python爬取某潮鞋app帖子信息
python爬取某潮鞋app帖子信息
- 目的:爬取帖子中的图片及频率信息
- 用到的工具:appium,fiddler,python,mongodb,手机或模拟器
- 环境要求:java8,最好有Android开发环境,里面会提供一些分析元素定位的工具及adb命令
- 思路:使用appium模拟点击,下滑动作,使fiddler能不断自动抓包,编辑fiddler script,将关于贴子的链接保存到txt文件中,遍历文件中的链接下载图片到本地,及保存所需要的信息到mongodb数据库
具体过程及部分代码
- python控制appium代码
ParameterTerm = {
"platformName": "Android", # 平台名称
"platformVersion": "8", # 平板版本号
"deviceName": "LFLBB19903204818", # 设备名称
"appPackage": "cool.dingstock.mobile", # 测试的包名
"appActivity": ".activity.index.HomeIndexActivity", # 测试的包活动
'unicodeKeyboard': True,
"noReset": True,
}
# 这里的url是默认的,不用修改
driver = webdriver.Remote("http://localhost:4723/wd/hub", ParameterTerm)
time.sleep(5)
获取测试包名及包活动的命令:
adb shell "dumpsys window windows | grep mFocusedApp"
ps: 手机需要处于打开该app界面,appium可通过npm安装,adb devices可查看设备名称
- 模拟人的浏览动作
start_x = 400
start_y = 1000
distance = 600
while True:
driver.find_element_by_id("cool.xxxxxx.mobile:id/circle_item_dynamic_content_txt").click()
time.sleep(0.3)
driver.swipe(start_x, start_y, start_x, start_y - distance)
time.sleep(1)
driver.find_element_by_id("cool.xxxxx.mobile:id/common_titlebar_left_icon").click()
time.sleep(0.5)
driver.swipe(start_x, start_y, start_x, start_y - distance)
print("1s后滑到一个视频")
time.sleep(1)
用time.sleep()控制时间,防止操作过快带给服务器压力
- 保存所需信息链接
static function OnBeforeResponse(oSession: Session) {
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
if (oSession.fullUrl.Contains("apiv2.xxxxxx.net/xserver/community/post/detail")){
var fso;
var file;
fso = new ActiveXObject("Scripting.FileSystemObject");
//文件保存路径,可自定义
file = fso.OpenTextFile("D:\\py_20200302\\Request.txt", 8, true);
file.writeLine(oSession.fullUrl);
FiddlerObject.log(oSession.fullUrl);
file.close();
}
}
打开fiddler,使用快捷键ctrl+r打开fiddler脚本编辑器添加如上代码,此链接apiv2.xxxxxx.net/xserver/community/post/detail返回的是json信息,包括图片地址,用户信息,评论信息等
- 获得json信息
import urllib3
urllib3.disable_warnings()
def get_json(url):
headers = {
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 8.1.0; DUB-TL00 Build/HUAWEIDUB-TL00)'
}
try:
response = requests.get(url, headers=headers, verify=False)
if response.status_code == 200:
json_info = response.json()
return json_info
except Exception as e:
print("获取json信息出错原因:", e)
用的python的第三方库requests请求链接,注意添加header头信息,由于是https链接,requests.get需要使用verify=False关闭证书验证,并添加下面梁行代码关闭python关于安全问题的警告
import urllib3
urllib3.disable_warnings()
- 解析json信息
def parse_json(json_info_, dst_folder):
post_result = {}
try:
post_id = json_info_['res']['post']['id']
post_content = json_info_['res']['post']['content']
post_result['content'] = post_content.strip()
images = json_info_['res']['post']['images']
if len(images):
for i in range(len(images)):
image_url = json_info_['res']['post']['images'][i]['url']
dst_ = os.path.join(dst_folder, post_id)
os.makedirs(dst_, exist_ok=True)
download_picture(image_url, os.path.join(dst_, image_url.split('/')[-1]))
post_result['comment'] = {}
for i in range(len(json_info_['res']['sections'][0]['comments'])):
post_result['comment'][str(i)] = json_info_['res']['sections'][0]['comments'][i]['content'].strip()
print(post_result)
save2mongodb(post_result)
except Exception as e:
print("解析json信息出错原因:", e)
从返回的json中获取post_id用做本地文件夹名保存图片,post_result[‘content’]存放帖子内容,post_result[‘comment’]存放评论信息,暂时我只关注这些信息,不关注用户信息
- 下载图片函数
def download_picture(image_url_, file_path_):
headers = {
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 8.1.0; DUB-TL00 Build/HUAWEIDUB-TL00)'
}
try:
response = requests.get(image_url_, headers=headers, verify=False)
if response.status_code == 200:
with open(file_path_, 'wb') as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
file.flush() # 刷新缓存
except Exception as e:
print("下载图片出错原因:%s", e)
先请求图片链接,再将response的二进制流通过iter_content函数以chunk方式写入文件,效率更高
- 保存信息到数据库
def save2mongodb(json_item):
client = pymongo.MongoClient(
host='localhost',
port=27017
) # 客户连接
db = client.spiderdb # 选择数据库
collection = db.dingstock # 选择集合
collection.insert_one(json_item)
print("储存到mongodb成功!")
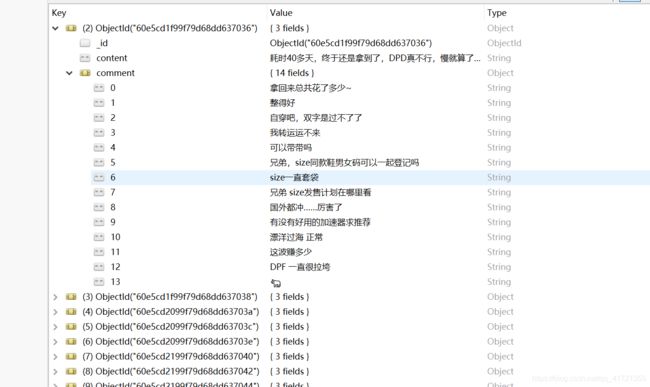
连接数据写入json信息即可,我的格式是,{‘id’:{‘post_content’:‘xxxx’}, {‘commnet’:{‘1’:‘xxx’, ‘2’:‘xxx’, …}}}
- 主函数
def main():
with open(r"D:\py_20200302\Request.txt") as f:
urls = f.readlines()
urls = [url.strip().split('%')[0] for url in urls]
urls = list(set(urls))
print(urls)
for url in urls:
dst_folder = r'D:\py_20200302\result'
json_info = get_json(url)
parse_json(json_info, dst_folder)
if __name__ == '__main__':
main()
打开fiddler过滤出的目标json信息链接的文件,去除其中可能存在的重复链接,遍历url,执行parse_json函数,下载图片及写入数据在此函数中被条用
ps:此文档仅用于学习,涉及网站等信息已用xxxxx代替
- 结果样例展示