DETR系列之 MDETR - Modulated Detection for End-to-End Multi-Modal Understanding 论文笔记
DETR系列之 MDETR - Modulated Detection for End-to-End Multi-Modal Understanding 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- 四、方法
-
- 4.1 背景
-
- 4.1.1 DETR
- 4.2 MDETR
-
- 4.2.1 架构
- 4.2.2 训练
-
- Soft token prediction
- Contrastive alignment
- 五、实验
-
- 5.1 合成图像
- 模型
- 监督
- 训练
- 结果
- 5.2 自然图像
-
- 5.2.1 预训练的模块化检测
-
- 结合
- 模型
- 5.2.2 下游任务
-
- 短语定位
- 参考表达式理解
- 参考表达式分割
- 视觉问答
- 5.2.3 少样本迁移用于长尾检测
写在前面
时隔几个月没完整地写一篇论文笔记了,下一个目标,开始行动了。
- 论文地址:MDETR - Modulated Detection for End-to-End Multi-Modal Understanding
- 代码地址:https://github.com/ashkamath/mdetr
- 收录于:ICCV 2021
一、Abstract
指出当前依赖于预训练目标检测器的多模态推理系统是个黑箱模型(通常在固定类别和属性的下游任务上训练),因此很难捕捉无特定形式的长尾视觉概念。本文提出了端到端的MDETR,用于检测给定问题/字幕文本中对应的图像目标。预训练 1.3M 图像-文本对,然后在下游任务(短语定位,参考表达式理解和分割)。同时验证了少样本的性能。数据集选用 GQA、CLEVR。
二、引言
第一段指出单模态目标检测无法适应多模态的情况,同时不能识别由本文表达出的视觉目标。第二段指出最近的一些工作考虑了单阶段或者两阶段的目标检测器,但是目前还没有证据表明这些工作能够提升需要推理的下游任务的性能。第三段提出本文的方法,基于DETR的多模态推理方法。
本文贡献如下:
- 从DETR中引入了一个端到端的文本模块化检测系统;
- 能够在参考表达式理解,短语定位上达到新的SOTA;
- 检测性能可以自然迁移到下游任务中:视觉问答,参考表达式分割,少样本长尾目标检测。
三、相关工作
CLEVR数据集的介绍,单双流预训练Transform的介绍,指出弱点,还可以做到紧凑结合的结构。然后是一些参考文献的介绍,从模型提取视觉特征到多模态的参考表达分割。
四、方法
4.1 背景
4.1.1 DETR
推荐看DETR的论文:End-to-end object detection with transformers
4.2 MDETR
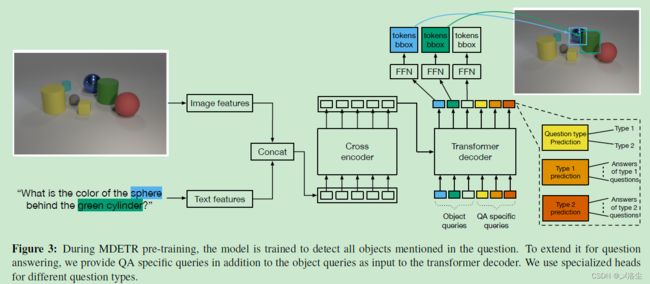
4.2.1 架构

上图是本文提出的MDETR的架构,图像用CNN抽取特征,文本用预训练的Transformer语言模型抽取特征,之后每个特征接个线性投影将其映射到同一 embedding 空间,之后拼接送入Transformer编码器中,在之后利用解码器输出其隐藏状态,来输出预测的真实边界框。
4.2.2 训练
采用两个额外的损失函数来训练MDETR:soft token prediction loss(无参数的对齐损失); text-query contrastive alignment loss(有参数的文本-序列对比联合):强制目标序列和token之间的对齐相似度。
Soft token prediction
首先设置任何所给句子的 token 长度 L=256,使用双边匹配将每一个预测的box对应于一个GT box,模型在所有 token 位置上去预测对应于目标的统一分布。(原文这一块语言组织的非常糟糕,服了,混乱的语言?搞不清楚到底在干啥。)
Contrastive alignment
贴出公式,细节描写不到位,看的头疼。
l t = ∑ i = 0 L − 1 1 ∣ O i + ∣ ∑ j ∈ O i + − log ( exp ( t i ⊤ o j / τ ) ∑ k = 0 N − 1 exp ( t i ⊤ o k / τ ) ) l_{t}=\sum_{i=0}^{L-1} \frac{1}{\left|O_{i}^{+}\right|} \sum_{j \in O_{i}^{+}}-\log \left(\frac{\exp \left(t_{i}^{\top} o_{j} / \tau\right)}{\sum_{k=0}^{N-1} \exp \left(t_{i}^{\top} o_{k} / \tau\right)}\right) lt=i=0∑L−1∣ ∣Oi+∣ ∣1j∈Oi+∑−log(∑k=0N−1exp(ti⊤ok/τ)exp(ti⊤oj/τ))
五、实验
5.1 合成图像
CLEVR数据集,额,看着语言描述很糟糕。
模型
ResNet-18的图像模型,预训练 ImageNet 上,DistilRoberta 的语言模型,DETR的主体模型
监督
CLEVR数据集并没有bounding box标注,因此用场景图的方式再创造出来,MDETR仅预测问题中的一个目标。
训练
先从整个CLEVR数据集提取15%的只含有一个指代目标的集合作为子集。采用循环学习的策略:首先在剩下的集合中训练30个epoch,然后30个epoch在整个数据集上训练,两个损失都用上。
结果

5.2 自然图像
5.2.1 预训练的模块化检测
检测出文本所指向的所有目标
结合
总量1.3M的数据集
模型
预训练的RoBERTa-base,12层Transform编码器,768维度,12头
5.2.2 下游任务
4个下游任务,参考表达理解和分割,视觉问答,短语定位。
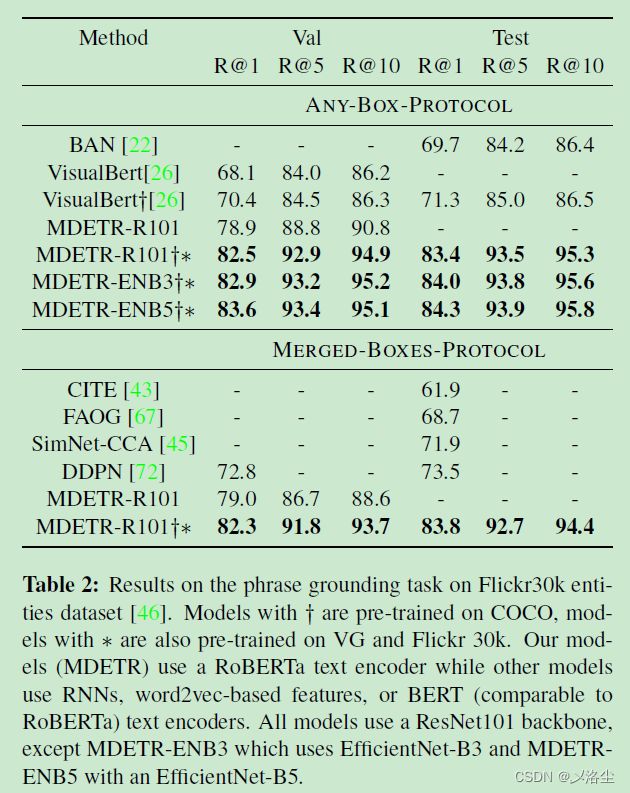
短语定位
Flickr30K实体数据集
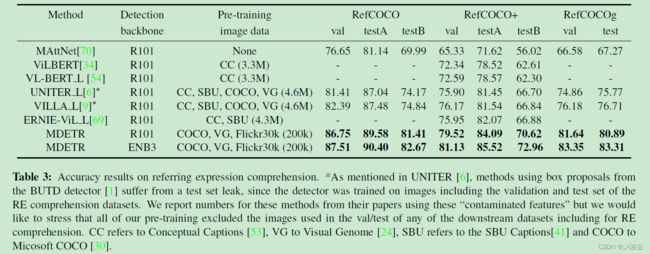
参考表达式理解
只需要返回一个目标即可。
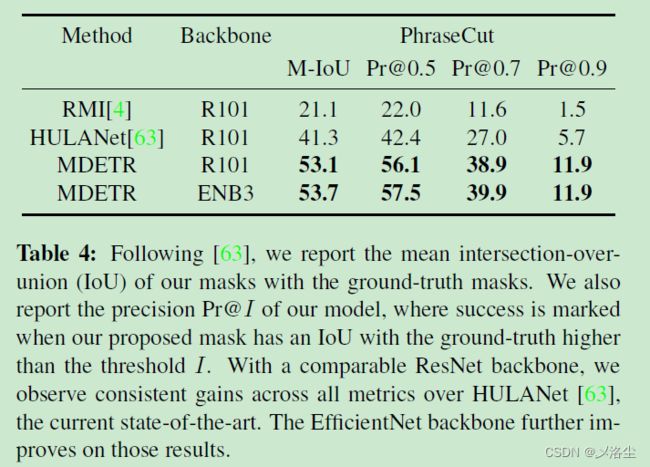
参考表达式分割
数据集:PhraseCut,需要找到所有目标。模型训练40个epoch,然后在PhraseCut微调5个epoch。
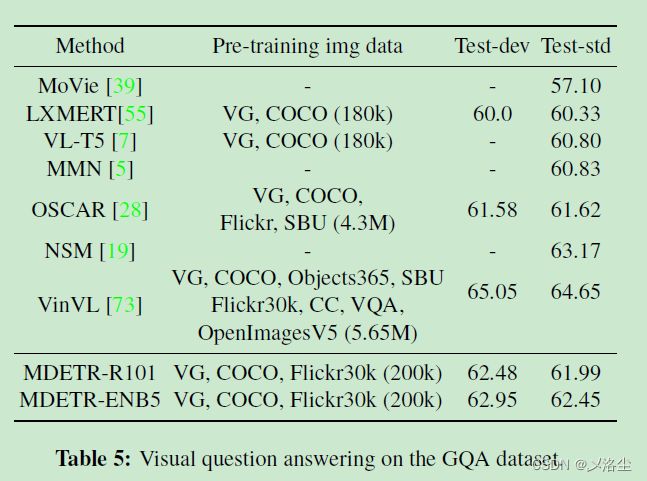
视觉问答
数据集:GQA,训练40次在自己的组合数据集上,然后在不平衡数据集上微调5个epoch,在平衡数据集上微调10次epoch
5.2.3 少样本迁移用于长尾检测
数据集:LVIS。

写在后面
后面附录部分没写,感觉整个文章写得太混乱了,数据集太多,任务太多,实验太多,实验技巧太多,语言组织混乱。结构部分写得简短,整篇文章靠数据集上的实验充实其工作量。就两个字总结:混乱。给自己的忠告,少写这类文章,脑壳疼