【Journal of Computer-Aided Design & Computer Graphics】基于生成对抗网络的行人重识别方法研究综述

文章目录
- 引言
- 数据集介绍
- 基于GAN的行人重识别方法分类
-
- 2.1基于风格转换的方法
- 2.2基于数据增强的方法
- 2.3基于不变性特征学习的方法
- 3 基于GAN的方法性能对比分析
- 总结
引言
对于行人检测, 已有多种精度较高的算法, 如**YOLO[5], SSD[6]和Fast R-CNN[7]**等, 均可获得高质量的检测结果.
行人重识别在真实场景中仍然面临诸多挑战:
- 深度学习的方法依赖大量的训练数据, 目前公开的数据集标注的行人数据规模有限, 并且不同的行人重识别数据集之间存在域差, 即在不同数据集上分别训练和测试时会导致性能的严重下降, 使模型很难泛化到其他应用场景[53]
- 同一数据集内不同摄像头拍摄背景、分辨率和光照的变化会导致图像风格差异, 相同的行人在不同摄像头中的姿态和外观变化大, 并且不同行人可能具有相同的外观和姿态。
利用生成对抗网络(generative adversarial networks, GAN)进行图像风格转换或统一不同图像风格, 缓解不同数据集之间或同一数据集内的图像风格差异[53,55-62]
本文更**聚焦GAN这一特定技术在行人重识别任务中的发展和应用.**这类方法属于目前研究热点, 并且可以反映基于GAN的行人重识别方法的研究趋势。
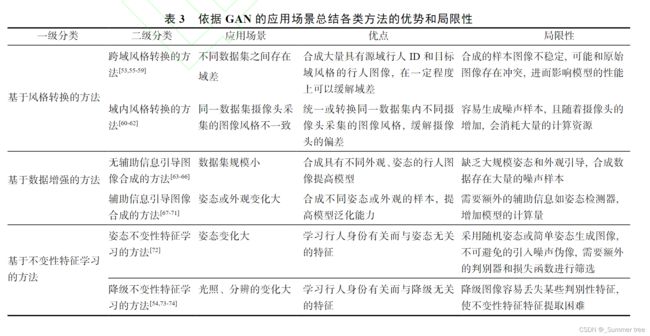
基于GAN的方法分类:
- 基于风格转换的方法
- 跨域风格转换的方法[53,55-59]
- 域内风格转换的方法[60-62]
- 数据增强的方法
- 无辅助信息引导的图像合成方法[63-66]
- 辅助信息引导的图像合成方法[67-71]
- 不变性特征学习的方法
- 姿态不变性特征学习的方法[72]
- 降级不变性特征学习的方法[54,73-74]
数据集介绍
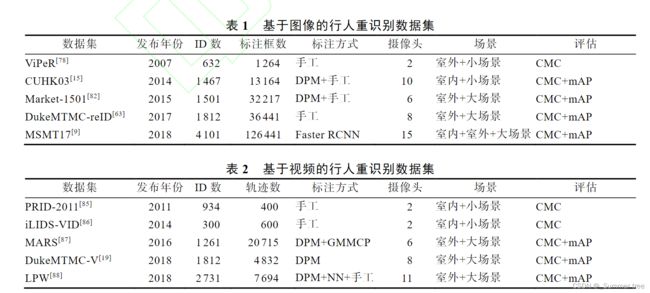
- VIPeR数据集[78]是最早提出的小型行人重识别数据集. 由2个摄像头在校园采集得到, 且每个视角的摄像头只拍摄行人的一幅图像, 总共包含632个不同行人的1264幅图像, 每幅图像都被裁剪并缩放为128 48的大小, 采用手工标注行人检测框
- CUHK03数据集[15]属于大规模行人重识别数据集. CUHK03数据集在CUHK01数据集[79]和CUHK02数据集[80]的基础上进行改进, 增加了摄像头和采集图像的数量, 可以采集更多视角下的行人图像. 该数据集采用**手工标记和自动检测器(deformable part model,DPM)[81]**这2种方式标注行人检测框, 相比单一的手工标注, DPM标注的行人更符合真实场景
- Market-1501数据集[82]是在2015年公布的大规模行人重识别数据集. 包含1501个不同行人的总共32668幅图像, 每幅图像的大小为128 64, 采用手工标记和自动检测器DPM这2种方式标注行人检测框. 相比CUHK03数据集, Market-1501数据集包含502793个干扰因素和更多的标注图像.
- DukeMTMC-reID数据集[63]是多摄像头多目标行人跟踪数据集DukeMTMC[83]的子集同样属于大规模行人重识别数据集. 每幅图像的大小不定, 采用手工标注行人检测框.
- MSMT17数据集[9]是在2018年公布的一个大规模行人重识别数据集.其中的行人图像是由校园内的15个摄像头采集得到的, 包含4101个不同行人的总共126441幅图像, 每幅图像的大小不定, 采用行人自动检测器Faster R-CNN[84]标注行人检测框.该数据集覆盖了更多的场景, 并且能够捕获多个时间段光照变化的行人图像.
另外, 大多主流数据集均采用累计匹配特征(cumulative matchingcharac-teristics,CMC)曲线和平均均值精度(mean average precision, mAP)进行性能评估
基于GAN的行人重识别方法分类
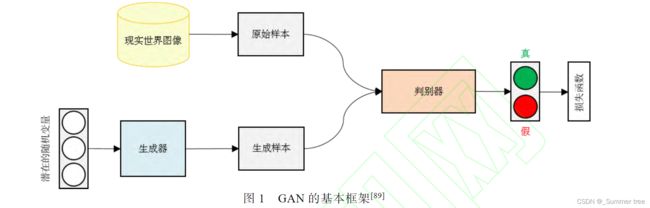
GAN的工作原理: 利用GAN
的生成器将真实图像特定的像素迁移到生成图像上, 并使用判别器判断生成图像的真伪, 然后反馈给生成器以生成更相似的图像.
2.1基于风格转换的方法

在训练阶段, 生成器ABG将图像1从风格A转换成风格B, 生成器BAG将图像从风格B转换成风格A;判别器BD判断生成的图像是否逼近原始图片2的风格B. 通过最小化判别损失和2L损失, 使生成器和判别器不断对抗直至收敛[75], 最终实现AB的风格转换. 本文根据风格转换数据域的不同, 将风格转换方法归纳为2类: 基于跨域风格转换的方法和基于域内风格转换的方法.
基于跨域风格转换的方法:
为了解决域差, 传统有监督图像到图像的转换方法使用对齐的图像对训练模型, 以学习输入图像到输出图像之间的映射, 但大规模的标注图像对在现实任务中很难实现. 因此, 当目标域未进行行人标注时, 有监督的单域行人重识别方法会受限[55]
解决此类问题的常用策略是利用GAN进行跨数据域的风格转换.:
- **CycleGAN[90]**可以实现任意2幅图像风格的转换, 研究者考虑在其基础上改进, 以实现不同数据集之间的自适应行人样式转换, 从而缩小或消除域差.
- PTGAN:
- Wei等[53]提出人员转移GAN(persontransferGAN, PTGAN), 在保留源域中行人身份的前提下, 将源域中的行人转移到目标数据集, 使源域中的行人具有目标域的背景和光照样式.
- PTGAN是随机生成行人图像, 生成样本中可能存在未知的噪声.
- Deng等[55]利用孪生网络和CycleGAN组成相似性保留GAN(similarity preserving GAN, SPGAN), 以无监督的方式将有标签的行人从源域迁移到目标域.
上述方法都是基于单一因素的风格转换. 实际上, 域差可能由多个因素(如光照、分辨率和摄像头视角)的变化引起[98], 并且不同图像受到这些因素影响的程度不同, 使单一因素样式转换的方法识别性能不佳.
下面考虑多因素:
Liu等[56]提出一种自适应转移网络(adaptive transfer network, ATNet), 其网络结构如图3所示.
ATNet使用3个CycleGAN实现摄像头视角、光照和分辨率的风格转换, 并根据不同因素影响的程度自适应地为每个CycleGAN分配权重, 从而进行精确的风格转换.
- Zhong等[58]不仅考虑不同数据集之间的域差, 同时考虑目标域内摄像头的风格差异对跨域自适应行人重识别性能的影响, 提出一种异构同质学习(hetero-homogeneous learning, HHL)方法.
基于域内风格转换的方法
- Zhong等[60]引入相机样式(camerastyle, CamStyle)

- CamStyle首先使用CycleGAN将标注的训练数据迁移到不同的摄像头, 使合成的样本在保留行人标签的同时具有不同摄像头的风格, 以此平滑同一数据集内不同摄像头之间的风格差异;
- 将生成图像加入训练集增加多样性, 以防止过拟合, 并引入**标签平滑正则化(label smooth regularization, LSR)**减少噪声的影响.
CamStyle 存在的问题:
(1) 当同一数据集内不同摄像头拍摄的图像之间存在较大的风格差异时, CycleGAN生成的转移样本会产生更多的失真图像, 使模型引入噪声, 并需要额外的LSR调整网络的性能。
(2)生成的不同风格的图像只能作为扩展训练集, 当出现无效的生成样本时会严重影响训练模型的鲁棒性.
(3) CamStyle为每个摄像头生成不同风格的行人图像, 随着摄像头的数量增加, 需要训练的模型数量越来越多, 将消耗大量的计算资源, 在实际场 景中并不适用。
- 针对上述存在的问题, Liu等[61]提出统一风格自适应的方法, 称为UnityStyle, 其工作流程如图5所示.

该方法可以平滑同一摄像头以及同一数据集内不同摄像头之间的样式差异. 通过为每个摄像头生成形状稳定的风格图像, 消除不同图像之间的风格差异, 并将真实图像和合成图像共同训练以增强训练集, 以提高行人匹配的准确率。
优点:
- UnityStyle合成的样本近乎原始图像, 无需引入LSR消除噪声的影响,
- 并且UnityStyle为所有的摄像头统一样式, 无需额外训练大量的模型.
GAN的摄像头风格的转换也应用于红外和可见光之间的相互转换. Wang等[62]提出一种双级差异减少学习(dual-level discrepancy reduction learning, D2RL)方案, 通过分解形态和外观差异, 可以实现红外图像和可见光图像的相互转换
基于风格转换的方法总结


表4的第1部分为以DukeMTMC-reID作为源域数据集, Market-1501作为目标域数据集**(Duke→Market)的跨域风格转换的方法. 从实验结果来看, 增加三元组损失约束可以提高跨域风格转换行人重识别的准确度.
表4的第2部分为域内图像风格转换的方法**, 转换的策略主要是以合成同一数据集内不同摄像头风格的样本或统一不同摄像头风格为主. 从Market-1501数据集上的实验结果可以得到, 统一摄像头风格的方法能够得到更好的识别性能.
在未来的研究中, 设计GAN生成更高质量的多样化行人样本、更优的损失函数约束模型对判别性特征和不变性特征的学习以及更高效的训练策略, 是解决上述问题的研究重点
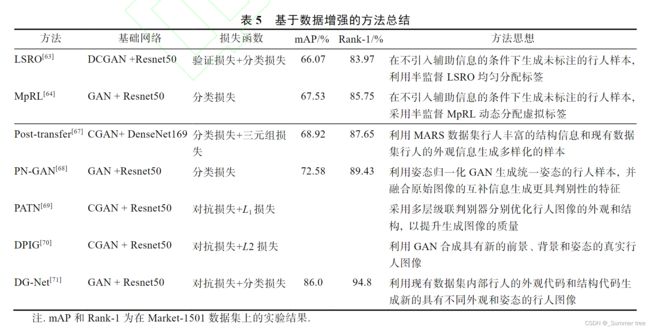
2.2基于数据增强的方法
基于数据增强的方法从模型的训练出发, 通过增加多样性的训练数据提高模型的泛化能力.
基于无辅助信息引导的图像合成方法
-
深度卷积GAN(deep convolutional AGN, DCGAN)[94]:
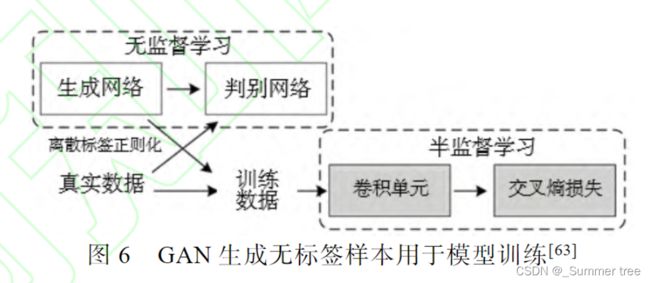
- 首先, 通过无监督学习的方式, 使用原始训练数据生成未标注的行人样本;
- 然后, 通过半监督学习的方式, 利用离散标签正则化(label smoothingregularization for outliers, LSRO) 为未标注图像均匀分配标签.
-
Huang等[64]提出一种多伪正则化标签(multi-pseudo regularized label, MpRL), 为每个生成的样本分配一个适当的虚拟标签, 以建立真实图像和生成图像的对应关系,
无辅助信息引导的GAN存在以下问题 :
- (1)这类方法只关注生成图像的视觉效果, 生成样本的质量得不到保证, 容易生成一些严重扭曲的噪声图像, 从而影响训练模型的性能;
- 传统无辅助信息引导的方法没有充分利用行人的结构和外观信息, 生成的图像不能很好地指导模型对判别性特征的学习, 极大地限制了生成样本的有效使用[67]
基于辅助信息引导的图像合成方法
-
Liu等[67]引入行人姿态信息辅助GAN生成样本.
- 首先, 利用MARS[87]数据集的丰富行人信息引入大量行人骨架结构特征, 以构建姿态引导模型;
- 然后, 将得到的姿态信息和现有数据集行人的外观信息进行配准
- 最后, 利用GAN生成同时具有MARS数据行人的姿态结构和现有数据集行人外观的样本图像. 将骨架姿态和外观特征进行重构。
-
Qian等[68]利用姿态归一化: GAN(pose-normalization GAN, PN-GAN)生成具有统一体态的行人图像
- 首先, 利用PN-GAN合成具有不同姿势的辅助图像
- 然后, 通过2个基础网络分别学习原始图像和合成图像的互补特征
- 最后, 将2种类型的特征进行融合用作最终行人重识别任务的特征匹配
- 为了生成更丰富多样的行人图像, Ma等[70]利用GAN将输入图像的3种变化因素(前景、背景和姿态)解构并编码为嵌入特征, 采用对抗性方式学习特征映射, 生成具有新的前景、背景和姿势的真实人物图像.
大多数方法生成器和判别器相互分离, 仅采用独立的生成模型生成图像, 可能使生成模块的优化无法与行人重识别任务匹配, 限制了生成数据的可扩展性
- Zheng等[71]提出将判别器和生成器结合的学习框架, 其结构如图8所示.
生成模块利用现有数据集内部的行人外观和结构编码生成新的图像, 判别模块与生成模块共享外观编码器, 并作为行人重识别的主干网络. 通过切换外观和结构编码, 可以生成高质量的交叉外观和结构的行人图像. 该框架仅利用现有数据集的行人姿态和外观就能够合成多样性的行人样本。
基于数据增强的方法总结:
2.3基于不变性特征学习的方法
现实场景下的行人重识别任务包含:
- 高级视觉变化: 主要包括行人的遮挡、姿态和摄像头视角的变化等;
- 低级视觉变化[54] 主要包括分辨率、光照和天气变化等
基于姿态不变性特征学习的方法
- Ge等[72]提出特征提取GAN(feature distilling GAN, FD-GAN), 学习与行人身份相关而与姿态无关的特征, 用以进行具有姿势变化的行人重识别, 其网络结构如图9所示.
FD-GAN采用孪生网络结构进行特征学习, 每个分支由一个图像编码器和图像生成器组成.
1. 前者根据输入图像学习行人鲁棒性的与身份相关而与姿势无关的嵌入视觉特征,
2. 后者根据编码器的姿态信息和输入行人特征合成新的行人样本
3. 身份判别器、姿态判别器、验证分类器和相同姿势损失共同作用确保学习更多姿态不变性特征
4. 该方法无需额外的计算成本或辅助姿态信息, 并且在Market-1501, CUHK03和DukeMTMC-reID数据集上具有先进性的实验结果.
- Chen等[73]提出一种端到端的自适应分辨率行人重识别网络(resolution adaptation and re-identification network, RAIN), 通过在低分辨率图像和高分辨率图像特征上增加对抗损失, 学习和对齐不同分辨率行人图像的不变特征.
- Li等[74]提出的模型除了可以学习不同分辨率行人图像的不变性特征, 还能够利用SR恢复低分辨率图像丢失的细粒度细节信息, 有助于判别性特征的学习.
- Huang等[54]提出一种降级不变性学习框架, 借助自我监督和对抗性训练策略, 可以保留与身份相关的鲁棒性特征并删除与降级相关的特征.
基于不变性特征学习的方法总结:

不变性特征学习的方法通过学习与行人身份相关, 而与姿态、分辨率和光照无关的特征, 能够缓解行人特征未对齐的问题, 提高行人身份匹配的准确度。
这类方法依然存在不足:
- (1)姿态不变性特征学习的方法采用随机姿态或简单姿态生成图像, 因此不可避免地引入噪声伪像, 需要额外的判别器和损失函数对生成的图像进行筛选, 增加了网络的复杂程度;
- (2)低分辨率图像容易丢失细粒度的区分信息, 使学习高分辨率图像和低分辨率图像的不变性特征变得困难.
- 在未来的研究中, 设计更加简单、高效的模型, 挖掘姿态、分辨率和光照不变性特征, 依然是值得关注的研究内容
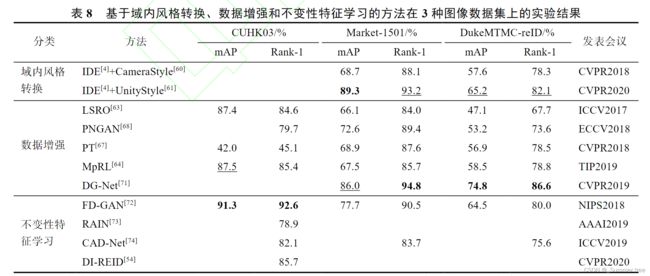
3 基于GAN的方法性能对比分析
*
总结
存在问题的一些方面。
- 高质量数据集的获取。
- 模型的跨域自适应
- 特征的对齐.
- 端到端生成模型与行人重识别模型的设计