yolov5笔记(4)——CPU部署以及NCNN
最近工作需要研究了CPU部署,为了在香橙派上部署模型(想吐槽一下这个板子,可能是树莓派jetson玩多了,对这个板子一脸嫌弃)。我试了很多种方案,其中部署最简单且效果还不错的CPU部署方案是onnxruntime。
简单过一遍yolov5的ncnn部署
参考上一篇export.pt文件导出onnx格式,记得形参加上--train

导出后安装onnx-simplifier,裁剪掉不需要的层。下文还有python的办法完成这一步
python3 -m onnxsim yolov5.onnx yolov5-sim.onnx
然后去编译好的ncnn里的tool/onnx文件夹下,下文还有用torchscript转ncnn的办法
onnx2ncnn yolov5-sim.onnx yolov5.param yolov5.bin
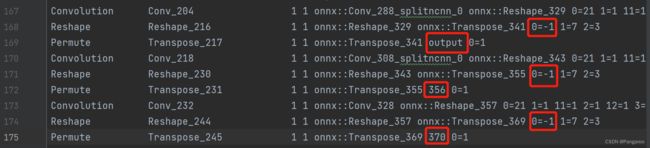
打开yolov5.param文件,最后9行,修改reshape成0=-1,记住permute的0=1前面的那个名称
去ncnn/examples文件夹下复制yolov5.cpp文件,修改ncnn模型文件路径

修改输出层名称,名称就是上面需要记的
——CPU部署以及NCNN_第4张图片](http://img.e-com-net.com/image/info8/15144bb711e84f418c99dffb1e8539d5.jpg)


然后根据自己的分类任务修改label

最后给上检查路径

运行即可完成部署。
下面是自定义部署的部分
1.安装onnxruntime
安装onnxruntime前你要想清楚你到底想CPU部署还是GPU部署,装错版本似乎就会很麻烦。
pip install onnxruntime
pip install onnxruntime-gpu
2.将模型转换成onnx格式
yolov5的库自带onnx的输出程序可以参考我的上一篇yolov5笔记(3)——移动端部署自己的模型(随5.0更新)
这里由于是新的一篇,为了不这么水就简单写一下通用的转换方式
model = Kangaroo() #加载模型
model.load_state_dict(torch.load('./best.pt')) #加载模型文件
torch.onnx._export(model, eample_data.to(torch.float32), "best.onnx", export_params=True)
#(模型,一个输入的例子,输出模型的命名,输出模型)
# 训练模型时的数据类型和例子的类型要一致,模型的位置和例子的位置要一直(cpu or gpu)
#还简化一下模型
import onnx
from onnxsim import simplify
model_onnx = onnx.load("best.onnx") #加载模型
# simplify
model_onnx_simp, check = simplify(model_onnx) #简化
onnx.save_model(model_onnx_simp,"best-sim.onnx") #输出简化模型
3.程序调用
这里我拿自己的项目作例子,不直接部署yolov5了。
思路是用numpy作数据处理,用onnxruntime作推理,丢弃pytorch。
import argparse
from PIL import Image
import numpy as np
import onnxruntime as rt
import timeit
将数据处理成模型的输入形状。
# 通过csv读取张量
d = np.loadtxt(open(air_root, "rb"), delimiter=",")
# 通过PIL读取照片,转换灰度值,剪裁操作,resize操作,转换成ndarray并标准化
image = Image.open(camera_root).convert('L').crop((1050, 0, 1550, 300)).resize((size, size), resample=2)
img = (np.array(image) / 255 - 0.485) / 0.229
# 通过opencv读取照片并转成ndarray
img = cv2.imread(filename)
img = np.array(image)
onnx加载以及推理
# model为模型路径,x为输入的ndarray
sess = rt.InferenceSession(model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run([label_name], {input_name: x.astype(np.float32)})[0]
最后处理输出结果,根据输出结果在图片上显示标签、框、置信度什么的。我的项目里没有这些我就不展示了,也可以参考我上一篇的底部代码yolov5笔记(3)——移动端部署自己的模型(随5.0更新)
个人认为这是目前最方便的cpu部署方法了(gpu也是一样的),由于onnxruntime底层是c++调用的,所以速度上也还是可以的。当然你也可以继续看c++的部分。
4.onnxruntime、ncnn、opencv环境配置
ncnn的库下载前往https://github.com/Tencent/ncnn
git clone https://github.com/Tencent/ncnn.git
然后参照这个https://github.com/Tencent/ncnn/wiki/how-to-build
这里多说一下如果不需要vulkan,cmake时要把vulkan的选项给off掉
cmake -DCMAKE_OSX_ARCHITECTURES="arm64" \
-DNCNN_VULKAN=OFF -DNCNN_BUILD_EXAMPLES=ON ..
另外还有mac和linux可以直接brew install ncnn,官方自带的是有vulkan,通过brew方式安装的必须要下载vulkan库才能使用。
CMakeList.txt设置
cmake_minimum_required (VERSION 3.5.1)
project ("ncnnTest")
set(CMAKE_CXX_STANDARD 11)
set(OpenCV_DIR "/Users/kangaroo/software/opencv/build_opencv")
set(NCNN_DIR "/Users/kangaroo/software/ncnn/build")
set(NCNN_LIBS ${NCNN_DIR}/install/lib/libncnn.a)
set(NCNN_INCLUDE_DIRS ${NCNN_DIR}/install/include/ncnn)
set(CMAKE_PREFIX_PATH ${NCNN_DIR}/install/lib/cmake/ncnn)
find_package(OpenCV REQUIRED)
find_package(NCNN REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
include_directories(${NCNN_INCLUDE_DIRS})
# 将源代码添加到此项目的可执行文件。
add_executable (ncnnTest "main.cpp")
target_link_libraries(ncnnTest ${NCNN_LIBS})
target_link_libraries(ncnnTest ${OpenCV_LIBS})
onnxruntime的库前往https://github.com/microsoft/onnxruntime/releases
选择一个对应的版本下载下来
M芯片mac电脑下载osx-arm64-1.13.1
香橙派树莓派下载linux-aarch64-1.13.1

都是编译好的版本
CMakeList.txt设置
cmake_minimum_required(VERSION 3.23)
project(onnxTest)
set(CMAKE_CXX_STANDARD 11)
set(OpenCV_DIR "/Users/kangaroo/software/opencv/build_opencv")
set(ONNXRUNTIME_ROOTDIR "/Users/kangaroo/software/onnxruntime-osx-arm64-1.13.1")
find_package(OpenCV REQUIRED)
include_directories("${ONNXRUNTIME_ROOTDIR}/include")
link_directories("${ONNXRUNTIME_ROOTDIR}/lib")
add_executable(onnxTest main.cpp)
target_link_libraries(onnxTest ${OpenCV_LIBS})
target_link_libraries(onnxTest ${ONNXRUNTIME_ROOTDIR}/lib/libonnxruntime.1.13.1.dylib)
5.c++数据处理
用c++重写数据预处理,同样的我也只给思路了。
在c++上我是用opencv搭配vector、array来替换numpy
# 通过csv读取张量
vector<float> inputArr = csvRead(air_root);
vector<float>::const_iterator First = inputArr.begin() + 450;
vector<float>::const_iterator End = inputArr.begin() + 1650;
inputArr.assign(First, End);
cv::Mat inputArrMat = cv::Mat(inputArr, CV_8UC1);
cv::Mat d = inputArrMat.reshape(1,4).t();
vector<float> csvRead(string air_root) {
vector<float> tmp;
ifstream inFile(air_root, ios::in);
if (!inFile)
{
cout << "open film failed" << endl;
exit(1);
}
int i = 0;
string line;
string field;
while (getline(inFile, line))
{
istringstream sin(line);
while (getline(sin, field, ',')) {
tmp.push_back(atof(field.c_str()));
}
i++;
}
inFile.close();
return tmp;
}
# 通过opencv读取照片,转换灰度值,剪裁操作,resize操作,转换成ndarray并标准化
Mat image = imread(camera_root);
cvtColor(image, image,COLOR_BGR2GRAY);
image.convertTo(image,CV_32FC1,1/255.0);
cv::Mat img1 = image(Rect(1052,0,448,300));
img1 = (img1-0.485)/0.229
6.onnxruntime Cpp部署
const wchar_t* model_path = L"C:/Users/DELL/Desktop/onnx/best-sim.onnx"; win用这行读取
//const char* model_path = "C:/Users/DELL/Desktop/onnx/best-sim.onnx"; linux用这行读取
Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING, "onnx");
Ort::SessionOptions session_options;
//调用线程数目
session_options.SetInterOpNumThreads(5);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
Ort::AllocatorWithDefaultOptions allocator;
Ort::Session session(env, model_path, session_options);
// printModelInfo(session, allocator);
//model info
// 获得模型又多少个输入和输出,一般是指对应网络层的数目
// 一般输入只有图像的话input_nodes为1
size_t num_input_nodes = session.GetInputCount();
// 如果是多输出网络,就会是对应输出的数目
size_t num_output_nodes = session.GetOutputCount();
//获取输入name
const char* input_name = session.GetInputName(0, allocator);
//std::cout << "input_name:" << input_name << std::endl; 下面的input.1靠这行打印看到
//获取输出name
const char* output_name = session.GetOutputName(0, allocator);
//std::cout << "output_name: " << output_name << std::endl; 下面的188靠这行打印看到
// 自动获取维度数量
auto input_dims = session.GetInputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
auto output_dims = session.GetOutputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
//std::cout << "input_dims:" << input_dims[0] << std::endl;
//std::cout << "output_dims:" << output_dims[0] << std::endl;
vector<const char*> input_names{ input_name };
vector<const char*> output_names = { output_name };
vector<const char*> input_node_names = { "input.1" };
vector<const char*> output_node_names = { "188" };
//创建输入tensor
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
vector<Ort::Value> input_tensors;
input_tensors.emplace_back(Ort::Value::CreateTensor<float>(memory_info, input.ptr<float>(), input.total(), input_dims.data(), input_dims.size())); ///函数里的input参数就是上一小节预处理完的cv::Mat
/*cout << int(input_dims.size()) << endl;*/
clock_t startTime = clock();
//推理(score model & input tensor, get back output tensor)
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), input_tensors.data(), input_names.size(), output_node_names.data(), output_node_names.size());
clock_t endTime = clock();
//assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
float* floatarr = output_tensors[0].GetTensorMutableData<float>();
cout << "The iop is:" << floatarr[0] << endl;
cout << "The run time is:" << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
我个人测试是python和c++的部署cpu推理时间两者是差不多的,大家也可以试一试
另opencv c++的矩阵处理时间与numpy的处理时间也差不多。
7.pytorch转ncnn
model = Kangaroo() #读取模型结构
model.load_state_dict(torch.load('./best.pt')) #读取模型参数
traced_cell = torch.jit.trace(model, example_data.to(torch.float32))
# (更新参数的模型类,定义数据类型的输入例子)
traced_cell.save('best_ts.pt') # 生成torchscript模型
print(traced_cell.conv1.code) # 打印具体某一层的卷积
print(traced_cell.code) # 打印整个模型数据结构
来到pnnx的github下载转换文件https://github.com/pnnx/pnnx/releases
下载对应系统的文件解压,命令行来到这个解压后的文件夹
pnnx.exe best_ts.pt inputshape=[1,3,224,224]
# pnnx.exe文件 torchscript文件 输入例子的大小

我训练的best_ts.pt文件的输入大小是1,1,300,900。所以我图片就写这个了,然后会生成一堆文件,选下面的这两个文件。

这两个文件就是我们想要的ncnn模型文件。
8.ncnn推理
将cv的Mat类转为ncnn的Mat类,这里可以参考官方https://github.com/Tencent/ncnn/wiki/use-ncnn-with-opencv
上接第四小节 4.c++数据处理,img1为预处理完的cv::Mat
ncnn::Mat in(img1.cols, img1.rows, 1, (void*)img1.data);
in = in.clone();
因为我的数据类型是float32,然后是灰度图1通道的,
这个也是和前面的输入例子的大小是对应的。
输入大小是[1, 1, 300, 900] -> [batch_size, channel, rows/h, cols/w]
所以我是cv::Mat CV_32FC1 -> ncnn::Mat 1 channel

数据预处理了后就是加载模型
ncnn::Net net;
net.load_param("C:\\Users\\Kangaroo\\Desktop\\ncnn\\best_ts.ncnn.param");
net.load_model("C:\\Users\\Kangaroo\\Desktop\\ncnn\\best_ts.ncnn.bin");
然后传入输入Mat,得到输出Mat
ncnn::Mat out;
ncnn::Extractor ex = net.create_extractor();
ex.set_light_mode(true);
ex.set_num_threads(4);
ex.input("in0", in); //注意,先看后文
ex.extract("out0", out); //注意,先看后文
pretty_print(out);
同样由于我的项目没有数据后处理,我就拿一个函数直接打印了。
当然这其中有个地方需要注意,打开前面的param文件

最前面的输入层名字是in0,再拉到最后面看到输出层名字是out0。
所以上面的两个位置填in0与out0

这样就可以完成ncnn部署了,配合AndroidStudio可以安卓端部署。
感觉这个系列可以完结了,之前只介绍了cuda设备的部署,一直觉得有遗憾,现在终于补全了。我觉得有详细介绍了框架安装,训练模型以及多个平台设备的部署了,之后有可能的话会再补全一下ios和安卓的部署,希望能帮助到大家的项目/学业/毕设/论文。
yolov5笔记(1)——安装pytorch_GPU(win10+anaconda3)
yolov5笔记(2)——训练自己的数据模型(随6.0更新)
yolov5笔记(3)——移动端部署自己的模型(随5.0更新)
yolov5笔记(4)——CPU部署以及NCNN