RAFT:使用深度学习的光流估计
在这篇文章中,我们将讨论两种基于深度学习的使用光流进行运动估计的方法。FlowNet是第一种用于计算光流的CNN方法,RAFT是目前最先进的估算光流的方法。我们还将看到如何使用作者提供的经过训练的模型来使用PyTorch对新数据进行推理。
(1)光流任务
在前一篇文章中,我们讨论了估算光流的基本组件和一些算法方法。让我们提醒您,光流任务包括估计两个连续帧之间的逐像素运动。我们的目标是找到稀疏特征集或所有图像像素的位移来计算它们的运动向量。在前一篇文章中,我们回顾了基于OpenCV的理论和实际解决方案,现在我们将继续讨论用于光流估计的深度学习方法。
(2)FlowNet
FlowNet架构作为第一种预测光流的CNN方法,于2015年被引入。CNN体系结构在分类、深度估计和语义分割任务中的成功启发了作者。随着深度学习方法和CNN在解决许多计算机视觉任务上的成功,作者介绍了两种用于光流估计的神经网络。

结构
FlowNetS和FlowNetCorr架构都包含类似于U-Net架构的编码器和解码器部分。编码器从连续的两幅图像中提取特征,解码器对编码器的特征映射进行放大,得到最终的光流预测。让我们更深入地了解FlowNetS和FlowNetCorr网络。
FlowNetS编码器
FlowNetS(也称为FlowNetSimple)中的输入数据是两个连续帧的连接。这两张图像连接后是6通道张量,其中前三个通道属于第一张图像,其余三个通道属于第二张图像。编码器部分由几个卷积层和激活函数组成。这种架构允许网络自行决定如何处理两个堆叠的图像,并给出特征图,以进行后续的结果细化。

FlowNetCorr编码器
FlowNetCorr架构每次只接受一帧作为输入,所以在这里图像不会堆叠。在该网络中,作者使用共享权重的CNN第一阶段分别从两幅连续图像中提取特征。下一步是分别从第一帧和第二帧计算出两个特征映射 f 1 和 f 2 \mathbf{f}_1和\mathbf{f}_2 f1和f2。为此,作者介绍了一种叫做相关层的新技术,这是FlowNetS和FlowNetCorr的主要区别。相关性的计算等于卷积运算,但这里没有可训练的核——一个特征映射与另一个特征映射进行卷积。因此,该层对两个特征映射 ( f 1 , f 2 ) (\mathbf{f}_1, \mathbf{f}_2) (f1,f2)进行乘法块比较,并且没有可训练的权值。
对于第一个和第二个特征图,以 x 1 , x 2 x_1, x_2 x1,x2为中心的两个方形块的相关公式分别定义为:
![]()
正方形块的大小定义为 K = 2 k + 1 K = 2k+1 K=2k+1。值得一提的是,作者并没有在两个特性图之间做完整的关联,而是在局部上做。
两个特征图匹配完成后,相关结果前向传递到其余卷积层,提取高级特征。下图是FlowNetCorr的架构:
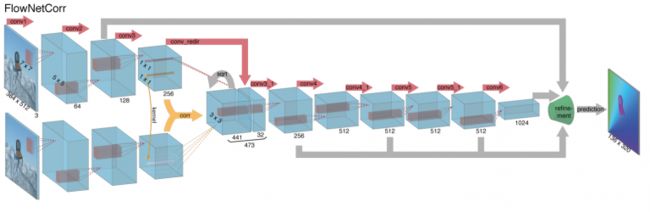
FlowNetS和FlowNetCorr解码器
编码器输出的特征图比输入图像分辨率小64倍,所以我们需要上采样结果。这里的策略对于两种架构都是相同的。在解码器阶段使用可训练的上采样卷积层来提升编码器的光流输出。每个解码器阶段将上一阶段的放大结果和编码器相应层的特征图连接起来。使用来自编码器的数据有助于预测细节,就像在U-Net中做的那样。
作者只使用了四个上采样阶段,因为使用更多的阶段提供了质量的边际改善。为了上采样输出到初始图像分辨率,最好使用计算成本较低的双线性上采样。

网络输出是一个具有两个通道的张量,第一个通道由x轴上每个像素的运动位移组成,第二个通道由y轴上每个像素的运动位移组成。因此,我们对图像中的每个像素都有一个运动向量。
损失函数
多尺度训练损失是FlowNet较好的惩罚策略。最后的预测是放大的小尺度光流,所以小尺度的预测对下一个大尺度的预测有很大的影响。使用影响减少参数为每个解码器阶段计算损失,以获得对每个解码器阶段的精细预测。结果表明,小尺度预测的计算损失对总损失的贡献大于大尺度预测的损失。
每个译码阶段的损失公式是基于预测 V p r e d = ( Δ x p r e d , Δ y p r e d ) V_{pred} =(\Delta x_{pred}, \Delta y_{pred}) Vpred=(Δxpred,Δypred)与真实数据 V g t = ( Δ x g t , Δ y g t ) V_{gt}=(\Delta x_{gt}, \Delta y_{gt}) Vgt=(Δxgt,Δygt)之间的端点误差:
L = ∣ ∣ V g t − V c a l c ∣ ∣ 1 = ( Δ x g t − Δ x c a l c ) 2 + ( Δ y g t − Δ y c a l c ) 2 L = ||V_ {gt} -V_ {calc}||_{1} =\sqrt{(\Delta x_{gt}-\Delta x_{calc})^2+(\Delta y_{gt}-\Delta y_{calc})^2} L=∣∣Vgt−Vcalc∣∣1=(Δxgt−Δxcalc)2+(Δygt−Δycalc)2
(3)RAFT
根据SINTEL基准,最先进的方法是2020年引入的CNN和RNN架构的组合。这种新方法被称为RAFT(Recurrent All-Pairs Field Transforms)。与前面的架构一样,它也有两种不同的类型——RAFT和RAFT- s。这两种体系结构有一个共同点,但是RAFT- s是RAFT的轻量级版本。在这里,我们将了解RAFT架构的基本组件和思想,然后将其与RAFT- s进行比较。
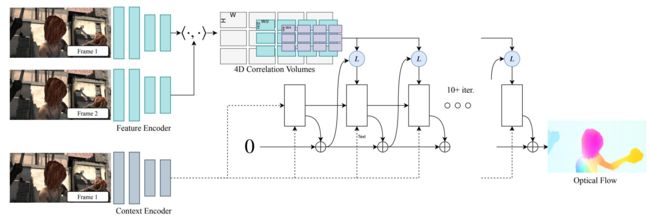
结构
RAFT可分为三个阶段:
- 1.特征提取:网络输入由两个连续的帧组成。为了从这两幅图像中提取特征,作者使用了两个共享权值的cnn。这种方法类似于FlowNetCorr架构,我们分别从两幅图像中提取特征。CNN的架构由6个残差层组成,就像ResNet的层一样,每隔一层分辨率就降低一半,同时通道数量也在增加。这里我们可以看到RAFT编码器的结构:

此外,同样的CNN架构也用于上下文网络(Context network),它只从第一张图像生成特征。在归一化方法上只有一个区别——特征提取器使用实例归一化,而上下文网络使用批处理归一化。上下文网络的特征映射将在稍后的递归块中使用。 - 2.视觉相似性(Visual Similarity):视觉相似度计算为所有特征图对的内积。因此,我们将得到一个称为相关体积的四维张量,它提供了关于大小像素位移的关键信息。这种方法不应该与FlowNetCorr中的相关层混淆。在FlowNetCorr中,我们使用patch-wise correlation,而在RAFT中,我们计算两个特征图的全相关性,没有任何固定大小的窗口。明确地说,两个特征映射 ( f 1 , f 2 ) (\mathbf{f_1, f_2}) (f1,f2)之间的相关性计算如下: C i j k l = ∑ d f 1 i j d ⋅ f 2 k l d C_{ijkl} = \sum \limits_{d} \mathbf{f_1}_{ijd} \cdot \mathbf{f_2}_{kld} Cijkl=d∑f1ijd⋅f2kld

然后,将这个四维张量的最后两个维用大小为1、2、4、8的核进行池化,构建4层相关金字塔。你可以在下面的图片中看到前三层的二维切片:

利用相关金字塔建立多尺度图像相似度特征,使突变运动更明显。因此,金字塔提供了关于小位移和大位移的信息。 - 3.迭代更新:迭代更新是一个门控循环单元(GRU)序列,它结合了我们之前计算的所有数据。GRU单元模拟了一种迭代优化算法,但有一个改进——有共享权重的可训练卷积层。每次更新迭代产生一个新的光流更新 Δ f \Delta \mathbf{f} Δf,以使每一个新步骤的预测更准确: Δ f + f k + 1 = f + f k + 1 \Delta \mathbf{f} + \mathbf{f}_{k+1} = \mathbf{f} + \mathbf{f}_{k+1} Δf+fk+1=f+fk+1。经典GRU表示如下:

上采样模块
GRU单元输出的光流分辨率为初始图像的1/8,因此作者提出了两种不同的上采样方法来匹配真值分辨率。第一种是光流的双线性插值。它是一种简单快速的方法,但这种方法的质量不如一个可学习名叫Convex Upsampling的上采样模块:

凸上采样(Convex Upsampling)方法表明,全分辨率光流是GRU单元预测的3x3加权网格的凸组合。8 倍图像上采样意味着必须将 1 个像素扩展为 64(8x8) 个像素。凸上采样模块由两个卷积层和末端的softmax激活来预测上采样光流预测中每个新像素的 H / 8 × W / 8 × ( 8 × 8 × 9 ) H/8 \times W/8 \times (8 \times 8 \times 9) H/8×W/8×(8×8×9)掩码。现在,上采样图像上的每个像素都是之前粗糙分辨率像素的凸组合,由预测掩码加权,系数为 w 1 , w 2 , … , w 9 {w_1, w_2,…,w_9} w1,w2,…,w9:

作者认为,该方法预测了更准确的光流输出,特别是在运动边界附近。
损失函数
损失函数定义为真实值与预测值之间的L1距离,等于FlowNet中的损失。所有上采样的循环单元输出创建一个光流预测序列 f 1 , … , f N {\mathbf{f}_1,…,\mathbf{f}_N} f1,…,fN。
总损失是真实值与上采样预测之间每个循环块输出的损失之和:
L = ∑ i = 1 N γ i − N ∣ ∣ g t − f i ∣ ∣ 1 , γ = 0.8 L = \sum_ {i = 1} ^ N \gamma^ {i-N} | | gt - \mathbf {f} _i | | _1 , \: \: \: \ γ= 0.8 L=∑i=1Nγi−N∣∣gt−fi∣∣1, γ=0.8
RAFT和RAFT- s的比较
如前所述,在原始论文中介绍了两种类型的网络架构——RAFT和RAFT- s。让我们来看看它们的图像比较:
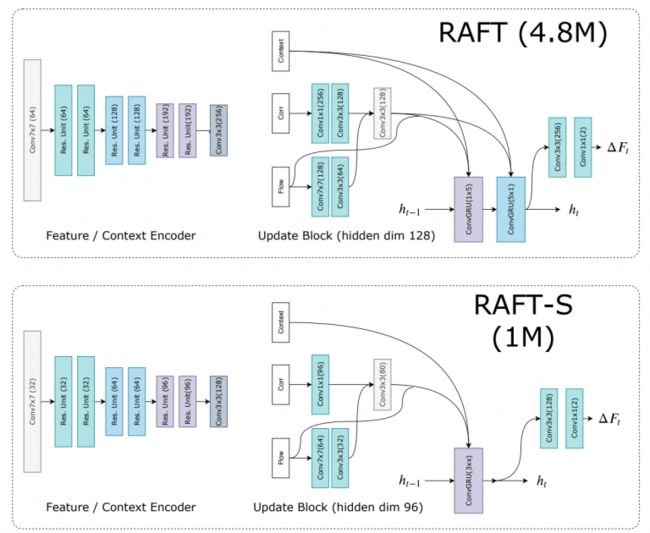
首先,Feature and Context Extractor具有不同数量的通道,RAFT-S中残差单元被瓶颈残差单元代替;其次,RAFT架构在一个block中有两个卷积GRU cell,卷积核分别为1x5和5x1,而RAFT- s只有一个3x3卷积GRU cell。因此,RAFT 的轻量级版本 RAFT-S 具有较少的参数数量,同时在质量方面的准确性稍差。
(4) 基于PyTorch的RAFT
代码地址:
链接:https://pan.baidu.com/s/1nxrcPzshw3Tp5yFC5dZrZw
提取码:123a
作者还将RAFT架构的实现开源并附加了预训练权重,所以我们可以检查这个体系结构,并使用作者的开发创建推理脚本。要启动演示,您需要下载我们的代码并安装所需的库。所有关于安装的信息都可以在README中找到。
项目的结构组成:
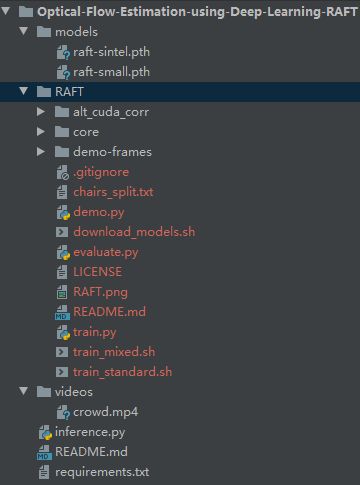
- 1)推理代码
import os
import sys
sys.path.append('RAFT/core')
from argparse import ArgumentParser
from collections import OrderedDict
import cv2
import numpy as np
import torch
from raft import RAFT
from utils import flow_viz
def frame_preprocess(frame, device):
frame = torch.from_numpy(frame).permute(2, 0, 1).float()
frame = frame.unsqueeze(0)
frame = frame.to(device)
return frame
def vizualize_flow(img, flo, save, counter):
# 更换通道和更换设备是必要的
img = img[0].permute(1, 2, 0).cpu().numpy()
flo = flo[0].permute(1, 2, 0).cpu().numpy()
# 将光流映射到RGB图像
flo = flow_viz.flow_to_image(flo)
flo = cv2.cvtColor(flo, cv2.COLOR_RGB2BGR)
# 连接,保存和显示图像
img_flo = np.concatenate([img, flo], axis=0)
if save:
cv2.imwrite(f"demo_frames/frame_{str(counter)}.jpg", img_flo)
cv2.imshow("Optical Flow", img_flo / 255.0)
k = cv2.waitKey(25) & 0xFF
if k == 27:
return False
return True
def get_cpu_model(model):
new_model = OrderedDict()
# 从模型中获取所有层的名称
for name in model:
# 创建新名称并更新新模型
new_name = name[7:]
new_model[new_name] = model[name]
return new_model
def inference(args):
# 得到RAFT模型
model = RAFT(args)
# 加载预训练权重
pretrained_weights = torch.load(args.model)
save = args.save
if save:
if not os.path.exists("demo_frames"):
os.mkdir("demo_frames")
if torch.cuda.is_available():
device = "cuda"
# 并行计算
model = torch.nn.DataParallel(model)
# 将预先训练权重加载到模型中
model.load_state_dict(pretrained_weights)
model.to(device)
else:
device = "cpu"
# 更改CPU运行时的键名
pretrained_weights = get_cpu_model(pretrained_weights)
# 将预先训练权重加载到模型中
model.load_state_dict(pretrained_weights)
# 将模型模式改为评价模式
model.eval()
video_path = args.video
# 捕获视频并获得第一帧
cap = cv2.VideoCapture(video_path)
ret, frame_1 = cap.read()
# 帧预处理
frame_1 = frame_preprocess(frame_1, device)
counter = 0
with torch.no_grad():
while True:
# 读取下一帧
ret, frame_2 = cap.read()
if not ret:
break
# 预处理
frame_2 = frame_preprocess(frame_2, device)
# 预测
flow_low, flow_up = model(frame_1, frame_2, iters=args.iters, test_mode=True)
# 将光流输出转换为numpy数组
ret = vizualize_flow(frame_1, flow_up, save, counter)
if not ret:
break
frame_1 = frame_2
counter += 1
def main():
parser = ArgumentParser()
parser.add_argument("--model", help="restore checkpoint")
parser.add_argument("--iters", type=int, default=12)
parser.add_argument("--video", type=str, default="./videos/car.mp4")
parser.add_argument("--save", action="store_true", help="save demo frames")
parser.add_argument("--small", action="store_true", help="use small model")
parser.add_argument(
"--mixed_precision", action="store_true", help="use mixed precision"
)
args = parser.parse_args()
inference(args)
if __name__ == "__main__":
main()
# python inference.py --model=./models/raft-sintel.pth --video ./videos/crowd.mp4
- 2)代码解析
首先,我们需要定义模型并加载预训练的权重,为了同时可以在CPU和GPU设备上推理,我们需要检查GPU的可用性。默认情况下,该脚本使用您的CPU设备。预训练模型是在两个gpu上训练的,因此,预训练模型中的字典键有额外的前缀名称module。为了在CPU上运行推理,我们需要删除这个前缀并获得新的适合CPU的模型;现在,我们可以继续我们的演示任务。读取两个连续的帧,然后输出光流预测。然后对光流预测进行编码,转换为BGR图像。为了可视化流程,我们使用标准的RAFT编码器。可视化策略几乎与我们在前一篇文章中使用的HSV相似。在得到BGR格式的光流结果后,我们将图像与光流连接起来进行可视化。

(5)结论
光流在视频编辑的稳定化、压缩、慢动作等方面都有广泛的应用。此外,一些跟踪和动作识别系统也使用了光流数据。我们回顾了一些深度学习方法,这些方法在FlowNet和RAFT架构的例子中提高了质量。目前,RAFT 架构在 SINTEL 数据集上显示了最佳结果,在 KITTY 数据集上前三名。
(6)参考目录
https://learnopencv.com/optical-flow-using-deep-learning-raft/