情感分析的不同方式比较
1 词袋模型
首先利用词袋 模型对文本进行向量化处理,利用传统的机器学习分类算法进行分析,如logistics,svm以及朴素贝叶斯,其中很多文献上都表明,SVM是分类算法中效果最优的选择,因此这里以SVM为例演示:
import joblib
import pandas as pd
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import classification_report
# 读取数据,并增加新列标注出正负向,最后拼接在一起
dfpos = pd.read_excel("购物评论.xlsx", sheet_name = "正向", header=None)
dfpos['y'] = 1
dfneg = pd.read_excel("购物评论.xlsx", sheet_name = "负向", header=None)
dfneg['y'] = 0
df0 = dfpos.append(dfneg, ignore_index = True)
stoplist=open('哈工大停用词表.txt','r',encoding='utf-8').read()
cuttxt = lambda x: " ".join(jieba.lcut(x)) # 这里不做任何清理工作,以保留情感词
df0["cleantxt"] = df0[0].apply(cuttxt)
# 生成词频矩阵
countvec = CountVectorizer(min_df = 5) # 出现5次以上的才纳入
wordmtx = countvec.fit_transform(df0.cleantxt)
# 按照7:3生成训练集与测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
wordmtx, df0.y, test_size=0.3) # 这里可以直接使用稀疏矩阵格式
# 使用SVC进行建模
from sklearn.svm import SVC
clf=SVC(kernel = 'rbf', verbose = True,probability=True)
clf.fit(x_train, y_train) # 内存占用可能较高
clf.score(x_train, y_train)
print(classification_report(y_test, clf.predict(x_test)))
# 保存模型
#joblib.dump(clf, 'cdmodel.pkl')
#model = joblib.load('cdmodel.pkl')
data = open('物流评论小样本.txt','r',encoding='utf-8').readlines()
seg_word=[]
for sentence in data:
c_words=jieba.lcut(sentence)
seg_word.append(''.join(c_words))
result=[]
for sample in seg_word:
words_vecs = countvec.transform([sample]) # 数据需要转换为可迭代格式
result.append(pd.DataFrame(clf.predict_proba(words_vecs)))
prob=[]#每条评论为积极的概率
for i in result:
prob.append(i[1])
a = pd.DataFrame(prob)
a.to_excel('预测概率.xlsx')
2 分布式表达
分布式表达是基于词袋模型不能很好的考虑语句环境即上下文的缺陷而提出的,它其实就是在分类算法前单独训练了一个word2vec模型来得到语义相似度使分类的结果更加准确。所以,顾名思义,为分布式表达。
import joblib
import pandas as pd
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import classification_report
# 读取数据,并增加新列标注出正负向,最后拼接在一起
dfpos = pd.read_excel("购物评论.xlsx", sheet_name = "正向", header=None)
dfpos['y'] = 1
dfneg = pd.read_excel("购物评论.xlsx", sheet_name = "负向", header=None)
dfneg['y'] = 0
dfword2vec = pd.read_excel("购物评论.xlsx", sheet_name = "word2vec语料", header=None)
df0 = dfpos.append(dfneg, ignore_index = True)
def my_cut(text):
jieba.load_userdict("自定义词典.txt")
stoplist=open('哈工大停用词表.txt','r',encoding='utf-8').read()
return [word for word in jieba.cut(text) if word not in stoplist]
# 分词和预处理,要求返回list格式,dataframe里面嵌套一个list
df0['cut'] = df0[0].apply(my_cut)
#生成用于相似度训练的语料
word2vec=[]
for i in dfword2vec[0]:
word2vec.append(my_cut(i))
# 按照7:3生成训练集与测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
df0.cut, df0.y, test_size=0.3)
#word2vec模块
from gensim.models.word2vec import Word2Vec
n_dim = 300 # 指定向量维度,大样本量时300~500较好
w2vmodel = Word2Vec(vector_size = n_dim, min_count = 0)
w2vmodel.build_vocab(word2vec) # 生成词表
w2vmodel.train(word2vec,total_examples = w2vmodel.corpus_count, epochs = 10)
#w2vmodel.wv.most_similar("新鲜")
pd.DataFrame([w2vmodel.wv[w] for w in df0.cut[0] if w in w2vmodel.wv]).head()
#分类算法模块
def m_avgvec(words, w2vmodel):
return pd.DataFrame([w2vmodel.wv[w]
for w in words if w in w2vmodel.wv]).agg("mean")
train_vecs = pd.DataFrame([m_avgvec(s, w2vmodel) for s in x_train])
#用均值填补一下矩阵的缺失值,以防之后报错
train_vecs.fillna(train_vecs.mean(),inplace=True) # 填充均值
import numpy as np
test = np.isnan(train_vecs).any()
from sklearn.svm import SVC
clf2 = SVC(kernel = 'rbf', verbose = True,probability=True)
clf2.fit(train_vecs, y_train) # 占用内存小于1G
clf2.score(train_vecs, y_train)
print(classification_report(y_train, clf2.predict(train_vecs)))
#data = list(pd.read_excel('最新评论.xlsx')['评价内容'])
data = open('物流评论小样本.txt','r',encoding='utf-8').readlines()
seg_word=[]#格式类型要与df[0]保持一致,即list of list格式
for sentence in data:
c_words=my_cut(sentence)
seg_word.append(c_words)
vec=[]
for sample in seg_word:#sample是类型为list的一条评论分词的结果
words_vecs =pd.DataFrame(m_avgvec(sample, w2vmodel)).T
vec.append(words_vecs)
result=[]
for i in vec:
result.append(pd.DataFrame(clf2.predict_proba(i)))
prob=[]
for i in result:
prob.append(i[1])
a = pd.DataFrame(prob)
a.to_excel('分布式模型预测概率.xlsx')
这里需要注意的是,由于分类算法是在word2vecm模型的基础上进行分类的,所以要保证用于SVM训练的语料在word2vec中全部要存在,否则系统会报错“AttributeError: 'int' object has no attribute 'decode'”这个问题卡了我好几天,同样的代码同样格式的文本,但不同内容有的报错有的能运行,最后仔细回顾了代码,发现是word2vec的词表不全,因此最好单独为语义相似度的训练设置一个语料库,简言之即用于分类的训练集与测试集要为语义相似度训练语料的子集。也有可能是word2vec模型训练时候过滤的低频词太多了,把一些超短评论给过滤掉了。
3 模型评价
3.1 词袋模型评价

3.2 分布式模型评价
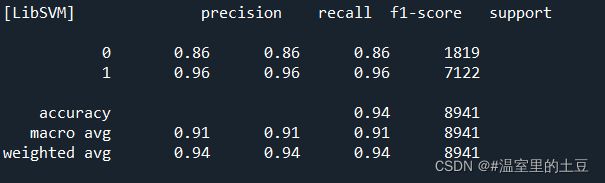
3.3 选择与比较
两种模型的优劣并没有一锤定音的结果,一直处于争论之中,具体要看项目或论文使用情况,但仅从效果来看,显然,分布式算法更为准确。