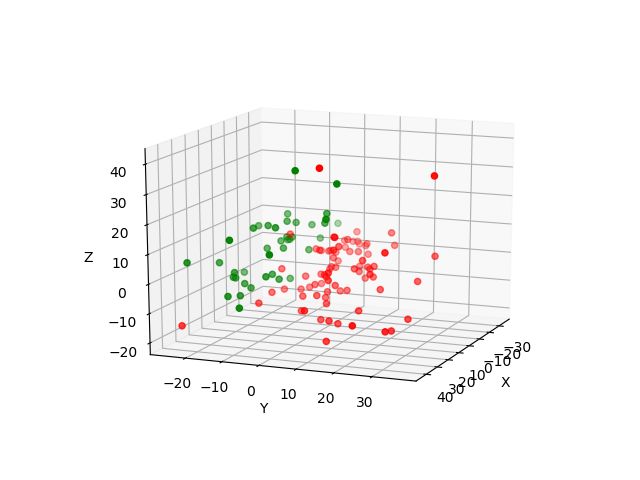
图中红色的点代表前80回,绿色的点代表后40回。
明显可以观察到前80回和后40章写作风格用词的区别。
4. 用SVM(Support Vector Machines)进行机器学习
支持向量机将向量映射到一个更高维度的空间,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个超平行的距离最大化,从而减少预测误差。
5. 预测结果
用上面训练好的机器进行数据预测,得到如下结果:
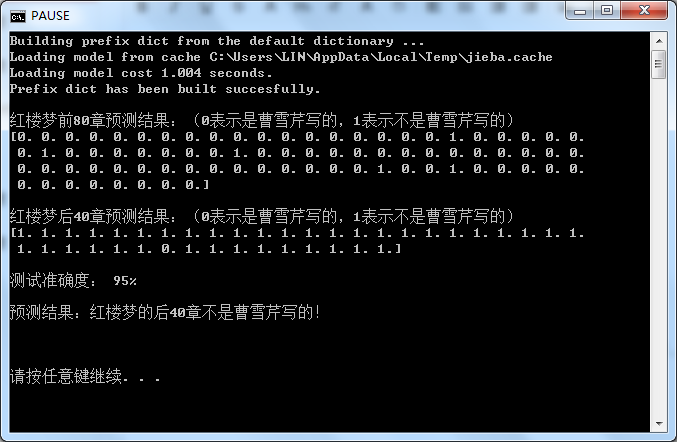
结果表明机器能够预测后40回不是曹雪芹写的,且准确度高达95%
代码下载:https://download.csdn.net/download/flyoung1994/10345010
写在最后: 虽然此方法已经有很多人研究过了,本人在设计严谨性和可靠性做了更详细的分析,能够使机器更加准确的学习,进而提高了机器的泛化能力,能够更加准确的预测结果。