软件测试质量保证与测试
软件测试质量保证与测试
第一章 软件测试概述
1.1 软件测试背景
随着计算机技术的迅速发展和越来越广泛深入地应用于国民经济与社会生活的各个方面,软件系统的规模和复杂性与日俱增,软件的生产成本和软件中存在的缺陷与故障造成的各类损失也大大增加,甚至会带来灾难性的后果。软件质量问题已成为所有使用软件和开发软件人员关注的焦点。而由于软件本身的特性,软件中的错误是不可避免的。不断改进的开发技术和工具只能减少错误的发生,但是却不可能完全避免错误。因此为了保证软件质量,必须对软件进行测试。软件测试是软件开发中必不可少的环节,是最有效的排除和防止软件缺陷的手段。
随着人们对软件测试重要性的认识越来越深刻。软件测试在整个软件开发周期中所占的比例日益增大,大量测试文献表明,通常花费在软件测试和排错上代价大约占软件开发总代价的50%以上。现有写软件开发机构将研制力量的40%以上投入到软件测试之中,,对于某些姓名有关的软件,其测试费用甚至高达所有其他软件工程阶段费用的3到5倍。美国微软公司软件测试人员是开开发人员的1.5倍。
所以,当软件业不断成熟,走入工业化阶段的同时,软件测试在软件开发领域的地位也越来越重要。
1.1.1 软件可靠性
已投入运用的软件质量一个重要标志是软件可靠性。从试验系统所获得的统计数据表说明,运行软件的驻留故障密度各不相同,与生命攸关的关键软件为每千行0.01-1个故障,与财务(财产)有关的关键软件为每千行代码1-10个故障。其他对可靠性要求相对较低的软件系统故障就更多了。然后,正是由于软件可靠性的大幅度提高才使得计算机得以广泛应用与社会的各个方面。
1.1.2 软件缺陷
-
软件缺陷案例
- 当今人类的生存和发展已经离不开各种各样的信息服务,为了获取这些信息,需要计算机网络或通信网络的支持,这里包含着不仅需要计算机硬件等基础设施或设备,还需要各式各样的、功能各异的计算机软件。软件在电子信息领域里无处不在。然后,软件是由人编写开发的,是一种逻辑思维的产品,尽管现在软件开发者采取了一系列有效措施,不断提高软件开发的质量,但仍然无法完全避免软件(产品)会存在各种各样的缺陷。下面介绍两个软件缺陷的案列,借此说明软件缺陷问题有时会造成相当严重的损失和灾难。
- 跨世纪“千年虫”问题

- 跨世纪千年虫问题,是一个非常著名的计算机软件缺陷问题,在上世纪末的最后几年中,全世界的各类硬件系统、软件系统和应用系统都为“千年虫”问题付出了巨大的代价。
- 20世纪70年代,程序员为了节约非常宝贵的内存资源和硬盘空间,在存储日期时只保留了年份的后两位数,如1980被保存为80.他们采用这一措施的出发点主要是认为只有在到了2000年时程序在计算00或01这样的年份时才会出现问题,但在到达2000年时,程序早已不用或者修改升级了。然后令这些程序员万万没有想到的是她们的程序会一直被用到2000年。当2000年到来时,问题就出现了。计算机系统在处理2000年份问题(以及与此年份相关的其他问题)时,软、硬件系统存在的问题隐患被业界成为“千年虫”问题。
- 据不完全统计,从1998年初全球就开始进行“千年虫”问题的大检查,特别是金融、保险、军事、科学、商务等领域花费了大量的人力、物力对现有的各种各样的程序进行检查、修改和更正,仅此项费用就达数百亿美元。
- windows2000中文输入法漏洞
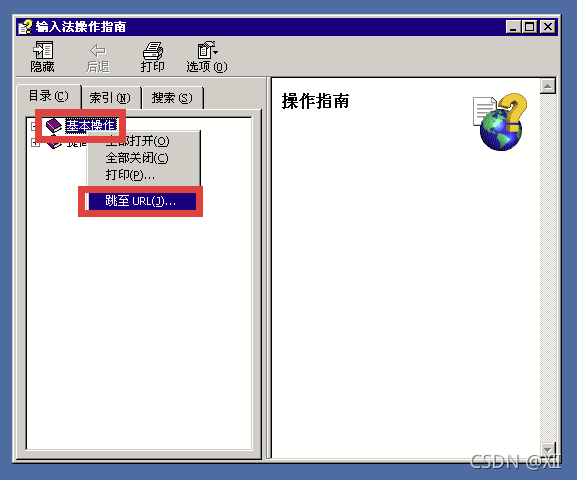
- 在安装微软的windows2000简体中文版的过程中,在默认情况下会同时安装各种简体中文输入法。随后这些装入的输入法可以再windows2000系统用户登录界面中使用,以便用户能够使用基于字符的用户表示和密码登录系统。然而, 在默认安装的情况下,windows2000中的简体中文输入法不能正确检测当前的状态,导致了在系统登录界面中提供不应有的功能,即出现了下面的问题:在windows在 Windows 2000 用户登陆界面中,当用户输入用户名时,用 Ctrl+Shift 组合键将输入法切换
到全拼输入法状态下,同时在登陆界面的屏幕的左下角将会出现输入法状态条。用鼠标右键单击状
态条并在出现的菜单中选择“帮助”项,再将鼠标移到“帮助”项上,在弹出的选择项里选择“输
入法入门”,随后即弹出“输入法操作指南”帮助窗口。再用鼠标右键单击“选项”,并选择“跳至
URL”,此时将出现 Windows 2000 的系统安装路径并要求添入路径的空白栏。如果该操作系统安装在C 盘上,在空白栏中填入“C:\windowsnt\system32”,并单击“确定”按钮,在“输入法操作指南”右边的框里就会出现C:\windowsnt\system32 目录下的内容了,也就是说这样的操作成功地绕过了身份的验证,顺利地进入了系统的system32 目录,当然也就可以进行各种各样的操作了。此缺陷被披露后,微软公司推出了该输入法的漏洞补丁,并在 Windows 2000 Server Pack2 以后的补丁中都包含了对该漏洞的修补,但对于没有安装补丁的用户来说,系统仍然处于不安全的状态
- 在安装微软的windows2000简体中文版的过程中,在默认情况下会同时安装各种简体中文输入法。随后这些装入的输入法可以再windows2000系统用户登录界面中使用,以便用户能够使用基于字符的用户表示和密码登录系统。然而, 在默认安装的情况下,windows2000中的简体中文输入法不能正确检测当前的状态,导致了在系统登录界面中提供不应有的功能,即出现了下面的问题:在windows在 Windows 2000 用户登陆界面中,当用户输入用户名时,用 Ctrl+Shift 组合键将输入法切换
- 跨世纪“千年虫”问题
- 当今人类的生存和发展已经离不开各种各样的信息服务,为了获取这些信息,需要计算机网络或通信网络的支持,这里包含着不仅需要计算机硬件等基础设施或设备,还需要各式各样的、功能各异的计算机软件。软件在电子信息领域里无处不在。然后,软件是由人编写开发的,是一种逻辑思维的产品,尽管现在软件开发者采取了一系列有效措施,不断提高软件开发的质量,但仍然无法完全避免软件(产品)会存在各种各样的缺陷。下面介绍两个软件缺陷的案列,借此说明软件缺陷问题有时会造成相当严重的损失和灾难。
-
软件缺陷的定义和种类
- 上面实例中的软件问题在软件工程或软件测试中都被称为软件缺陷或软件故障。在不引起误解情况下,不管软件存在问题的规模和危害是大还是小,由于都会产生软件使用上的各种障碍,所以将这些问题统称为软件缺陷。
- 软件缺陷==即计算机系统或者程序中存在的任何一种破坏正常运行能力的问题、错误,或者隐藏的功能缺陷、瑕疵。==缺陷会导致软件产品在某种程度上不能满足用户的需要。在IEEE 1983 of IEEEStandard 729 中对软件缺陷下了一个标准的定义:
从产品内部看,软件缺陷是软件产品开发或维护过程中所存在的错误、毛病等各种问题;从外部看,软件缺陷是系统所需要实现的某种功能的实效或违背。因此软件缺陷就是软件产品中所存在的问题,最终表现为用户所需要的功能没有完全实现,没有满足用户的需求。
软件缺陷表现得形式有多重,不仅仅体现在功能的失效方面,还体现在其他放方面,软件缺陷的主要类型通常有
- 软件未达到产品说明书已经表明的功能
- 软件产品出现了产品说明书中指明不会出现的错误
- 软件未达到产品说明书中虽未指出但应当达到的目标
- 软件功能超出了产品说明书中指出的范围
- 软件测试人员认为软件难以理解、不易使用,或者最终用户认为该软件使用效果不良
为了对以上5条描述进行理解,这里以日常我们所使用的计算器内的嵌入式软件来说明上述每条定义的规则。
计算器说明书一般声称该计算器将准确无误的进行加、减、乘、除运算。如果测试人员或用户选定了两个数值后,随意按下了“+”号键,结果没有任何反应或得到一个错误的结果,根据第一条规则,这是一个软件缺陷;如果得到错误答案,根据第一条规则,同样是软件缺陷。
加入计算器产品说明书指明计算器不会出现奔溃、死锁或者停止反应,而在用户随意按、敲键盘后,计算器停止接受输入或没有了反应,根据第二条规则,这也是一个软件缺陷。
若在测试过程中发现,因为电池没电而导致了计算不正确,但产品说明书未能指出在此情况下应如何进行处理,根据第三条规则,这也算作软件缺陷
若在进行测试时,发现除了规定的加减乘除功能之外,还能够进行平方根的运算,而这一功能并没有在说明书的功能中规定,根据第四条,这也是软件缺陷。
第五条的规则说明了无论测试人员或者是最终用户,若发现计算器某些地方不好用,比如,按键太小、显示屏在亮光下无法看清等,也都应算作软件缺陷。
软件缺陷一旦被发现,就要设法找出引起这个缺陷的原因,分析对产品质量的影响,然后确定软件缺陷的严重性和处理这个缺陷的优先级。各种软件缺陷所造成的后果是不同的,有的仅仅是不方便,有的则可能是灾难性的。一般来说,问题越严重的,其优先级越高,越要得到及时的纠正。软件公司对缺陷严重性级别的定义不尽相同,但一般可概括为以下几种。
- 致命的:致命的错误,造成系统或应用程序奔溃、死机、系统悬挂,造成数据丢失、主要功能完全丧失等。
- 严重的:严重错误,指功能或特性没有实现,主要功能丧失,导致严重的问题或致命的错误声明。
- 一般的:不太严重的错误,这样的软件缺陷虽然不影响系统的基本使用,但没有很好地实现功能,没有达到预期效果。如次要功能丧失,提示信息不太准确,或用户界面差,操作时间长等。
- 微小的,一些小问题,对功能几乎没有影响,产品及属性仍可使用,如有个别错别字,文字排列不整齐等。
除了这4种以外,有时需要“建议”级别来处理测试人员所提出的建议或质疑,如建议程序做适当的修改,来改善程序运行状态。或对设计不合理、不明白的地方提出质疑。
-
软件缺陷的产生
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FFFnKCYk-1668933686516)(https://pic-1310091761.cos.ap-chengdu.myqcloud.com/img/u=2211945209,3300664111&fm=253&fmt=auto)]
软件缺陷的产生是不可避免的,那么造成软件缺陷的原因是什么呢?通过大量的测试理论研究及实践经验的积累,软件缺陷产生的主要原因可以被归纳为以下几种类型。
- 需求解释有错误
- 用户需求定义错误
- 需求记录错误
- 设计说明有误
- 编码说明有误
- 程序代码有误
- 其他,如:数据输入有误,问题修改不正确
由此可见,造成软件缺陷的原因是多方面的,经过软件测试专家们的研究发现,大多数的软件缺陷并非来自编码过程中的错误,从小项目到大项目都基本上证明了这一点。因为软件缺陷很可能是在系统详细设计阶段、概要设计阶段,甚至是在需求分析阶段就存在的问题所导致的。即使是针对源程序进行的测试所发现的故障的根源也可能存在于软件开发前期的各个阶段。大量的事实表明,导致软件缺陷的最大原因是软件产品说明书,也是软件缺陷出现最多的地方。
在多数情况下,软件产品说明书并没有写的明确、清楚或者描述不全面,或者在软件开发过程中对需求、产品功能经常更改,或者开发小组的人员之间没有很好地进行交流和沟通, 没有很好地组织开发与测试流程。因此,制作软件产品开发计划是非常重要的,如果计划没有做好,软件缺陷就会出现。
软件缺陷产生的第二大来源是设计方案,这是实施软件计划的关键环节。编程排在第三位,许多人认为软件测试主要是找程序代码中的错误,这是一个认识的误区。经统计,因编写程序代码引入的软件缺陷大约仅占缺陷总数的7%左右。
- 软件缺陷的修复费用
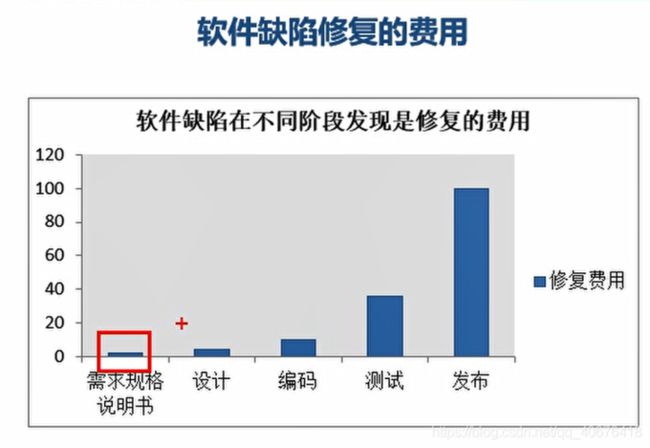
软件通常要靠有计划,有条理的开发过程来建立。从前面的讨论可知,缺陷并不只是在编程阶段产生,在需求分析和设计阶段同样会产生。也许一开始只是一个很小范围内的潜在错误。但随着产品开发工作的进行,小错误会扩散程大错误,为了想修改后期发现错误所做的工作要大得多。及越到后来往前返工也越远。如果错误不能及时发现,那只可能造成越来越严重的错误。缺陷发现解决的越迟,成本也就越高。Boehm在Software Engineering Economics一书中曾经写到,平均而言,如果在需求阶段修正一个错误的代价是1,那么在设计阶段就是他的3到6倍,在编程阶段是他的10倍,而到了产品发不出去时,这个数字就是40到1000倍,修正错误的代价不是随时间线性增长,而几乎是成指数级增长的。
所以,测试人员应当把“今早和不断地测试”作为其座右铭,从需求分析时就介入进去,尽早发现和改正错误。
1.1.3 软件测试发展与现状
20世纪50-60年代,软件测试相对于开发工作仍然处于次要位置,测试理论和方法的发展都比较缓慢。除了极关键软件系统外一般都测试不完备。导致大量包含大大小小缺陷的软件投入运行。一旦暴露即带来不同程度的严重后果,例如早年火星探测运载火箭因可控制程序中错写了一个逗号而爆炸。
随着人们对软件测试重要性的认识和软件技术的不断成熟和完善,70年代以后软件测试的规模和复杂度日益加大,并逐渐形成了一套完整的体系,开始走向规范化。1982年在美国北卡罗来纳州大学召开了首次软件测试技术会议,这是软件测试与软件质量研究人员和开发人员的第一次聚会,成为软件测试技术发展的一个重要里程碑。此后,测试理论、测试方法进一步完善,从而使软件测试这一实践性很强的学科成为有理论指导的学科。
不过尽管软件测试技术与实践都有了很大进展,但是就目前软件工程发展状况而言,软件测试仍然是较为薄弱的一个方面。而国内软件测试工作相对于国外起步较晚,与一些发达国家相比还存在一定差距,因此对于国内软件企业来说,需要进一步提高对软件测试重要性的认识,研究与采用先进的测试管理与应用技术,建立完善的软件质量保证的管理体系。
1.2 软件测试基础理论
1.2.1 软件测试定义
1.软件测试的定义
软件测试就是在软件投入运行前,对软件需求分析、设计规格说明和编码实现的最终审查,他是软件质量保证的关键步骤。
根据著名软件测试专家G.j.Myers的观点,他认为“软件测试是为了发现错误而执行程序的过程”。根据该定义,软件测试是根据软件开发各个阶段的规格说明和程序的内部结构而精心设计的一批测试用例(即输入数据及其预期的输出结果),并利用这些测试用例运行程序以及发现错误的过程,即执行测试步骤。测试是采用测试用例执行软件的活动,他有两个显著目标:找出失效或演示正确的执行
其中,测试用例是为特定的目的而设计的一组输入输出,执行条件和预期的结果,测试用例是执行测试的最小实体。
测试步骤详细规定了如何设置、执行、评估特定的测试用例。
除此之外,G.J.Myers还给出了与测试相关的三个重要观点。
- 测试是为了证明程序有错,而不是证明程序无错误
- 一个好的测试用例是在于它能发现至今未发现的错误。
- 一个成功的测试是发现了至今未发现的错误的测试
在一个测试定义中,明确指出“寻找错误”是测试的目的。相对于“程序测试是证明程序中不存在错误的过程”Myers的定义是对的。因为把证明程序无措当做测试的目的不仅是不正确的,是完全做不到的,而且对于做好测试工作没有任何益处,甚至是十分有害的。因此从这方面讲,可以接受Myers的定义以及它所蕴含的方法观和观点。不过,这个定义也有局限性,他将测试定义规定的范围限制的过于狭窄,测试工作似乎只有在编码完成以后才能开始。更多专家认为软件测试的范围应当更为广泛,除了要考虑测试结果的正确性以外,还应关心程序的效率、可使用性、维护性、可扩充性、安全性、可靠性、系统性能、系统容量、可伸缩性、服务可管理性、兼容性等因素。随着人们对软件测试更广泛、深刻的认识,可以说对软件质量判断绝不只限于程序本身,而是整个软件研制过程。
综上所述,对于软件测试我们可以做出如下定义:软件测试是为了尽快发现在软件产品中所存在的各种软件缺陷而展开的贯穿整个软件开发生命周期、对软件产品(包括阶段性产品)进行验证和确认的活动过程
2.软件测试的基本问题
一个软件生命周期包括制定计划、需求分析定义、软件设计、程序编码、软件测试、软件运行、软件维护、软件停用八个阶段。
软件测试的根本目的是为了保证软件质量。ANSI/IEEE Std 729-1983文件中,软件质量概念被定义为“与软件产品满足规定的和隐含的需求的能力有关的特征或特征的全体”。软件质量反映以下三个方面
- 软件需求是度量质量的基础。
- 在各种标准中定义开发准则,用来指导软件人员用于工程化的方法来开发软件
- 往往会有一些隐含的需求没有明确的指出,如果软件只满足那些精确定义的需求,而没有满足那些隐含的需求,软件质量也不能得到保证。
软件质量内涵包括:正确性、可靠性、可维护性、可读性(文档、注释)、结构化、可测试性、可移植性、可扩展性、用户界面友好性、易学、易用、健壮性。
软件测试的对象:软件测试不仅仅是对程序的测试,而是贯穿于软件定义和开发的整个过程。因此,软件开发过程中产生的需求分析、概要设计、详细设计以及编码等各个阶段所得到的文档,包括需求规格说明书、概要设计规格说明书、详细设计规格说明书以及源代码,都是软件测试的对象。
软件测试在软件生命周期,也就是软件从开发设计、运行、直到结束的全过程中,主要横跨以下两个测试阶段。
第一个阶段:单元测试阶段,即在每个模块编写出以后所做的必要测试。
第二个阶段:综合测试阶段,即在完成单元测试后进行的测试,如集成测试、系统测试、验收测试等。
软件测试设计的关键问题包括以下四个方面:
- 测试由谁来执行。通常软件产品的开发设计包括开发者和测试者两种角色。开发者通过开发而形成产品,如以上所列的分析、设计编码调试或文档编制等。测试者通过测试来检查产品中是否存在缺陷。包括根据特定目的而设计测试用例、构造测试、执行测试和评价测试结果等。通常的做法是开发者(机构或组织)负责完成自己代码地单元测试,而系统测试则由一些独立的测试人员或专门的测试机构进行。
- 测试什么。测试经验表明,通常表现在程序中的故障,并不一定是由编码所引起的。他可能在详细设计阶段、概要设计阶段,甚至是需求分析阶段的错误所致。即使对源程序进行测试,所发现的故障的根源也可能是在开发前期的某个阶段。要排除故障、修正错误,也必须追溯到前期的工作。事实上,软件需求分析、设计和实施阶段是软件故障的主要来源。
- 什么时候进行测试。测试可以是一个与开发并行的过程,还可以是在开发完成某个阶段任务之后的活动或者是开发结束之后的活动。即模块开发结束之后可以进行测试,也可以推迟在快装配成为一个完整的程序之后在进行测试。开发经验表明,随着开发不断深入,没有进行测试的模块对整个软件的潜在破坏作用更明显。
- 怎样进行测试。软件“规范”说明了软件本身应该达到的目标,程序“实现”则是对应各种输入如何产生输出结果的算法。换言之,规范界了一个软件要做什么,而程序实现则规定了软件应该怎样做。对软件进行测试就是根据软件的功能规范说明和程序实现,利用各种测试方法,声称有效的测试用例,对软件进行测试。
要实现软件质量保证,主要有两种途径:首先通过贯彻软件工程各种有效的技术方法和措施使得尽量在软件开发期间减少错误,其次就是通过分析和测试软件来发现和纠正错误。因此,软件测试就是软件质量的重要保证。
对于一个系统做的测试越多,就越能确保他的正确性。然而,软件的测试通常不能保证系统的百分之一百的正确。因此,软件测试在确保软件质量方面的主要贡献在于它能发现那些一开始就应避免的错误。软件质量保证的使命首先是避免错误。
1.2.2 软件测试基本理论
1.软件测试的目的
从历史的 观点来看,测试关注于执行软件来获得软件在可用性方面的信息并且证明软件能够满意的工作。这引导测试把重点投入在检测和排除缺陷上。现代的软件测试持续了这个观点。同时,还认识到许多重要的缺陷主要来自于对需求和设计的误解、遗漏和不正确。因此,早期的同行评审被用于帮助预防编码前的缺陷。证明,检测和预防已经成为一个良好测试的重要目标。
- 证明:获取系统在可接受风险范围内可用的信息;尝试在非正常情况和条件下的功能和特性;保证一个工作产品是完整的并且可用或可被集成。
- 检测:发现缺陷、错误和系统不足;定义系统的能力和局限性;提供组件、工作产品和系统的质量信息
- 预防:澄清系统的规格和性能;提供预防或减少可能制造错误的信息;在过程中尽早检测错误;确认问题和风险,并且提前确认解决这些问题和风险的途径
2.软件测试的原则
软件测试的基本原则则是站在用户的角度,对产品进行全面测试,尽早、尽可能多地发现缺陷,并负责跟踪和分析产品中的问题,对不足之处提出质疑和改进意见。零缺陷是一种立项,足够好是测试的原则
如果进一步去研究测试的原则,我们发现在软件测试过程中,应注意和遵循的原则可以概括为10项
- 测试不是为了证明程序的正确性,而是为了证明程序不能工作。正如Mayer所说,测试的目的是证伪而不是正真。事实上证明程序的正确性是不可能的。一个大型的集成化的软件系统不能被穷尽测试以遍历其每条路径,而且即使遍历了所有的路径,错误仍有可能隐藏。我们做测试是为了尽可能地发现错误。
- 测试应当有重点。因为时间和资源是有限的,我不可能无休止的进行测试。测试的重点选择需要根据多个方面考虑,包括测试对象的关键程度,可能的风险,质量要求等。这些考虑与经验有关,随着实践经验的增长,判断也会更有效。
- 事先定义好产品的质量标准。只有建立了质量标准,才能根据测试的结果,对产品的质量进行分析和评估。同样,测试用例应确定预期输出结果。如果无法确定测试结果,则无法进行校验。必须用事先精确对应的输入数据和输出结果来对照检查当前的输出结果是否正确。做到“有的放矢”
- 软件项目一启动,软件测试也就开始,而不是等到程序写完后才开始进行测试。测试是一个持续进行的过程,而不是一个阶段。在代码完成之前,测试人员要参与需求分析、系统或程序设计的审查工作,而且要准备测试计划、测试用例、测试脚本和测试环境。测试计划可以在需求模型一完成就开始,相信的测试用例定义可以设计模板被确定后开始。
- 穷举测试是不可能的。既是一个大小适度的程序,其路径排列的数量也非常大,因此在测试中不可能运行路径的每一种组合。然而,充分覆盖程序逻辑,并确保程序设计中所使用的条件都达到是有可能的。
- 第三方进行测试会更客观、更有效。程序员应避免测试自己的程序,为达到最佳的效果,应由第三方来进行测试。测试是带有“挑剔性”的行为,心理状态是测试自己程序的障碍。同时对于需求规格的理解产生的错误也很难在程序员本人测试时被发现。
- 软件测试计划是做好软件测试工作的前提,所以在进行测试之前。应制定良好的、切实可行的测试计划并严格执行,特别要确定测试策略和测试目标。
- 测试用例式设计出来的,不是写出来的。所以要根据测试地目的,采用响应的方法去设计测试用例,从而提高测试的效率,更多地发现错误,提高程序的可靠性。除了检查程序是否做了他应该做的事,还要看程序是否做了她不应该做的事。不仅应选用合理的输入数据,对于非法的输入也要设计测试用例进行测试。
- 对发现错误较多的程序段,应进行更深入的测试。一般来说,一段程序中已发现的错误数越多,其中存在的错误概率也就越大。
- 重视文档,妥善保存一切测试过程文档。测试计划、测试用例、测试报告都是检查整个开发过程的主要依据,有利于今后流程改进,同时也是测试人员智慧结晶和经验积累,对新人或今后的工作都有指导意义。
3.测试在开发各个阶段的任务
- 项目规划阶段:负责从单元测试到系统测试的整个测试阶段的监控
- 需求分析阶段:确定测试需求分析、系统测试计划的制定,评审后成为管理项目。测试需求分析是对产品生命周期中测试所需的资源、配置、每阶段评选通过的规约;系统测试计划则是依据软件的需求规格说明书,制定测试计划和设计相应的测试用例。
- 详细设计和概要设计阶段:确保集成测试计划和单元测试计划完成
- 编码阶段:由开发人员进行自己负责部分的代码设计。在项目较大时,由专人进行编码阶段的测试任务。
- 测试阶段(单元测试、集成测试、系统测试):根据测试代码进行测试,并提交相应的测试报告和测试结束报告。
4.测试信息流
测试信息流如图1.1所示,测试过程中 需要两类输入信息
- 软件配置:指测试对象。通常包括软件需求规格说明、软件设计规格说明、源代码等。
- 测试配置:通常包括测试计划、测试步骤、测试用例以及实施测试的测试程序、测试工具等。
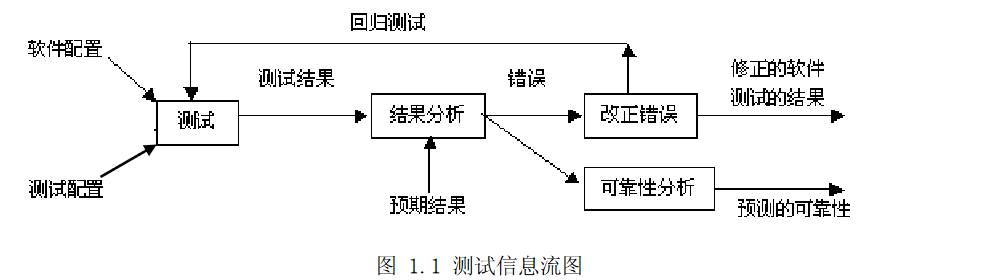
对测试结果与预期的结果进行比较以后,即可判断是否存在错误,决定是否进入排错阶段,进行调试任务。由于修改可能会带来新的问题,我们需要对修改以后的程序重新测试,即进行回归测试。
通常根据出错的情况得到出错率来预计被测试软件的可靠性,这将对软件运行后的维护工作有重要价值。
5.软件测试停止标准
因为无法判定当前发现的故障是否为最后一个故障,所以决定什么时候停止测试是一件非常可能的事。受经济条件的限制,测试最终要停止。在实际工作中,常用的停止测试标准有5类。
第一类标准 测试超过了预定的时间,停止测试
第二类标准 执行了所有测试用例但没有发现故障,停止测试。
第三类标准 使用特定的测试用例设计方法作为判断测试停止的基础。
第四类标准 正面指出测试停止的要求,比如发现并修改70个软件故障
第五类标准 根据单位时间内查处故障的数量决定是否停止测试
第一类标准意义不大,因为即便什么都不敢也能满足这一条。这不能用来衡量测试的质量。
第二类标准同样也没有什么指导作用,因为他客观上鼓励人们编制查不出的测试用例。像上面所讨论的那样,人是有很强工作目的性的。如果告诉测试人员测试用例失败之时就是他完成任务之时,那他会不自觉地以此为目的去编写测试用例,回避那些更有用的,能暴露更多故障的测试用例。第三类标准把使用特定的测试用例设计方法作为判断测试停止的基础。比如,可以定义测试用例的设计必须满足以下两个条件,作为模块测试停止的标准:
- 条件覆盖准则
- 边界值分析
并且由此产生的测试用例最终全部失败。尽管这类标准比前两个标准优越,但他只给出了一个测试用例设计的方法,并不是一个确定的目标。只有测试人员确实能够成功地运用测试用例设计的方法时,才能应用这类标准,并且这类标准只对某些测试阶段适用。
第四类标准正面指出了停止测试的要求,将其定义为查出某一预定数目的故障。他虽然加强了测试的定义,但存在两个方面的问题:如何知道将要查出的故障数:过高或过低估计故障总数。
第五类标准看上去很容易,但在实际使用中要用到很多判断和直觉,他要求人们用图表表示某个测试阶段中单位时间检查出的故障数量。通过分析图表,确定应继续进行测试还是结束这一测试阶段而开始下一测试阶段。
最好的停止测试标准或许是将上面讨论的几类标准结合起来。因为大部分软件开发项目在单元测试阶段并没有正式的跟踪查错过程。所以这一阶段最好的停止测试标准可能是第一类。对于集成测试和系统测试阶段,停止测试的标准可以是查出了预定数量的故障而达到一定的测试期限,但还要分析故障–时间图,只有当改图指明这一阶段的测试效率很低时才能停止测试。
1.2.3 软件测试技术概要
1.软件测试的策略
任何实际的测试,都不能够保证北侧软件中不存在遗漏的缺陷。为了最大程度地减少这种遗漏,同时也为了最大限度的发现已经存在的错误,在测试实施之前,软件测试工程师必须确定将要采用的软件测试策略和方法,并以此为依据制定详细的测试案例。一个好的软件测试策略和方法,必将给软件测试带来事半功倍的效果。他可以充分利用有限的人力和物力资源,高效率,高质量的完成测试。
软件测试的策略就是指测试将按照什么样的思路和方式进行。通常,针对代码得软件测试要经过单元测试、集成测试、确认测试、系统测试和验收测试。
-
单元测试。单元测试也称为模块测试,是在软件测试当中进行的最低一级测试活动,它测试的对象是软件设计的最小单元。在面向过程的结构化程序中,如c程序,其测试的对象一般是函数或子过程。在面向对象的程序中,如c++,单元测试的对象可以是类,也可以是类的成员函数。在第四代语言中,单元测试的原则也基本适用,这时的单元被定义为一个菜单或显示界面。
单元测试的目的就是检测程序模块中的错误故障存在。
单元测试任务是,针对每个程序模块,解决五个方面的问题:模块接口测试,模块局部数据结构测试,覆盖测试,出错处理检测,边界条件测试。
在对每个模块进行单元测试时,需要考虑各模块与周围模块之间的相互联系。因为每个模块在整个软件中并不是单一的。为模拟着已联系,在单元测试时,必须设计辅助测试模块,即驱动模块和桩模块,被测模块与这两个模块一起构成测试环境。
-
集成测试。集成测试是按照设计要求将通过单元测试后的模块组合成一个整体测试的过程。因为程序在某些局部没有出现的问题,很可能在全局上暴露出来。
集成测试方法猪獒分为非增量式集成测试和增量式集成测试两种。
-
确认测试。通过集成测试之后,独立的模块已经联系起来,构成一个完整的程序,其中各模块之间存在问题已被取消,即可以进入确认测试阶段。
所谓确认测试,是对照软件需求规格说明,对软件进行产品评估,以确认其是否满足软件需求的过程。
经过确认测试,应该为已开发的软件作出结论性的评价。这无非存在两种情况:其一,经过检验,软件功能、性能及其他方面的要求都已满足软件需求规格的说明的规定,是一个合格的软件;其二,经过检验,发现与软件需求规格说明有相当的偏离,得到缺陷清单,这就需要开发部门和用户进行协商。找出解决的方法。
-
系统测试。软件和硬件进行了一系列系统集成和测试,以保证系统各组成部件能够协调地工作。系统测试实际是针对系统中各个组成部分进行的综合测试等。系统测试的目的不是要找出软件故障,而是要证明系统的性能。例如,确定安装过程是否会导致不正确的方法,确定系统或程序出现故障之后是否能满足恢复性能要求,确定系统是否能满足可靠性能要求等。
-
验收测试。验收测试是将最终产品和最终用户的当前需求进行比较的全过程是软件开发结束后向用户交付之前进行的最后一次质量检验活动,他解决软件产品是否符合预期的各项要求,用户是否接受等问题。验收测试是全面的质量检验并决定软件是否合格。
验收测试的主要任务是:明确验收测试通过的标准;确定验收计划、方式对其进行评审;确定测试结果的分析方法;设计验收测试的测试用例;执行验收测试,分析验收结果,决定是否通过验收。
2.软件测试方法和技术
软件测试的方法和技术多种多样,可以从不同的角度加以分类:
- 根据执行测试的主体不同,可分为人工测试和自动化测试
- 根据软件测试针对系统的内部结构还是具体实现功能的角度而论,可分为白盒测试法和黑盒测试法。
- 根据软件测试是否执行程序而论,可分为静态测试和动态测试。
- 按照测试的对象分类,涉及面向开发的单元测试、GUI和捕获/回放测试、基于WEB应用的测试、C/C++/JAVA应用测试、负载和性能测试、数据库测试、软件测试和QA管理等各类工具测试。
- 其他测试方法,如回归测试、压力测试、恢复测试、安全测试和兼容性测试等
1.3 软件开发
一个软件的产品的简历可能需要数十个、数百个甚至上千个小组成员各司其职,并且在严格的进度计划中合作。制定这些人做什么、如何交流、如何做决定是软件开发过程的几大部分。软件开发过程是软件工程中的重要内容,也是进行软件测试的基础。
1.3.1软件产品组成
分析构成软件产品的各个部分并了解常用的一些方法,对正确理解具体的软件测试任务和工作过程将十分有益。
一般来说,开发软件产品需要产品说明书、产品审查、设计文档、进度计划、其他公司同类软件产品情况、客户调查、易用性数据、软件代码等一些大多数软件产品用户不曾想到过的内容。
软件行业用来描述制造并交付他人使用的软件产品术语是“可提供的”。为了得到“可提供的”软件产品,需要付出各种各样大量的工作。
1.客户需求
编写软件的目的是满足客户的需求,为了更好地满足要求,产品开发小组必须弄清楚客户的需求。这里的需求包括调差收集的详细信息,以前软件的使用情况及存在的问题,竞争对手的软件产品信息等。除此之外,还有收集到的其他信息,并对这些信息进行研究和分析,以便确定将要开发的软件产品应该具有哪些功能。
要从客户那里得到反馈意见,目前主要的途径除了直接由开发组进行调查外,还需通过独立调查机构进行调查问卷活动,获得有关的问题反馈。
2.产品说明书
对客户要求的研究结果其实只是原始资料,无法描述要做的产品,只是确定哪些要做、哪些不做以及客户所需要的产品功能。产品说明书的格式千差万别。对某些软件产品,如金融公司、航天系统、政府机构、军事部门的特制软件,要采取严格的程序对产品说明书进行检查,检查内容是份详细,并且在整个产品说明书中是完全确定的。在非特殊情况下,产品说明书是不能随意发生变化的,软件开发组的任务是完全确定的。
但有一些开发小组,特别是编制不严格的团队,对某些应用软件产品,其产品说明书写的简单粗糙。这种做法的好处是比较灵活,但存在目标不明确的潜在问题。
3.进度表
软件产品的一个关键部分是进度表。随着项目的不断扩大和复杂性的增加,开发产品需要大量的人力、物力,必须由某种机制来跟踪进度。制定进度的目标是明确哪些工作完成了,哪些没有完成,何时能够完成。通常应用Gantt图标来描述开发进度。如图1.2所示。
4.设计文档
一个常见的错误观念是当程序员创建程序时,没有计划直接就开始编写代码。对于稍大一些程序而言,就必须要有一个计划来编写软件的设计过程。
下面是一些常用软件设计文档的内容:
- 架构。描述软件整体设计的文档,包括软件所有主要部分的描述以及相互之间的交互方式。
- 数据流示意图。表示数据在程序中如何流动的正规示意图,有时称为泡泡图。
- 状态变化示意图。把软件分解为基本状态或者条件的另一种正规示意图,表示不同状态间的变化的方式。
- 流程图。用图形描述逻辑的传统方式。流程图现在不流行了,但是一旦投入使用,根据详细的流程图编写程序代码是很简单的。
- 注释代码。在软件代码中嵌入有用的注释是极为重要的,这样便于维护代码的程序员轻松掌握代码的内容和执行方式。
5.测试文档
测试文档是完整的软件产品一部分。根据软件产品开发过程的需要,程序员和测试员必须对工作进行文档说明。
下面是一般测试文档所包含的内容。
- 测试计划,描述用于验证软件是否符合产品说明书和客户需求的整体方案。
- 测试案例。列举测试的项目,描述验证软件的详细步骤。
- 软件缺陷报告。描述依据测试案例找出的问题。可以在纸上记录,但通常记录在数据库中。
- 归纳、统计和总结。把生产过程转化为测试过程。采用图形、表格和报告等形式。
6.软件产品的其他组成部分
软件产品不仅仅应当关心程序代码,还要关注各种各样的技术支持,这些部分通常由客户使用或查看,所以也需要进行测试。
下面列出软件产品除程序代码之外的其他各种组成
- 帮助文件
- 用户手册
- 样本和示例
- 标签
- 产品支持信息
- 图标和标志
- 错误信息
- 广告和宣传材料
- 软件安装
- 软件说明文件
- 测试错误提示信息
1.3.2开发人员角色
软件开发过程中,软件开发人员各司其职,根据职责的不同分为多种角色
项目经理
项目经理负责管理业务应用开发或者软件和系统开发项目。项目经理角色计划、管理和分配资源,确定优先级,协调用户和客户的交互。项目经理也要建立一系列的时间互动以确保项目工作产品的完整性和质量
业务分析人员
业务分析人员的任务是理解和描述客户的需求,引导和协调用户和业务需求的收集和确认,文档化和组织系统的需求,或者向整个团队传达需求。
架构师
架构师负责理解系统的业务需求,并创建合理、完善的系统架构。架构师也负责通过软件架构来决定主要的技术选择。和典型的包括识别和文档化系统的重要架构方面,包括系统的需求、设计、实现和部署“视图”
数据设计人员
对于大多数的应用开发项目来说,用于持久存储数据的技术是关系型数据库,数据库架构师负责定义详细的数据库设计,包括表、索引、视图、约束、触发器、存储过程和其他的特定数据库用于存储、返回和删除持久性对象的结构。
开发人员
开发人员通常付足额设计和实现可执行的代码方案,测试开发出的组件和分析运行时情况,以去除可能存在的错误哦。又是开发人员还负责创建的体系结构或者快速应用开发工具。
测试人员
系统测试人员负责制定测试计划并依照测试计划进行测试。这些测试包括功能性的测试(黑盒测试)和非功能性的测试(白盒测试)。测试人员需要良好的测试工具来辅助完成测试任务,自动化的测试工具将大幅度提高测试人员的工作效率和质量
1.3.3软件开发模式
1.大棒模式
大棒模式的有点是简单。计划、进度安排和正规开发过程几乎没有。软件项目组成员的所有精力都花在开发软件和编写代码上,它的开发过程是非工程化的。
大棒模式的软件测试通常是再开发任务完成后进行,也就是说以形成了软件产品才进行测试。测试工作有的较为容易,有的则非常困难,这是因为软件及其说明书在最初就已经完成,待形成产品后,已经无法回头修复存在的问题,所以软件测试的工作只是向客户报告软件产品经过测试后发现的情况。
软件产品开发工作应当避免采用大棒模式作为软件开发的方法。
2.边写边改模式
边写边改模式是项目小组为可以采用其他开发模式时常用的一种开发模式,他是在大棒模式基础上的一个进步,考虑到了软件产品的要求。
采用这种方式软件开发通常最初只有粗略的想法,就进行简单的设计,然后开始较长的反复编写、测试和修复过程。在认为无法更精细地描述软件产品要求时就发布产品。
因为从开始就没有计划和文档的编制,项目组能够较为迅速地展现成果。因此,边写边改模式适合用在快速制作而且用完就扔的小项目上。
处于边写边改开发项目的软件测试员要明确的是,其将和程序员一起陷入可能是长期的循环往复的一个开发过程。通常,新的软件版本在不断的产生,而旧的版本的测试工作可能还未完成,新版本还可能包含了新的或修改了的功能。
在进行软件测试工作期间,边写边改开发模式最有可能遇到。虽然他有缺点,但它是通向采用合理软件开发的路子,有助于理解更正规的软件开发模式
3.瀑布模式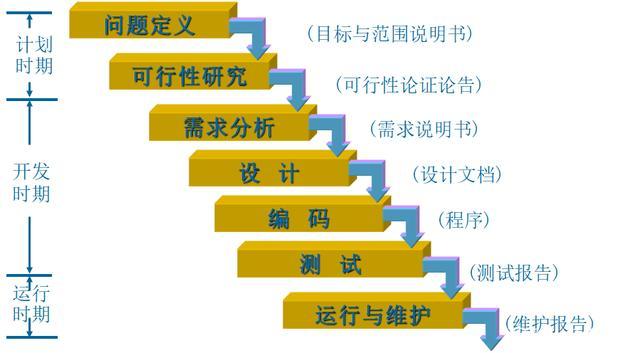
瀑布模式是将软件生命周期的各项活动规定为按照固定顺序相连的若干个阶段性工作,形如瀑布流水,最终得到软件产品。因为这种开发模式形如瀑布,由此而得名。
瀑布模型具有以下的优点:易于理解;调研开发呈阶段性;强调早期计划及需求调查;确定何时能够交付产品及何时进行评审与测试。
但同时瀑布模式也存在以下缺点:需求调查分析只进行一次,不能适应需求的变化;顺序的开发流程,使得开发中的经验教训不能反馈到该项目的开发中去,不能反映出软件开发过程的反复性与迭代性;没有包含任何类型的风险评估;开发中出现的问题直到开发后期才能显露,因此失去了及早纠正的机会。
4.快速原型模式
快速原型模式是一种以计算机为基础的系统开发方法,它首先构造一个功能简单的原型系统,然后通过对原型系统逐步求精,不断扩充完善得到最终的软件系统。原型就是模型,而原型系统就是应用系统的模型。它是待构筑的实际系统的缩小比例模型,但是保留了实际系统的大部分性能。
这个模型可在运行中被检查、测试、修改,直到它的性能达到用户需求为止。因而这个工作模型很快就能转换成原样的目标系统。
快速原型模式的主要优点在于它是一种支持用户的方法,使得用户在系统生存周期的设计阶段起到积极的作用;它能减少系统开发的风险,特别是在大型项目的开发中,由于对项目需求的分析难。以一次完成,应用此方法效果更为明显
5.螺旋模式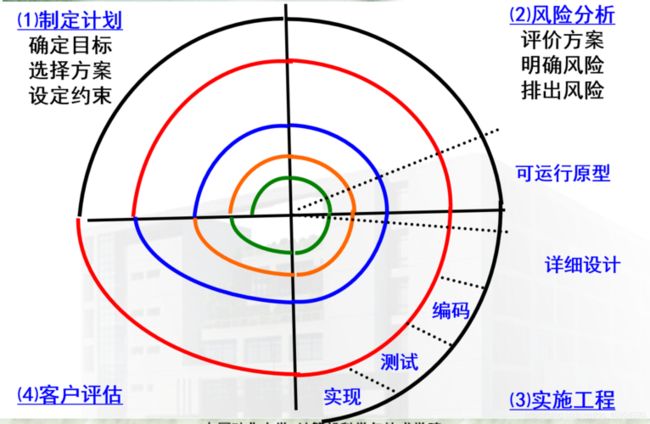
螺旋模式是瀑布模式与边写边改模式演化、结合的形式,并加入了开发风险评估所建立的软件开发模式。
螺旋模式的主要思想是在开始时不必详细定义所有细节,而是从小开始,定义重要功能,尽量实现,接受客户反馈,进入下一阶段并重复上述过程,直到获得最终产品。
每一个螺旋(开发阶段)包括 6 个步骤:
(1)确定目标、选择方案和限制条件;
(2)指出方案风险并解决风险;
(3)对方案进行评估;
(4)进行本阶段的开发和测试;
(5)计划下一阶段;
(6)确定进入下一个阶段的方法。
螺旋开发模式中包含了一些瀑布模式(分析、设计、开发和开发步骤)、边写边改模式(每次盘旋上升)和大棒模式(从外界看)。该开发模式具有发现早、产品的来龙去脉清晰、成本相对低、测试从最初就参与各项工作的特点。该软件开发模式目前最常用,并被广泛认为是软件开发的有效手段。
1.4软件测试过程
美国Carnegie Mellon大学软件工程研究所(Software Engineering  Institute)Don McAndrews于1997年提出一个软件测试过程(Software Test Process)模型,该测试过程模型可用于确认测试、系统测试、验收测试或第三方软件测试过程。在此模型的基础上进行适当的扩充形成一个典型的软件测试过程模型,该测试过程包括6个主要活动如下所述
Institute)Don McAndrews于1997年提出一个软件测试过程(Software Test Process)模型,该测试过程模型可用于确认测试、系统测试、验收测试或第三方软件测试过程。在此模型的基础上进行适当的扩充形成一个典型的软件测试过程模型,该测试过程包括6个主要活动如下所述
- 测试计划,确定测试基本原则,生成测试概要设计
- 测试需求分析
- 测试设计,包括测试用例设计和测试规程规格说明
- 测试规程实现
- 测试执行
- 总结生成报告
1.4.1测试计划
测试计划活动在软件开发项目的定义、规划、需求分析阶段执行,该项活动确定测试的基本原则并生成测试活动的高级计划。
测试计划在软件项目启动时开始,活动输入是项目进度表和系统/软件功能需求的描述(如软件的需求规格说明)测试计划包括以下步骤
1.项目经理和负责人共同参与测试过程相关的测试需求评审,包括
- 进度表中各阶段的日程
- 作为测试活动输入的相关合同中的可交付项
- 项目进度表中针对测试活动而指定的时间
- 客户指定的测试级别
- 估计分配给测试活动的小时数
- 客户在规格说明中指定的质量准则
2.测试负责人制定一个针对项目的测试策略,包括阶段、段、类型和几倍
3.测试负责人完成测试计划、用户规格说明、需求验证测试矩阵等测试策略文档,包括由客户规格说明定义的、从单元/集成测试到系统/验收测试的测试级别流程图
4.测试负责人标示测试过程中产生的所有产品名称及交付日期。
5.项目经理和测试分组恶人标示项目功能需求的来源(如用户需求规格说明、功能规格说明、系统规格说明、合同或其他文档)以便于实现需求追踪。
(6)测试负责人审查用户需求规格说明中的功能需求以确定逻辑测试集。这一工作用于确定可
重用策略。如果已存在类似的项目,测试负责人应当审查已有的测试产品以确定这些测试
产品能否被重用。
(7)测试负责人书写测试设计规格说明提纲。
(8)测试负责人标示项目中将要进行的所有测试活动,包括测试准备、测试执行和测试后的活
动并形成文档。
(9)测试负责人在软件测试计划文档中描述测试活动。
(10)测试负责人在项目进度表中标示测试活动、确定测试活动的起始和结束时间、风险和不可预见费用。
(11)测试负责人完成软件测试计划进度表,列出风险和不可预见费用并在测试活动描述中说明其度量。
(12)基于当前可利用资源,测试项目负责人和项目经理安排测试人员和支持测试的人员并写入测试计划中。
(13)测试负责人在软件测试计划文档中的描述测试可交付项。
(14)测试负责人和系统工程师定义测试环境(测试环境包括可用的硬件环境和必要的软件)并写入测试检查表中。
(15)测试负责人、配置管理员和系统工程师定义测试控制规程(作为项目配置管理的组成部分)并写入测试计划。
(16)测试负责人根据测试计划模板完成软件测试计划。测试计划包括风险和不可预见费用、暂停规则、恢复要求、缩略语列表等。
测试计划完成的标志是生成经过评审的软件测试计划文档,软件测试计划应获得客户的认可。
测试规划完成后测试进入需求分析阶段。
2.测试需求分析
在确定需求追踪矩阵,完成软件测试计划文档后即进入测试需求分析阶段。测试需求分析活动步骤如下:
- 测试负责人和测试工程师审查需求追踪矩阵中每个需求并为其确定测试方法
- 测试负责人和测试工程师审查所有可测的需求并分配到测试设计规格说明中进行详细描述。
- 任何未在软件测试计划中标示的测试设计规格说明内容应当添加到需求跟踪矩阵中。
- 测试工程师生成关于测试需求制定到测试方法的报告供评审。
- 测试工程师生成关于可测试需求制定和测试设计规格说明的报告。
- 随着需求中问题的出现,测试负责人和/或测试工程师书面描述问题并于项目经理讨论些问题。如有必要,会生成基于缺陷的问题报告。
测试需求分析阶段的产品时被批准的需求测试矩阵。
3.测试设计
完成需求测试矩阵和测试计划后,即可进入测试设计阶段。该阶段活动步骤如下。
- 测试工程师审查客户规格说明、需求可测试矩阵和开发文档确保测试设计规格说明的大纲是恰当的。如果考虑可追踪性将是比较困难的,则选择最具有综合性的文档用于软件的开发和维护(可能是软件需求规格说明或其他文档)。测试用例和规程设计应遵循此大纲,以保证需求的可追踪性
- 测试工程师根据测试计划生成测试设计规格说明
- 测试工程师审查从需求测试矩阵分配到测试和设计规格说明的每一测试要求,并给出测试用例的逻辑集大纲
- 测试工程师根据测试计划生成测试用例规格说明。
- 测试工程师根据测试用例分配和可追踪的信息更新需求测试矩阵
- 测试工程师审查从更新的需求测试矩阵分配到测试和设计规划说明的每一测试要求,并给出测试用例的逻辑集大纲
- 测试工程师根据测试规程分配和可追踪的信息更新需求测试矩阵
- 测试工程师根据测试计划生成测试规程规格说明
- 测试工程师审查从需求测试矩阵分配给每个测试规程的需求,手机与每个规程相关的任何附加开发文档。除了下一步之外,这一步骤将贯穿项目接下来的部分。
- 测试工程师参考更新的需求测试矩阵分配给每个规程的需求和任何附加开发文档,给出执行软件现骨干所有相关测试场景的详细说明。在整个项目中随着特定功能的新信息不断产生,测试工程师将信息以需求测试矩阵中测试需求的形式收集。
- 测试工程师准备所有测试规程说明、测试用例规格说明和测试规程规格说名,并更新需求矩阵用于发布和评审。
本次活动完成的标志是生成标准的测试设计规格说明。
4.测试规程说明
测试设计规格说明、测试用例规格说明、测试规程和更新的需求测试矩阵完成后,即可进入测试规程实现阶段,该阶段活动步骤如下。
- 测试工程师审查需求测试矩阵、测试设计规格说明、测试用例规格说明和测试规程,为测试步骤的准备、检查、更新和发布准备详细的工作计划
- 测试负责人从测试工程师获取详细的工作计划,进行计划,跟踪和监督
- 测试工程师根据客户要求的深度撰写详细规程,该规程能够清晰地显示测试规程说明中的场景是如何被覆盖的。
- 测试工程师根据规程实现活动进程的每周报告,分发给项目经理和软件测试组。
- 测试负责人根据测试工程师提供的信息更新高级的工作计划
- 测试负责人准备测试规程实现活动进程的每周报告,分发给项目经理和软件测试组
- 测试工程师引导进行测试规程的正式技术评审
- 测试工程师基于正式技术评审更新测试规程
- 测试工程师基于测试规程的活动更新需求测试矩阵
- 测试工程师打印出最终的可执行规程发布给客户。
- 测试负责人将测试规程和需求测试矩阵发给客户。
测试规程实现活动完成的标志是生成经批准的测试规程和更新需求测试矩阵
**5.测试执行 **
在完成测试规程后进入测试执行阶段。该阶段活动步骤如下:
1.在测试之前,测试负责人he测试工程师为即将进行的测试准备执行规程检查表
2.测试工程师确保所有的规程都经过评审和更新。
3.测试工程师、系统工程师、开发工程师协同工作,为测试时间建立基线和实验设置。所有人都必须知道哪些内容属于基线的范围。
4.在测试时间开始前两周,测试工程师和软件测试组和/开发工程师应执行规程已发现软件和测试文档中存在的问题。
5.测试工程师和客户/或质量管理员一起执行测试。
6.根据测试时间生成软件问题报告
7.测试工程师按照测试计划的定义准备软件测试报告
6.总结生成报告
在完成测试执行活动后进入总结生成报告阶段。
该活动主要任务是测试负责人根据测试计划、测试规程和软件问题报告,分析测试执行结果,总结生成软件测试报告。
活动的结束标志是生成软件测试报告。

第2章 软件测试方法与过程
2.1软件测试复杂性与经济性
人们常常以为,开发一个程序是困难的,测试一个程序则比较容易。然而事实并非如此。在软件测试当中,由于各种原因,不能实现对软件进行完全的测试并找出所有的软件缺陷,使软件达到完美无缺的理想状态。设计测试用例是一项细致并需要高度技巧的工作,稍有不慎就会顾此失彼,
发生不应有的疏漏。除此之外,要通过测试找出软件中的所有故障也是不现实、不可能的,因为这涉及到软件测试的复杂性、充分性和经济性。
1.软件测试的复杂性
无法对程序进行完全的测试
无论是黑盒测试方法还是白盒测试方法,由于测试情况数量巨大,都不可能进行彻底的测试。所谓彻底测试,久石让被测程序在一切可能的输入情况下全部执行一遍。通常也称这种测试为“穷举测试”。“黑盒”法是穷举输入测试,只是把所有可能的输入都作为测试情况使用,才能以这种方法查出程序中所有的错误。实际上测试情况有无穷多个,人们不仅要测试所有合法的输入,而且还要对那些不合法但是可能的输入进行测试。“白盒”法是穷举路径测试,贯穿程序的独立路径数是天文数字,要是每天路径都要得到测试是不现实的。
软件工程的总目标就是重逢利用有限的人力和物力资源,高效率、高质量地完成测试。为了降低测试成本,选择测试用例时应注意遵守“经济性”的原则。第一,要根据程序的重要性和一旦发生故障将造成的损失来确定它的测试等级;第二,要认真研究测试策略,以便能使用尽可能少的测试用例,发现尽可能多的程序错误。掌握好测试量是至关重要的,一位有经验的软件开发管理人员在谈到软件测试时曾这样说过:“不充分的测试是愚蠢的,而过度的测试是一种罪孽”。测试不足意味着让用户承担隐藏错误带来的危险,过度测试则会浪费许多宝贵的资源。

测试无法保证被测程序中无遗留错误
软件测试工作与传染病疫情员的工作是很相似的,疫情员只是报告已经发 现的疫情,却无法报告潜伏的疫情状况。同样通过软件测试只能报告软件已经被发现的缺陷和故障,也不能保证经测试后发现的是全部的软件缺陷,即无法报告隐藏的软件故障。若能继续进行测试工作,可能会发现一
现的疫情,却无法报告潜伏的疫情状况。同样通过软件测试只能报告软件已经被发现的缺陷和故障,也不能保证经测试后发现的是全部的软件缺陷,即无法报告隐藏的软件故障。若能继续进行测试工作,可能会发现一
些新的问题。在实际测试中,穷举测试工作量太大,实践上行不通,这就注定了一切实际测试都是不彻底的。当然就不能够保证被测试程序中不存在遗留的错误。而且在“白盒”法中即使实施了穷举路径测试,程序仍然可能有错误。第一,穷举路径测试决不能查出程序违反了设计规范,即程序本身是个错误的程序。第二,穷举路径测试不可能查出程序中因遗漏路径而出错。第三,穷举路径测试可能发现不了一些与数据相关的错误。E.W.Dijkstra 的一句名言对此作了很好的注解:“程序测试只能证明错误的存在,但不能证明错误不存在”。
不能修复所有的软件故障
在软件测试中,严峻的现实是:即使付出再多的时间和代价,也不能够使所有的软件故障都得到修复。但这并不说明测试没有达到目的,关键是要进行正确的判断、合理的取舍,根据风险分析决定哪些故障必须修复,哪些故障可以不修复。通常不能修复软件故障的理由是:
(1)没有足够的时间进行修复;
(2)修复的风险较大。修复了旧的故障可能产生更多的故障;
(3)不值得修复。主要是在不常用的功能中的故障,或对运行影响不大的故障;
(4)可不算做故障的一些缺陷。在某些场合,错误理解或者软件规格说明变更可以将软件故障当作附加的功能而不作为故障来对待。
2.软件测试的经济性
如果不能做到测试软件所有的情况,则该软件就是有风险的。软件测试不可能对软件使用中所有的情况进行测试,但有可能客户会在使用软件的时候遇到,并且可能发现软件的缺陷。等到这个时候再进行软件缺陷的修复,代价是很高的。
软件测试的一个主要工作原则就是如何将无边无际的可能性减小到一个可以控制的范围,以及如何针对软件风险做出恰当的选择,去粗存精,找到最佳的测试量,使得测试工作量不多不少,既能达到测试的目的,又能较为经济。
测试是软件生存期中费用消耗最大的环节。测试费用除了测试的直接消耗外,还包括其它的相关费用。能够决定需要做多少次测试的主要影响因素如下:
(1)系统的目的
系统的目的的差别在很大程度上影响所需要进行的测试的数量。那些可能产生严重后果的系统必须要进行更多的测试。一台在 Boeing 757 上的系统应该比一个用于公共图书馆中检索资料的系统需要更多的测试。一个用来控制密封燃气管道的系统应该比一个与有毒爆炸物品无关的系统有更高
上的系统应该比一个用于公共图书馆中检索资料的系统需要更多的测试。一个用来控制密封燃气管道的系统应该比一个与有毒爆炸物品无关的系统有更高
的可信度。一个安全关键软件的开发组比一个游戏软件开发组要有苛刻得多的查找错误方面的要求。
(2)潜在的用户数量
一个系统的潜在用户数量也在很大程度上影响了测试必要性的程度。这主要是由于用户团体在经济方面的影响。一个在全世界范围内有几千个用户 的系统肯定比一个只在办公室中运行的有两三个用户的系统需要更多的测试。如果不能使用的话,前一个系统的经济影响肯定比后一个系统大。
的系统肯定比一个只在办公室中运行的有两三个用户的系统需要更多的测试。如果不能使用的话,前一个系统的经济影响肯定比后一个系统大。
除此而外,在分配处理错误的时候,所花的代价的差别也很大。如果在内部系统中发现了一个严重的错误,在处理错误的时候的费用就相对少一些,如果要处理一个遍布全世界的错误就需要花费相当大的财力和精力。
(3)信息的价值
在考虑测试的必要性时,还需要将系统中所包含的信息的价值考虑在内,一个支持许多家大银行或众多证券交易所的客户机/服务器系统中含有经济价值非常高的内容。很显然这一系统需要比一个支持鞋店的系统要进行更多的测试。这两个系统的用户都希望得到高质量、无错误的系统,但是
前一种系统的影响比后一种要大得多。因此我们应该从经济方面考虑,投入与经济价值相对应的时间和金钱去进行测试。

(4)开发机构
一个没有标准和缺少经验的开发机构很可能开发出充满错误的系统。在一个建立了标准和有很多经验的开发机构中开发出来的系统,错误不会很多,因此,对于不同的开发机构来说,所需要的测试的必要性也就截然的不同。 然而,那些需要进行大幅度改善的机构反而不大可能认识到自身的弱点。那些需要更加严格的测试过程的机构往往是最不可能进行这一活动的,在许多情况下,机构的管理部门并不能真正地理解开发一个高质量的系统的好处。
(5)测试的时机
测试量会随时间的推移发生改变。在一个竞争很激烈的市场里,争取时间可能是制胜的关键,开始可能不会在测试上花多少时间,但几年后如果市场分配格局已经建立起来了,那么产品的质量就变得更重要了,测试量就要加大。测试量应该针对合适的目标进行调整。
2.2软件测试方法
软件测试的策略、方法和技术是多种多样的。对于软件测试方法,可以从不同的角度得到以下基本分类:从是否需要执行被测软件的角度,可分为静态测试和动态测试;从测试是否针对系统的内部结构和具体实现算法的角度来看,可分为白盒测试和黑盒测试;根据执行测试的主体不同,又
可以将测试方法分为人工测试和自动化测试。
2.2.1静态测试与动态测试
1.静态测试
在软件开发过程中,每产生一个文档,都必须对它进行测试,以确定它的质量是否满足要求。这样的检查工作与全面质量管理的思想是一致的,也与项目管理过程相一致。每当一个文档通过了静态测试,就标志着一项开发工作的总结,标志着项目取得了一定的进展,进入了一个新的阶段。
静态测试的基本特征是在对软件进行分析、检查和测试时不实际运行被测试的程序。它可以用于对各种软件文档进行测试,是软件开发中十分有效的质量控制方法之一。在软件开发过程中的早期阶段,由于可运行的代码尚未产生,不可能进行动态测试,而这些阶段的中间产品的质量直接关
系到软件开发的成败与开销的大小,因此,在这些阶段,静态测试的作用尤为重要。在软件开发多年的生产实践经验和教训的基础上,人们总结出了一些行之有效的静态测试技术和方法,如结构化走通、正规检视等等。这些方法和测试技术可以与软件质量的定量度量技术相结合,对软件开发过程进行监视、控制,从而保障软件质量。
针对程序代码的静态测试是指不运行被测程序本身,仅通过分析或检查源程序的文法、结构、过程、接口等来检查程序的正确性。静态方法通过程序静态特性的分析,找出欠缺和可疑之处,例如不匹配的参数、不适当的循环嵌套和分支嵌套、不允许的递归、未使用过的变量、空指针的引用和可疑的计算等。静态测试结果可用于进一步的查错,并为测试用例选取提供指导。
针对代码的静态测试包括代码检查、静态结构分析、代码质量度量等。他可以由人工进行,充分发挥人的逻辑思维优势,也可以借助软件工具自动进行。
(1)代码检查 代码检查主要检查代码和设计的一致性,代码对标准的遵循、可读性,代码的逻辑表达的正确性,代码结构的合理性等方面;可以发现违背程序编写标准的问题,程序中不安全、不明确和模糊的部分,找出程序中不可移植部分、违背程序编程风格的问题,包括变量检查、命名
和类型审查、程序逻辑审查、程序语法检查和程序结构检查等内容。
在实际使用中,代码检查比动态测试更有效率,能快速找到缺陷,发现 30%~70%的逻辑设计和编码缺陷;代码检查看到的是问题本身而非征兆。但是代码检查非常耗费时间,而且代码检查需要知识和经验的积累。代码检查应在编译和动态测试之前进行,在检查前,应准备好需求描述文档、程序设计文档、程序的源代码清单、代码编码标准和代码缺陷检查表等。
(2)静态结构分析 静态结构分析主要是以图形的方式表现程序的内部结构,例如函数调用关系图、函数内部控制流图。其中,函数调用关系图以直观的图形方式描述一个应用程序中各个函数的调用和被调用关系;控制流图显示一个函数的逻辑结构,它由许多节点组成,一个节点代表一条
语句或数条语句,连接结点的叫边,边表示节点间的控制流向。
(3)代码质量度量 ISO/IEC 9126 国际标准所定义的软件质量包括六个方面:功能性、可靠性、易用性、效率、可维护性和可移植性。软件的质量是软件属性的各种标准度量的组合。
针对软件的可维护性,目前业界主要存在三种度量参数:Line 复杂度、Halstead 复杂度和 McCabe复杂度。其中 Line 复杂度以代码的行数作为计算的基准。Halstead 以程序中使用到的运算符与运算元数量作为计数目标(直接测量指标),然后可以据此计算出程序容量、工作量等。McCabe 复杂度一般称为圈复杂度(Cyclomatic complexity),它将软件的流程图转化为有向图,然后以图论来衡量软件的质量。McCabe 复杂度包括圈复杂度、基本复杂度、模块设计复杂度、设计复杂度和集成复
杂度。
2.动态测试
所谓动态测试是指通过运行被测程序,检查运行结果和预期结果的差异,并分析运行效率和健壮性等性能,动态测试包括功能确认与接口测试、覆盖率分析、性能分析、内存分析等。
(1) 功能确认与接口测试 这部分的测试包括各个单元功能的正确执行、单元间的接口,包括:单元接口、局部数据结构、重要的执行路径、错误处理的路径和影响上述几点的边界条件等内容。
(2) 覆盖率分析 覆盖率分析主要对代码的执行路径覆盖范围进行评估,语句覆盖、判定覆盖、条件覆盖、条件/判定覆盖、修正条件/判定覆盖、基本路径覆盖都是从不同要求出发,为设计测试用例提出依据的。
(3) 性能分析 代码运行缓慢是开发过程中一个重要问题。一个应用程序运行速度较慢,程序员不容易找到是在哪里出现了问题。如果不能解决应用程序的性能问题,将降低并极大地影响应用程序的质量,于是查找和修改性能瓶颈成为调整整个代码性能的关键。目前性能分析工具大致分为纯软件的测试工具、纯硬件的测试工具(如逻辑分析仪和仿真器等)和软硬件结合的测试工具三类。
(4) 内存分析 内存泄漏会导致系统运行的崩溃,尤其对于嵌入式系统这种资源比较匮乏、应用非常广泛,而且往往又处于重要部位的,将可能导致无法预料的重大损失。通过测量内存使用情况,我们可以了解程序内存分配的真实情况,发现对内存的不正常使用,在问题出现前发现征兆,在系统崩溃前发现内存泄露错误;发现内存分配错误,并精确显示发生错误时的上下文情况,指出发生错误的原由。
2.2.2黑盒测试与白盒测试
1.黑盒测试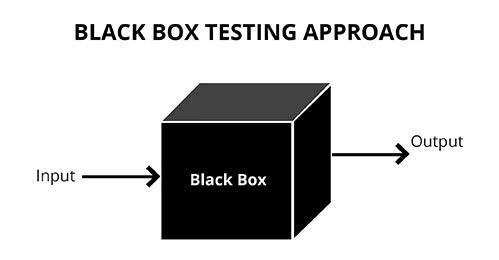
黑盒测试是指在对程序进行的功能抽象的基础上,将程序划分成功能单元,然后对每个功能单元生成测试数据进行测试。黑盒测试也称功能测试或数据驱动测试,它是已知产品所应具有的功能,通过测试来检测每个功能是否都能正常使用。在测试时,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,测试者在程序接口进行测试,只检查程序功能是否按照需求规格说明书的规定正常使用,程序是否能适当接收输入数据而产生正确的输出信息,并且保持外部信息的完整性。
在黑盒测试中,被测软件的输入域和输出域往往是无限域,因此穷举测试通常是不行的。必须以某种策略分析软件规格说明,从而得出测试用例集,尽可能全面而又高效的对软件进行测试。下面就几种功能测试的方法进行简单介绍,具体说明会在后面的章节进行。
a.等价类划分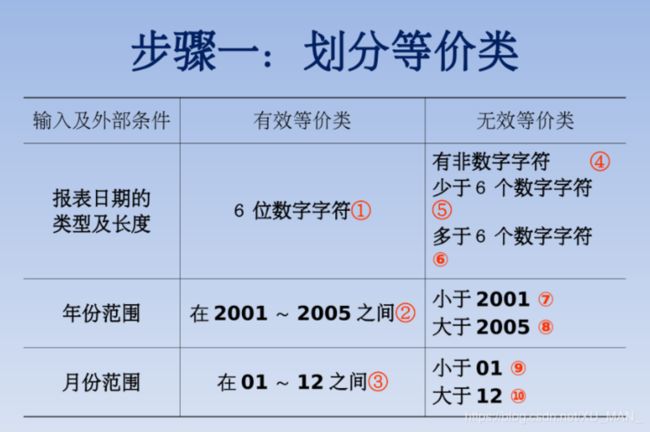
所谓等价类,就是某个输入域的集合,集合中的每个输入对揭露程序错误都是等效的,把程序的输入域划分成若干部分,然后从每个部分中选取少数代表型数据作为测试用例,这就是等价类划分方法,他是功能测试的基本方法。
b.因果图法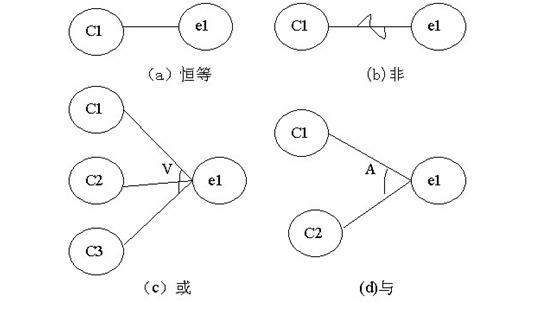
因果图是一种形式语言,由自然语言写成的规范转换而成,这种形式语言实际上是一种使用简化记号表示数字逻辑图。因果图法是帮助人们系统地选择一组高效测试用例的方法,此外,它还能指出程序规范中的不完全性和二义性。
c.边界值分析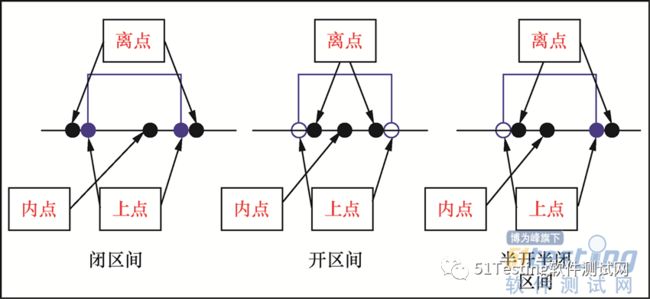
实践证明,软件在输入、输出域的边界附近容易出现差错,边界值分析是考虑边界条件而选取测试用例的一种功能测试方法。所谓边界条件,是相对于输入和输出等价类直接在其边界上,或稍高于和稍低于其边界的这些状态条件。边界值分析是对等价类划分的有效补充。
另外常见的黑盒测试方法还有基于决策表的测试、错误推测法等。
2.白盒测试
白盒测试是根据被测程序的内部结构设计测试用例的一类测试,又称为结构测试或逻辑驱动测试,它是知道产品内部工作过程,通过测试来检测产品内部动作是否按照规格说明书的规定正常进行,按照程序内部的结构测试程序,检验程序中的每条通路是否都能按预定要求正确工作。其主要方法有逻辑覆盖、基本路径测试等,主要用于软件验证。白盒法全面了解程序内部逻辑结构、对所有逻辑路径进行测试,是穷举路径测试。在使用这一方案时,测试者必须检查程序的内部结构,从检查程序的逻辑着手,得出测试数据,测试程序的内部变量状态、逻辑结构、运行路径等,检验程
序中的每条通路是否都能按预定要求正确工作,所有内部成分是否按规定正常进行。
贯穿程序的所有路径数是天文数字,所以白盒测试法在实际操作时不可能实现路径的穷举。它常以达到对程序内部结构的某种覆盖标准为目标。白盒测试主要用于软件验证,其主要方法有逻辑覆盖、数据流覆盖等。
不同的测试方法各有所长,都能比较容易地发现某种类型的错误,却不易发现其他类型的错误,各有侧重、各有优缺点,构成互补关系。白盒测试可以有效地发现程序内部的编码和逻辑错误,但无法检验出程序是否完成了规定的功能;黑盒测试可以根据程序的规格说明检测出程序是否完成了规定的功能,但未必能够提供对代码的完全覆盖,而且规格说明往往会出现具有歧义或不完整的情况,这在一定程度上降低了黑盒测试的效果。因此在实际测试中,应结合各种测试方法形成综合策略。一般在单元测试阶段主要用白盒测试,在系统测试时主要用黑盒测试。
实际上,黑盒测试法和白盒测试法的界限现在已经变得越来越模糊了,因为单纯地根据规约或代码生成测试用例都不是很现实的。目前己有越来越多的人在尝试将这两种方法结合起来,例如根据规格说明来生成测试用例,然后根据代码(静态分析或动态执行代码)来进行测试用例的取舍和
精化等,以至形成了所谓的“灰盒测试”法。这也是目前软件测试的一个发展方向。
2.2.3 人工测试与自动化测试
1.人工测试
广义上,人工测试是人为测试和手工测试的统称。人为测试的主要方法有桌前检查 (deskchecking) ,代码审查( code review )和走查( walkthrough )。事实上,用于软件开发各个阶段的审查( inspection )或评审 (review) 也是人为测试的一种。经验表明,使用这种方法能够
有效地发现 30% 到 70% 的逻辑设计和编码错误。由于人为测试技术在检查某些编码错误时,有着特殊的功效,它常常能够找出利用计算机不容易发现的错误。人为测试至今仍是一种行之有效的测试方法。手工测试指的是在测试过程中,按测试计划一步一步执行程序,得出测试结果并进行分析的测试行为。目前,在功能测试中经常使用这种测试方法。
2.自动化测试
自动化测试指的是利用测试工具来执行测试,并进行测试结果分析的测试行为。自动化测试不可能完全自动,它离不开人的智力劳动。但是它能替代人做一些繁琐或不可能通过手工达到的事情。由于测试工作的繁重性、重复性等特征,自动化测试是提高测试效率的一个有效方法,也是目前测
试研究领域的一个热点。
2.3软件测试阶段
软件测试贯串软件产品开发的整个生命周期,软件项目一开始软件测试也就开始了。从过程来看,软件测试是由一系列的不同测试阶段所组成的。这些阶段分为:规格说明书审查、系统和程序设计审查、单元测试、集成测试、确认测试、系统测试以及验收(用户)测试。软件开发的过程是
自顶向下的,测试则正好相反,上述过程就是自底向上、逐步集成的。
规格说明书审查
为保证需求定义的质量,应对需求分析规格说明书进行严格的审查。由测试人员参与系统或产品需求分析,认真阅读有关用户需求分析文档,真正理解客户的需求,检查规格说明书对产品描述的准确性、一致性等,为今后熟悉应用系统、编写测试计划、设计测试用例等做好准备工作。
系统和程序设计审查
代码会审是一种静态的白盒测试方法,是由一组人通过阅读、讨论来审查程序结构、代码风格、算法等的过程。会审小组由组长、3-5 名程序设计人员、编程人员和测试人员组成。会审小组在充分阅读待审程序文本、控制流程图及有关要求、规范等文件基础上,召开代码会审会。实践表明,
代码会审做得好的话可以发现大部分程序缺陷,甚至程序员在自己讲解过程中就能发现不少代码错误,而讨论可能进一步促使问题暴露。
单元测试
单元测试集中对用源代码实现的每一个程序单元进行测试,检查各个程序模块是否正确地实现了规定的功能。
集成测试
该阶段把已测试过的模块组装起来,主要对与设计相关的软件体系结构的构造进行测试。
确认测试
检查已实现的软件是否满足了需求规格说明中确定了的各种需求以及软件配置是否完全、正确。
系统测试
把已经经过确认的软件纳入实际运行环境中,与其它系统成份组合在一起进行测试。
验收测试
检验软件产品的最后一道工序,主要突出用户的作用,同时软件开发人员也应有一定的程度参与。
2.4 单元测试
单元测试又称模块测试,是针对软件设计的最小单位——程序模块,进行正确性检验的测试工作。其目的在于发现各模块内部可能存在的各种差错。这个阶段更多关注程序实现的细节,需要从程序的内部结构出发设计测试用例。多个模块可以平行地独立进行单元测试。
2.4.1 单元测试主要任务
在单元测试时,测试者需要依据详细设计说明书和源程序清单,了解该模块的I/O条件和模块的逻辑结构,主要采用白盒测试的测试用例,辅之以黑盒测试的测试用例,使之对任何合理的输入和不合理的输入,都能鉴别和响应。它主要测试以下几方面的问题:
1.模块接口测试
(1)单元测试的开始,应对通过被测模块的数据流进行测试。测试项目包括:
① 调用本模块的输入参数是否正确;
② 本模块调用子模块时输入给子模块的参数是否正确;
③ 全局量的定义在各模块中是否一致;
④ 是否修改了只做输入用的形式参数。
(2)在做内外存交换时需要考虑:
① 文件属性是否正确;
② OPEN 与 CLOSE 语句是否正确;
③ 缓冲区容量与记录长度是否匹配;
④ 在进行读写操作之前是否打开了文件;
⑤ 在结束文件处理时是否关闭了文件;
⑥ 正文书写/输入错误;
⑦ I/O 错误是否检查并做了处理。
2.局部数据结构测试
(1)不正确或不一致的数据类型说明。
(2)使用尚未赋值或尚未初始化的变量。
(3)错误的初始值或错误的缺省值。
(4)变量名拼写错或书写错。
(5)不一致的数据类型。
(6)上溢、下溢或地址异常。
3.路径测试
(1)选择适当的测试用例,对模块中重要的执行路径进行测试。
(2)应当设计测试用例查找由于错误的计算、不正确的比较或不正常的控制流而导致的错误。
(3)对基本执行路径和循环进行测试可以发现大量的路径错误。
4.错误处理测试
(1)出错的描述是否难以理解。
(2)出错的描述是否能够对错误定位。
(3)显示的错误与实际的错误是否相符。
(4)对错误条件的处理正确与否。
(5)在对错误进行处理之前,错误条件是否已经引起系统的干预等。
5.边界测试
注意数据流、控制流中刚好等于、大于或小于确定的边界值时出错的可能性,对这些地方要仔细地选择测试用例,认真加以测试。
如果对模块运行时间有要求的话,还要专门进行关键路径测试,以确定最坏情况下和平均意义下影响模块运行时间的因素。
2.4.2 单元测试执行过程
通常单元测试在编码阶段进行,在源程序代码编制完成,经过评审和验证,确认没有语法错误之后,就开始进行单元测试的测试用例设计。利用设计文档,设计可以验证程序功能、找出程序错误的多个测试用例。对于每一组输入,应有预期的正确结果。
模块并不是一个独立的程序,在考虑测试模块时,同时要考虑它和外界的联系,用一些辅助模块去模拟与被测模块相联系的其它模块。这些辅助模块分为两种:
驱动模块(driver):泳衣模拟被测模块的上级模块,他接受测试数据,把这些数据传送给被测模块,启动被测模块,最后输出实测结果。
桩模块(stub):也称为存根程序,用以模拟被测模块工作过程中所调用的子模块。桩模块由被测模块调用,他们一般只进行很少的数据处理,例如打印入口和返回,以便于用于检验被测模块与其下级模块的接口。桩模块可以做少量的数据操作,不需要把子模块所有功能都带进来,但不允许什么事情也不做。
被测模块与它相关的驱动模块以及桩模块共同构成了一个“测试环境”。如果一个模块要完成多种功能,且以程序包或对象类的形式出现,例如Ada中的包,MODULA中的模块,C++中的类。这是可以将这个模块看成由几个小程序组成。对其中的每个小程序先进行单元测试要做的工作,对关键模块还要做性能测试。对支持某些标准规程的程序,更要着手进行互联测试。有人把这种情况特别成为模块测试,以区别单元测试。
2.5集成测试
集成测试,也称为组装测试或联合测试。在单元测试的基础上,将所有模块按照设计要求组装成子系统或系统,进行集成测试,一些模块虽然能够单独地工作,但并不能保证连接起来也能正常的工作。程序在某些局部反映不出来的问题,在全局上很可能暴露出来,影响功能的实现。
2.5.1集成模式
选择什么样的方式把模块组装起来形成一个可运行的系统,直接影响到测试成本、测试计划、测试用例的设计、测试工具的选择等。通常有两种集成方式:一次性集成方式和增量式集成方式。
1.一次性集成测试模式
它是一种非增量式组装方式,也叫做整体拼装。使用这种方式,首先对每个模块分别进行模块测试,然后再把所有模块组装在一起进行测试,最终得到要求的软件系统。
2.增量式集成测试模式
增量式的测试方法与非增量式的测试不同,它的集成是逐步实现的,集成测试也是逐步完成的,又称渐增式集成。也可以说它将单元测试与集成测试结合起来进行。首先对一个个模块进行模块测试,然后将这些模块逐步组装成较大的系统,在集成的过程中边连接边测试,以发现连接过程中产
生的问题,通过增殖逐步组装成为要求的软件系统。
一次性集成测试的方法是先分散测试,然后集中一起来再一次完成集成测试。假如在模块的接口处存在错误,只会在最后的集成测试时一下子暴露出来。这时为每个错误定位和纠正非常困难,并且在改正一个错误的同时又可能引入新的错误,新旧错误混杂,更难断定出错的原因和位置。与
此相反,增量式集成测试的逐步集成和逐步测试的方法,将可能出现的差错分散暴露出来,错误易于定位和纠正。而且一些模块在逐步集成的测试中,得到了较多次的考验,因此,接口测试更加彻底,能取得较好的测试结果。总之,增量式测试要比非增量式测试具有一定的优越性。两种模式中,增量式测试模式虽然需要编写的 Driver 或 Stub 程序较多、发现模块间接口错误相对稍晚些,但增量式测试模式还是具有比较明显的优势。一次性集成测试模式一般不推荐使用,不过在规模较小的应用系统中还是比较适合使用的。
2.5.2集成方法
当对两个以上模块进行集成时,不可能忽视它们和周围模块的相互联系。为模拟这种联系,需设置若干辅助测试模块,也就是连接被测试模块的程序段。和单元测试阶段一样,辅助模块通常有驱动模块和桩模块两种。
增量式集成测试可以按照不同的次序实施,因此通常有两种不同的方法,也就是自顶向下结合和自底向上结合。
1.自顶向下集成
自顶向下集成是从主控模块开始,按照软件的控制层次结构向下逐步把各个模块集成在一起。集成过程中可以采用深度优先或广度优先的策略。其中按深度方向组装的方式,可以首先实现和验证一个完整的软件功能。
自顶向下集成的具体步骤可以描述为:
(1)对主控模块进行测试,测试时用桩程序代替所有直接附属于主控模块的模块;
(2)根据选定的结合策略(深度优先或广度优先),每次用一个实际模块代替一个桩模块(新结合进来的模块往往又需要新的桩模块);
(3)在结合下一个模块的同时进行测试;
(4)为了保证加入模块没有引进新的错误,可能需要进行回归测试(即全部或部分地重复以前做过的测试);
从第(2)步开始不断地重复进行上述过程,直至完成。
自顶向下集成能尽早地对程序的主要控制和决策机制进行检验,因此较早地发现错误。但是在测试较高层模块时,低层处理采用桩模块替代,不能反映真实情况,重要数据不能及时回送到上层模块,因此测试并不充分。自顶向下集成不需要驱动模块,但需要建立桩模块,要使桩模块能够模拟实际子模块的功能十分困难,因为桩模块在接收了所测模块发送的信息后需要按照它所代替的实际子模块功能返回应该回送的信息,这必将增加建立桩模块的复杂度,而且导致增加一些附加的测试。另外,涉及复杂算法和真正输入/输出的模块一般在底层,它们是最容易出问题的模块,到组装和测试的后期才遇到这些模块,一旦发现问题,导致过多的回归测试。
2.自底向上集成
自底向上集成是从“原子”模块(即软件结构最低层的模块)开始组装测试。因为模块是自底向上进行组装,对于一个给定层次的模块,它的子模块(包括子模块的所有下属模块)已经组装并测试完成,所以不再需要桩模块,在模块的测试过程中需要从子模块得到的信息可以直接运行子模块
得到。其具体步骤是:
(1)把低层模块组合成实现某个特定软件子功能的族;
(2)写一个驱动程序(用于测试的控制程序),协调测试数据的输入和输出;
(3)对由模块组成的子功能族进行测试;
(4)去掉驱动程序,沿软件结构自下向上移动,把子功能族组合起来形成更大的子功能族;
从第(2)步开始不断重复进行上述过程,直至完成。
自底向上集成的缺点是“程序一直未能作为一个实体存在,直到最后一个模块加上去后才形成一个实体”。就是说,在自底向上组装和测试的过程中,对主要的控制直到最后才接触到。但这种方式的
优点是不需要桩模块,而建立驱动模块一般比建立桩模块容易,同时由于涉及到复杂算法和真正输入/输出的模块最先得到组装和测试,可以把最容易出问题的部分在早期解决。此外自底向上集成可以实施多个模块的并行测试,提高测试效率。
3.混合集成
自顶向下增殖的方式和自底向上增殖的方式各有优缺点。一般来讲,一种方式的优点是另一种方式的缺点。因此,具体测试时通常是把以上两种方式结合起来进行集成和测试。混合集成是自顶向下和自底向上集成的组合。一般对软件结构的上层使用自顶向下结合的方法,对下层使用自底向上结合的方法。
另外在组装测试时,应当确定关键模块,并尽量对这些关键模块及早进行测试。关键模块的特征是:=满足某些软件需求;在程序的模块结构中位于较高的层次(高层控制模块);较复杂、较易发生错误;有明确定义的性能要求。
2.5.3持续集成
在实际测试中,应该将不同集成模式有机结合起来,采用并行的自顶向下、自底向上混合集成方式,而更重要的是采取持续集成的策略。软件开发中各个模块不是同时完成,根据进度将完成的模块尽可能早的进行集成,有助于尽早发现缺陷,避免集成阶段大量缺陷涌现。同时自底向上集成时,先期完成的模块将是后期模块的桩程序,而自顶向下集成时,先期完成的模块将是后期模块的驱动程序,从而使后期模块的单元测试和集成测试出现了部分的交叉,不仅节省了测试代码的编写,也有力于提高工作效率。
如果不采用持续集成策略,开发人员经常需要集中开会来分析软件究竟在什么地方出了错。因为某个程序员在写自己这个模块代码时,可能会影响其它模块的代码,造成与已有程序的变量冲突、接口错误,结果导致被影响的人还不知道发生了什么,缺陷就出现了。随着时间的推移,问题会逐
渐恶化。通常,在集成阶段出现的缺陷早在几周甚至几个月之前就已经存在了。结果,开发者需要在集成阶段耗费大量的时间和精力来寻找这些缺陷的根源。如果使用持续集成,这样的缺陷绝大多数都可以在引入的第一天就被发现。而且,由于一天之中发生变动的部分并不多,所以可以很快找到出错的位置。这也就是为什么进行每日构建软件包的原因所在。所以,持续集成可以减少集成阶段消灭缺陷所消耗的时间,从而提高软件开发的质量与效率。
2.5.4 回归测试
在软件生命周期中的任何一个阶段,只要软件发生了改变,就可能给该软件带来问题。软件的改变可能是源于发现了错误并做了修改,也有可能是因为在集成或维护阶段加入了新的模块。在增量型软件开发过程中,通常将软件分成阶段进行开发,在一个阶段的软件开发结束后将被测软件交
给测试组进行测试,而下一个阶段增加的软件又有可能对原来的系统造成破坏。因此,每当软件发生变化时,我们就必须进行回归测试,重新测试原有的功能,以便确定修改是否达到了预期的目的,检查修改是否损害了原有的正常功能
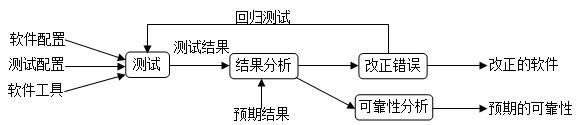
具体的方法可以是:对修改过的代码重新运行现有的测试,确定更改是否破坏了在更改之前有效的任何事物,并且在必要的地方编写新测试。执行回归测试时,首要考虑的应该是覆盖范围足够大但不浪费时间。尽可能少花时间执行回归测试,但不减少在旧的、已经测试过的代码中检测新失
败的可能性
此过程中需考虑的一些策略和因素包括下列内容:
\1. 即测试已修复的错误。程序员可能已经处理了症状,但并未触及根本原因;
\2. 监视修复的副作用。错误本身可能得到了修复,但修复也可能造成其他错误;
\3. 为每个修复的错误编写一个回归测试;
\4. 如果两个或更多的测试类似,确定哪一个效率较低并将其删除;
\5. 识别程序始终通过的测试并将它们存档;
\6. 集中考虑功能性问题,而不是与设计相关的问题;
\7. 更改数据(更改量可多可少)并找出任何产生的损坏;
\8. 跟踪程序内存更改的效果。
在实际工作中,回归测试需要反复进行,当测试者一次又一次地完成相同的测试时,这些回归测试将变得非常令人厌烦,而在大多数回归测试需要手工完成的时候尤其如此,因此,需要通过自动测试来实现重复的和一致的回归测试。通过测试自动化可以提高回归测试效率。在测试软件时,
应用多种测试技术是常见的。当测试一个修改了的软件时,测试者也可能希望采用多于一种回归测试策略来增加对修改软件的信心。不同的测试者可能会依据自己的经验和判断选择不同的回归测试技术和策略。因此为了支持多种回归测试策略,自动测试工具应该是通用的和灵活的,以便满足达到不同回归测试目标的要求。
回归测试并不减少对系统新功能和特征的测试需求,回归测试也包括新功能和特征的测试。如果回归测试包不能达到所需的覆盖要求,必须补充新的测试用例使覆盖率达到规定的要求。
回归测试是重复性较多的活动,容易使测试者感到疲劳和厌倦,降低测试效率,在实际工作中可以采用一些策略减轻这些问题。例如,安排新的测试者完成手工回归测试,分配更有经验的测试者开发新的测试用例,编写和调试自动测试脚本,做一些探索性的测试。还可以在不影响测试目标
的情况下,鼓励测试者创造性地执行测试用例,变化的输入、按键和配置能够有助于激励测试者又能揭示新的错误。
在组织回归测试时需要注意两点,首先是个测试阶段发生的修噶一定要在本测试阶段内完成回归,以免将错误遗留到下一阶段。其次,回归测试期间应对该软件版本冻结,将回归测试发现的问题集中修改,集中回归。
在实际工作中,可以将回归测试与兼容性测试结合起来进行。在新的配置条件下运行旧的测试可以发现兼容性问题,同时也可以揭示编码在回归方面的错误。
2.6确认测试
确认测试又称有效性测试。他的任务是验证软件的有效性,即验证软件的功能和性能及其他特性是否与用户的要求一致。在软件需求规格说明书描述了全部用户可见的软件属性,其中有一节叫做有效性准则,它包含的信息就是软件确认测试的基础。
在确认测试阶段主要进行有效性测试以及软件配置复审。
1.进行有效性测试(功能测试)
有效性测试是在模拟的环境(可能就是开发的环境)下,运用黑盒测试的方法,验证被测软件是否满足需求规格说明书列出的需求。为此,需要首先制定测试计划,规定要做测试的种类。还需要制定一组测试步骤,描述具体的测试用例。通过实施预定的测试计划和测试步骤,确定软件的特
性是否与需求相符,确保所有的软件功能需求都能得到满足,所有的软件性能需求都能达到,所有的文档都是正确且便于使用。同时,对其它软件需求,例如可移植性、兼容性、出错自动恢复、可维护性等,也都要进行测试,确认是否满足。
2.软件配置复查
软件配置复查的目的是保证软件配置的所有成分都齐全,各方面的质量都符合要求,具有维护阶段所必需的细节,而且已经编排好分类的目录。
除了按合同规定的内容和要求,由人工审查软件配置之外,在确认测试的过程中,应当严格遵守用户手册和操作手册中规定的使用步骤,以便检查这些文档资料的完整性和正确性。必须仔细记录发现的遗漏和错误,并且适当地补充和改正。
2.7系统测试
所谓系统测试,是将通过确认测试的软件,作为基于整个计算机系统的一个元素,与计算机硬件、外设、某些支持软件、数据和人员等其他系统元素结合在一起,在实际运行(使用)环境下,对计算机系统进行一系列的严格有效的测试以发现软件的潜在问题,保证系统的运行。
系统测试明显区别于功能测试。功能测试主要是验证软件功能的实现情况,不考虑各种环境以及非功能问题,如安全性、可靠性、性能等,而系统测试是在更大的范围内进行的测试,着重对系统的性能、特性进行测试。它的目的在于通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。所以系统测试的测试用例应该根据需求分析规格说明来设计,并在实际使用环境下来运行。
下面对系统测试的内容进行简要介绍:
1.强度测试
强度测试是要检查在系统运行环境不正常乃至发生故障的情况下,系统可以运行到何种程度的测试。强度测试需要在反常规数据量、频率或资源的方式下运行系统,以检查系统能力的最高实际限度。例如:输入数据速率提高一个数量级,确定输入功能将如何响应;或设计需要占用最大存储
量或其它资源的测试用例进行测试。
强度测试的一个变种就是敏感性测试。在程序有效数据界限内一个小范围内的一组数据可能引起极端的或不平稳的错误处理出现,或者导致极度的性能下降的情况发生。此测试用以发现可能引起这种不稳定性或不正常处理的某些数据组合。
2.性能测试
性能测试用来测试软件在系统集成中的运行性能,检查其是否满足需求说明书中规定的性能,特别是对于实时系统或嵌入式系统,仅提供符合功能需求但不符合性能需求的软件是不能接受的。
性能测试可以在测试过程的任意阶段进行,即使是在单元层,但只有当整个系统的所有成分都集成在一起后,才能检查一个系统的真正性能。性能测试常常需要与强度测试结合起来进行,并常常要求同时进行硬件和软件检测,这就是说,常常有必要在一种苛刻的资源环境中衡量资源的使用。通常,对软件性能的检测表现在以下几个方面:响应时间、吞吐量、辅助存储区,例如缓冲区,工作区的大小等、处理精度,等等。
外部的测试设备可以检测测试执行,当出现某种情况时可以记录下来。通过对系统的检测,测试者可以发现导致效率降低和系统故障的原因。为了记录性能,需要在系统中安装必要的量测仪表或者为度量性能而设置的软件。
3.恢复测试
恢复测试是要证实在克服硬件故障(包括掉电、硬件或网络出错等)后,系统能否正常地继续进行工作,并不对系统造成任何损害。为此,可采用各种人工干预的手段,模拟硬件故障,故意造成软件出错,并由此检查系统的错误探测功能──系统能否发现硬件失效与故障;能否切换或启动备用的硬件;在故障发生时能否保护正在运行的作业和系统状态;在系统恢复后能否从最后记录下来的无错误状态开始继续执行作业,等等。例如掉电测试,它的目的是测试软件系统在发生电源中断时能否保护当时的状态且不毁坏数据,然后在电源恢复时从保留的断点处重新进行操作。
4.安全测试
任何管理敏感信息或者能够对个人造成不正当伤害的计算机系统都是不正当或非法侵入的目标。通常力图破坏系统的保护机构以进入系统的主要方法有:正面攻击或从侧面、背面攻击系统中易受损坏的那些部分;以系统输入为突破口,利用输入的容错性进行正面攻击;申请和占用过多的
资源压垮系统,以破坏安全措施,从而进入系统;故意使系统出错,利用系统恢复的过程,窃取用户口令及其它有用的信息;通过浏览残留在计算机各种资源中的垃圾(无用信息),以获取如口令,安全码,译码关键字等信息;浏览全局数据,期望从中找到进入系统的关键字;浏览那些逻辑上不存在,但物理上还存在的各种记录和资料等。
安全性测试是要检验在系统中已经存在的系统安全性、保密性措施是否发挥作用,有无漏洞,以检查系统对非法侵入的防范能力。安全测试期间,测试人员假扮非法入侵者,采用各种方法试图突破防线。系统安全设计的准则是,使非法侵入的代价超过被保护信息的价值。
5.可靠性测试
软件可靠性是软件系统在规定的时间内和规定的环境条件下,完成规定功能的能力。它是软件系统的固有特性之一,表明了一个软件系统按照用户的要求和设计目标,执行其功能的可靠程度。
软件可靠性与软件缺陷有关,也与系统输入与系统使用有关。理论上说,可靠的软件系统应该是正确、完整、一致和健壮的。但是实际上任何软件都不可能达到百分之百的正确,而且也无法精确度量。一般情况下,只能通过对软件系统进行测试来度量其可靠性。
可靠性测试是从验证的角度出发,为了检验系统的可靠性是否达到预期目标而进行的测试。它通过测试发现并纠正影响可靠性的缺陷,实现软件可靠性增长,并验证其是否达到了用户的可靠性要求。该测试需要从用户的角度出发,模拟用户实际使用系统的情况,设计出系统的可操作视图。
在这个基础上,根据输入空间的属性及依赖关系导出测试用例,然后在仿真的环境或真实的环境下执行测试用例并记录测试的数据。
根据在测试过程中收集获得的失效数据,如失效间隔时间、失效修复间、失效数量、失效级别等,应用可靠性模型,可以得到系统的失效率及可靠性增长趋势。其中可靠性增长趋势是测试开始时的失效率与测试结束时的失效率之比。
从黑盒(占主要地位)和白盒测试两个角度出发有以下几种常用的可靠性模型。
● 黑 盒 方 面 的 可 靠 性 模 型 包 括 了 基 本 执 行 时 间 模 型 ( Musa )、 故 障 分 离 模 型(Jelinski-Moranda)、NHPP 模型及增强的 NHPP 模型(Goel-Okumoto)以及贝叶斯判定模型(Littlewood-Verrall)。
● 在白盒方面的可靠性模型包括了基于路径的模型(Krishna-Murthy 和 Mathur)和基于状态的模型(Gokhale,et al.)。
6.安装测试
理想情况下,一个软件的安装程序应当平滑地集成用户的新软件到已有的系统中去,就象一个客人被介绍到一个聚会中去一样,彼此交换适当的问候。一些对话窗口提供简单的、容易理解的安装选项和支持信息,并且完成安装过程。然而,在某些糟糕的情况下,安装程序可能会做错误的事
情,使新的程序无法工作,已有的功能受到影响,甚至安装过程严重损坏用户系统。
在安装软件系统时,会有多种选择:要分配和装入文件与程序库;布置适用的硬件配置;进行程序的联结。而安装测试就是要找出在这些安装过程中出现的错误,其目的是要验证成功安装系统的能力。它通常是开发人员的最后一个活动,并且通常在开发期间不太受关注。但是,它是客户使
用新系统时执行的第一个操作。因此,清晰并且简单的安装过程是系统文档中最重要的部分。
7.容量测试
容量测试是根据预先分析出反映软件系统应用特征的某项指标极限值(如最大并发用户数,最大数据库记录数等),测试系统在其极限值状态下是否能保持主要功能正常运行。例如:对于编译程序,让它处理特别长的源程序;对于操作系统,让它的作业队列“满员”;对于信息检索系统,让它使用频率达到最大。在使用系统的全部资源达到“满负荷”的情形下,测试系统的承受能力。容量测试的完成标准可以定义为:所计划的测试已全部执行,而且达到或超出指定的系统限制时没有出现任何软件故障。
8.文档测试
文档测试是检查用户文档(如用户手册)的清晰性和精确性。在用户文档中所使用的例子必须在测试中测试过,确保叙述正确无误。
2.8验收测试
验收测试是软件产品完成系统测试后,在发布之前所进行的软件测试活动,它是技术测试的最后一个阶段。通过验收测试,产品就会进入发布阶段。验收测试的目的是确保软件准备就绪,并且可以让最终用户将其用于执行软件的既定功能和任务。它是向未来的用户表明系统能够像预定要求
那样工作,应检查软件能否按合同要求进行工作,即是否满足软件需求说明书中的确认标准。
验收测试是以用户为主的测试。软件开发人员和 QA(质量保证)人员也应参加。由用户参加设计测试用例,使用用户界面输入测试数据,并分析测试的输出结果。一般使用生产中的实际数据进行测试。在测试过程中,除了考虑软件的功能和性能外,还应对软件的可移植性、兼容性、可维护
性、错误的恢复功能等进行确认。
验收测试同样需要制订测试计划和过程,测试计划应规定测试的种类和测试进度,测试过程则定义一些特殊的测试用例,旨在说明软件与需求是否一致。无论是计划还是过程,都应该着重考虑软件是否满足合同规定的所有功能和性能,文档资料是否完整、准确,人机界面和其他方面(例如,可移植性、兼容性、错误恢复能力和可维护性等)是否令用户满意。 验收测试的结果有两种可能,一种是功能和性能指标满足软件需求说明的要求,用户可以接受;另一种是软件不满足软件需求说明的要求,用户无法接受。项目进行到这个阶段才发现严重错误和偏差一般很难在预定的工期内改正,因此必须与用户协商,寻求一个妥善解决问题的方法,决定必须作很大修改还是在维护后期或下一个版本改进。
验收测试的另一个重要环节是配置复审。复审的目的在于保证软件配置齐全、分类有序,并且包括软件维护所必须的细节。
实施验收测试既可以是非正式的测试,也可以是有计划、有系统的测试。在软件交付使用之后,用户将如何实际使用程序,对于开发者来说是无法预测的。因为用户在使用过程中常常会发生对使用方法的误解、异常的数据组合、以及产生对某些用户来说似乎是清晰的但对另一些用户来说却难
以理解的输出等等。由于一个软件产品可能拥有众多用户,不可能由每个用户都进行验收,而且初期验收测试中大量的错误可能导致开发延期,甚至吓跑用户,因此多采用一种称为α、β测试的过程,以发现可能只有最终用户才能发现的错误。
α测试是软件开发公司组织内部人员模拟各类用户对即将面世的软件产品(称为α版本)进行测试。这是在受控制的环境下进行的测试。它的关键在于要尽可能逼真地模拟实际运行环境和用户对软件产品的操作,并尽最大努力涵盖所有可能的用户操作方式。α测试人员是除产品开发人员之
外首先见到产品的人,他们提出的功能和修改意见是特别有价值的。α测试可以从软件产品编码结束之时开始,或在模块(子系统)测试完成之后开始,也可以在确认测试过程中产品达到一定的稳定和可靠程度之后再开始。有关的手册(草稿)等应事先准备好。经过α测试调整的软件产品称为β版本。
β测试是由软件的多个用户在一个或多个用户的实际使用环境下进行的测试。与α测试不同的是,开发者通常不在测试现场。因而,β测试是在开发者无法控制的环境下进行的软件现场应用。
在β测试中,由用户记下遇到的所有问题,包括真实的以及主观认定的,定期向开发者报告,开发者在综合用户的报告之后,做出修改,最后将软件产品交付给全体用户使用。只有当α测试达到一定的可靠程度时,才能开始β测试。由于它处在整个测试的最后阶段,不能指望这时发现主要问题。
同时,产品的所有手册文本也应该在此阶段完全定稿。由于β测试的主要目标是测试可支持性,所以β测试应尽可能由主持产品发行的人员来管理。
2.9面向对象软件测试
传统软件开发采用面向过程、面向功能的方法,将程序系统模块化,也产生相应的单元测试、集成测试等方法。面向对象软件测试的整体目标和传统软件测试是一致的,即以最小的工作量发现尽可能多的错误。其动态测试过程也与传统软件一样,分为制定测试计划、产生测试用例、执行测
试和评价几个阶段。但面向对象的程序结构不再是传统的功能模块结构,类是构成面向对象程序的基本成分。在类定义中封装了数据(用于表示对象的状态)及作用在数据上的操作,数据和操作统称为特征。对象是类的实例,类和类之间按继承关系组成一个有向无圈图结构。父类中定义了共享的公共特征,子类除继承了父类中定义的所有特征外,还可以引入新的特征,也允许对继承的方法进行重定义。面向对象语言提供的动态绑定机制将对象与方法动态地联系起来,继承和动态绑定的结合使程序有较大的灵活性,当用户需求变动时,设计良好的面向对象程序变动相对较小。面向对象技术具有的信息隐蔽、封装、继承、多态和动态绑定等特性提高了软件开发的质量,但同时也给软件测试提出了新的问题,增加了面向对象软件测试的难度。
在面向对象的程序设计中,由于相同的语义结构,如类、属性、操作和消息,出现在分析、设计和代码阶段,因此,需要扩大测试的范围,重视面向对象分析和设计模式的复审。在分析阶段发现类属性定义中的问题,将可能减少和防止延伸到软件设计和软件编码阶段的错误,反之,若在分
析阶段及设计阶段仍未检测到问题,则问题可能会传送到程序的编码过程当中,并造成耗费大量的开发资源。同时,测试的结果会造成对系统进行相关的修改,而修改有可能带来新的、更多的潜在问题。面向对象的分析和面向对象的设计提供了关于系统的结构和行为的实质性信息,因此,在产生代码前必须进行严格的复审。
软件测试层次是基于测试复杂性分解的思想,是软件测试的一种基本模式。传统层次测试基于功能模块的层次结构,而在面向对象软件测试中,继承和组装关系刻画了类之间的内在层次,它们既是构造系统结构的基础,也是构造测试结构的基础。面向对象程序的执行实际上是执行一个由消息连接起来的方法序列,而这个方法序列通常是由外部事件驱动的。面向对象软件抛弃了传统的开发模式,对每个开发阶段都有不同以往的要求和结果,已经不可能用功能细化的观点来检测面向对象分析和设计的结果。对面向对象程序的测试应当分为多少级别尚未达成共识。由于面向对象软件从宏观上来看是各个类之间的相互作用,类是面向对象方法中最重要的概念,是构成面向对象程序的基本成分,也是进行面向对象程序测试的关键,因此大部分文献都将类作为最小的可测试单元,得到一种较为普遍的面向对象软件测试层次划分方法,将面向对象程序测试分为三级:类级、类簇级和系统级。根据测试层次结构,面向对象软件测试总体上也呈现从单元级、集成级到系统级的分层测试结构,测试集成的过程是基于可靠部件组装系统的过程。
2.9.1面向对象软件的单元测试
传统的单元测试的对象是软件设计的最小单位——模块。单元测试应对模块内所有重要的控制路径设计测试用例,以便发现模块内部的错误。单元测试多采用白盒测试技术,系统内多个模块可以并行地进行测试。
当考虑面向对象软件时,单元的概念发生了变化。封装驱动了类和对象的定义,这意味着每个类和类的实例(对象)包装了属性(数据)和操纵这些数据的操作。一个类可以包含一组不同的操作,而一个特定的操作也可能存在于一组不同的类中。因此,单元测试的意义发生了较大变化。我们不
再孤立地测试单个操作,而是将操作作为类的一部分。此时最小的可测试单位是封装的类或对象,而不再是个体的模块。
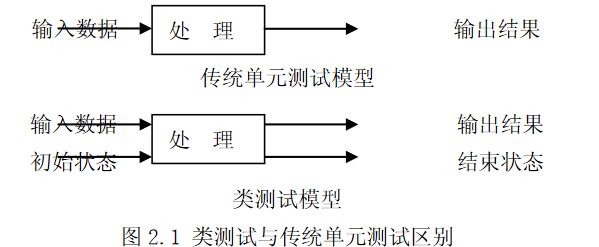
面向对象的单元测试通常也称为类测试。传统单元测试主要关注模块的算法实现和模块的接口间数据的传递,而00的类测试主要要考察封装在一个类中的方法和类的状态行为。进行类测试时要把对象与其状态结合起来,进行对象状态行为的测试,因为工作过程中对象的状态可能被改变,产生新的状态。而对象状态的正确与否取决于该对象自创建以来接收到的消息序列,以及该对象对这些消息序列所作的响应。一个设计良好的类应能对正确的消息序列作出正确的反应,并具有抵御错误序列的能力。因而类测试应着重考察类的对象对消息序列的响应和对象状态的正确性。它与传统单元测试的区别如图 2.1:
2.9.2 面向对象软件的集成测试
面向对象的集成测试即类簇测试。类簇是指一组相互有影响,联系比较紧密的类。它是一个相对独立的实体,在整体上是可执行和可测试的,并且实现了一个内聚的责任集合,但不提供被测试程序的全部功能,相当于一个子系统。类簇测试主要根据系统中相关类的层次关系,检查类之间的
相互作用的正确性, 即检查各相关类之间消息连接的合法性、子类的继承性与父类的一致性、动态绑定执行的正确性、类簇协同完成系统功能的正确性等等。面向对象软件没有层次的控制结构,因此传统的自下而上或自上而下的集成测试策略并不适用于面向对象方法构造的软件,需要研究适合面向对象特征的新的集成测试策略。其测试有两种不同策略:
(1)基于类间协作关系的横向测试。由系统的一个输入事件作为激励,对其触发的一组类进行执行相应的操作/消息处理路径,最后终止于某一输出事件。应用回归测试对已测试过的类集再重新执行一次,以保证加入新类时不会产生意外的结果。
(2)基于类间继承关系的纵向测试。首先通过测试不使用或很少使用其他类服务的类,即独立类(是系统中已经测试正确的某类)来开始构造系统。在独立类测试完成后,下一层继承独立类的类(称为依赖类)被测试,这个依赖类层次的测试序列一直循环执行到构造完整个系统。
面向对象的集成测试能够检测出相对独立的单元测试无法检测出的那些类相互作用时才会产生的错误。基于单元测试对成员函数行为正确性的保证,集成测试只关注系统的结构和内部的相互作用。
2.9.3面向对象软件的系统测试
通过单元测试和集成测试,仅能保证软件开发的功能得以实现。但不能确认在实际运行时,他是否满足用户的需要。为此,对完成开发的软件必须经过规范的系统测试。系统测试是对所有程序和外部成员构成的整个系统进行整体测试,检验软件和其他系统成员配合工作是否正确,另外,还包括了确认测试内容,以验证软件系统的正确性和性能指标等是否满足需求规格说明书所制定的要求。它一般不考虑内部结构和中间结果,因此与传统的系统测试差别不大,可沿用传统的系统测试方法。
系统测试应该尽量搭建与用户实际使用环境相同的测试平台,应该保证被测系统的完整性,对临时没有的系统设备部件,也应有相应的模拟手段。系统测试时,应该参考 OOA 分析的结果,对应描述的对象、属性和各种服务,检测软件是否能够完全“再现”问题空间。系统测试不仅是检测软
件的整体行为表现,从另一个侧面看,也是对软件开发设计的再确认。

第3章 黑盒测试
3.1黑盒测试法概述
黑盒测试又称为功能测试或数据驱动测试,着眼于程序外部结构,将被测试程序视为一个不能打开的黑盒子,完全不考虑程序内部逻辑结构和内部特性,主要针对软件界面、软件功能、外部数据库访问以及软件初始化等方面进行测试。因此黑盒测试的目的主要是在已知软件产品应具有的功
能的基础上,发现以下类型的错误:
(1)检查程序功能是否按照需求规格说明书的规定正常使用,测试每个功能是否有遗漏,检测性能等特性要求是否满足要求。
(2)检测人机交互是否错误,检测数据结构或外部数据库访问是否错误,程序是否能够适当地接收数据而产生正确的输出结果,并保持外部信息(如数据库或文件)的完整性。
(3)检测程序初始化和终止方面的错误。
黑盒测试属于穷举输入测试方法,只有将所有可能的输入都作为测试情况来使用,才能检查出程序中所有的错误。但穷举测试是不现实的,因此我们需要选择合适的方法使设计出来的测试用例具有完整性、代表性,并能有效地发现软件缺陷。
盒测试常用的方法和技术主要包括边界值分析法、等价类划分法、决策表法、错误推测法、功能图法等。掌握和运用这些方法并不十分困难,但每种方法都有其所长,需要对被测软件的具体特点进行分析,选择合适的测试方法,才能有效解决软件测试中的问题。
3.2边界值测试
3.2.1. 边界值分析法
边界值分析法(BVA,Boundary Value Analysis )是一种很实用的黑盒测试用例设计方法,它具有很强的发现程序错误的能力。无数的测试实践表明,大量的故障往往发生在输入定义区域或输出值域的边界上,而不是在其内部,如做一个除法运算的例子,如果测试者忽略被除数为 0 的情况就会导致问题的遗漏。所以在设计测试用例时,一定要对边界附近的处理十分重视。为检验边界附近的处理专门设计测试用例,通常都会取得很好的效果。
应用边界值分析的基本思想是:选取正好等于、刚刚大于和刚刚小于边界值的数据作为测试数据。边界值分析法是最有效的黑盒分析法,但在边界情况复杂的情况下,要找出适当的边界测试用例还需要针对问题的输入域、输出域边界,耐心细致地逐个进行考察。
1.边界值分析
边界值分析关注的是输入、输出空间的边界条件,以标识测试用例。实践证明,程序在处理大量中间数值时都正确,但在边界处却往往可能出现错误。例如,循环条件漏写了等于,计数器少计了一次或多计了一次,数组下标忽略了 0 的处理等等,这些都是我们平时编程容易疏忽而导致出错
的地方。
刚开始时,可能意识不到一组给定数据包含了多少边界,但是仔细分析总可以找到一些不明显的、有趣的或可能产生软件故障的边界。实际上,边界条件就是软件操作界限所在的边缘条件。
一些可能与边界有关的数据类型有:数值、速度、字符、位置、尺寸、数量等。同时,针对这些数据类型可以考虑它们的下述特征:第一个/最后一个,最小值/最大值,开始/完成,超过/在内,空/满,最短/最长,最慢/最快,最早/最迟,最高/最低,相邻/最远等。
以上是一些可能出现的边界条件。实际应用中,每一个软件测试问题都不完全相同,可能包含各式各样的边界条件,应视具体情况而定
2.内部边界值分析
上面边界值分析中所讨论的边界条件比较容易发现,它们在软件规格说明中或者有定义,或者可以在使用软件的过程中确定。而有些边界却是在软件内部,用户几乎看不到,但我们在进行软件测试时仍有必要对它们进行检查,这样的边界条件称为内部边界条件或次边界条件。
寻找内部边界条件比较困难,虽然不要求软件测试人员成为程序员或者具有阅读源代码的能力,但要求软件测试人员能大体了解软件的工作方式。例如对文本输入或文本转换软件进行测试,在考虑数据区间包含哪些值时,最好参考一下 ASCII 表。如果测试的文本输入框只接受用户输入字符
A——Z 和 a——z,就应该在非法区间中,检查 ASCII 表中刚好位于 A 和 a 前面,Z 和 z 后面的值——@ ,[ ,‘ 和 { 。
3.2.2边界值分析法测试用例
边界值分析测试的基本思想
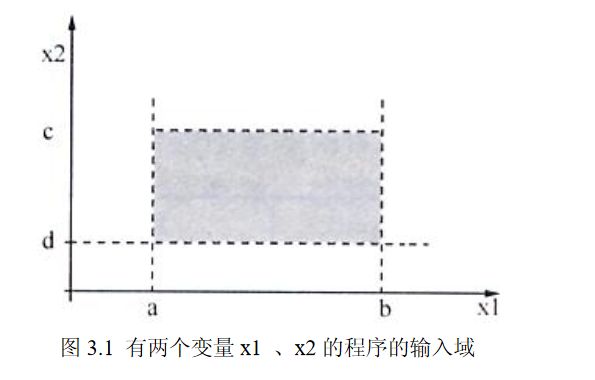
为便于理解,假设有两个变量 x1 和 x2 的函数 F,其中函数 F 实现为一个程序,x1、x2 在下列范围内取值:a≤x1≤bc≤x2≤d
区间[a,b]和[c,d]是 x1、x2 的值域,程序 F 的输入定义域如下图所示,即带阴影矩形中的任何点都是程序 F 的有效输入。
采用边界值分析测试的基本原理是:故障往往出现在输入变量的边界值附近。例如,当一个循环条件为“≤”时,却错写成“<”,计时器发生少计数一次。
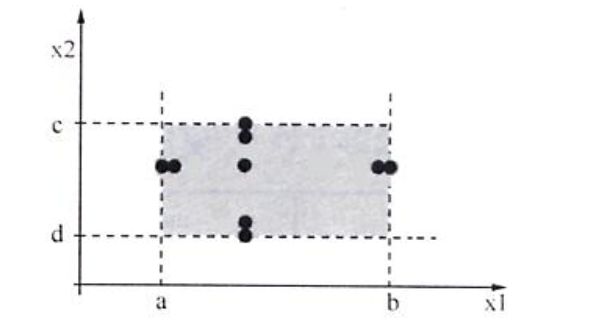
边界值分析测试的基本思想是使用在最小值(min)、略高于最小值(min+)、正常值(nom)、略低于最大值(max-)和最大值(max)处取输入变量值。同时,对于有多个输入变量的情况我们通常是基于可靠性理论中称为“单故障”的假设,这种假设认为有两个或两个以上故障同时出现而导致软件失效的情况很少,也就是说,软件失效基本上是由单故障引起的。因此,边界值分析测试用例的获得,是通过使一个变量取极值,剩下所有变量取正常值。前面有两个输入变量的程序 F 的边界值析测试用例(如图 3.2 所示 )是
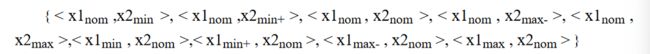
对于一个含有 n 个变量的程序,保留其中一个变量,让其余的变量取正常值,被保留的变量依次取 min、 min+、nom、max-、max 值,对每个变量都重复进行。这样,对于一个有 n 个变量的程序,边界值分析测试程序会产生 4n+1 个测试用例。如果没有显式的给出边界,如三角形问题,则必须创建一种人工边界,可以先设定下限值(边长应大于等于 1),并规定上限值,如 100,或取默认的最大可表示的整数值。
2.健壮性测试
健壮性测试是边界分析测试的一种简单扩展,除了取 5 个边界值分析取值外,还需要考虑采用
一个略超过最大值(max+)以及略小于最小值(min-)的取值,检查超过极限值时系统的表现会是
什么。健壮性测试最有意义的部分不是输入,而是预期的输出。它要观察例外情况如何处理,比如
某个部分的负载能力超过其最大值可能出现的情形。健壮性测试如图 3.3 所示。
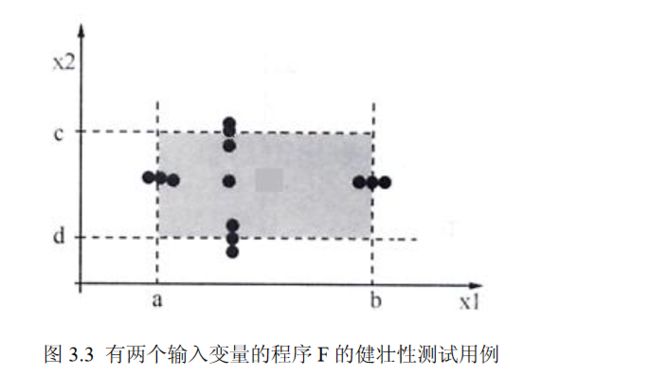
3.2.3 边界值分析法测试实例
1.三角形问题
问题描述:
简单版本:三角形问题接受三个整数a\b\c作为输入,用作三角形的边。程序的输出是由这三条边确定的三角形类型:等边三角形、等腰三角形、不等边三角形或非三角形。
通过提供更多细节可以改进这个定义。于是这个问题变成以下的形式。
改进版本:三角形问题接受三个整数a,b和c作为输入,用作三角形的边。整数a,b和c必须满足以下条件:
c1.1≤a≤100 c4.a 程序的输出是由这三条边确定的三角形类型:等边三角形、等腰三角形、不等边三角形或非三角形。如果输入值没有满足 c1、c2 和 c3 这些条件中的任何一个,则程序会通过输出消息来进行通知,例如,“b 的取值不在允许取值的范围内。”如果 a、b 和 c 取值满足 c1、c2 和 c3,则给出以下四种相互排斥输出中的一个: (1)如果三条边相等,则程序的输出是等边三角形。 在三角形问题描述中,除了要求边长是整数外,没有给出其它的限制条件。边界下限为 1,上限为 100。表 3.1 给出了边界值分析测试用例. 三角形问题的边界值分析测试用例 2.NextDate函数 问题描述:NextDate是一个有三个变量(月份、日期和年)的函数。函数返回输入日期后面的那个日期。变量月份、日期和年都具有整数值,且满足以下条件: c1. 1<=月份<=12 c2. 1<=日期<=31 c3. 1912<=年<=2050 在 NextDate 函数中,规定了变量 month、day、year 相应的取值范围,即 1 ≤ month ≤ 12,1 ≤day ≤31,1912 ≤ year ≤ 2050,表 3.2 给出了其健壮性测试用例。 如果被测程序十多个独立变量的函数,这些变量受物理量的限制,则很适合采用边界值分析。这里的关键是“独立”和“物理量”。 简单地看一下表 3.2 中 NextDate 函数的边界分析测试用例,就会发现其实这些测试用例是不充分的。例如,没强调 2 月和闰年。这里的真正问题是,月份、日期和年变量之间存在依赖关系,而边界值分析假设变量是完全独立的。不过即便如此,边界值分析也能够捕获月末和年末缺陷。边界值分析测试用例通过引用物理量的边界独立导出变量极值,不考虑函数的性质,也不考虑变量的语义含义。因此我们把边界值分析测试用例看作是初步的,这些测试用例的获得基本没有利用理解和想象。 物理量准则也很重要。如果变量引用某个物理量,例如温度、压力、空气速度、负载等,则物理边界极为重要。举一个这方面的例子:菲尼克斯的航空港国际机场 1992 年 6 月 26 日被迫关闭,原因是当天的空气温度达到 122 °F导致飞行员在起飞之前不能设置某一特定设备,因为该设备能够接受的最大空气温度是 120 °F。 使用等价类作为功能性能测试的基础有两个动机:我们希望进行完备的测试,同时又希望避免冗余。边界值测试不能实现这两种希望中的任意一个:研究那些测试用例表,很容易看出存在大量冗余,再进一步仔细研究,还会发现严重漏洞。等价类测试重复边界值测试的两个决定因素:健壮性和单/多缺陷假设。本节我们给出了 4 种形式的等价类测试,在弱/强等价类测试之分的基础之上针对是否进行无效数据的处理产生健壮与一般等价类测试之分。 等价类的重要特征是对它们构成集合的一个划分,其中,划分是指互不相交的一组子集,并且这些子集的并是整个集合。这对于测试有两点非常重要的意义:表示整个集合这个事实提供了一种形式的完备性,而互不相交可保证一种形式的无冗余性。由于子集是由等价关系决定的,因此子集的元素都有一些共同点。等价类测试思想是通过每个等价类中的一个元素标识测试用例。如果广泛选择等价类,则可以大大降低测试用例之间的冗余。例如,在三角形问题中,我们当然要有一个等边三角形的测试用例,我们可能选择三元组(10,10,10)作为测试用例的输入。如果这样做了,则可以预期不会从诸如(3,3,3)和(100,100,100)这样的测试用例中得到多少新东西。直觉告诉我们,这些测试用例会以与第一个测试用例一样的方式进行“相同处理”,因此,这些测试用例是冗余。当我们在考虑结构性测试时,将会看到“相同处理”映射到“遍历相同的执行路径。” 等价类测试的关键就是选择确定类的等价关系。通常我们通过预测可能的实现,考虑在现实中必须提供的功能操作来做出这种选择。我们将用一系列例子说明这一点,但是首先必须区分弱和强等价类测试。 为了便于理解,我们还是讨论与有两个变量 x1 和 x2 的函数 F 联系起来。如果 F 实现为一个程序,则输入变量 x1 和 x2 将拥有以下边界,以及边界内的区间: 其中方括号和圆括号分别表示闭区间和开区间的端点。x1和x2的无效值是:x1 1.弱一般等价类测试 弱一般等价类测试通过使用测试用例的每个等价类(区间)的一个变量实现(单缺陷假设的作用)。对于上面给出的例子,可得到如图3.4所示的弱等价类测试用例 这三个测试用例使用每个等价类中的一个值。事实上,永远都有等量的弱等价类测试用例,因为划分中的类对应最大子集数。 2.强一般等价类测试 强一般等价类测试基于多缺陷假设,它需要等价类笛卡儿积的每个元素对应的测试用例(如图 3.5所示)。笛卡儿积可保证两种意义上的“完备性”:一是覆盖所有的等价类,二是覆盖所有可能的输入组合中的每一个。 “好的”等价类测试的关键是等价关系的选择,要注意被“相同处理”的输入。在大多数情况下,等价类测试定义输入定义域的等价类。不过,其实也没有理由不能根据被测程序函数的输出值域定义等价关系。事实上,这对于三角形问题是最简单的方法。 3.弱健壮等价类测试 这种测试的名称显然与直觉矛盾,怎么能够既弱又健壮呢?其实这是因为它是基于两个不同的角度而命名的。说它弱是因为它基于单缺陷假设,说它健壮是因为这种测试考虑了无效值。(测试用例如图 3.6 所示) (1)对于有效输入,弱健壮等价类测试使用每个有效类的一个值,就像我们在弱一般等价类测试中所做的一样。请注意,这些测试用例中的所有输入都是有效的。 (2)对于无效输入,弱健壮等价类测试的测试用例将拥有一个无效值,并保持其余的值都是有效的。此时,“单缺陷”会造成测试用例失败。 对于健壮等价类测试通常有两个问题。第一是:规格说明常常并没有定义无效测试用例所预期的输出是什么。因此,测试人员需要花大量时间定义这些测试用例的输出。第二是:强类型语言没有必要考虑无效输入。 4.强健壮等价类测试 强健壮等价类测试,“强”是指该类测试用例的获得是基于多缺陷假设,“健壮”则和前面的定义一样,是指考虑了无效值。如图 3.7 所示,强健壮等价类测试从所有等价类笛卡尔积的每个元素中获得测试用例。 1.三角形问题 在描述问题时,我们曾经提到有四种可能出现的输出:非三角形、不等边三角形、等腰三角形 R1={ 四个弱一般等价类测试用例是: 由于变量 a、b 和 c 没有有效区间划分,则强一般等价类测试用例与弱一般等价类测试用例相同。 考虑 a、b 和 c 的无效值产生的以下额外弱健壮等价类测试用例 以下是额外强健壮等价类测试用例三维立方的一个“角”: 请注意,预期输出如何完备地描述无效输入值。 等价类测试显然对于用来定义的等价关系很敏感。如果在输入定义域上定义等价类,则可以得到更丰富的测试用例集合。三个整数 a、b 和 c 有些什么可能的取值呢?这些整数相等(有三种相等方式),或都不相等。 D1={ 作为一个单独的问题,我们可以通过三角形的性质来判断三条边是否构成一个三角形(例如,三元组<1,4,1>有一对相等的边,但是这些边不构成一个三角形) D6={ D7={ 如果我们要彻底一些,可以将“小于或等于”分解为两种不同的情况,这样 D6 就变成: D6′={ 同样对于 D7 和 D8 也有类似的情况。 2.NextDate函数 NextDate 函数可以很好地说明选择内部等价关系的工艺。前面已经介绍过,NextDate 是一个三变量函数,即月份、日期和年,这些变量的有效值区间定义如下: M1={月份:1≤月份≤12} 无效等价类是: M2={月份:月份<1} 由于每个独立变量的有效区间均为 1 个,因此只有弱一般等价类测试用例出现,并且与强一般等价类测试用例相同: 以下是弱健壮测试用例的完整集合: 与三角形问题一样,以下是额外强健壮性等价类测试用例三维立方的一个“角”: 划分等价关系的重点是等价类中的元素要被“同样处理”。上述方法所得测试用例集其实是不足的,因为它只注意到在单个变量处理的有效/无效层次上进行,而没有进一步分析具体处理的过程与特征。对该函数如果更仔细地选择等价关系,所得到的等价类和测试用例集将会更有用。 例如在 NextDate 函数中,注意到必须对输入日期做怎样的处理?如果它不是某个月的最后一天,则 NextDate 函数会直接对日期加 1。到了月末,下一个日期是 1,月份加 1。到了年末,日期和月份会复位到 1,年加 1。最后,闰年问题要确定有关的月份的最后一天。经过这些分析之后,可以假设 M1={月份:每月有 30 天} 通过选择有 30 天的月份和有 31 天的月份的独立类,可以简化月份最后一天问题。通过把 2 月分成独立的类,可以对闰年问题给予更多关注。我们还要特别关注日期的值:D1 中的日(差不多)总是加 1,D4 中的日只对 M2 中的月才有意义。最后,年有三个类,包括 2000 年这个特例、闰年和非闰年类。这并不是完美的等价类集合,但是通过这种等价类集合可以发现很多潜在错误。 这些类产生以下弱等价类测试用例。与前面一样,机械地从对应类的取值范围中选择输入: 机械选择输入值不考虑领域知识,因此没有考虑两种不可能出现的日期。“自动”测试用例生成永远都会有这种问题,因为领域知识不是通过等价类选择获得的。 经过改进的强一般等价类测试用例是: 从弱一般测试转向强一般测试会产生一些边界值测试中也出现的冗余问题。从弱到强的转换,不管是一般类还是健壮类,都是以等价类的叉积表示。三个月份类乘以4个日期类乘以三个年类,产生3个枪一般等价类测试用例。对每个变量加上2个无效类,得到 150 个强健壮等价类测试用例。 通过更仔细地研究年类,还可以精简测试用例集合。通过合并 Y1 和 Y3,把结果称做平年,则36 个测试用例就会降低到 24 个。这种变化不再特别关注 2000 年,并会增加判断闰年的难度。需要在难度和能够从当前用例中了解到的内容之间做平衡综合考虑。 3. 佣金问题 问题描述:前亚利桑那州境内的一位步枪销售商销售密苏里州制造商制造的步枪机(lock)、枪 输入变量对应的有效类是: 输入变量对应的无效类是: L2={枪机:枪机=0 或枪机<-1} B3={枪管:枪管>90} 其中变量枪机还用做指示不再有电报的标记。当枪机等于-1 时,While 循环就会终止,总枪机、总枪托和枪管的值就会被用来计算销售额,进而计算佣金,因此对于变量枪机增加了第 2 个有效类L2。 根据上述等价类的划分,可得如下所示佣金问题的弱一般等价类测试用例,这个测试用例同样也等于强一般等价类测试用例。 七个弱健壮测试用例如下。 最后,额外强健壮等价类测试用例三维立方的一个“角”是: 请注意,对于强测试用例,不管是强一般测试用例还是强健壮测试用例,都只有一个是合理输入。如果确实担心错误案例,那么这就是很好的测试用例集合。但是这样很难确信佣金问题的计算部分没有问题。在本例中,我们可以通过对输出值域定义等价类来进一步完善测试。前面提到过, 销售额=45枪机+30枪托+25*枪管 我们可以根据销售额值域定义三个等价类: S1={<枪机,枪托,枪管>:销售额≤1000} 由此得到如下的输出值域等价类测试用例: 这些测试用例让人感觉到正在接触问题的重要部分。与弱健壮测试用例结合在一起,就可得到佣金问题的相当不错的测试。另外,可能还希望增加一些边界检查,只是为了保证从1000美元到1800美元的转移是正确的。 我们已经介绍了三个例子,最后讨论关于等价类测试的一些观察和等价类测试指导方针。 1. 显然,等价类测试的弱形式(一般或健壮)不如对应的强形式的测试全面。 2. 如果实现语言的强类型(无效值会引起运行时错误),则没有必要使用健壮形式的测试。 3. 如果错误条件非常重要,则进行健壮形式的测试是合适的。 4. 如果输入数据以离散值区间和集合定义,则等价类测试是合适的。当然也适用于如果变量值越界就会出现故障的系统。 5. 通过结合边界值测试,等价类测试可得到加强。(我们可以“重用”定义等价类的工作成果。) 在所有的功能性测试方法中,基于决策表的测试方法是最严格的,因为决策表具有逻辑严格性。 决策表 自从 20 世纪 60 年代初以来,决策表一直被用来表示和分析复杂逻辑关系。决策表很适合描述不同条件集合下采取行动的若干组合的情况。表 3.3 给出了基本决策表术语。 决策表有四个部分:粗竖线左侧是桩部分;右侧是条目不分。横粗线的上面是条件部分,下面是行动部分。因此,我们可以引用条件桩、条件条目、行动桩和行动条目。条目部分中的一列是一条规则。规则只是在规则的条件部分中指示的条件环境下要采取什么行动。在表 3.3 给出的决策表 如果有二叉条件(真/假,是/否,0/1 ),则决策表的条件部分是旋转了 90 度的(命题逻辑)真值表。这种结构能够保证我们考虑了所有可能的条件的组合。如果使用决策表标识测试用例,那么决策表的这种完备性质能够保证一种完备的测试。所有条件都是二叉条件的决策表叫做有限条目决策表。如果条件可以有多个值,则对应的决策表叫做扩展条目决策表。 决策表被设计为说明性的,给出的条件没有特别的顺序,而且所选择的行动发生时也没有任何特定顺序。 1.表示方法 为了使用决策表标识测试用例,我们把条件解释为输入,把行动解释为输出。有时条件最终引用输入的等价类,行动引用被测软件的主要功能处理部分。这时规则就解释为测试用例。由于决策表可以机械地强制为完的,因此可以有测试用例的完整集合。 产生决策表的方法可以有多种。 在表 3.4 所示的决策表中,给出了不关心条目和不可能规则使用的例子。正如第一条规则所指示,如果整数 a、b 和 c 不构成三角形,则我们根本不关心可能的相等关系。在规则 3、4 和 6 中,如果两对整数相等,则根据传递性,第三对整数也一定相等,因此这些规则不可能满足。 表 3.5 所示的决策表给出了有关表示方法的另一种考虑:条件的选择可以大大地扩展决策表的规模。这里将老条件(c1:a、b、c 构成三角形?)扩展为三角形特性的三个不等式的详细表示。如果有一个不等式不成立,则三个整数就不能构成三角形。我们还可以进一步扩展,因为不等式不成 如果条件引用了等价类,则决策表会有一种典型的外观。如表 3.6 所示的决策表来自 NextDate问题,引用了可能的月份变量相互排斥的可能性。由于一个月份就是一个等价类,因此不可能有两个条目同时为真的规则。不关心条目(-)的实际含义是“必须失败”。有些决策表使用者用 F 表示这一点。 不关心条目的使用,对完整决策表的识别方式有微妙的影响。对于有限的条目决策表,如果有n 个条件,则必须有 2^n 条规则。如果不关心条目实际地表明条件是不相关的,则可以按以下方法统计规则数:没有不关心条目的规则统计为 1 条规则;规则中每出现一个不关心条目,该规则数乘一次 2。表 3.5 所示决策表的规则条目数统计如表 3.7 所示。请注意,规则总数是 64(正好是应该得到的规则条数)。 如果将这种简化算法应用于表 3.6 所示的决策表,会得到如表 3.8 所示的规则条数统计。 应该只有八条规则,所以显然有问题。为了找出问题所在,我们扩展所有三条规则,用可能的T 或 F 替代“-”,如图 3.9 所示。 请注意,所有条目都是 T 的规则有三条:规则 1.1、2.1、和 3.1;条目是 T、T、F 的规则有两条:规则 1.2 和 2.2。类似地,规则 1.3 和 3.2、2.3 和 3.3 也是一样的。如果去掉这种重复,最后可得到七条规则,缺少的规则是所有条件都是假的规则。这种处理的结果如表 3.10 所示,表中还给出了不可能出现的规则。 这种识别完备决策表的能力,使我们在解决冗余性和不一致性方面处于很有利的地位,表 3.11给出的决策表是冗余的,因为有三个条件则应该是 23=8 条规则,此处却有九条规则。(规则 9 和规则 1~4 中某一条相同,是冗余规则。) 注意规则 9 的行为条目与规则 1~4 的条目相同。只要冗余规则中的行为与决策表相同的部分相同,就不会有什么大问题。如果行为条目不同,例如表 3.12 所示的情况,则会遇到比较大的问题。 如表 3.12 所示的决策表被用来处理事务,其中 c1 是真,c2 和 c3 都是假,则规则 4 和规则 9都适用。我们可以观察到两点: (1)规则 4 和规则 9 是不一致的。因为它们的行为集合是不同的。 因此测试人员在应用决策表技术时要小心使用不关心条目。 2.决策表的应用 决策表最为突出的优点是,能够将复杂的问题按照各种可能的情况全部列举出来,简明并避免遗漏。因此,利用决策表能够设计出完整的测试用例集合。运用决策表设计测试用例,可以将条件理解为输入,将动作理解为输出。 (1)三角形问题的测试用例 用表 3.5 所示的决策表,可得到 11 个功能性测试用例:3 个不可能测试用例,3 个测试用例违反三角形性质,1 个测试用例可得到等边三角形,1 个测试用例可得到不等边三角形,3 个测试用例可得到等腰三角形(如表 3.13 所示)如果扩展决策表以显示两种违反三角形性质的方式,可以再 (2)NextDate 函数测试用例 NextDate 函数可以说明定义域中的依赖性问题,决策表可以突出这种依赖关系,因此使得它成为基于决策表测试的一个完美例子。前面介绍过 NextDate 函数的等价类划分。等价类划分的不足之处是机械地选取输入值,可能会产生“奇怪”的测试用例,如找 2003 年 4 月 31 日的下一天。问题产生的根源是等价类划分和边界值分析测试都假设了变量是独立的。若变量之间在输入定义域中存在某种逻辑依赖关系,则这些依赖关系在机械地选取输入值时就可能会丢失。决策表方法通过使用“不可能动作”的概念表示条件的不可能组合,使我们能够强调这种依赖关系。 为了产生给定日期的下一个日期,NextDate 函数能够使用的操作只有 5 种:day 变量和 month变量的加 1 和复位操作,year 变量的加 1 操作。 在以下等价类集合上建立决策表: M1: { month: month 有 30 天 } M2: { month: month 有 31 天,12 月除外 } M3: { month: month 是 12 月 } 如表 3.14 所示是决策表,共有 22 条规则。 规则 1~5 处理有 30 天的月份,其中不可能规则也列出,如规则 5 处理在有 30 天的月份中考虑31 日;规则 6~10 和规则 11~15 处理有 31 天的月份,其中规则 6~10 处理 12 月之外的月份,规则 11~15处理 12 月;最后的 7 条规则关注 2 月和闰年问题。 规则 1、2、3 都涉及有 30 天的月份 day 类 D1、D2 和 D3,并且它们的动作项都是 day 加 1,因此可以将规则 1、2、3 合并。类似地,有 31 天的月份的 day 类D1、D2、D3 和 D4 也可合并,2 月的 D4 和 D5 也可合并。简化后的决策表如表 3.15 所示。 根据简化后的决策表 3.15,可设计测试用例,如表 3.16 所示。 3. 决策表测试适用范围 每种测试方法都有适用的范围。基于决策表的测试可能对于某些应用程序,如 NextDate 函数十分有效,但是对于另一些应用程序(如佣金问题)就不是很有效。基于决策表测试通常适用于要产生大量决策的情况,如三角形问题,或在输入变量之间存在重要的逻辑关系的情况,如 NextDate 函数。 一般来说,决策表测试法适用于具有以下特征的应用程序: 错误猜测大多基于经验,需要从边界值分析等其它技术获得帮助。这种技术猜测特定软件类型可能发生的错误类型,并且设计测试用例查出这些错误。对有经验的工程师来说,错误猜测有时是最有效的发现 bug 的测试设计方法。为了更好地利用现成的经验,可以列出一个错误类型的检查表,帮助猜测错误可能发生在程序中的位置,提高错误猜测的有效性。 白盒测试也称结构测试或逻辑驱动测试,是针对被测单元内部是如何进行工作的测试,它的突出特点是基于被测程序的源代码,而不是软件的规格说明。在软件测试中,白盒测试一般是由程序员完成的,包括其结构、个组成部分之间的关联,以及其内部的运行原理、逻辑,等等。白盒测试人员实际上是程序员和测试员的结合体。 白盒测试的主要方法有程序结构分析、逻辑覆盖、基本路径测试等,它根据程序的控制结构设计导出测试用例,主要用于软件程序的验证。白盒测试法全面了解程序内部的逻辑结构,对所有的逻辑路径进行测试,是一种穷举路径的测试方法。在使用这种方法时,测试者必须检查程序的内部结构,从检查程序的逻辑着手,得出测试数据。 采用白盒测试方法必须遵循以下几条原则,才能达到测试的目的: (1)保证一个模块中的所有独立路径至少被测试一次。 为了清晰描述白盒测试方法。需要首先对有关白盒测试的几个基本概念进行说明,即流图、环形复杂度和图矩阵。 1. 流图 在程序设计时,为了更加突出控制流的结构,可对程序流程图进行简化,简化后的图称为控制流图。 经简化后产生的控制流图中所涉及的图形符号只有两种,即节点和控制流线。 包含条件的节点被称为判定节点( 也叫谓词节点 ),由判定节点发出的边必须终止于某一个相同节点,由边和节点所限定的范围被称为区域。 对于复合条件,则可将其分解为多个单个条件,并映射成控制流图,图 4.3 所示。 2.环形复杂度 环形复杂度也称为圈复杂度,概括地讲,它就是一种为程序逻辑复杂度提供定量尺度的软件度量。可以将该度量用于基本路径方法,它可以提供程序基本集的独立路径数量和确保所有语句至少执行一次的测试数量上界。其中,独立路径是指程序中至少引入一个新的处理语句集合或一个新条 显而易见,程序中含有的路径数和程序的复杂性有着密切的关系,也就是说程序越复杂,它的路径数就越多。但程序复杂性如何度量呢?McCabe 给出了程序结构复杂性的计算公式。 其中,e 为图 G 中的边数,n 为图 G 中的结点数,并且 McCabe 认为,强连通图的复杂度 V(G)就是图中线性独立环路的数量。 通过从汇结点到源结点添加一条边,便可创建控制流图的强连接有向图。 图 4.4 是一个经过了这种处理后的强连接有向图。其复杂度是: V(G)=e-n+l=11-7+1=5 图 4.4 中的强连接图的复杂度是 5,因此图 4.4 中有 5 个线性独立环路。如果现在删除从结点 G到结点 A 所添加的边,则这 5 个环路就成为从结点 A 到结点 G 的线性独立路径:以下给出用结点序列表示的 5 条线性独立路径: pl=A,B,C,G p5=A,D,F,G 独立路径是指从程序入口到出口的多次执行中,每次至少有一个语句(包括运算、赋值、输入、输出或判断)是新的,未被重复的。如果用前面提到的控制流图来描述,独立路径就是在从入口进入控制流图后,至少要经历一条从未走过的弧。 因此,路径 p6=A、B、C、B、E、F、G,p7=A、B、C、B、C、B、C、G 不是独立路径。因为 p6 可以由路径 pl、p2 和 p3 组合而成,p7 可由路径 pl 和 p2 组合而成。 很明显,从测试角度来看,如果某一程序的每一条独立路径都测试过了,那么可以认为程序中的每个语句都已检验过了。但在实际测试中,要真正构造出程序的每条独立路径,并不是一件轻松的事。 测试可被设计为基本路径集的执行过程。需要注意的是,基本路径集通常并不唯一。 3.图矩阵 图矩阵即流图的邻接矩阵表示形式,其阶数等于流图的节点数。矩阵中的每列和每行都对应于标识的某一节点,矩阵元素对应于节点之间的边。如图 4.5 和图 4.6 所示,描述了一个简单的流图及其对应的矩阵。 通常,流图中的节点用数字标识,边则用字母标识。在如图 4.5 所示的例子当中,若矩阵记为M ,则 M(4,1)= “d”,表示边 d 连接节点 4 和 节点 1 。需要注意的是,边 d 是有方向的,它从节点 4 到节点 1。 有选择地执行程序中某些最有代表性的通路是对穷尽测试的唯一可行的替代办法。所谓逻辑覆盖是对一系列测试过程的总称,这组测试过程逐渐进行越来越完整的通路测试。测试数据执行(或叫覆盖)程序逻辑的程度可以划分成哪些不同的等级呢?从覆盖源程序语句的详尽程度分析,大致 1.语句覆盖 为了暴露程序中的错误,至少每个语句应该执行一次。语句覆盖的含义是,选择足够多的测试数据,使被测程序中每个语句至少执行一次。例如,图 4.7 所示的程序流程图描绘了一个被测试模块的处理算法。 为了使每个语句都执行一次,程序的执行路径应该是 sacbed ,为此只需要输入下面的测试数据(实际上 X 可以是任意实数): 语句覆盖对程序的逻辑覆盖很少,在上面例子中两个判定条件都只测试了条件为真的情况,如果条件为假时处理有错误,显然不能发现。此外,语句覆盖只关心整个判定表达式的值,而没有分别测试判定表达式中每个条件取值不同时的情况。在上面的例子中,为了执行 sacbed 路径,以测 试每个语句,只需两个判定表达式( A > 1)AND ( b = 0 ) 和 ( A = 2 ) OR ( X > 1 )都取真值,因此使用上述一组测试数据就够了。但是,如果程序中不把第一个判定表达式中的逻辑运算符“AND”错写成“OR”,或者把第二个判定表达式中的条件“X>1”误写成“X<1”,使用上面的测试数据并不能查出这些错误。 综上所述,可以看出语句覆盖是很弱的逻辑覆盖标准,为了更充分地测试程序,可以采用以下所述的逻辑覆盖标准。 2.判定覆盖 判定覆盖又叫分支覆盖,它的含义是,不仅每个语句必须至少执行一次,而且每个判定表达式的每种可能的结果都应该至少执行一次,也就是每个判定的每个分支都至少执行一次。 对于上述例子来说,能够分别覆盖路径 sacbed 和 sabd 的两组测试数据,或者可以分别覆盖路径 sacbd 和 sabed 的两组测试数据,都满足判定覆盖标准。例如,用下面两组测试数据就可做到判定覆盖: I.A = 3, B = 0, X = 3 ( 覆盖 sacbd ) 判定条件覆盖比语句覆盖强,但是对程序逻辑的覆盖程度仍然不高,例如,上面的测试数据只覆盖了程序全部路径的一半。 3.条件覆盖 条件覆盖的含义是,不仅每个语句至少执行一次,而且使判定表达式中的每个条件都取到各种可能的结果。 图 4.7 的例子总共有两个判定表达式,每个表达式中有两个条件,为了做到条件覆盖,应该选取测试数据使得实在 a 点有下述各种结果出现: A > 1, A ≤ 1, B = 0, B ≠ 0 在 b 点有下述各种结果出现: A = 2, A ≠ 2, X > 1, X ≤ 1 只需要使用下面两组测试数据就可以达到上述覆盖标准: I.A = 2, B = 0, X = 4 ( 满足 A > 1, B = 0, A = 2 和 X > 1 的条件,执行路径 sacbed ) II.A = 1, B = 1, X = 1 ( 满足 A ≤ 1, B ≠ 0, A ≠ 2 和 X ≤ 1 的条件,执行路径 sabd ) 条件覆盖通常比判定覆盖强,因为它使判定表达式中每个条件都取到了两个不同的结果,判定覆盖却只关心整个判定表达式的值。例如,上面两组测试数据也同时满足判定覆盖标准。但是,也可能有相反的情况:虽然每个条件都取到了两个不同的结果,判定表达式却始终只取一个值。例如,如果使用下面两组测试数据,则只满足条件覆盖标准并不满足判定覆盖标准( 第二个判定表达式的值总为真 ): 4.判定/条件覆盖 既然判定覆盖不一定包含条件覆盖,条件覆盖也不一定包含判定覆盖,自然会提出一种能同时满足这两种覆盖标准的逻辑覆盖,这就是判定/条件覆盖。它的含义是,选取足够多的测试数据,使得判定表达式中的每个条件都取到各种可能的值,而且每个判定表达式也都取到各种可能的结果。 对于图 4.7 的例子而言,下述两组测试数据满足判定/条件覆盖标准: I.A = 2, B = 0, X = 4 但是,这两组测试数据也就是为了满足条件覆盖标准最初选取的两组数据,因此,有时判定/条件覆盖也并不比条件覆盖更强。 5.条件组合覆盖 条件组合覆盖是更强的逻辑覆盖标准,它要求选取足够的测试数据,使得每个判定表达式中条件的各种可能组合都至少出现一次。 对于图 4.7 的例子,共有 8 种可能的条件组合,它们是: 和其它逻辑覆盖标准中的测试数据一样,条件组合(5)~(8)中的 X 值是指在程序流程图第二个判定框( b 点)的 X 值。 下面的 4 个测试数据可以使上面列出的 8 种条件组合每种至少出现一次: I.A = 2, B = 0, X = 4 显然,满足条件组合覆盖标准的测试数据,也一定满足判定覆盖、条件覆盖和判定/条件覆盖标准。因此,条件组合覆盖是前述几种覆盖标准中最强的。但是,满足条件组合覆盖标准的测试数据并不一定能使程序中的每一条路径都执行到,例如,上述 4 组测试数据都没有测试到路径 sacbd 。 以上根据测试数据对源程序语句检测的详尽程度,简单讨论了几种逻辑覆盖标准。在上面的分析过程中常常谈到测试数据执行的程序路径,显然,测试数据可以检测的程序路径的多少,也反映了对程序测试的详尽程度。从对程序路径的覆盖程度分析,我们又能够提出下述一些主要的逻辑覆 6.点覆盖 图论中点覆盖的概念定义如下:如果连通图 G 的子图 G′是连通的,而且包含 G 的所有结点,则称 G′是 G 的点覆盖。在正常情况下流图是连通图的有向图。满足点覆盖标准要求选取足够多的测试数据,使得程序执行路径至少经过流图的每个结点一次,由于流图的每个结点与一条或条语句相对应,显然,点覆盖标准和语句覆盖标准是相同的。 7.边覆盖 图论中边覆盖的定义是:如果连通图 G 的子图 G′′是连通的,而且包含 G 的所有边,则称 G′′是G 的边覆盖。为了满足边覆盖的测试标准,要求选取足够多的测试数据,使得程序执行路径至少经过流图中每条边一次。通常边覆盖和判定覆盖是一致的。 8. 路径覆盖 路径覆盖的定义是,选取足够多测试数据,使程序的每一条可能路径都至少执行一次。 对于图 4.7 所示例子,请读者考虑满足路径覆盖的测试数据。 这里所用的程序段非常简短,只有 4 条路径。但在实际问题中,一个不太复杂的程序,其路径数都可能是一个庞大的数字,以致要在测试中覆盖所有的路径是不可能实现的。为解决这一难题,只得把覆盖的路径数压缩到一定限度内,例如,对程序中的循环体只执行一次。 即使对于路径数有限的程序做到了路径覆盖,也不能保证被测程序的正确性。因为通过分析测试数据,我们可以发现路径覆盖不能保证满足条件组合覆盖。而且在前面我们也已经介绍过穷举路径测试法无法检查出程序本身是否违反了设计规范,即程序是否是一个错误的程序;不可能查出程 为实现测试的逻辑覆盖,必须设计足够多的测试用例,并使用这些测试用例执行被测程序,实施测试。对某个具体程序来说,至少要设计多少测试用例。这里提供一种估算最少测试用例数的方法。 这样,任一循环便改造成进入循环体或不进入循环体的分支操作了。 图4.8给出了类似于流程图的N-S图表示的基本控制结构(图中A、B、C、D、S均表示要执行的操作,P是可取真假值的谓词,Y表真值,N表假值)。其中图4.8(c)和图4.8(d)两种重复型结构代表了两种循环。在作了如上简化循环的假设以后,对于一般的程序控制流,我们只考虑选择型结构。事实上它已能体现顺序型和重复型结构了。 例如,图 4.9 表达了两个顺序执行的分支结构。两个分支谓词 P1 和 P2 取不同值时,将分别执行 a 或 b 及 c 或 d 操作。显然,要测试这个小程序,需要至少提供 4 个测试用例才能做到逻辑覆盖。使得 ac、ad、bc 及 bd 操作均得到检验。其实,这里的 4 是图中第 1 个分支谓词引出的两个操作,及第 2 个分支谓词引出的两个操作组合起来而得到的。 对于一般的、更为复杂的问题,估算最少测试用例数的原则也是同样的。现以图 4.10 表示的程序为例。该程序中共有 9 个分支谓词,尽管这些分支结构交错起来似乎十分复杂,很难一眼看出应至少需要多少个测试用例,但如果仍用上面的方法,也是很容易解决的。我们注意到该图可分上下两层:分支谓词 1 的操作域是上层,分支谓词 8 的操作域是下层。这两层正像前面简单例子中的 P1和 P2 的关系一样。只要分别得到两层的测试用例个数,再将其相乘即得总的测试用例数。这里需要首先考虑较为复杂的上层结构。谓词 1 不满足时要作的操作又可进一步分解为两层,这就是图 4.11中的子图(a)和(b)。它们所需测试用例个数分别为 1+1+1+1+1 = 5 及 1+1+1 = 3。因而两层组合,得到 5×3 = 15。于是整个程序结构上层所需测试用例数为 1+15 = 16。而下层显然为 3。故最后得到 独立路径测试是在程序控制流图的基础上,通过分析控制结构的环路复杂性,导出可执行的独立路径集合,从而设计出相应的测试用例。设计出的测试用例要保证被测程序的每条可执行的独立路径至少被执行一次。路径测试考虑以下几个方面: 程序控制流图 由于测试用例要完成某条程序路径的执行,因此测试用例和测试用例所执行的程序路径之间有着非常明确的关系。 在路径测试中,最关键的问题仍然是如何设计测试用例,使之能够避免测试的盲目性,又能有较高的测试效率。一般有 3 个途径可得到测试用例: 按以上方法实施测试,原则上是可以做到路径覆盖的,因为: 对程序中的循环作了如上限制以后,程序路径的数量是有限的。 循环是绝大多数软件算法的基础,但是,在测试软件时却往往未对循环结构进行足够的测试。循环测试是一种白盒测试技术,它专注于测试循环结构的有效性。在结构化的程序中通常只有3 种循环,即简单循环、串接循环和嵌套循环,如图 4.12 所示。下面讨论这 3 种循环的测试方法。 1.简单循环 2.嵌套循环 如果把简单循环的测试方法直接应用到嵌套循环,可能的测试数就会随嵌套层数的增加按几何级数增长,这会导致不切实际的测试数目。B.Beizer 提出了一种能减少测试数的方法:从最内层循环开始测试,把所有其它循环都设置为最小值;对最内层循环使用简单循环测试方法,而使外层循环的迭代参数(例如,循环计数器)取最小值,并为越界值或非法值增加一些额外的测试;由内向外,对下一个循环进行测试,但保持所有其它外层循环为最小值,其它嵌套循环为“典型”值;继续进行下去,直到测试完所有循环。 3.串接循环 如果串接循环的各个循环都彼此独立,则可以使用前述的测试简单循环的方法来测试串接循环。但是,如果两个循环串接,而且第一个循环的循环计数器值是第二个循环的初始值,则这两个循环并不是独立的。当循环不独立时,建议使用测试嵌套循环的方法来测试串接循环。 对面向对象软件的类测试相当于传统软件的单元测试。但与传统软件的单元测试不同的是,它往往关注模块的算法细节和模块借口间流动的恶数据,面向对象软件的类测试是由封装在类中的操作和类的状态行为所驱动的。 功能性测试以类的规格说明为基础,它主要检查类是否符合其规格说明的要求。例如,对于 Stack类,即检查它的操作是否满足 LIFO 规则;结构性测试则从程序出发,它需要考虑其中的代码是否正确,同样是 Stack 类,就要检查其中代码是否动作正确且至少执行过一次。 结构性测试是对类中的方法进行测试,它把类作为一个单元来进行测试。测试分为两层:第一层考虑类中各独立方法的代码;第二层考虑方法之间的相互作用。 每个方法的测试要求能针对其所有的输入情况,但这样还不够,只有对这些方法之间的接口也做同样测试,才能认为测试是完整的。对于一个类的测试要保证类在其状态的代表集上能够正确工作,构造函数的参数选择以及消息序列的选择都要满足这一准则。因此,在这两个不同的测试层次 (1)方法的单独测试 结构性测试的第一层是考虑各独立的方法,这可以与过程的测试采用同样的方法,两者之间最大的差别在于方法改变了它所在实例的状态,这就要取得隐藏的状态信息来估算测试的结果,传给其它对象的消息被忽略,而以桩来代替,并根据所传的消息返回相应的值,测试数据要求能完全覆盖类中代码,可以用传统的测试技术来获取。 (2)方法的综合测试 第二层要考虑一个方法调用本对象类中的其它方法和从一个类向其它类发送信息的情况。单独测试一个方法时,只考虑其本身执行的情况,而没有考虑动作的顺序问题,测试用例中加入了激发这些调用的信息,以检查它们是否正确运行了。对于同一类中方法之间的调用,一般只需要极少甚 1.域测试 域测试(Domain Testing)是一种基于程序结构的测试方法。Howden 把程序中出现的错误分为域错误、计算型错误和丢失路径错误三种。这是相对于执行程序的路径来说的。我们知道,每条执行路径对应于输入域的一类情况,是程序的一个子计算。如果程序的控制流有错误,对于某一特定的输入可能执行的是一条错误路径,这种错误称为路径错误,也叫做域错误。如果对于特定输入执行的是正确路径,但由于赋值语句的错误致使输出结果不正确,则称此为计算型错误。另外一类错误是丢失路径错误。它是由于程序中某处少了一个判定谓词而引起的。域测试是主要针对域错误进行的程序测试。 域测试的“域”是指程序的输入空间。域测试方法基于对输入空间的分析。自然,任何一个被测程序都有一个输入空间。测试的理想结果就是检验输入空间中的每一个输入元素是否都产生正确的结果。而输入空间又可分为不同的子空间,每一子空间对应一种不同的计算。在考察被测试程序 2. 符号测试 符号测试的基本思想是允许程序的输入不仅仅是具体的数值数据,而且包括符号值,这一方法也是因此而得名。这里所说的符号值可以是基本符号变量值,也可以是这些符号变量值的一个表达式。这样,在执行程序过程中以符号的计算代替了普通测试执行中对测试用例的数值计算。所得到 符号测试可以看作是程序测试和程序验证的一个折衷方法。一方面,它沿用了传统的程序测试方法,通过运行被测程序来验证它的可靠性。另一方面,由于一次符号测试的结果代表了一大类普通测试的运行结果,实际上是证明了程序接受此类输入,所得输出是正确的,还是错误的。最为理 从符号测试方法使用来看,问题的关键在于开发出比传统的编译器功能更强,能够处理符号运算的编译器和解释器。 (1)分支问题 当采用符号执行方法进行到某一分支点处,分支谓词是符号表达式,这种情况下通常无法决定谓词的取值,也就不能决定分支的走向,需要测试人员做人工干预,或是执行树的方法进行下去。如果程序中有循环,而循环次数又决定于输入变量,那就无法确定循环的次数。 (2)二义性问题 数据项的符号值可能是有二义性的。这种情况通常出现带有数组的程序中。 我们来看以下的程序段: 如果I = J,则C = 3,否则C = 2 + A。但由于使用符号值运算,这时无法知道I是否等于J。 (3)大程序问题 符号测试中总是要处理符号表达式。随着符号执行的继续,一些变量的符号表达式会越来越庞大。特别是当符号执行树如果很大,分支点很多,路径条件本身变成一个非常长的合取式。如果能够有办法将其化简,自然会带来很大好处。但如果找不到化简的办法,那将给符号测试的时间和运 3. Z 路径覆盖 分析程序中的路径是指:检验程序从入口开始,执行过程中经历的各个语句,直到出口。这是白盒测试最为典型的问题。着眼于路径分析的测试可称为路径测试。完成路径测试的理想情况是做到路径覆盖。对于比较简单的小程序实现路径覆盖是可能做到的。但是如果程序中出现多个判断和 为了解决这一问题,我们必须舍掉一些次要因素,对循环机制进行简化,从而极大地减少路径的数量,使得覆盖这些有限的路径成为可能。我们称简化循环意义下的路径覆盖为Z路径覆盖。 这里所说的对循环化简是指限制循环的次数。无论循环的形式和实际执行循环体的次数多少,我们只考虑循环一次和零次两种情况。即只考虑执行时进入循环体一次和跳过循环体这两种情况。 对于程序中的所有路径可以用路径树来表示,具体表示方法本文略。当得到某一程序的路径树后,从其根结点开始,一次遍历,再回到根结点时,把所经历的叶结点名排列起来,就得到一个路径。如果我们设法遍历了所有的叶结点,那就得到了所有的路径。当得到所有的路径后,生成每个 软件测试是一项艰苦的工作,需要投入大量的时间和精力,据统计,软件测试会占用整个开发时间的 40%。一些可靠性要求非常高的软件,测试时间甚至占到总开发时间的 60%。但是软件测试具有一定的重复性,我们知道,软件在发布之前要进行几轮测试。在测试后期所进行的回归测试中大部分测试工作是重复的,回归测试就是要验证已经实现的大部分功能。这种情况下,代码修改很少,针对代码变化所做的测试相对较少。而为了覆盖代码改动所造成的影响需要进行大量的测试,虽然这种测试找到软件缺陷的可能性小,效率比较低,但又是必要的。此后,软件不断升级,所要做的测试重复性也很高,所有这些因素驱动着软件自动化的产生和发展。 自动化测试是相对于手工测试而存在的,主要是使用软件工具来代替手工进行的一系列动作,具有良好的可操作性、可重复性和高效率等特点。自动化测试的目的是减轻手工测试的工作量,以达到节约资源(包括人力、物力等),保证软件质量,缩短测试周期的效果,是软件测试中提高测试 测试人员在进行手工测试时,具有创造性,可以举一反三,从一个测试用例想到另外一个测试用例,特别是可以考虑到测试用例没有覆盖的一些特殊的或边界的情况。同时,对于那些复杂的逻辑判断、界面是否友好,手工测试具有明显的优势。但是手工测试在某些测试方面,可能还存在着 1.提高测试效率 手工测试是一个劳动密集型的工作,并且容易出错。引入自动测试能够用更有效、可重复的自动化测试环境代替繁琐的手工测试活动,而且能在更少的时间内完成更多的测试工作,从而提高了测试工程师的工作效率。 2.降低对软件新版本进行回归测试的开销 对于现代软件的迭代增量开发,每一个新版本大部分功能和界面都和上一个版本相似或完全相同,这时要对新版本再次进行已有的测试,这部分工作多为重复工作,特别适合使用自动化测试来完成,从而减小回归测试的开销。 3.完成手工测试不能或难以完成的测试 对于一些非功能性方面的测试,如:压力测试、并发测试、大数据量测试、崩溃性测试等,这些测试用手工测试是很难,甚至是不可能完成的。但自动化测试能方便地执行这些测试,比如并发测试,使用自动化测试工具就可以模拟来自多方的并发操作了。 4.具有一致性和可重复性 由于每次自动化测试运行的脚本是相同的,所以可以进行重复的测试,使得每次执行的测试具有一致性,手工测试则很难做到这点。 5.更好地利用资源 将繁琐的测试任务自动化,可以使测试人员解脱出来,将精力更多地投入到测试案例的设计和必要的手工测试当中。并且理想的自动化测试能够按计划完全自动地运行,使得完全可以利用周末和晚上的时间执行自动测试。 6.降低风险,增加软件信任度 自动化测试能通过较少的开销获得更彻底的测试效果,从而更好地提高了软件产品的质量。 当然,自动化测试也并非万能,它所完成的测试功能也是有限的,不可能也没有必要取代手工测试来完成所有的测试任务。以下几点是自动化测试的不足: 测试工具可以从两个不同的方面去分类: 根据测试方法不同,分为白盒测试工具和黑盒测试工具。 1.白盒测试工具 白盒测试工具是针对程序代码、程序结构、对象属性、类层次等进行测试,测试中发现的缺陷可以定位到代码行、对象或变量级。根据测试工具原理的不同,又可以分为静态测试工具和动态测试工具。 2.黑盒测试工具 黑盒测试工具适用于系统功能测试和性能测试,包括功能测试工具、负载测试工具、性能测试工具等。黑盒测试工具的一般原理是利用脚本的录制(Record)/回放(Playback),模拟用户的操作,然后将被测系统的输出记录下来同预先给定的标准结果比较。黑盒测试工具可以大大减轻黑盒测试的工作量,在迭代开发的过程中,能够很好地进行回归测试。 3.其他测试工具 在上述两类测试工具之外还有测试管理工具,这类工具负责对测试计划、测试用例、测试实施进行管理、对产品缺陷跟踪管理、产品特性管理等。 随着计算机硬件成本的不断下降,软件在整个计算机系统的成本中占有越来越高的比例,如何提高软件质量是整个计算机软件行业的重大课题。软件测试作为软件开发的一个重要环节,日益受到人们的重视。为了尽可能多地找出程序中的错误,保证软件产品的质量,就需要对软件测试进行 实践证明,对软件进行测试管理可及早发现错误,避免大规模返工,降低软件开发费用。为确保最终软件质量符合要求,必须进行测试与管理。对于不同企业的不同类产品、不同企业的同一类产品或同一企业的不同类产品,其各阶段结果的形式与内容都会有很大的不同。所以对于软件测试 一个成功的测试开始于一个全面的测试管理计划。因此,在每次测试之前应做好详细的测试管理计划: 首先应该了解被测对象的基本信息,选择测试的标准级别,明确测试管理计划标识和测试管理项。在定义了被测对象的测试管理目标、范围后必须确定测试管理所使用的方法,即提供技术性的测试管理策略和测试管理过程。在测试管理计划中,管理者应该全面了解被测试对象的系统方法、 由于任何一个软件不可能没有缺陷、系统运行时不出现故障,所以在测试管理计划中还必须考虑到一些意外情况,也就是说。当问题发生时应如何处理。因为测试管理具有一定难度,所以对测试管理者应进行必要的测试设计、工具、环境等的培训。 最后,还必须确定认可和审议测试管理计划的负责人员。 一般来讲,由一位对整个系统设计熟悉的设计人员编写测试大纲,明确测试的内容和测试通过的准则,设计完整合理的测试用例,以便系统实现后进行全面测试。 在实现组将所开发的程序经验证后,提交测试组,由测试负责人组织测试,测试一般可按下列方式组织: \1. 首先,测试人员要仔细阅读有关资料,包括规格说明、设计文档、使用说明书及在设计过程中形成的测试大纲、测试内容及测试的通过准则,全面熟悉系统,编写测试计划,设计测试用例,作好测试前的准备工作。 \2. 为了保证测试的质量,将测试过程分成几个阶段,即:代码审查、单元测试、集成测试、确认测试和系统测试。 ① 代码审查 代码审查是由一组人通过阅读、讨论和争议对程序进行静态分析的过程。审查小组在充分阅读待审程序文本、控制流程图及有关要求、规范等文件基础上,召开代码审查会议,程序员逐句讲解程序的逻辑,并展开热烈的讨论甚至争议,以揭示错误的关键所在。实践表明,程序员在讲解过程 ② 单元测试 单元测试集中在检查软件设计的最小单位——模块上,通过测试发现实现该模块的实际功能与定义该模块的功能说明不符合的情况,以及编码的错误。 ③ 集成测试 集成测试是将模块按照设计要求组装起来同时进行测试,主要目标是发现与接口有关的问题。如数据穿过接口时可能丢失;一个模块与另一个模块可能有由于疏忽的问题而造成有害影响;把子功能组合起来可能不产生预期的主功能;个别看起来是可以接受的误差可能积累到不能接受的程度; 全局数据结构可能有错误等。 ④ 确认测试 确认测试的目的是向未来的用户表明系统能够像预定要求那样工作。经集成测试后,已经按照设计把所有的模块组装成一个完整的软件系统,接口错误也已经基本排除了,接着就应该进一步验证软件的有效性,这就是确认测试的任务,即软件的功能和性能如同用户所合理期待的那样。 ⑤ 系统测试 软件开发完成以后,最终还要与系统中其它部分配套运行,进行系统测试。包括恢复测试、安全测试、强度测试和性能测试等。 在整个过程当中我们需要对测试过程中每个状态进行记录、跟踪和管理,并提供相关的分析和统计功能,生成和打印各种分析统计报表。通过对详细记录的分析,形成较为完整的软件测试管理文档,保障软件在开发过程中,避免同样的错误再次发生,从而提高软件开发质量。 为了保证软件的开发质量,软件测试应贯穿于软件定义与开发的整个过程。因此,对分析、设计和实现等各阶段所得到的结果,包括需求规格说明、设计规格说明及源程序都应进行软件测试。基于此,软件测试人员的组织也应是分阶段的。 \1. 软件的设计和实现都是基于需求分析规格说明进行的。 需求分析规格说明是否完整、正确、清晰是软件开发成败的关键。为了保证需求定义的质量,应对其进行严格的审查。 审查小组通常由一名组长和若干成员组成,其成员包括系统分析员,软件开发管理者,软件设计、开发、测试人员和用户。 \2. 设计评审 软件设计是将软件需求转换成软件表示的过程。主要描绘出系统结构、详细的处理过程和数据库模式。按照需求的规格说明对系统结构的合理性、处理过程的正确性进行评价,同时利用关系数据库的规范化理论对数据库模式进行审查。评审小组由下列人员组成:组长一名,成员包括系统分 \3. 软件测试 软件测试是软件质量保证的关键。软件测试在软件生存周期中横跨两个阶段:通常在编写出每一个模块之后,就对它进行必要的测试(称为单元测试)。编码与单元测试属于软件生存周期中的同一阶段。该阶段的测试工作,由编程组内部人员进行交叉测试(避免编程人员测试自己的程序)。这一阶段结束后,进入软件生存周期的测试阶段,对软件系统进行各种综合的测试。测试工作由专门的测试组完成,测试组设组长一名,负责整个测试的计划、组织工作。测试组的其他成员由具有一定的分析、设计和编程经验的专业人员组成,人数根据具体情况可多可少,一般 3~5 人为宜。 \1. 测试控制对象的编辑和管理: 测试控制对象包括测试方案、测试案例、各案例的具体测试步骤、问题报告、测试结果报告等,该部分主要是为各测试阶段的控制对象提供一个完善的编辑和管理环境。 \2. 测试流程控制和管理 测试流程的控制和管理是基于科学的流程和具体的规范来实现的,并利用该流程和规范,严格约束和控制整个产品的测试周期,以确保产品的质量。整个过程避免了测试人员和开发设计人员之间面对面的交流,减少了以往测试和开发之间难免的摩擦和矛盾,提高了工作效率。 \3. 统计分析和决策支持 在系统建立的测试数据库的基础上,进行合理的统计分析和数据挖掘,例如根据问题分布的模块、问题所属的性质、问题的解决情况等方面的统计分析使项目管理者全面了解产品开发的进度,产品开发的质量,产品开发中问题的聚集,为决策管理提供支持。例如,设计人员在遇到问题时可 任何程序,无论大小,都可能会有错误发生。每一个新版本都需要进行新特性的测试和其他特性的一些回归测试。所以软件测试管理具有周期性。 \1. 按照国际质量管理标准,建立适合本公司的软件测试管理体系,以提高公司开发的软件质量,并降低软件开发及维护成本; 在软件测试管理周期中,为了便于对制定的测试方案、编写测试案例和测试步骤等各个阶段进行有效的控制和管理;为了提高软件开发和产品测试的管理水平,保证软件产品质量,软件测试管理工具是非常重要的手段。在此介绍一些比较流行的软件测试管理工具: \1. 软件测试管理系统(TMS): TMS 测试管理系统管理功能全面。对测试流程的设计科学、规范、合理。系统的开发是在充分借鉴了 Microsoft、Nortel 等国际知名大公司在测试领域尤其是测试流程管理方面的经验,参考了 SQA Manager 等国外知名测试管理软件。并结合开发人员在业界的经验和对国内软件开发现状的把握等基础上开发而成,非常贴近国内用户的需求;具有很强大的测试案例、测试步骤的编辑和管理功能。问题(缺陷)的跟踪处理功能。所有输出结果自动生成 Word 文档的功能。同时有强大的统计分析、决策支持能力。该系统技术实现上采用 Web/Browser 开发模式。使用维护方便,具有良好的性价比。 \2. Test Management Workshop(测试管理工具): 该系统定义了一个良好的表单归档机制。并且支持这些表单的交叉引用。通过关键项目文档中内建的关联设计,用户可以根据不同的线索追踪和调用相关的文档。同时。所有文档均被置于严格的安全控制之下,而且客户端支持浏览器方式操作。 \3. 测试管理工具(Jactus Labs) :Jactus Labs 的测试管理工具为了适应数以百计的用户,有一个中心数据储存库。所有的用户可以共享并存取主要的信息——测试脚本、缺陷及报告书。该测试管理工具把测试计划、测试执行和缺陷跟踪三者有机地结合在一起,同时为了更多的灵活性还采用了开放式测试结构(Open Test Architecture。OTA)。它利用 Microsoft Access 数据库缩小安装。并利用符合行业标准的关系数据库包括:Oracle、Microsoft SQL Server 和 Sybase 来扩大安装测试管理工具。 \4. 软件测试管理系统(i-Test) :i-Test 系统采用 B/S 结构。可以安装在 Web 服务器上。项目有关人员都可以在不同地点通过 Internet 同时登录和使用,协同完成软件测试,减少为了集中人员而出差所产生的费用。同时,该系统提供相应的自动化功能。可高效编写、查询和引用测试用例,快速填写、修改和查询软件缺陷报告,并提供相关的分析和统计功能,生成和打印各种分析统计报表。 这些软件测试管理工具可以为企业商业系统提供全面的、综合的测试管理解决方案,并可以控制和管理所有的测试工作来确保测试是一个有组织的、规范文档化的和全面的测试活动。 JUnit 是一个开源的 java 测试框架,它是 Xuint 测试体系架构的一种实现。JUnit 最初由 ErichGamma 和 Kent Beck 所开发。在 JUnit 单元测试框架的设计时,设定了三个总体目标,第一个是简化测试的编写,这种简化包括测试框架的学习和实际测试单元的编写;第二个是使测试单元保持持久性;第三个则是可以利用既有的测试来编写相关的测试。 JUnit 是以 JAR 文件的形式发布的,其中包括了所有必须的类。安装 JUnit,你所需要做的一切工作就是把 JAR 文件放到你的编译器能够找到的地方。 在微软的 Windows 操作系统中,进行下面这个菜单路径: Start 如果有了修改已经存在的哪个 CLASSPATH 变量,或者添加一个名为 CLASSPATH 的环境变量。假设 JUnit 的 jar 包位于 C:\java\junit3.8.1\junit.jar。需要把这些值输入哪个对话框中: Variable:CLASSPATH 如果在 class path 中有已经存在的条目,注意每个新加的 class path 都要用分号(“;”)隔开。需要重新启动所有的 shell 窗口或者应用程序以使这些改动生效。 要获知 JUnit 是否已经安装好了,试着编译一下包含下面这个 import 语句的源文件:Import junit.framework.*; 在编写测试代码的时候,需要遵循一些命名习惯。如果有一个名为 createAccount 的被测试函数,那么第一个测试函数的名称也许就是 testCreateAccount 什么的。其中,方法 testCreateAccount 以恰当的参数调用 createAccount 并验证 createAccount 的行为是否和它宣称的一样。当然可以有许多测试方法来执行 createAccount. 图 6.1 展示了两块代码之间的关系。 测试代码仅限于内部使用。客户或者最终用户永远都不会看到,更不会使用这些代码。因此,产品代码(最后要发布给客户或者放入产品中的代码)对测试代码是一无所知的。产品代码最后将撇下测试代码独自闯入一个寒冷的世界。 测试代码必须要做以下这几件事情: ● 准备测试所需要的各种条件(创建所有必须的对象,分配必要的资源等)。 对于测试代码,也是用一般的方式编写和编译,这和项目中普通源码是一样的。测试代码可能偶尔会用到某些额外的程序库,但是除此之外,测试代码并没有任何特别之处,它们也只是普通代码而已。 JUnit 提供了一些辅助函数,用于帮助我们确定某个被测试函数是否工作正常。通常而言,把所 断言是单元测试最基本的组成部分。因此 JUnit 程序库提供了不同形式的多种断言。 ● assertEquals 95 任何对象都可以拿来做相等性测试:适当的相等性判断方法会被用来做这样的比较。譬如,可能会使用这个方法来比较两个字符串的内容是否相等。此外,对于原生类型(boolean,int,short 等)和 Object 类型也提供了不同的函数签名。值得注意的是使用原生数组的 equals 方法时,它并不是比较数组的内容,而只是比较数组引用本身,而这大概不是所希望的。 计算机并不能精确地表示所有的浮点数,通常都会有一些偏差。因此,如果想用断言来比较浮点数(在 Java 中,是类型为 float 或者 double 的数),则需要指定一个额外的误差参数。它表明需要多接近才能认为两数“相等”。对于商业程序而言,只要精确到小数点的后 4 位或者后 5 位就足够了。对于进行科学计算的程序而言,则可能需要更高的精度。 assertEquals([Sting message], 例如,下面的断言将会检查实际的计算结果是否等于 3.33,但是该检查只精确到小数点的后两 ● assertNull assertNull([Sting message],java.lang.Object object) ● assertSame assertSame([Sting message],expected,axtual) ● assertTrue assertTrue([Sting message],Boolean condition) ● Fail Fail([Sting message])上面的断言将会使测试立即失败,其中 message 参数是可选的。这种断言通常被用于标记某个不应该被到达的分支(例如,在一个预期发生的异常之后。) ● 使用断言 一般而言,一个测试方法包含有多个断言,因为需要验证该方法的多个方面以及内在的多种联系。当一个断言失败的时候,该测试方法将会被中止,从而导致该方法中余下的断言这次就无法执行了,此时不能有别的想法,而只能是在继续测试之前先修复这个失败的测试。依此类推,不断地 期望所有的测试在任何时候都能通过。在实践中,这意味着当引入一个 bug 的时候,只有一到两个测试会失败。在这种情况下,把问题分离出来将会相当容易。当有测试失败的时候,无论如何都不能给原有代码再添加新的特性。此时应该尽快地修复这个错误,直到让所有的测试都能顺利通过。 到目前为止,我们只是介绍了断言方法本身。显然,不能只是简单地把断言方法写到源文件里面,然后就希望它这就能运行起来。需要一个框架,那就要比这多做一些工作了。幸运的是,也不会多做太多。 尽管上面的代码非常清楚,但还是看看这段代码的每一部分。 首先,第 1 行的 import 声明引入了必须的 JUnit 类。 接下来,在第 3 行定义了一个类:每个包含测试都必须如所示那样由 TestCase 继承而来。基类TestCase 提供了所需的大部分的单元测试功能,包括所有在前面讲述过的断言方法。 基类需要一个以 String 为参数的构造函数,因而我们必须调用 super 以传递这么一个名字。不知道这个名字此时是什么,因而仅仅让构造函数接受 String 为参数并把这个参数在第 5 行传递上去。 最后,测试类包含了名为 test 的方法。在上面这个例子中,在第 9 行写了一个名为 testAdd 的方法。而所有以 test 开头的方法都会被 JUnit 自动运行。还可以通过定义 suite 方法指定特殊的函数来运行;后面会对这个做更多讲述。 在上面的例子中,展示了一个测试,它只有一个测试方法,而这个测试方法中又仅有一个断言。 正如之前所看到的一样,一个测试类包含一些测试方法;每个方法包含一个或者多个断言语句。 但是测试类也能调用其它测试类:单独的类、包、甚至一个完整的系统。 这种魔力可以通过创建 test suite 来取得。任何测试类都能包含一个名为 suite 的静态方法 可以提供 suite()方法来返回任何想要的测试集合(没有 siute()方法 JUnit 会自动运行所有的 test方法)。但是可能需要手工添加特殊的测试,包括其它 suite。 例如,假设已经有了类似于在 TestClassOne 类中看到过的那样普通的一套测试: 默认的动作对这个类使用 Java 反射,将运行 testSubtraction()和 testAddition()。 现在假设有了第二个类 TestClassTwo。它使用了 brute-force 算法来寻找旅行销售商 Bob 的最短行程。关于旅行销售商人的算法的有趣事情是,当城市数目小的时候,它能工作正常,但是它是一个指数型的算。比如,数百个城市的问题可能需要 20000 年才能运行出结果。甚至 50 个城市都需要花上数小时的运行时间,因此,在默认情况下,可能不想包括这些测试。 测试仍然在那儿,但要运行它必须显示说明要运行它(131 页的附录 C 中会展示一种用特殊的测试骨架来做这项工作的办法)。没有这个特殊的机制,当调用 test suite 的时候,只有那些运行不花多少时间的测试会被运行。 而且,此时看到了给构造函数的 String 参数是做什么用的了:它让 TestCase 返回了一个对命名测试方法的引用。这使用它来得到那两个耗时少的方法的引用,以把它们包含到 test suite 之中。 可能想要一个高一级别的测试来组合这两个测试类: 现在,如果运行 TestClassComposite,以下单个的测试方法都将被运行: ● 来自 TestClassOne 的 testAddition() 可以继续这种模式;另外一个类可能会包含 TestClassComposite,这将使得它包括上面所有的测试方法,另外还会有它包含的其它测试的组合,等等。 ● Per-method 的 Setup 和 Tear-down 每个测试的运行都应该是互相独立的;从而可以在任何时候,以任意的顺序运行每个单独的测试。 为了获得这样的好处,在每个测试开始之前,都需要重新设置某些测试环境,或者在测试完成之后,需要释放一些资源。JUnit 的 TestCase 基类提供两个方法供改写,分别用于环境的建立和清理: protected void setup(); 在以上例子中,在调用每个 test 方法之前,调用方法 setUp();并且在每个测试方法完成之后,调用方法 tearDown()。 例如,假设对于每个测试,都需要某种数据库连接。这时,就不需要在每个测试方法中重复建立连接和释放连接了,而只须在 setup 和teardown 方法中分别建立和释放连接: ● Per-suite SetUp 和 Tear-down 一般而言,只须针对每个方法设置运行环境;但是在某些情况下,须为整个 test suite 设置一些环境,以及在 test-suite 中的所有方法都执行完成后做一些清理工作。要达到这种效果,需要 per-suitesetup 和 per-suite tear-down( 就执行顺序而言,per-test 和 per-suite 之间的区别可以参见图 6.2 )。 Per-suite 的 setup 要复杂些。需要提供所需测试的一个 suite( 无论通过什么样的方法 )并且把它包装进一个 TestSetup 对象。使用前面的例子,那可能就象这样: 注意,可以在同一个类中同时使用 per-suite 和 per-test 的 setup()和 teardown()。 通常而言,JUnit 所提供的标准断言对大多数测试已经足够了。然而,在某些环境下,譬如要处理一个特殊的数据类型,或者处理对多个测试都共享的一系列操作,那么如果有自定义的断言,将会更加方便。 在测试代码中,请不要拷贝和粘贴公有代码;测试代码的质量应该和产品代码一样,也就是说,在编写测试代码的时候,也应该维持好的编码原则,诸如 DRY 原则、正交性原则等等。因此,需要把公共的测试代码抽取到方法中去,并且在测试用例中使用这些方法。 在此,提供了两种形式的断言:一种接收一个 String 参数,另外一种则没有。注意,并没有拷贝和粘贴代码,而只是把第二个调用委托给了第一个。 事实上,开始新项目时总是从自己的自定义基类继承而不直接从 JUnit 的类继承通常是一个好主意,即便自己的基类在一开始没有添加任何额外的功能。这样做的好处是当需要添加一个所有测试类都需要的方法或者能力时,可以简单地编写自己的基类而不需要改动项目中的所有 test case。 对于测试而言,下面两种异常是可能令人感兴趣的: \1. 从测试代码抛出的可预测异常。 \2. 由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。 也许和想象的正好相反,异常在这里是彻头彻尾的好东西——它们能够告诉人们什么东西出错了。有时,在一个测试中,需要被测试方法抛出一个异常。例如,有一个名为 sortMyList()的方法。 被测试的方法调用被第 3 行的 try/catch 块包含于内。预期中这个方法会抛出一个异常,因而如果它没有——如果成功通过了第三行——那么就需要立即把测试置为失败。如果异常如预期那样发生了,则代码将跳到第 6 行并且记录下断言以做统计目的使用。 现在可能要问为什么还要那么麻烦用 assertTrue 呢?它什么也不干,它不会失败,干嘛还要把它放进来?任何对 assertTrue(true)的使用都应该被翻译为“预期控制流程会达到这个地方。”这对将来可能的误解来说会起到强有力的文档的作用。然而,不要忘记一个 assertTrue(true)没有被调用不会产生任何错误的。 通常而言,对于方法中每个被期望的异常,都应该写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。然而,这样虽然能够确认期望的异常,但是对于出乎意料的异常,应该怎么办呢? 虽然能够捕捉所有的异常并且调用 JUnit 的 fail(),但是最好让 JUnit 来做这件困难事。例如,假设正在读取一个包含测试数据的文件。不要自己去捕捉所有可能的 I/O 异常,而是简单地改变测试方法的声明让它能抛出可能的异常: 实际上,JUnit 框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要参与。更好的是,JUnit 不只是让一个断言失败,而是能够跟踪整个堆栈,并且报告 bug 的堆栈调用顺序;当需要查找一个失败测试的原因时,这将非常有用。 通常而言,都希望所有的测试在任何时候都能够顺利通过。但假设之前想到了一些测试,并且编写了这些测试;现在正在编写能够通过测试的实现代码。那么这些还不具备实现代码的新测试未能通过,又该怎么办? 虽然可以继续编写这些测试,但现在却不能让测试框架运行这些测试。幸运的是大部分测试框架使用了命名习惯来自动发现测试。比如,当用 Java 使用 JUnit 时,以“test”开头的方法(比如testMyThing)将作为测试来运行;所有需要做的事情就是把方法命名为别的,然后等你准备好了要来运行它时再改回来。如果把进行中的测试命名为“pendingTestMyThing”,那么不仅测试框架现在会忽略它,而且还能通过在所有代码中搜索字符串“pendingTest”来轻易寻找到漏掉的所有测试。当然,代码必须能编译通过;如果还不能,那么应当注释掉那些无法编译的部分。 无论如何,要避免养成忽略“失败的测试结果”的习惯。 用 JUnit 写测试真正所需要的就三件事: 1. 一个 import 语句引入所有 junit.framework.*下的类。 许多 IDE 至少会提供这些。这样写出来的类能够使用 JUnit 的 test runner 运行,并且自动执行类中所有 test 方法。 但是有时不从 JUnit 的 runner 运行,而是能够直接运行一个测试类会更方便一些。而且每个测试运行前和后的方法名又是什么? 可以制作一个骨架来提供所有这些特性并且做得相当简单。 对于测试而言,首要的也是最明显的任务就是查看所期望的结果是否正确——验证结果。 通常一些简单的测试,甚至这类测试的一部分在需求说明中都已经指定了。如果文档中没有的话,那么就需要问问其他人员。总之,必须能够最终回答这个关键问题。 如果代码能够运行正确,要怎么才知道它是正确的呢 如果不能很好的回答这个问题,那么编写代码——或者测试——完全就是在浪费时间。试想,如果文档比较晦涩或者不完整的话,该怎么办呢?这是否意味着不能编写代码,而必须等到文档都已经齐备且清楚时才能继续编写代码呢? 不是,完全不是。如果文档真的还不明了,或者不完整的话,至少总是可以自己发明出一些需求来。虽然从用户的角度来看,这些功能或许是不准确的,但是现在就可以知道编写的代码要做什么,从而能够回答上面的问题。 ● 使用数据文件 对于许多有大量测试数据的测试,可能会考虑用一个独立的数据文件来存储这些测试数据,然后让单元测试读取该文件。这并不困难——甚至并不需要使用 XML 文件。以下代码是 TestLargest的一个版本,它从一个测试文件中读取所有的测试数据。 数据文件的格式很简单:每行一些数字,其中第一个数字是期望的答案,剩余的数字就是要用来测试的参数。另外,使用井号(#)来表示所在行是注释,因此可以在测试文件中添加一些有意义的注释或者描述。 测试文件的具体形式如下: 如果上面的例子一样只有很少的东西要测试。也许就不值得费这么大的劲了。但是假如面对的是一个很复杂的应用程序,而表格中有几百个甚至几千个测试数据,那么测试文件就是一个很有吸引力的选择。 多注意一下测试数据。不管文件中的还是代码中的测试数据,都很有可能是不正确的。实际上,经验告诉我们,测试数据比代码更有可能是错的,特别是人工计算的,或者来自原由系统计算结果的测试数据(系统添加的新特性,可能故意导致了不同结果)。因此,当测试数据显示有错误发生的时候,应该在怀疑代码前先对测试数据检查两三遍。 一个原则是:对于验证被测方法是正确的这件事情,如果某些做法能够使它变得更加容易,那么就采纳它吧。 在前面“求最大值”的例子中,发现了几个边界条件:最大值位于数组末尾,数组包含负数,或者数组为空等等。 完全伪造或者不一致的输入数据,例如一个名为 “!*W : X&Gi/W~>g/h#WQ@”的文件。 个想到可能的边界条件的简单办法就是记住助记短语 CORRECT。对于其中的每一条,都应该想想它是否与存在于被测方法中的某个条件非常类似,而当这些条件被违反时,出现的又是什么情形: Conformance (一致性)—— 值是否和预期的一致。 对于一些方法,可以使用反向的逻辑关系来验证它们。例如,可以用对结果进行平方的方式来检查一个计算平方根的函数,然后测试结果是否和原数据很接近; 类似地,为了检查某条记录是否成功地插入了数据库,也可以通过查询这条记录来验证,等等。 同样可以使用其他手段来交叉检查函数的结果。 通常而言,计算一个量会有一种以上的算法。可能会基于运行效率或者其它的特性来选择算法。那是要在产品中使用的;但是在测试用的系统中,可以使用剩下算法中的一个来交叉测试结果。当确实存在一种经过验证并能完成任务的算法,只是由于速度太慢或者太不灵活而没有在产品代码中使用时,这种交叉检查的技术是非常有效。 我们可以充分利用一些比较弱的版本来检查我们新写的超级漂亮的版本,看它们是否产生了相同的结果: 另外一种办法就是:使用类本身不同组成部分的数据,并且确信它们能“合起来”。例如,假设正在做一个图书馆的数据系统。在这个系统中,对于每一本具体的书,它的数量永远是平衡的。也就是说,借出的数加上躺在架子上的库存数应当永远等于总共所藏的书籍数量,这些就是数据的两个分开的不同组成部分(借出数和库存数)。它们甚至可以由不同类的对象来汇报它们,但是它们仍然必须遵循上面的约束(即平衡,总数恒定)。因而可以在它们之间进行交叉检查,即用一种数量检查另一种数量。 在真实世界中,错误总是会发生的:磁盘会满、网络连线会断开、电子邮件会多得像掉进了黑洞,而程序会崩溃。应当能够通过强制引发错误,来测试自己的代码是如何处理所有这些真实世界中的问题的。 下面是一些我们能想到的可以用来测试我们的函数的环境方面的因素: 内存耗光。 系统过载。 我们想要的是一个性能特性的快速回归测试。很多时候,也许发布的第一个版本工作正常,但是第二个版本不知道为何变得很慢。我们不知道为什么,也不知道改变了什么,或者什么时候谁干的,几乎一切都是未知的。而最终用户绝对不会轻易放过你。 为了避免这种尴尬的场景发生,可以考虑实现一些粗糙测试来确保性能曲线能够保持稳定。例如,假设已经编写了一个过滤器,它能够鉴别希望阻止的 Web 站点。 那段代码在几十个样板站点上都工作正常,但要是 10 000 个呢?100 000 个呢?让我们写点单元测试来看看吧。 这给了我们一些保证,保证我们仍然满足了性能方面的要求。但是运行这一个测试就花去了 6-7秒钟,所以可能不想每次都运行它。因此,只要每晚或者每隔几天运行它一次,就能快速地定位到我们可能引入的任何问题,而此时仍然有时间来修正它们。 也许需要一些测试辅助工具。它们能够提供对耽搁测试进行记时,模拟高负载情况之类的功能,比如免费的 JUnitPerf。 通过前面的学习,我们已经掌握了 JUnit 的基本使用方法,下面利用它对一个具体的实例进行测试。 本例使用 Eclipse 中的 JUnit 工具建立测试。打开 Eclipse,建立一个新的工程的工作空间,输入工程名称,比如 ProjectWithJUnit,点击完成。这样就建立了一个新工程,配置一下 Eclipse,把 JUnit library 添加到 build path,点击 Project–>Properties,选择 Java Build Path Libraries,再点击 AddExteranal JARs 选中 JUnit.jar,可以看到 JUnit 将会出现在屏幕上 libraries 列表中,点击 Okay,Eclipse 为了方便起见,假定将要写的类名是 HelloWorld 有一个返回字符串的方法 say()。建立这样一个 test,在 ProjectWithJUnit 标题上点右键,选择 New -> Other,展开“Java”,选择 JUnit 里面的 JUnitTest Case 选项,接着点 Next,参见图 6.3。 在 Class under test 一栏里输入需要测试的类名 HelloWorld。接下来,在工程 ProjectWithJUnit 中新建一个名为 TestThatWeGetHelloWorldPrompt 的类,用来测试类 HelloWorld,点 Finish 完成。 下面是 TestThatWeGetHelloWorldPrompt.java 的代码: 这个代码继承了 JUnit 的 TestCase,TestCase 在 JUnit 的 javadoc 里的定义是用来运行多个 Test的固定装置。JUnit 也定义了 TestSuite 由一组关联的 TestCase 组成。 通过以下两步来建立简单的 Test Case: (a)建立 Junit.framework.TestCase 的实例。 (b)定义一些以 test 开头的测试函数,并且返回一空值。 TestThatWeGetHelloWorldPrompt.java 同时遵循这些标准。这些 TestCase 的子类含有一个 testSay()的方法。这个方法由assertEquals()方法调用,用于检验 say()的返回值。 主函数 main()是用来运行 test 并且显示输出的结果。JUnit 的 TestRunnery 以图形(swing. ui)和本文(text.ui)的方式来执行 test 并反馈信息。使用文本(text.ui)方式 Eclipse 肯定支持。所谓文本和图形,是指建立 TestCase 的时候,有一个选项 Which method stubs would you like to create,选择text.ui|| swing.ui||awt.ui,一般是选择 text.ui。依照这些文本的信息,Eclipse 同时会生成图形显示。 一旦运行了 test,应该看到返回一些错误的信息。点 Run-> Run as -> JUnit Test,可以看到 JUnit窗口会显示出一个红色条,表示是一个失败的 test,如图 6.4。 现在正式开始建立用于工作的 HelloWorld 代码,点 New->Class,代码如下 现在再来测试一下看看结果,点 Run-> Run As JUnit,在 JUnit 窗口中出现了一个绿条,表示测试通过,如图 6.5。 现在,再变个条件让测试不通过。这将帮助我们理解 JUnit test 是怎样覆盖并且报出不同错误的。编辑 assertEquals()方法,把它的返回值从“Hello World!”变成另外一个值比如“Hello ME!”。这样, Selenium 提供了 8 种定位方式。 这 8 种定位方式在 Python selenium 中所对应的方法为: find_element_by_id() 假如我们有一个 Web 页面,通过前端工具(如,Firebug)查看到一个元素的属性是这样的。 我们的目的是要定位 input 标签的输入框。 通过 id 定位: 通过 css 定位,css 定位有 N 种写法,这里列几个常用写法: 接下来,我们的页面上有一组文本链接。 通过 link text 定位 通过 link text 定位: 有时候我们希望能以某种浏览器尺寸打开,让访问的页面在这种尺寸下运行。例如可以将浏览器设置成移动端大小(480* 800),然后访问移动站点,对其样式进行评估;WebDriver 提供了set_window_size()方法来设置浏览器的大小。 在 PC 端执行自动化测试脚本大多的情况下是希望浏览器在全屏幕模式下执行,那么可以使用maximize_window()方法使打开的浏览器全屏显示,其用法与 set_window_size() 相同,但它不需要参数。 在使用浏览器浏览网页时,浏览器提供了后退和前进按钮,可以方便地在浏览过的网页之间切换,WebDriver 也提供了对应的 back()和forward()方法来模拟后退和前进按钮。下面通过例子来演示这两个方法的使用。 为了看清脚本的执行过程,下面每操作一步都通过 print()来打印当前的 URL 地址。 有时候需要手动刷新(F5) 页面。 driver.refresh() #刷新当前页面 前面我们已经学习了定位元素,定位只是第一步,定位之后需要对这个元素进行操作,或单击(按钮) 或输入(输入框) ,下面就来认识 WebDriver 中最常用的几个方法: submit()方法用于提交表单。例如,在搜索框输入关键字之后的“回车” 操作,就可以通过该方法模拟 有时候 submit()可以与 click()方法互换来使用,submit()同样可以提交一个按钮,但 submit()的应用范围远不及 click()广泛。 size:返回元素的尺寸。 输出结果 执行上面的程序并查看结果:size 方法用于获取百度输入框的宽、 高,text 方法用于获得百度底部的备案信息,get_attribute()用于获得百度输入的 type 属性的值,is_displayed()用于返回一个元素是否可见,如果可见则返回 True,否则返回 False。 在 WebDriver 中,将这些关于鼠标操作的方法封装在 ActionChains 类提供。 Keys()类提供了键盘上几乎所有按键的方法。前面了解到, send_keys()方法可以用来模拟键盘输入, 除此 之外, 我们还可以用它来输入键盘上的按键, 甚至是组合键, 如 Ctrl+A、 Ctrl+C 等。 需要说明的是, 上面的脚本没有什么实际意义, 仅向我们展示模拟键盘各种按键与组合键的用法。 在使用键盘按键方法前需要先导入 keys 类。 不管是在做功能测试还是自动化测试,最后一步需要拿实际结果与预期进行比较。这个比较的称之为断言。 我们通常可以通过获取 title 、URL 和 text 等信息进行断言。text 方法在前面已经讲过,它用于获取标签对之间的文本信息。下面同样以百度为例,介绍如何获取这些信息。 脚本运行结果如下: Before search================ title:用于获得当前页面的标题。 WebDriver 提供了两种类型的等待:显式等待和隐式等待。 显式等待使 WebdDriver 等待某个条件成立时继续执行,否则在达到最大时长时抛出超时异常(TimeoutException)。 WebDriverWait 类是由 WebDirver 提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。具体格式如下: driver:浏览器驱动。 调用该方法提供的驱动程序作为一个参数,直到返回值为 True。 until_not(method, message=‘’) 调用该方法提供的驱动程序作为一个参数,直到返回值为 False。 在 本 例 中 , 通 过 as 关 键 字 将 expected_conditions 重 命 名 为 EC , 并 调 用presence_of_element_located()方法判断元素是否存在。 WebDriver 提供了 implicitly_wait()方法来实现隐式等待,默认设置为 0。它的用法相对来说要简单得多。 implicitly_wait() 默认参数的单位为秒,本例中设置等待时长为 10 秒。首先这 10 秒并非一个固定的等待时间,它并不影响脚本的执行速度。其次,它并不针对页面上的某一元素进行等待。当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它将以轮询的方式不断地判断元素是否被定位到。假设在第 6 秒定位到了元素则继续执行,若直到超出设置时长(10 秒)还没有定位到元素,则抛出异常。 WebDriver 还提供了 8 种用于定位一组元素的方法。 定位一组元素的方法与定位单个元素的方法类似,唯一的区别是在单词 element 后面多了一个s 表示复数。 在 Web 应用中经常会遇到 frame/iframe 表单嵌套页面的应用,WebDriver 只能在一个页面上对元素识别与定位,对于 frame/iframe 表单内嵌页面上的元素无法直接定位。这时就需要通switch_to.frame()方法将当前定位的主体切换为 frame/iframe 表单的内嵌页面中。 126 邮箱登录框的结构大概是这样子的,想要操作登录框必须要先切换到 iframe 表单。 switch_to.frame() 默认可以直接取表单的 id 或 name 属性。如果 iframe 没有可用的 id 和 name属性,则可以通过下面的方式进行定位。 除此之外,在进入多级表单的情况下,还可以通过 switch_to.default_content()跳回最外层的页面。 在页面操作过程中有时候点击某个链接会弹出新的窗口,这时就需要主机切换到新打开的窗口上进行操作。WebDriver 提供switch_to.window()方法,可以实现在不同的窗口之间切换。以百度首页和百度注册页为例,在两个窗口之间的切换如下图。 在 WebDriver 中处理 JavaScript 所生成的 alert、confirm 以及 prompt 十分简单,具体做法是使用 switch_to.alert 方法定位到 alert/confirm/prompt,然后使用 text/accept/dismiss/ send_keys 等方法进行操作。 text:返回 alert/confirm/prompt 中的文字信息。 如下图,百度搜索设置弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to_alert()方法接受这个弹窗。 通过 switch_to_alert()方法获取当前页面上的警告框,并使用 accept()方法接受警告框。 ### 7.13 下拉框选择 有时我们会碰到下拉框,WebDriver 提供了 Select 类来处理下拉框。如百度搜索设置的下拉框,如下图: Select 类用于定位 select 标签。 对于通过 input 标签实现的上传功能,可以将其看作是一个输入框,即通过 send_keys()指定本地文件路径的方式实现文件上传。 通过浏览器打开 upfile.html 文件。 有时候我们需要验证浏览器中 cookie 是否正确,因为基于真实 cookie 的测试是无法通过白盒和集成测试进行的。WebDriver 提供了操作Cookie 的相关方法,可以读取、添加和删除 cookie 信息。 WebDriver 操作 cookie 的方法: 下面通过 get_cookies()来获取当前浏览器的 cookie 信息。 从执行结果可以看出,cookie 数据是以字典的形式进行存放的。知道了 cookie 的存放形式,接下来我们就可以按照这种形式向浏览器中写入 cookie 信息。 从执行结果可以看到,最后一条 cookie 信息是在脚本执行过程中通过 add_cookie()方法添加的。通过遍历得到所有的 cookie 信息,从而找到 key 为“name”和“value”的特定 cookie 的 value。 虽然 WebDriver 提供了操作浏览器的前进和后退方法,但对于浏览器滚动条并没有提供相应的操作方法。在这种情况下,就可以借助JavaScript 来控制浏览器的滚动条。WebDriver 提供execute_script()方法来执行 JavaScript 代码。 window.scrollTo(0,450) window.scrollTo()方法用于设置浏览器窗口滚动条的水平和垂直位置。方法的第一个参数表示水平的左间距,第二个参数表示垂直的上边距。其代码如下: 通过浏览器打开百度进行搜索,并且提前通过 set_window_size()方法将浏览器窗口设置为固定宽高显示,目的是让窗口出现水平和垂直滚动条。然后通过 execute_script()方法执行 JavaScripts 代码来移动滚动条的位置。 自动化用例是由程序去执行的,因此有时候打印的错误信息并不十分明确。如果在脚本执行出错的时候能对当前窗口截图保存,那么通过图片就可以非常直观地看出出错的原因。WebDriver 提供了截图函数get_screenshot_as_file()来截取当前窗口。 脚本运行完成后打开 D 盘,就可以找到 baidu_img.jpg 图片文件了。 在前面的例子中我们一直使用 quit()方法,其含义为退出相关的驱动程序和关闭所有窗口。除
(2)如果恰好有两条边相等,则程序的输出是等腰三角形。
(3)如果没有两条边相等,则程序输出的是不等边三角形。
(4)如果 c4、c5 和 c6 中有一个条件不满足,则程序输出的是非三角形。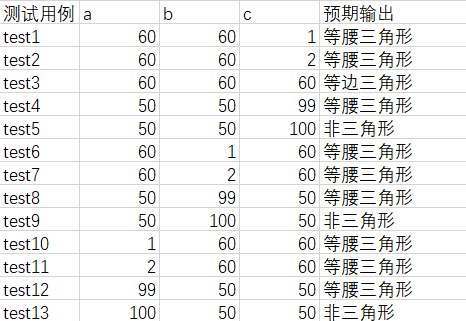
表 3.2 NextDate 函数的边界分析测试用例
3.2.4边界值分析局限性
边界值分析对布尔变量和逻辑变量没有多大意义。例如布尔变量的极值是 TRUE 和 FALSE,但是其余三个值不明确。我们在后面章节可以看到,布尔变量可以采用基于决策表的测试
3.3等价类测试
3.3.1 等价类
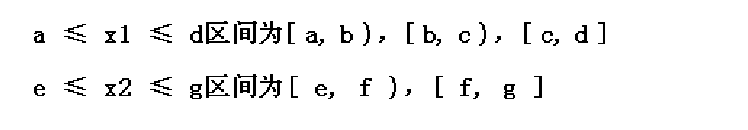
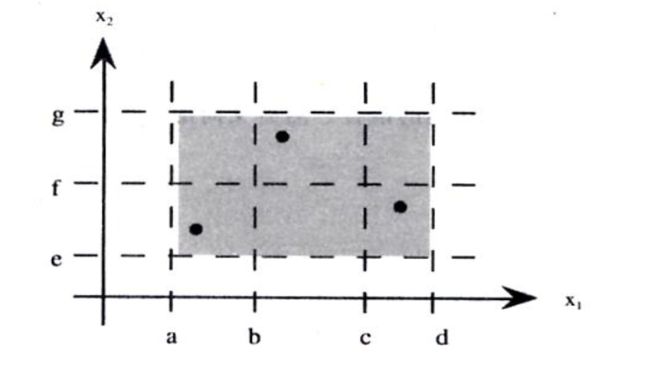
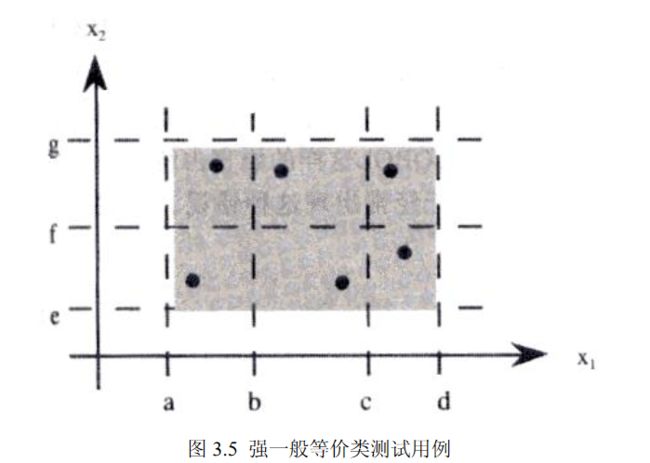
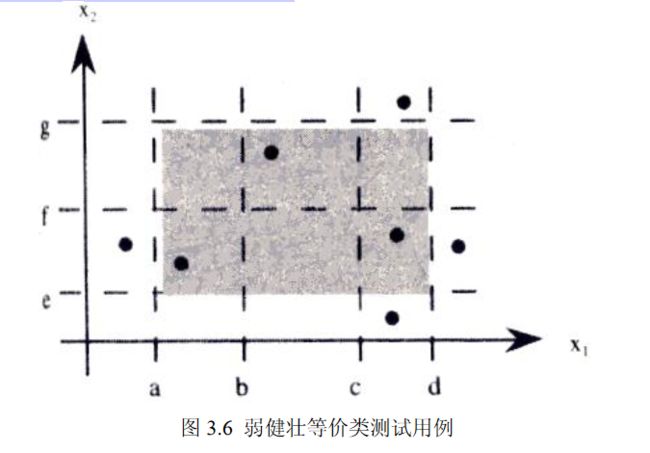
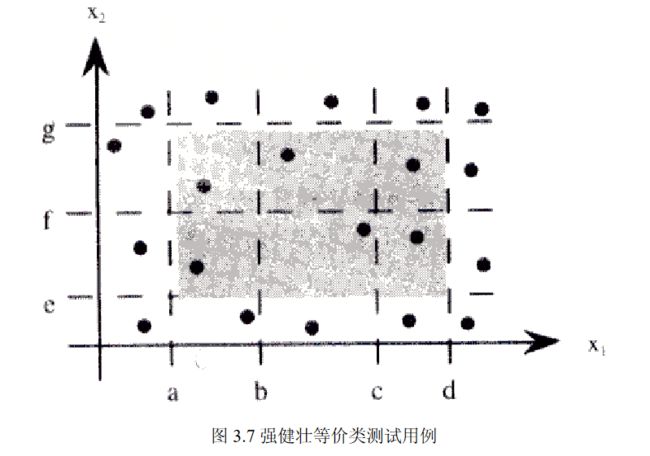
3.3.2等价类测试实例
和等边三角形。可以使用这些输出,标识如下所示的输出(值域)等价类:
R2={
R3={
R4={

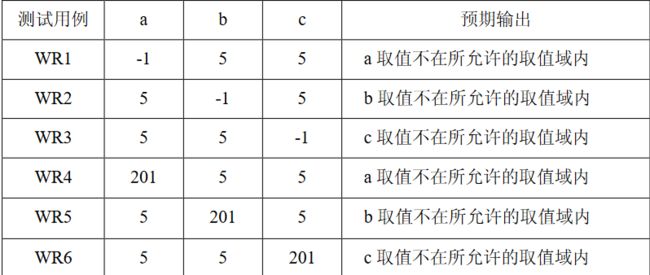
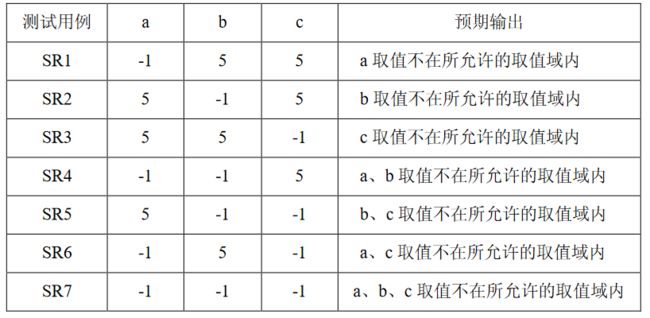
D2={
D3={
D4={
D5={
D8={
D6′′={
D1={日期:1≤月份≤31}
Y1={年:1812≤月份≤2012}
M3={月份:月份>12}
D2={日期:日期<1}
D3={日期:日期>31}
Y2={年:年<1812}
Y3={年:年>2012}
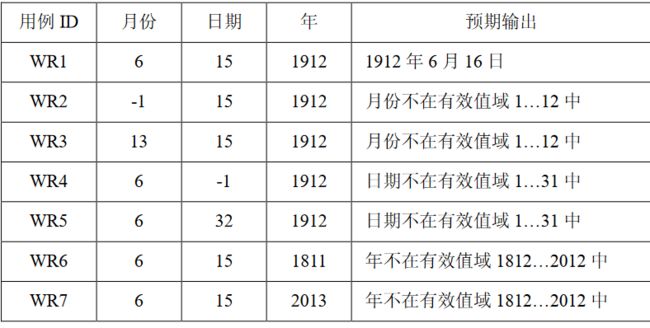
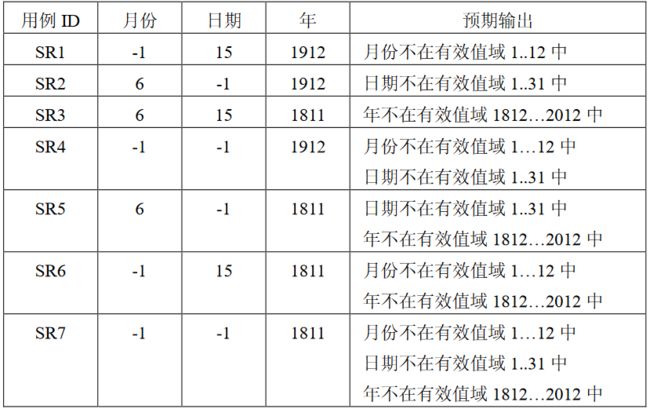
有以下等价类:
M2={月份:每月有 31 天}
M1={月份:此月是 2 月}
D1={日期:1≤日期≤28}
D2={日期:日期=29}
D3={日期:日期=30}
D4={日期:日期=31}
Y1={年:年=2000}
Y2={年:年是闰年}
Y3={年:年是平年}

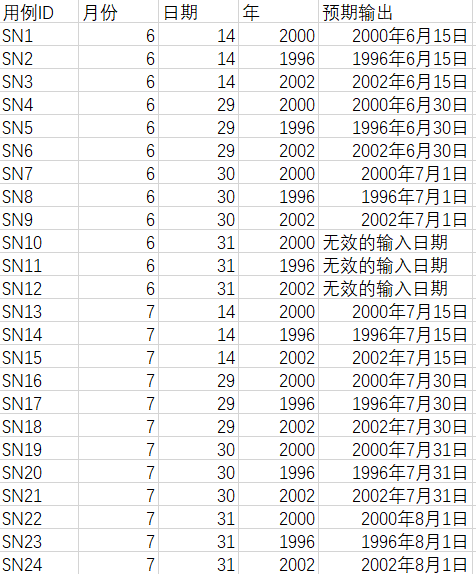
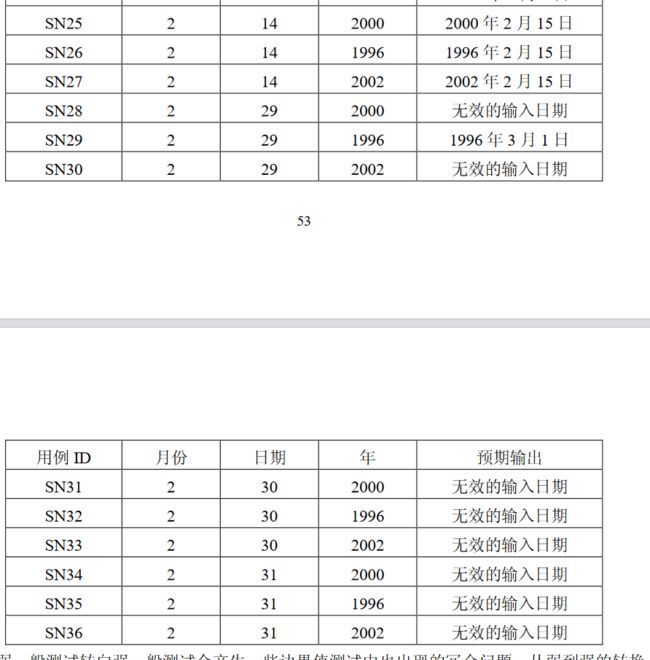
托(stock)和枪管(barrel)。枪机卖 45 美元,枪托卖 30 美元,枪管卖 25 美元。销售商每月至少要
售出一支完整的步枪,且生产限额是大多数销售商在一个月内可销售 70 个枪机、80 个枪托和 90 个
枪管。每访问一个镇子之后,销售商都给密苏里州步枪制造商发出电报,说明在那个镇子中售出的
枪机、枪托和枪管数量。到了月末,销售商要发出一封很短的电报,通知-1 个枪机被售出。这样
步枪制造商就知道当月的销售情况,并计算销售商的佣金如下:销售额不到(含)1000 美元的部分为 10%,1000(不含)~1800(含)美元的部分为 15%,超过 1800 美元的部分为 20%。佣金程序生成月份销售报告,汇总售出的枪机、枪托和枪管总数,销售商的总销售额以及佣金。
佣金问题的输入定义域,由于枪机、枪托和枪管的限制而被“自然地”划分。这些等价类也正是通过传统等价类测试所标识的等价类。第一个类是有效输入,其他两个类是无效输入。在佣金问题中,仅考虑输入定义域等价类产生的测试用例集合非常不能令人满意。通过进一步分析,我们能够
发现对佣金函数的输出值域定义等价类可以有效改进测试用例集合。
L1={枪机:1≤枪机≤70}
L2={枪机=-1}
S1={枪托:1≤枪托≤80}
B1={枪管:1≤枪托≤90}
L3={枪机:枪机>70}
S2={枪托:枪托<1}
S3={枪托:枪托>80}
B2={枪管:枪管<1}
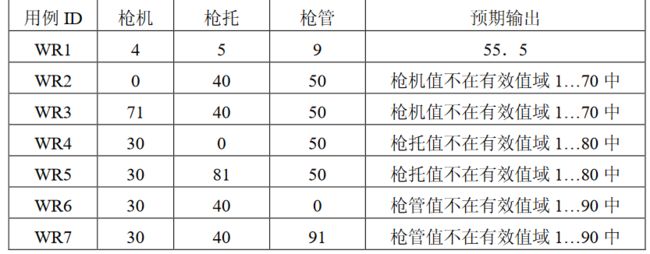
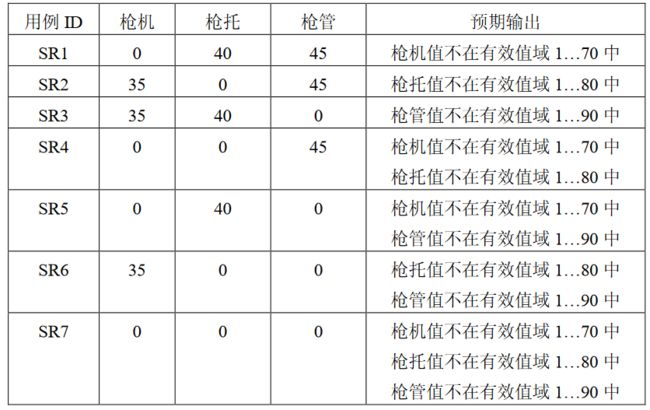
销售额是所售出的枪机、枪托和枪管数量的函数:
S2={<枪机,枪托,枪管>:1000<销售额≤1800}
S3={<枪机,枪托,枪管>:销售额>1800}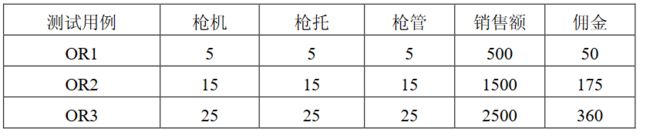
3.3.3 指导方针
6. 如果程序函数很复杂,则等价类测试是被指示的。在这种情况下,函数的复杂性可以帮助标识有用的等价类,就像 NextDate 函数一样。
7. 强等价类测试假设变量是独立的,相应的测试用例相乘会引起冗余问题。而如果存在依赖关系,则常常会生成“错误”测试用例,就像 NextDate 函数一样(此时最好采用决策表技术解决)。
8. 在发现“合适”的等价关系之前,可能需要进行多次尝试,就像 NextDate 函数例子一样。如果不能肯定存在“明显”或“自然”等价关系,最好对任何合理的实现进行再次预测。3.4基于决策表的测试
中,如果 c1、c2 和 c3 都为真,则采取行动 a1 和 a2。如果 c1 和 c2 都为真而 c3 为假,则采取行动a1 和 a3。在 c1 为真 c2 为假的条件下采取行动 a4,此时规则中的 c3 条目叫做“不关心”条目。不关心条目有两种主要解释:条件无关或条件不适用。
立有两种方式:一条边等于另外两条边的和,或严格大于另外两条边的和
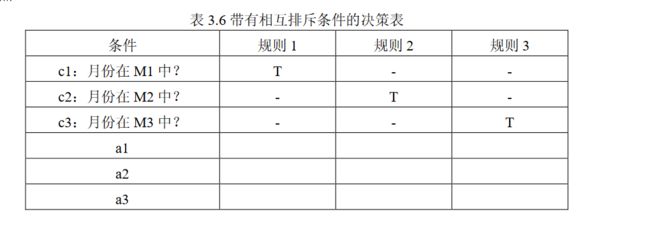
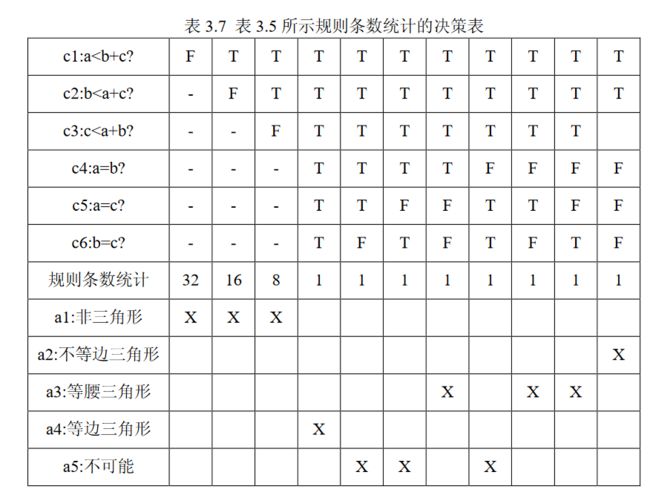
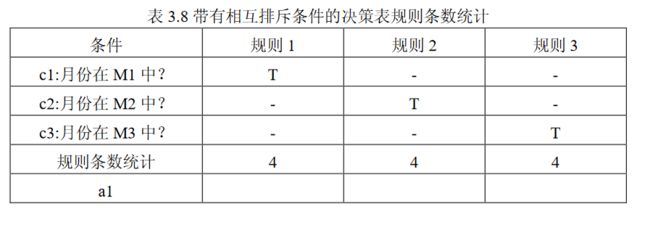
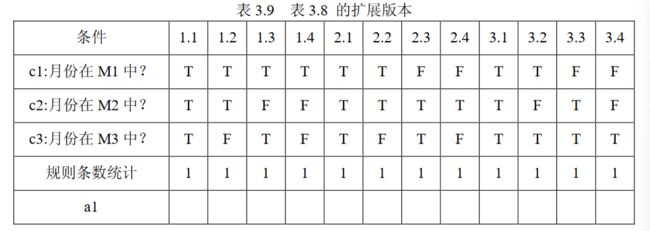
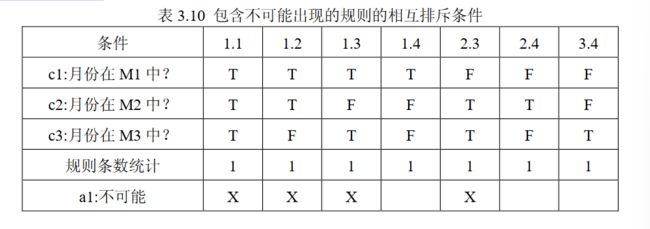
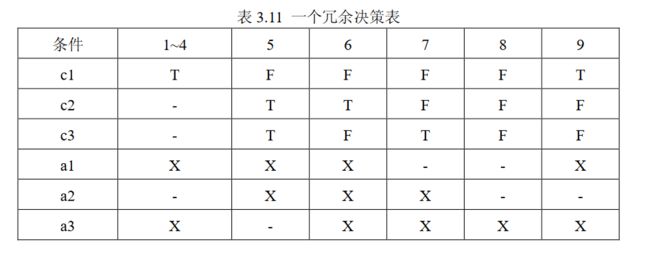
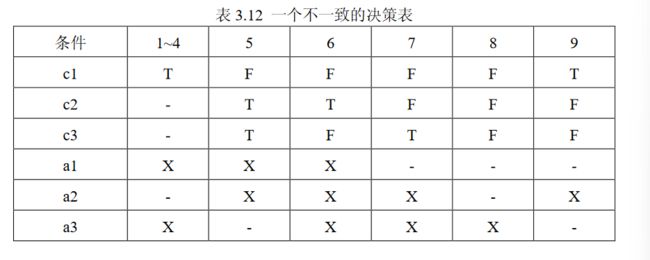
(2)决策表是非确定的。因为此时不能确定是应该应用规则 4 还是应用规则 9。
选三个测试用例(一条边正好等于另外两条边的和)。做到这一点需要做一定的判断,否则规则会呈指数级增长。在这种情况下,最终会再得到很多不关心条目和不可能的规则。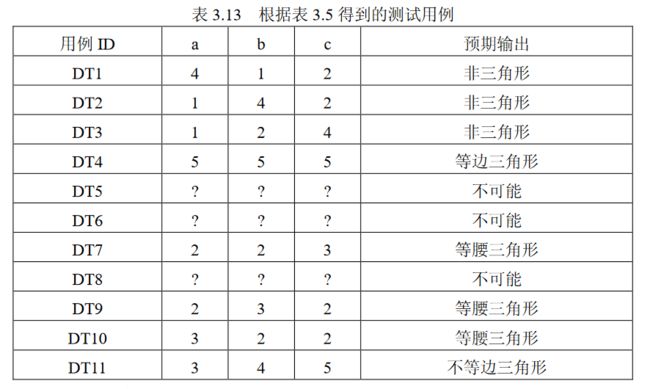
M4: { month: month 是 2 月 }
D1: { day: 1≤day≤27 }
D2: { day: day = 28 }
D3: { day: day = 29 }
D4: { day: day = 30 }
D5: { day: day = 31 }
Y1: { year: year 是闰年 }
Y2: { year: year 不是闰年 }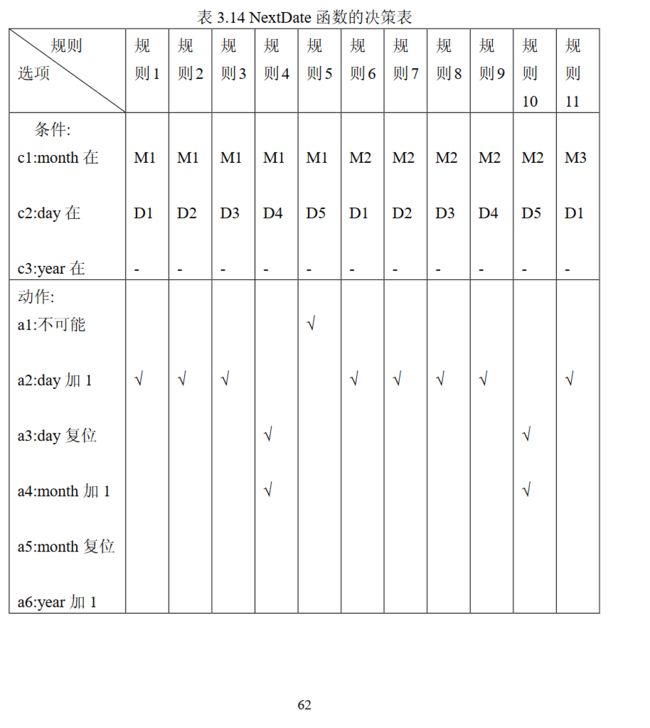
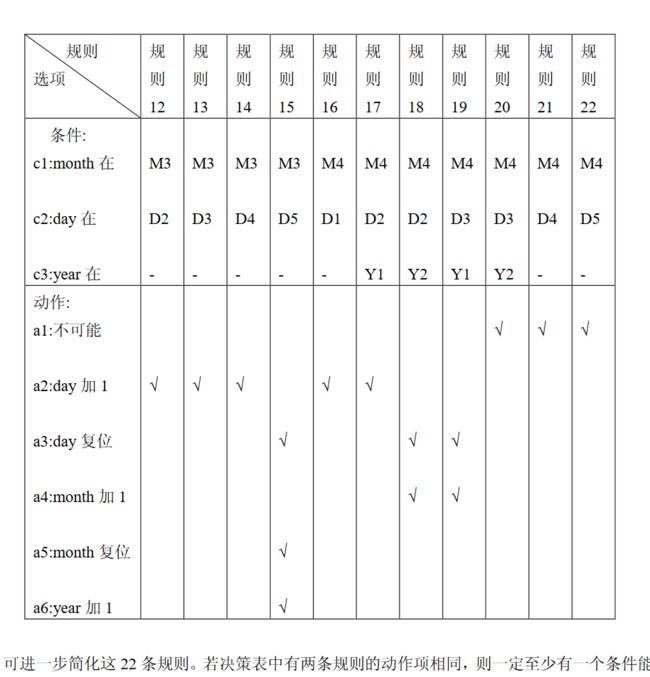
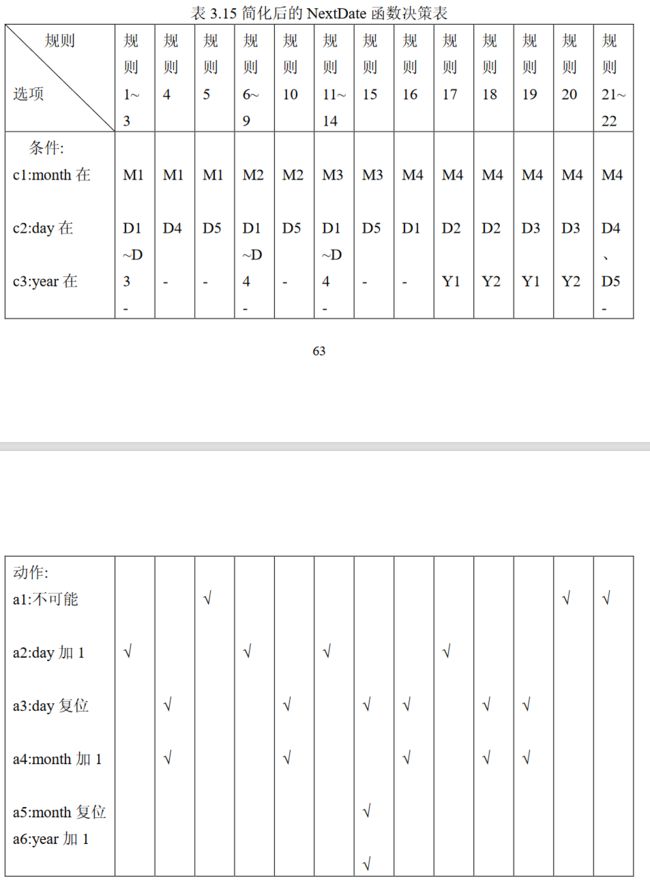
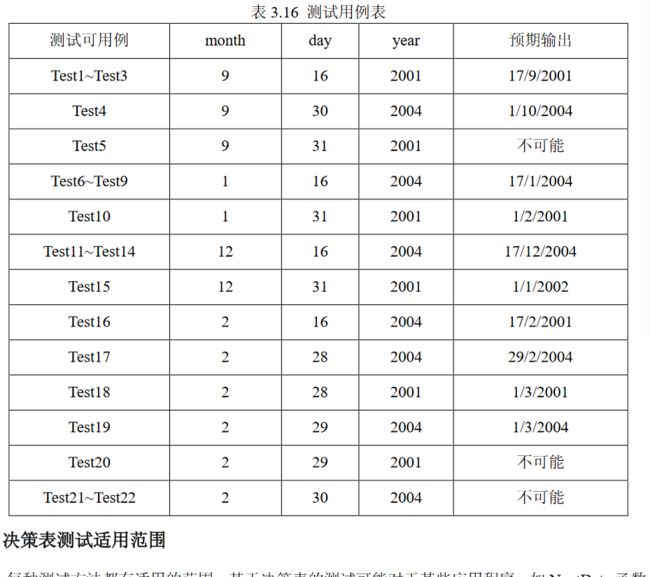
(1)if-then-else 逻辑突出;
(2)输入变量之间存在逻辑关系;
(3)涉及输入变量子集的计算;
(4)输入与输出之间存在因果关系。
在建立决策表的过程中不容易一步到位,第一次标识的条件和行动往往可能不那么令人满意。与其他技术一样,这时采用迭代会有所帮助。把第一次得到的结果作为铺路石,逐渐改进,直到得到满意的决策表。3.5错误推测法
第四章 白盒测试方法
(2)所有逻辑值均需测试真和假两种情况。
(3)检查程序的内部数据结构,保证其结构的有效性。
(4)在上下边界及可操作范围内运行所有循环。4.1白盒测试基本概念
(1)节点用带有标号的圆圈表示,可以代表一个或多个语句、一个处理框程序和一个条件判断框(假设不包含复合条件)。
(2)控制流线由带箭头的弧线或线表示,可称为边,它代表程序中的控制流。
常见语句的控制流图如图 4.1 所示。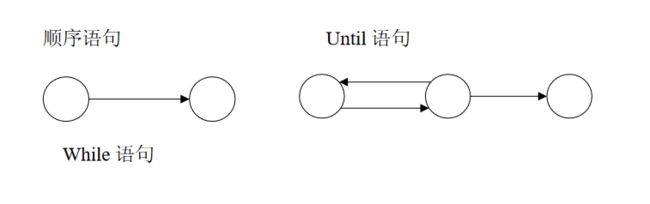
如果将一个典型的程序流程图转换为控制流图,转换结果如图 4.2 所示。
件的程序通路,它必须至少包含一条在本次定义路径之前不曾用过的边。路径可用流图中表示程序通路的节点序列表示,也可用弧线表示。
程序控制流图是一个有向图,如果图中任何两个结点之间都至少存在一条路径,这样的图称为强连通图。McCabe 提出,如果程序控制流图是一个强连通图,其复杂度 V(G)可按以下公式计算:V(G)=e-n+l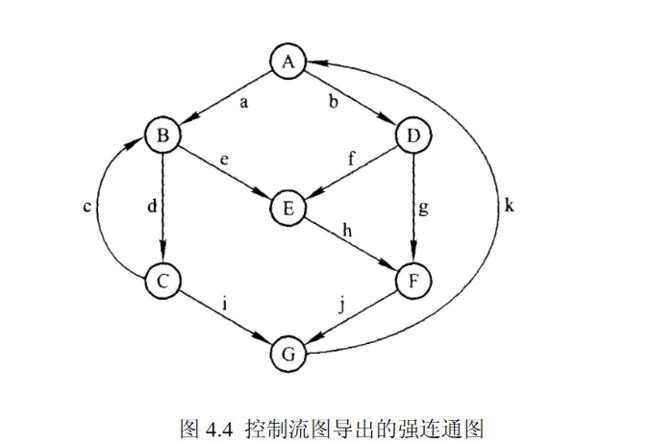
p2=A,B,C,B,C,G
p3=A,B,E,F,G
p4=A,D,E,F,G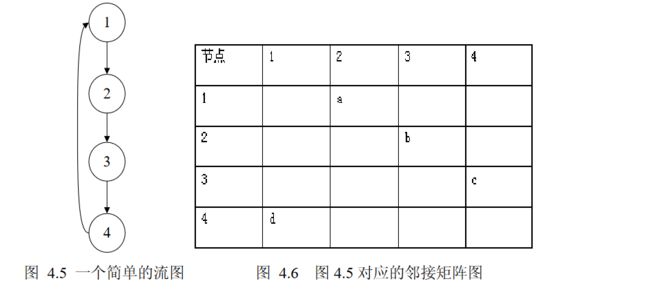
4.2逻辑覆盖
4.2.1逻辑覆盖标准
有以下一些不同的覆盖标准。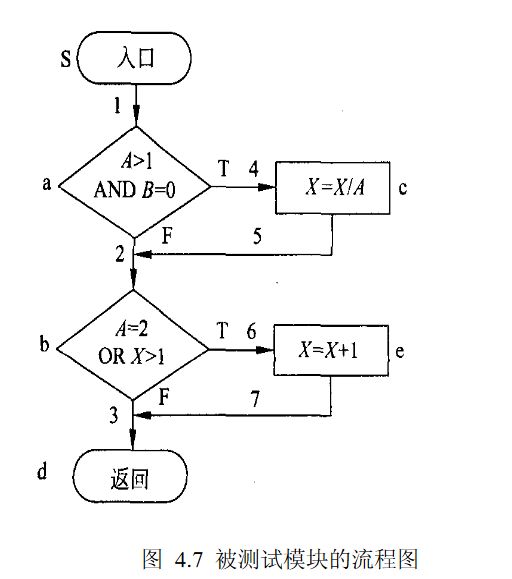
A = 2,B = 0, X = 4
II.A = 2, B = 1, X = 1 ( 覆盖 sabed)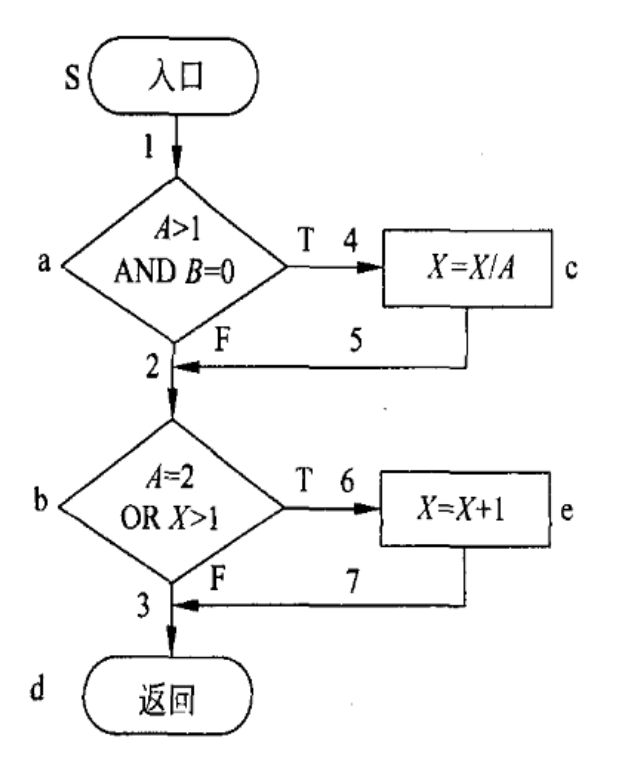
II.A = 1, B = 1, X = 1
( 针对 1,5 两种组合,执行路径 sacbed )
II.A = 2, B = 1, X = 1
( 针对 2,6 两种组合,执行路径 sabed )
III.A = 1, B = 0, X = 2
( 针对 3,7 两种组合,执行路径 sabed )
IV.A = 1, B = 1, X = 1
( 针对 4,8 两种组合,执行路径 sabd )
盖标准。
序因为遗漏路径而出现的错误;同时也发现不了一些与数据相关的错误。
由此看出,各种结构测试方法都不能保证程序的正确性。但是,测试的目的并不是要证明程序的正确性,而是要尽可能找出程序中隐藏的故障。事实上,并不存在一种十全十美的测试方法能够发现所有的软件故障。4.2.2 最少测试用例数计算
我们知道,结构化程序是由三种基本控制结构组成。这三种基本控制结构就是:顺序型——构成串行操作;选择型——构成分支操作;重复型——构成循环操作。
为了把问题化简,避免出现测试用例极多的组合爆炸,把构成循环操作的重复型结构用选择结构代替。也就是说,并不指望测试循环体所有的重复执行,而是只对循环体检验一次。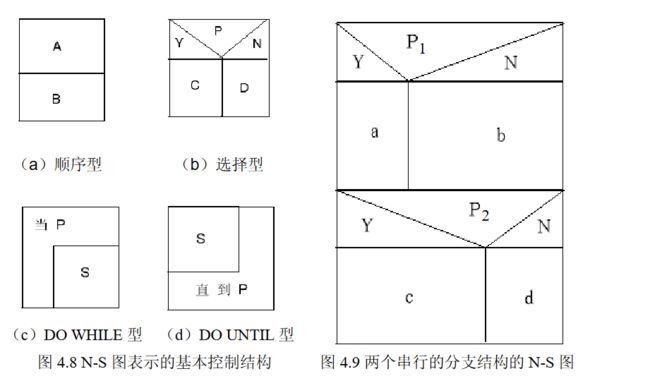
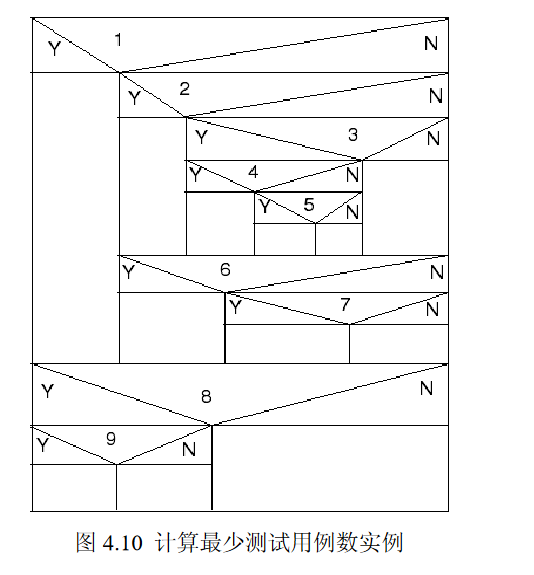
整个程序所需测试用例数至少为 6×3 = 48。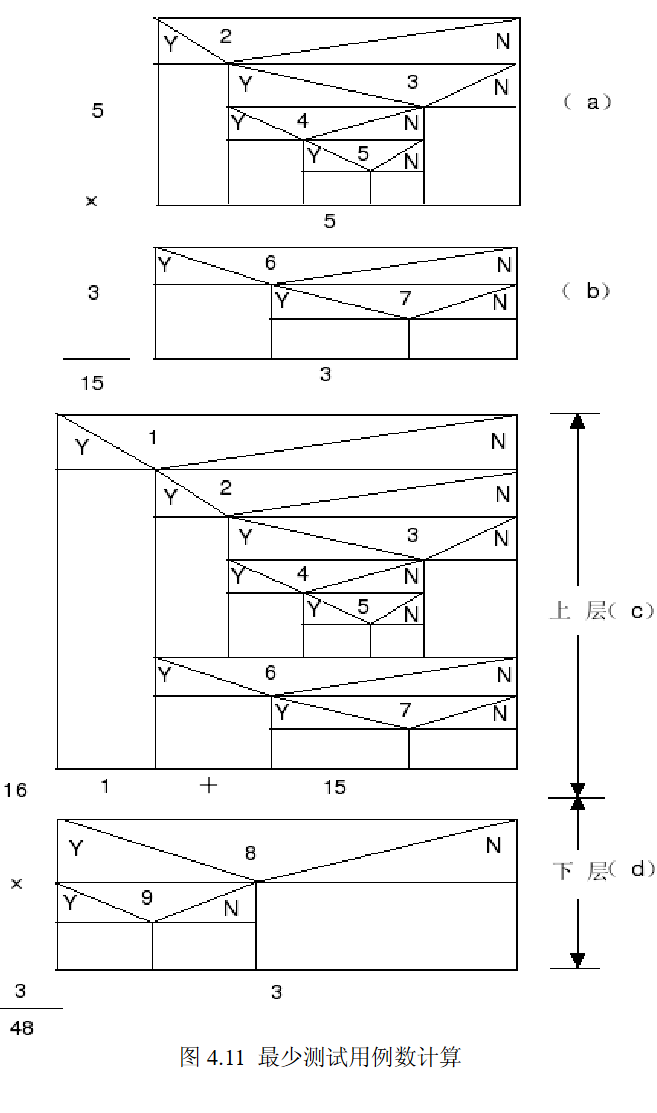
4.3独立路径测试
程序环路复杂性。借助 McCabe 复杂性度量,可以从程序的环路复杂性导出程序路径集合中的独立路径条数。
设计测试用例。确保独立路径集合中的每一条路径被执行。
(1)通过非路径分析得到测试用例测试人员凭经验设计测试用例或由应用系统本身提供测试用例。在使用这些测试用例执行被测程序后,一些路径就被检测过了。
(2)对未测试的路径生成相应的测试用例枚举被测程序所有可能的独立路径,并与前面已测试过的路径相比,便可得知哪些路径还没有被测试过,针对这些路径生成测试用例,进而完成对它们的测试。
(3)生成指定路径的测试用例根据指定的路径,生成相应的测试用例。
程序的路径可经枚举全部得到。
完成若干个测试用例后,对所测路径、未测路径是知道的。
在指出要测试的路径以后,可以自动生成相应的测试用例。4.4循环测试
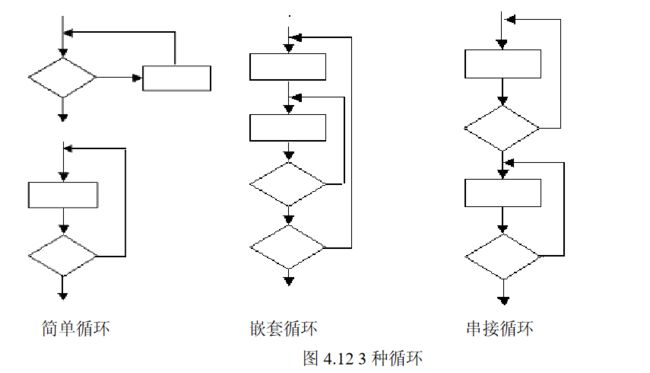
应该使用下列测试集来测试简单循环,其中,n 是允许通过循环的最大次数。
●跳过循环
●只通过循环一次
●通过循环两次
●通过循环 m 次,其中 m < n-1
●通过循环 n–1,n,n+1 次4.5面向对象的白盒测试
类测试一般有两种主要的方式:功能性测试和结构性测试,即对应于传统结构化软件的黑盒测试和白盒测试。
上应分别做到:
至不用附加数据,因为方法都是对类进行存取,故这一类测试的准则是要求遍历类的所有主要状态。4.6 其它白盒测试方法简介
的结构以后,会发现子空间的划分是由程序中分支语句中的谓词决定的。输入空间的一个元素,经过程序中某些特定语句的执行而结束(当然也可能出现无限循环而无出口),那都是满足了这些特定语句被执行所要求的条件的。
域测试正是在分析输入域的基础上,选择适当的测试点以后进行测试的。域测试有两个致命的弱点:一是为进行域测试对程序提出的限制过多,二是当程序存在很多路径时,所需的测试点也很多。
的结果自然是符号公式或是符号谓词。更明确地说,普通测试执行的是算术运算,符号测试则是执行代数运算。因此符号测试可以认为是普通测试的扩充。
想的情况是,程序中仅有有限的几条执行路径。如果对这有限的几条路径都完成了符号测试,就能较有把握地确认程序的正确性。
目前符号测试存在一些未得到圆满解决的问题,分别是:
X( I ) = 2 + A
X( J ) = 3
C = X( I )
行空间带来大幅度的增长,甚至使整个问题的解决遇到难于克服的困难。
多个循环,可能的路径数目将会急剧增长,达到天文数字,以至实现路径覆盖不可能做到。
图4.13中(a)和(b)表示了两种最典型的循环控制结构。前者先作判断,循环体B可能执行(假定只执行一次),也可能不执行。这就如同(c)所表示的条件选择结构一样。后者先执行循环体B(假定也执行一次),再经判断转出,其效果也与(c)中给出的条件选择结构只执行右支的效果一样。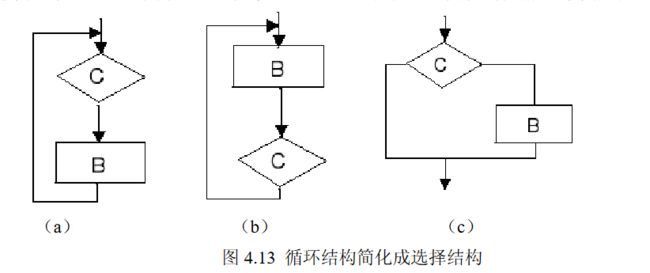
路径的测试用例,就可以做到 Z 路径覆盖测试。第 5 章 软件测试管理及自动化测试基础
5.1.1自动化测试含义
效率、覆盖率和可靠性的重要测试手段。也可以说,测试自动化是软件测试不可分割的一部分。
自动化测试将毫无差错地以同一方式多次运行同一测试。但是自动化测试不会执行与脚本编写的内容不一样的行为。正因为如此,自动化测试通常被看成为一系列的回归测试,只能捕获被引入原来工作代码的缺陷。不过事情也会出现例外,例如当大型数据数组循环输入。但是,可以肯定自
动化测试大都属于回归测试的范畴。5.1.2自动化测试意义
一定的局限性,例如:通过手工测试无法做到覆盖所有代码路径;简单的功能性测试用例在每一轮测试中都不能少,而且具有一定的机械性、重复性,其工作量往往较大,却无法体现手工测试的优越性;在系统负载、性能测试时,需要模拟大量数据或大量并发用户等各种应用场合时,很难通过手工测试来进行等。
由于手工测试的局限性,软件测试借助软件工具向自动化测试方向发展就显得极为必要。通过自动化测试,可以解决上述手工测试的局限性,带来以下的好处:5.1.3自动化测试局限性
\1. 软件自动化测试可能降低测试的效率。当测试人员只需要进行很少量的测试,而且这种测试在以后的重用性很低时,花大量的精力和时间去进行自动化的结果往往是得不偿失。因为自动化的收益一般要在很多次重复使用中才能体现出来。
\2. 测试人员期望自动测试发现大量的错误。测试首次运行时,可能发现大量错误。但当进行过多次测试后,发现错误的机率会相对较小,除非对软件进行了修改或在不同的环境下运行。
\3. 如果缺乏测试经验,测试的组织差、文档少或不一致,则自动化测试的效果比较差。
\4. 技术问题。毫无疑问商用软件自动测试工具是软件产品。作为第三方的技术产品,如果不具备解决问题的能力和技术支持或者产品适应环境变化的能力不强,将使得软件自动化工具的作用大大降低。
因此,我们对软件自动化测试应该有正确的认识,它并不能完全代替手工测试。不要期望仅仅通过自动化测试就能提高测试的质量,如果测试人员缺少测试的技能,那么测试也可能会失败。5.1.4测试工具
根据测试的对象和目的,分为单元测试工具、功能测试工具、负载测试工具、性能测试工具和测试管理工具等。
静态测试工具对代码进行语法扫描,找出不符合编码规范的地方,根据某种质量模型评价代码的质量,生成系统的调用关系图等。它直接对代码进行分析,不需要运行代码,也不需要对代码编译链接、生成可执行文件。
动态测试工具与静态测试工具不同,需要实际运行被测系统,并设置断点,向代码生成的可执行文件中插入一些监测代码,掌握断点这一时刻程序运行数据(对象属性、变量的值等)。单元测试工具多属于白盒测试工具。
除了上述的测试工具外,还有一些专用的测试工具,例如,针对数据库测试的 TestBytes,对应用性能进行优化的 EcoScope 等工具。5.2软件测试管理
有效地管理,确保测试工作顺利进行。
管理我们除了要考虑测试管理开始的时间、测试管理的执行者、测试管理技术如何有助于防止错误的发生、测试管理活动如何被集成到软件过程的模型中之外,还必须在测试之前,制订详细的测试管理计划,充分实现软件测试管理的主要功能,缩短测试管理的周期。5.2.1 软件测试管理计划
语言特征、结构特点、操作方法和特殊需求等,以便确定必要的测试环境,包括测试硬件、软件及测试环境的建立等等。而且,在测试管理计划中还应该制订一份详细的进度计划,如:测试管理的开始段、中间段、结束段及测试管理过程每个部分的负责人等。5.2.2软件测试管理过程
中能发现许多自己原来没有发现的错误,而讨论和争议则进一步促使了问题的暴露。5.2.3软件测试的人员组织
析员、软件设计人员、测试负责人员各一人。5.2.4 软件测试管理主要功能
以到案例库中查找类似问题的解决办法等等。5.2.5 软件测试管理实施
测试管理人员在接受一个测试管理任务后,除了要制定周密的测试管理计划。还要进行测试方案管理;并且对测试人员所做的测试活动予以记录,做好测试流程的管理。同时,对发现的缺陷予以标识,一方面反馈给提交测试的人员;另一方面将存在的问题和缺陷存入案例库,直至测试通过。
软件测试是一个完整的体系,主要由测试规划、测试设计、测试实施、资源管理等相互关联、相互作用的过程构成。软件测试管理系统可以对各过程进行全面控制。具体的实现过程如下:
\2. 建立、监测和分析软件测试过程,以有效地控制、管理和改进软件测试过程。监测软件质量,从而确定交付或发布软件的时间;
\3. 制定合理的软件测试管理计划,设计有效的测试案例集,以尽可能发现软件缺陷。并组织、管理和应用庞大的测试案例集;
\4. 在软件测试管理过程中,管理者、程序员、测试员(含有关客户人员)协同工作,及时解决发现软件问题;
\5. 对于软件测试中发现的大量的软件缺陷,进行合理的分类以分清轻重缓急。同时进行原因分析,并做好相应的记录、跟踪和管理工作;
\6. 建立一套完整的文档资料管理体系。因为软件测试管理很大程度上是通过对文档资料的管理来实现的。软件测试每个阶段的文档资料都是以后阶段的基础,又是对前面阶段的复审。5.2.6软件测试工具简介
对于每一件测试案例,它都会列出用户操作的顺序、案例描述、状态和预期的结果。这些信息都可以逐步填在一张校验表里并被记录在所有测试案例文件中。从而使测试过程更合理、统一。第6章 JUnit
6.1 Junit 概述
6.2.1 命令行安装
如果不使用 IDE,而是从命令行直接调用 JDK,那么必须让 CLASSPATH 包含 JUnit 的 jar 包所在的路径。
┕Settings
┕Control Panel
┕System
┕Advance Tab
┕Environment Variables . . .
Variable Value: C:\java\junit3.8.1\junit.jar6.2.2 检查是否安装成功
如果这样成功了,那么编译器就能找到 JUnit 了,也就是说一切都准备妥当了。
不要忘记测试代码需要在 JUnit 的 TestCase 基类继承而来。6.3 使用 JUnit 编写测试
6.3.1 构建单元测试
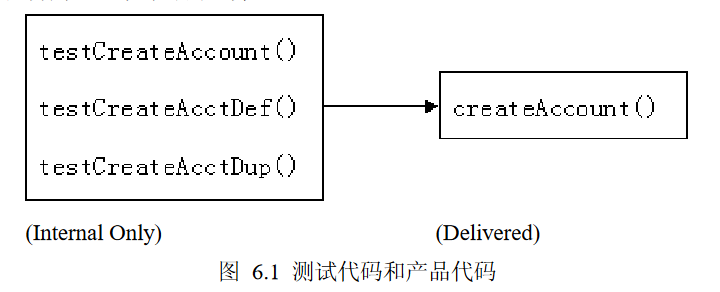
● 调用要测试的方法。
● 验证被测试方法的行为和期望是否一致。
● 完成后清理各种资源。
当执行测试代码的时候,从来不直接运用产品代码。至少,并非象一个普通用户那样。而是借助于测试代码,让它根据控制条件来执行产品代码。
我们将在例子中使用 Java 语言展示 JUnit 的一些习惯,但是一般性的概念对于任何语言或者环境的任何测试框架都是一样的。下面就看看 JUnit 特有的一些函数和类。6.3.2 JUnit 的各种断言
有这些函数统称为断言。可以确定:某条件是否为真;两个数据是否相等,或者不等,或者其它一
些情况。在接下来的内容中,将逐个介绍 JUnit 提供的每一个断言(assert)方法。
下面每个方法都会记录是否失败了(断言为假)或者有错误了(遇到一个意料外的异常)的情况,并且通过 JUnit 的一些类来报告这些结果。对于命令行版本的 JUnit 而言,这意味着将会在命令行控制台上显示一些消息。对于 GUI 版本的 JUnit 而言,如果出现失败或者错误,将会显示一个红色条和一些用于对失败进行详细说明的辅助消息。
当一个失败或者错误出现的时候,当前测试方法的执行流程将会被中止,但是(位于同一个测试类中的)其它测试将会继续运行。
assertEquals( [Sting message],
expected,
actual )
当执行测试代码的时候,从来不直接运用产品代码。至少,并非象一个普通用户那样。而是借
助于测试代码,让它根据控制条件来执行产品代码。
我们将在例子中使用 Java 语言展示 JUnit 的一些习惯,但是一般性的概念对于任何语言或者环
境的任何测试框架都是一样的。下面就看看 JUnit 特有的一些函数和类。
6.3.2 JUnit 的各种断言
JUnit 提供了一些辅助函数,用于帮助我们确定某个被测试函数是否工作正常。通常而言,把所
有这些函数统称为断言。可以确定:某条件是否为真;两个数据是否相等,或者不等,或者其它一
些情况。在接下来的内容中,将逐个介绍 JUnit 提供的每一个断言(assert)方法。
下面每个方法都会记录是否失败了(断言为假)或者有错误了(遇到一个意料外的异常)的情
况,并且通过 JUnit 的一些类来报告这些结果。对于命令行版本的 JUnit 而言,这意味着将会在命令
行控制台上显示一些消息。对于 GUI 版本的 JUnit 而言,如果出现失败或者错误,将会显示一个红
色条和一些用于对失败进行详细说明的辅助消息。
当一个失败或者错误出现的时候,当前测试方法的执行流程将会被中止,但是(位于同一个测
试类中的)其它测试将会继续运行。
断言是单元测试最基本的组成部分。因此 JUnit 程序库提供了不同形式的多种断言。
● assertEquals
assertEquals( [Sting message],
expected,
actual )
这是使用得最多的断言形式。在上面的参数中,expected 是期望值(通常都是硬编码的),actual是被测试代码实际产生的值,message 是一个可选的消息,如果提供的话,将会在发生错误的时候报告这个消息。当然,完全可以不提供这个 message 参数,而只提供 expected 和 value 这两个值。
expected,
actual,
tolerance)
位:
assertEquals(“Should be 3 1/3”,3.33,10.0/3.0,0.01);
assertNotNull([Sting message],java.lang.Object object)
验证一个给定的对象是否为 null(或者为非 null),如果答案为否,则将会失败。Message 参数是可选的。
验证 expected 参数和 actual 参数所引用的是否为同一个对象,如果不是的话,将会失败。Message参数是可选的:
assertNotSame([Sting message],expected,actual)
验证 expected 参数和 actual 参数所引用的是否为不同的对象,如果是相同的话,将会失败。Message 参数是可选的。
验证给定的二元条件是否为真,如果为假的话,将会失败。Message 参数是可选的。如果你发现测试代码象下面这样,宛如废话一般:
AssertTrue(true);那么就该好好想想这些代码了。对于这种写法,除非是被用于确认某个分支,或者异常逻辑才有可能是正确的选择;否则的话,很可能就是一个糟糕的主意。显然,怎么都不会愿意在一页代码
中看到只在该页的末尾出现许多 assertTrue(true) 语句(也就是说,只是为了确认代码能够运行到末尾,没有中途死掉,并以为它就必然工作正常了)。这哪里是测试,这简直就是一厢情愿的幻想。除了测试条件为真之外,也可以测试条件是否为假:assertFalse([Stingmessage],Boolean condition)上面代码用于验证给定的二元条件是否为假;如果不是的话(为真),该测试将会失败,message参数是可的。
修复一个又一个的测试,沿着这条路径慢慢前进。
为了遵循上面的这种原则,需要一种能够运行所有测试,或者一组测试,某个特殊子系统等等的辅助方法。6.3.3Junit框架
下面是一段简单的测试代码,它展示了开始使用的该框架的最小要求:import junnit.framework.*;
public class Testsimple extends TestCase{
public TestSimple(String name){
super(name);
}
public void testAdd(){
assertEquals(2,1+1);
}
}
当然,在测试方法中,是可以写多个断言的,像这样:
public void testAdds(){
assertEquals(2,1+14);
assertEquals(4,2+2);
assertEquals(-8,-12+4);
}
在此,一个测试方法里面使用了 3 个 assertEqual 断言。6.3.4 JUnit 测试的组成
import junit.framework.*;
public class TestClassOne extends TestCase{
public TestClassOne(String method){
super(method);
}
public void testAddition(){
assertEquals(4,2+2);
}
public void testSubtraction(){
assertEquals(0,2-2);
}
}
import junit.framework.*;
public class TestClassTow extends TestCase{
public TestClassTow(String method){
super(method);
}
//This one takes a few hours...
public void testlongRunner(){
TSP tsp=new TSP(); //Loadd with default cities
assertEquals(2300,tsp.shortestPath(5)); //top 50
}
public void testShortTest(){
TSP tsp=new TSP();//Load with default cities
assertEquals(140,tsp.shortestPath(5)); //top 5
}
public void testAnotherShortTest(){
TSP tsp= new TSP(); // Load with default cities
assertEquals(586,tsp.shortestPath(10)); //top 10
}
public static Test suite(){
TestSuite suite=new TestSuite();
//only include short tests
suite.addTest(
new TestClassTow(“testShortTest”));suite,addTest(
new TestClassTow(“testAnotherShortTest”));
return suite;
}
}
import joint.framework.*;
public class TestClassComposite extends TestCase{
public TestClassComposite(String method) {
super(method);
}
static public Test suite() {
TestSuite suite =new TestSuite();
//Grab everything:
suite.addTestSuite(TestClassOne.class);
//Use the suite method:
suite.addTest(TestClassTow.suite());
return suite;
}
}
● 来自 TestClassOne 的 testSuntraction()
● 来自 TestClassOne 的 testShortTest()
● 来自 TestClassOne 的 testAnotherShortTest()
protected void teardown();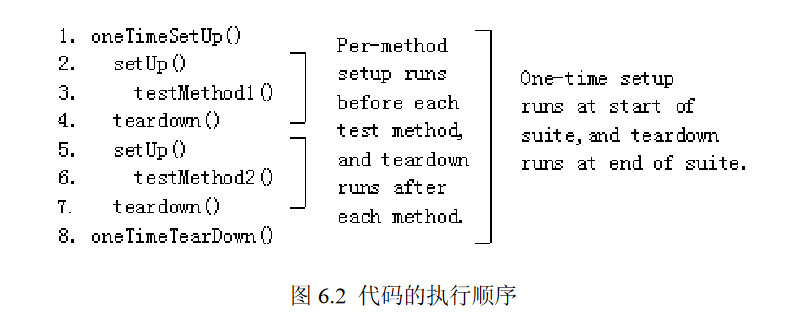
public class Test DB extends TestCase{
private connection dbConn;
protected void setup(){
dbConn =new Connection(“oracle”,1521,
“fred”,”foobar”);
dbConn.connect();
}
protected void teardown(){
dbConn.disconnect();
dbConn=null;
}
public void testAccountAccess() {
//Uses dbConn
xxx xxx xxxxxx xxx xxxxxxxxx;
xx xxx xxx xxxx x xx xxxx;
}
public void testEmployeeAccess() {
//Uses ddbConn
xxx xxx xxxxxx xxx xxxxxxxxx;
xxxx x x xx xxx xx xxxx;
}
}
import junit.framework.*;
import junit.extensions.*;
public class TestClassTow extends TestCase{
private static TSP tsp;
public TestClassTow (String method) {
super(method);
}
//This one takes a few hours...
public void testLongRunner() {
assertEquals(2300,tsp.shortestPath(50));
}
public void testShort Test() {
assertEquals(140,tsp.shortestPath(5));
}
public void testAnotherShortTest(){
assertEquals(586,tsp.shortestPath(10));
}
public static Test suite() {
TestSuite suite=new TestSuite ();
//only include short tests
suite.addTest(new TestClassTow(“testShortTest”));
suite.addTest(new TestClassTow (“testAnotherShortTest”));
TestSetup wrapper=new TestSetup(suite) {
protected void setUp() {
OoeTimeSetUp();
}
protected void tearDown() {
oneTimeTearDown();
}
};
return wrapper;
}
public static void onetimeSetUp() {
//one-time initialization code goes here...
tsp =new TSP();
tsp.loadCities(“EasternSeaboard”);
}
public static void oneTimeTearDown() {
//one-time cleanup code goes here...
tsp.releaseCities();
}
}
6.3.5 自定义 Junit 断言
如果有需要在整个项目中共享的断言或者公共代码,也许需要考虑从 TestCase 继承一个类并且使用这个子类来进行所有的测试。例如,假使在测试一个经济方面的程序并且事实上所有的测试都使用了名为 Money 的数据类型。不直接从 TestCase 继承,相反创建了一个项目特有的基础测试类:import junit.framework.*;
/**
*project-wide base class for Testing
*/
public class ProjectTest extends TestCase{
/**
*Assert that the amount of money is an even
*number of dollars (no cents)
*@param message Text message to display if the
* assertion fails
*@param amount Money object to test
*
*/
public void assertEvenDollars(String message,Money amount){
assertEquals(message,
amount.asDouble()-(int)amount.asDouble(),
0.0,
0.001);
}
/**
*Assert that the amount of money is an even
*
*@param amount Money object to test
*
*/
public void assertEvenDollars (Money amount) {
assertEvenDollars(“”,amount);
}
}
现在,项目中的所有其它测试类将从这个基类继承下来而不是直接从 TestCase 进行继承:public class TestSomething extends ProjectTest {
...
6.3.6Junit 和异常
如果传入参数是一个 null list,那么将希望该方法抛出一个异常。在这种情况下,就需要显式的测试这一点。Line 1 public void testForException() {
- try{
- sortMyList(null);
- fail(“Should have thrown an exception”):
5 } catch (RuntimeException e) {
- assertTrue(true);
- }
- }
public void testData1() throws FileNotFoundException {
FileInputStream in =new FileInputStream(“data.txt”):
xxx xxx xxxxxx xxxxx xxxx;
}
6.3.7 关于命名的更多说明
6.3.8Junit测试骨架
2. 一个 extends 语句让你的类从 TestCase 继承。
3. 一个调用 super(string)的构造函数
现在,已经知道了如何编写测试。在接下来的内容中,应该是进一步介绍找出哪些内容需要测试的时候了。6.4 测试的内容
6.4.1结果是否正确
当然,必须安排一些来自用户的反馈以调整自己的假设。在代码的整个生命期中,“正确”的定义可能会不断在变;但是无论如何,至少需要确认代码所做的和自己的期望是一致的。import junit.framework.*;
import java.io.*;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class TestLargestDataFile extends TestCase {
public TestLargestDataFile(String name) {
super(name);
}
/*Run all the tests in testdata.txt(does not test
*exception case). We’ll get an error if any of the
*file I/O goes wrong.
*/
public void testFromFile() throwa Exception {
String line;
BufferedReader rdr =new BufferedReader(
new FileReader(
“testdata.txt”));
while((line = rdr.readLine()) !=null) {
if (line.startsWith( “#”)) {// Ignore comments continue;
}
StringTokenizer st = new StringTokenizer(line);
If (!st.hasMoreTokens()) {
Continue; // Blank line
}
//Get the expected value
String val =st.nextToken();
int expected =Integer.valueof(val).intValue();
//And the arguments to Largest
ArrayList argument_list = new ArrayList();
while (st.hasMoreTokens()) {
argument_list.add(Integer.valueof(st.nextToken()));
}
//Transfer object list into native array
int[] arguments= new int [argument_list.size()];
for (int i=0; i<argument_list.size(); i++) {
arguments[i] = ((Integer)argument_list.
get(i)).intValue();
}
//And run the assert
assertEquals(expected,
Largest.largest(arguments));
}
}
}
#
# Simple tests;
#
9 7 8 9
9 9 8 7
9 9 8 9
#
# Negative number tests;
#
-7 -7 -8 -9
-7 -8 -7 -8
-7 -9 -7 -8
#
# Mixture;
#
7 -9 -7 -8 7 6 4
9 -1 0 9 -7 4
#
# Boundary conditions;
#
1 1
0 0
2147483647 2147483647
-2147483648 -2147483648
另外,还有一些值得考虑的:代码本身是否并没有测试任何异常的情况。要实现这个功能,需要怎么来做呢?
找边界条件是做单元测试中最有价值的工作之一,因为 bug 一般就出现在边界上。一些需要你考虑的条件有
格式错误的数据,例如没有顶层域名的电子邮件地址,就像 fred@foobar 这样的。
空值或者不完整的值(如 0,0.0,””和 null)。
一些与意料中的合理值相去甚远的数值。例如一个人的岁数为 10 000 岁。
如果要求的是一个不允许出现的重复数值的 list,但是传入的是一个存在重复的数值的 list.
如果要求的是一个有序的 list,但传入的是一个无序的 list;或者反之。例如,给一个要求
排好序的算法传入一个未排序的 list——甚至一个反序的 list。
事情到达的次序是错误的,或者碰巧和期望的次序不一致。例如,在未登陆系统之前,就尝试打印文档。
Ordering (顺序性)—— 值是否如应该的那样,是有序或者无序的。
Range (区间性)—— 值是否位于合理的最小值和最大值之内。
Reference (依赖性)—— 代码是否引用了一些不在代码范围之内的外部资源。
Existence (存在性)—— 值是否存在(例如,是否非 null,非 0,在一个集合中等等)。
Cardinatity (基数性)—— 是否恰好有足够的值。
Time (相对或者绝对的时间性)—— 所有事情的发生是否是有序的?是否是在正确的时刻?是否恰好及时?6.4.3检查反向关联
public void testSquareRootUsingInverse()
{
double x = mySquareRoot(4.0);
assertEquals(4.0,x*x,0.0001);
}
要注意的是:当同时编写了原方法和它的反向测试时,一些 bug 可能会被两个函数中都出现的错误所掩盖。在可能的情况下,应该使用不同的原理来编写反向测试。在上面平方根的例子中,用的只是普通的乘法来验证方法。而在数据库查找的例子中,大概可以使用厂商提供的查找方法来测
试自己的插入。6.4.4 使用其他手段来实现交叉检查
public void testSquareRootUsingStd() {
double number = 3880900.0;
double root1 = mySquareRoot (number);
double root2 = Math.sqrt(number);
assertEquals(root2, root1, 0.0001);
}
6.4.5 强制产生错误条件
磁盘用满。
时钟出问题。
网络不可用或者有问题。
调色板颜色数目有限。
显示分辨率过高或者过低。6.4.6 性能特性
public void testURLFilter() {
Timer timer = new Timer();
String naughty_url = “http://www.xxxxxxxx..com;”
// First, check a bad URL against a small list
URLFilter filter = new URLFilter(small_list);
timer.start();
filter.check(naughty_url);
timer.end();
assertTrue(timer.elapsedTime()<1.0);
//Next, check a bad URL against a big list
URLFilter f = new URLFilter(big_list);
time.start();
fliter.check(naughty_url)
timer.end();
assertTrue(timer.elapsedTime()<2.0);
//Finally, check a bad URL against a huge list
URLFilter f = new URLFilter(huge_list);
timer.start();
filter.check(naughty_url);
timer.end();
assertTure(timer.elapsedTime()<3.0);
}
6.5 JUnit 测试实例
将强制 rebuild 所有的 buildpaths。
public class TestThatWeGetHelloWorldPrompt extends TestCase
{
public TestThatWeGetHelloWorldPrompt( String name)
{
super(name);
}
public void testSay()
{
HelloWorld hi = new HelloWorld();
assertEquals("Hello World!", hi.say());
}
public static void main(String[] args)
{
junit.textui.TestRunner.run( TestThatWeGetHelloWorldPrompt.class);
}
}
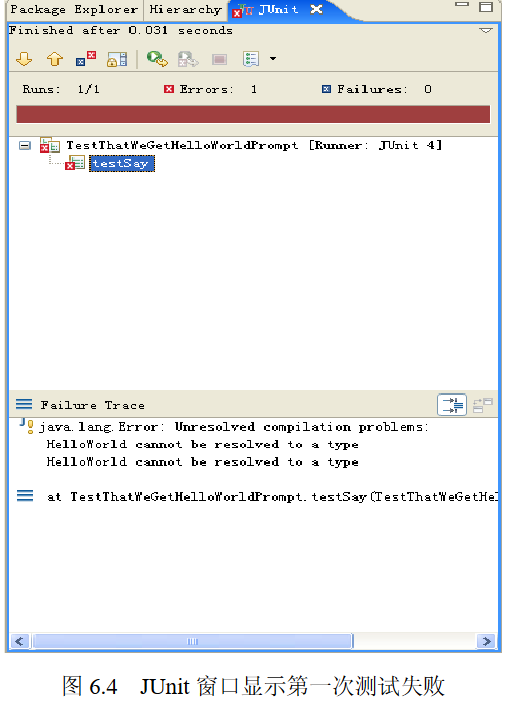
public class HelloWorld
{
public String say()
{
return("Hello World!");
}
}
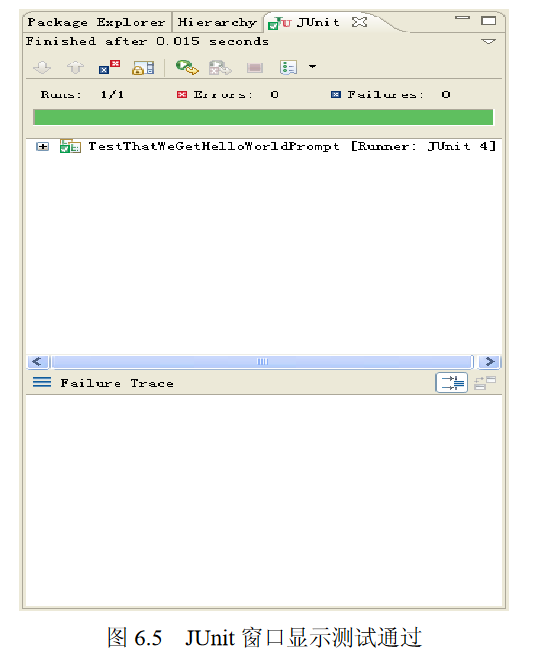
再运行这个 JUnit test,显示条又变成红色,并且可以看到是什么原因导致的错误,如图 6.6。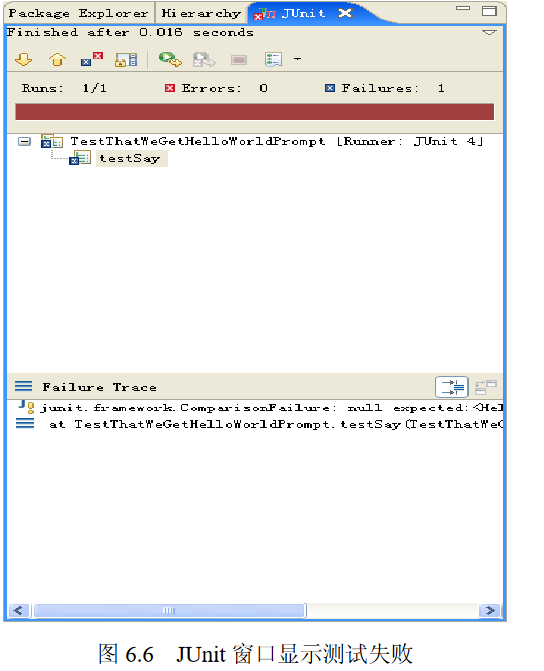
第 7 章 selenium
7.1 安装 selenium
7.3 selenium 元素定位
7.3.1 selenium 定位方法
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()7.3.2 定位方法的用法
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body link="#0000cc">
<a id="result_logo" href="/" onmousedown="return c({'fm':'tab','tab':'logo'})">a>
<form id="form" class="fm" name="f" action="/s">
<span class="soutu-btn">
<input id="kw" class="s_ipt" name="wd" value="" maxlength="255" autocomplete="off">
span>
form>
body>
html>
dr.find_element_by_id(“kw”)
通过 name 定位:
dr.find_element_by_name(“wd”)
通过 class name 定位:
dr.find_element_by_class_name(“s_ipt”)
通过 tag name 定位:
dr.find_element_by_tag_name(“input”)
通过 xpath 定位,xpath 定位有 N 种写法,这里列几个常用写法:dr.find_element_by_xpath("//*[@id='kw']")
dr.find_element_by_xpath("//*[@name='wd']")
dr.find_element_by_xpath("//input[@class='s_ipt']")
dr.find_element_by_xpath("/html/body/form/span/input")
dr.find_element_by_xpath("//span[@class='soutu-btn']/input")
dr.find_element_by_xpath("//form[@id='form']/span/input")
dr.find_element_by_xpath("//input[@id='kw' and @name='wd']")
dr.find_element_by_css_selector("#kw")
dr.find_element_by_css_selector("[name=wd]")
dr.find_element_by_css_selector(".s_ipt")
dr.find_element_by_css_selector("html > body > form > span > input")
dr.find_element_by_css_selector("span.soutu-btn> input#kw")
dr.find_element_by_css_selector("form#form > span > input")
新闻
hao123
dr.find_element_by_link_text("新闻")
dr.find_element_by_link_text("hao123")
dr.find_element_by_partial_link_text("新")
dr.find_element_by_partial_link_text("hao")
dr.find_element_by_partial_link_text("123")
7.4控制浏览器操作
7.4.1 控制浏览器窗口大小
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://m.baidu.com")
# 参数数字为像素点
print("设置浏览器宽 480、高 800 显示")
driver.set_window_size(480, 800)
driver.quit()
7.4.2 控制浏览器后退、前进
from selenium import webdriver
driver = webdriver.Firefox()
#访问百度首页
first_url= 'http://www.baidu.com'
print("now access %s" %(first_url))
driver.get(first_url)
#访问新闻页面
second_url='http://news.baidu.com'
print("now access %s" %(second_url))
driver.get(second_url)
#返回(后退)到百度首页
print("back to %s "%(first_url))
driver.back()
#前进到新闻页
print("forward to %s"%(second_url))
driver.forward()
driver.quit()
7.4.3 刷新页面
7.5 WebDriver 常用方法
7.5.1 点击和输入
clear():清除文本。
send_keys (value):模拟按键输入。
click():单击元素。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
driver.quit()
7.5.2 提交
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
search_text = driver.find_element_by_id('kw')
search_text.send_keys('selenium')
search_text.submit()
driver.quit()
7.5.3 其他常用方法
text:获取元素的文本。
get_attribute(name):获得属性值。
is_displayed():设置该元素是否用户可见。rom selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 获得输入框的尺寸
size = driver.find_element_by_id('kw').size
print(size)
# 返回百度页面底部备案信息
text = driver.find_element_by_id("s-bottom-layer-right").text
print(text)
# 返回元素的属性值, 可以是 id、 name、 type 或其他任意属性
attribute = driver.find_element_by_id("kw").get_attribute('type')
print(attribute)
# 返回元素的结果是否可见, 返回结果为 True 或 False
result = driver.find_element_by_id("kw").is_displayed()
print(result)
driver.quit()
{‘width’: 500, ‘height’: 22}
©2015 Baidu 使用百度前必读 意见反馈 京 ICP 证 030173 号
text
True7.6 鼠标事件
ActionChains 类提供了鼠标操作的常用方法:
perform():执行所有 ActionChains 中存储的行为;
context_click():右击;
double_click():双击;
drag_and_drop():拖动;
move_to_element():鼠标悬停。7.6.1 鼠标悬停操作
from selenium import webdriver
# 引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.baidu.cn")
# 定位到要悬停的元素
above = driver.find_element_by_id("s-usersetting-top")
# 对定位到的元素执行鼠标悬停操作
ActionChains(driver).move_to_element(above).perform()
from selenium.webdriver import ActionChains
导入提供鼠标操作的 ActionChains 类。
ActionChains(driver)
调用 ActionChains()类, 将浏览器驱动 driver 作为参数传入。
move_to_element(above)
context_click()方法用于模拟鼠标右键操作, 在调用时需要指定元素定位。
perform()
执行所 ActionChains 中存储的行为,可以理解成是对整个操作的提交动作。
7.6.2 键盘事件
from selenium import webdriver
# 引入 Keys 模块
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 输入框输入内容
driver.find_element_by_id("kw").send_keys("seleniumm")
# 删除多输入的一个 m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
# 输入空格键+“教程”
driver.find_element_by_id("kw").send_keys(Keys.SPACE)
driver.find_element_by_id("kw").send_keys("教程")
# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'a')
# ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'x')
# ctrl+v 粘贴内容到输入框
driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'v')
# 通过回车键来代替单击操作
driver.find_element_by_id("su").send_keys(Keys.ENTER)
driver.quit()
from selenium.webdriver.common.keys import Keys
以下为常用的键盘操作:send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
send_keys(Keys.SPACE) 空格键(Space)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(Esc)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.CONTROL,'a') 全选(Ctrl+A)
send_keys(Keys.CONTROL,'c') 复制(Ctrl+C)
send_keys(Keys.CONTROL,'x') 剪切(Ctrl+X)
send_keys(Keys.CONTROL,'v') 粘贴(Ctrl+V)
send_keys(Keys.F1) 键盘 F1
......
send_keys(Keys.F12) 键盘 F12
7.7 获取断言信息
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")
print('Before search================')
# 打印当前页面 title
title = driver.title
print(title)
# 打印当前页面 URL
now_url = driver.current_url
print(now_url)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
sleep(1)
print('After search================')
# 再次打印当前页面 title
title = driver.title
print(title)
# 打印当前页面 URL
now_url = driver.current_url
print(now_url)
# 获取结果数目
user = driver.find_element_by_class_name('nums').text
print(user)
driver.quit()
百度一下,你就知道
https://www.baidu.com/
After search================
selenium_百度搜索
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx…
搜索工具
百度为您找到相关结果约 5,380,000 个
current_url:用户获得当前页面的 URL。
text:获取搜索条目的文本信息。7.8 设置元素等待
7.8.1 显式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, "kw"))
)
element.send_keys('selenium')
driver.quit()
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
timeout:最长超时时间,默认以秒为单位。
poll_frequency:检测的间隔(步长)时间,默认为 0.5S。
ignored_exceptions : 超 时 后 的 异 常 信 息 , 默 认 情 况 下 抛
NoSuchElementException 异常。
WebDriverWait() 一 般 由 until() 或 until_not() 方 法 配 合 使 用 , 下 面 是 until() 和until_not()方法的说明。
until(method, message=‘’)7.8.2 隐式等待
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from time import ctime
driver = webdriver.Firefox()
# 设置隐式等待为 10 秒
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
try:
print(ctime())
driver.find_element_by_id("kw22").send_keys('selenium')
except NoSuchElementException as e:
print(e)
finally:
print(ctime())
driver.quit()
7.9 定位一组元素
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
接下来通过例子演示定位一组元素的使用:from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
sleep(1)
# 定位一组元素
texts = driver.find_elements_by_xpath('//div/h3/a')
# 循环遍历出每一条搜索结果的标题
for t in texts:
print(t.text)
driver.quit()
功能自动化测试工具——Selenium 篇
selenium + python 自动化测试环境搭建 - 虫师 - 博客园
selenium 是什么?_百度知道
怎样开始用 selenium 进行自动化测试(个人总结)_百度经验
Selenium_百度百科
selenium_百度翻译
Selenium 官网教程_selenium 自动化测试实践_Selenium_领测软件测试网
Selenium(浏览器自动化测试框架)_百度百科
自动化基础普及之 selenium 是啥? - 虫师 - 博客园
python 十大主流开源框架 「菜鸟必看」
7.10 多表单切换
<html>
<body>
...
<iframe id="x-URS-iframe" ...>
<html>
<body>
...
<input name="email" >
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.126.com")
driver.switch_to.frame('x-URS-iframe')
driver.find_element_by_name("email").clear()
driver.find_element_by_name("email").send_keys("username")
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys("password")
driver.find_element_by_id("dologin").click()
driver.switch_to.default_content()
driver.quit()
......
#先通过 xpth 定位到 iframe
xf = driver.find_element_by_xpath('//*[@id="x-URS-iframe"]')
#再将定位对象传给 switch_to.frame()方法
driver.switch_to.frame(xf)
......
driver.switch_to.parent_frame()
7.11 多窗口切换
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
# 获得百度搜索窗口句柄
sreach_windows = driver.current_window_handle
driver.find_element_by_link_text('登录').click()
driver.find_element_by_link_text("立即注册").click()
# 获得当前所有打开的窗口的句柄
all_handles = driver.window_handles
# 进入注册窗口
for handle in all_handles:
if handle != sreach_windows:
driver.switch_to.window(handle)
print('now register window!')
driver.find_element_by_name("account").send_keys('username')
driver.find_element_by_name('password').send_keys('password')
time.sleep(2)
# ......
driver.quit()
在本例中所涉及的新方法如下:
current_window_handle:获得当前窗口句柄。
window_handles:返回所有窗口的句柄到当前会话。
switch_to.window():用于切换到相应的窗口,与上一节的 switch_to.frame()类似,
前者用于不同窗口的切换,后者用于不同表单之间的切换。
7.12 警告框处理
accept():接受现有警告框。
dismiss():解散现有警告框。
send_keys(keysToSend):发送文本至警告框。keysToSend:将文本发送至警告框。from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
# 鼠标悬停至“设置”链接
link = driver.find_element_by_link_text('设置')
ActionChains(driver).move_to_element(link).perform()
# 打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
# 保存设置
driver.find_element_by_class_name("prefpanelgo").click()
time.sleep(2)
# 接受警告框
driver.switch_to.alert.accept()
driver.quit()
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import sleep
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
# 鼠标悬停至“设置”链接
driver.find_element_by_link_text('设置').click()
sleep(1)
# 打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
sleep(2)
# 搜索结果显示条数
sel = driver.find_element_by_xpath("//select[@id='nr']")
Select(sel).select_by_value('50')
# 显示 50 条
# ......
driver.quit()
select_by_value() 方法用于定位下接选项中的 value 值。7.14 文件上传
创建 upfile.html 文件,代码如下:<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>upload_filetitle>
<link href="http://cdn.bootcss.com/bootstrap/3.3.0/css/bootstrap.min.css" rel="stylesheet" />
head>
<body>
<div class="row-fluid">
<div class="span6 well">
<h3>upload_fileh3>
<input type="file" name="file" />
div>
div>
body>
<script src="http://cdn.bootcss.com/bootstrap/3.3.0/css/bootstrap.min.js">scrip>
html>
接下来通过 send_keys()方法来实现文件上传。from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('upfile.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()
7.15 cookie 操作
get_cookies():获得所有 cookie 信息。
get_cookie(name):返回字典的 key 为“name”的 cookie 信息。
add_cookie(cookie_dict):添加 cookie。“cookie_dict”指字典对象,必须有 name
和 value 值。
delete_cookie(name,optionsString):删除 cookie 信息。“name”是要删除的 cookie的名称,“optionsString”是该 cookie 的选项,目前支持的选项包括“路径”,“域”。
delete_all_cookies():删除所有 cookie 信息。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.youdao.com")
# 获得 cookie 信息
cookie= driver.get_cookies()
# 将获得 cookie 的信息打印
print(cookie)
driver.quit()
rom selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.youdao.com")
# 向 cookie 的 name 和 value 中添加会话信息
driver.add_cookie({'name': 'key-aaaaaaa', 'value': 'value-bbbbbb'})
# 遍历 cookies 中的 name 和 value 信息并打印,当然还有上面添加的信息
for cookie in driver.get_cookies():
print("%s -> %s" % (cookie['name'], cookie['value']))
driver.quit()
输出结果:
=====================RESTART: =====================
YOUDAO_MOBILE_ACCESS_TYPE -> 1
_PREF_ANONYUSER__MYTH -> aGFzbG9nZ2VkPXRydWU=
OUTFOX_SEARCH_USER_ID -> [email protected]
JSESSIONID -> abc7qSE_SBGsVgnVLBvcu
key-aaaaaaa -> value-bbbbbb
7.16 调用 JavaScript 代码
用于调整浏览器滚动条位置的 JavaScript 代码如下:from selenium import webdriver
from time import sleep
# 访问百度
driver=webdriver.Firefox()
driver.get("http://www.baidu.com")
# 设置浏览器窗口大小
driver.set_window_size(500, 500)
# 搜索
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
sleep(2)
# 通过 javascript 设置浏览器窗口的滚动条位置
js="window.scrollTo(100,450);"
driver.execute_script(js)
sleep(3)
driver.quit()
7.17 窗口截图
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
driver.find_element_by_id('kw').send_keys('selenium')
driver.find_element_by_id('su').click()
sleep(2)
# 截取当前窗口,并指定截图图片的保存位置
driver.get_screenshot_as_file("D:\\baidu_img.jpg")
driver.quit()
7.18 关闭浏览器
此之外,WebDriver 还提供了 close()方法,用来关闭当前窗口。例多窗口的处理,在用例执行的过程
中打开了多个窗口,我们想要关闭其中的某个窗口,这时就要用到 close()方法进行关闭了。
close() 关闭单个窗口
quit() 关闭所有窗口