疫情微博内容情感分析
一.前言
最近,碰到一个疫情微博情感分类的任务看到挺有意思的,就试了试手,顺便记录了下整个实验的全过程,话不多说,请看下文。
二.数据集简介与预处理
2.1 数据集简介
数据集为疫情期间在微博收集的,原始数据集的存储格式为TXT,其中存储的是一个py的列表对象,列表中包含的每条元素都为一条微博内容及其对应的标签,这里摘取了训练集中的一条数据来进行直观的展示:
{"id": 26, "content": "#全国确诊新型肺炎病例# http://t.cn/RXnNTiO ??福州", "label": "neural"}
整个数据集共包含10606条数据,其中训练集有8606条,测试集有2000条数据。数据集的微博内容按情感类别分为如下的6种:
- neural: 无情绪
- happy: 积极
- angry: 愤怒
- sad: 悲伤
- fear: 恐惧
- surprise: 惊奇
2.2 数据集预处理
对于微博内容,我们首先需要进行数据的清洗以及分词,分词可以用jieba分词,但我在github上看到有大佬实现了专门对微博的内容的清洗以及利用pynlpir进行分析 (传送门),抱着偷懒的心思,这里就直接站在前人的肩膀上了,下面给出对微博内容的清洗源码:
def weibo_process(content):
"""
功能:清洗微博内容并分词
"""
processed_content = []
# Replaces URLs with the word [URL]
content = re.sub(r'(https?|ftp|file|www\.)[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]', '[URL]', content)
# Replaces Email with the word [URL]
content = re.sub(r'[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+[\.][a-zA-Z0-9_-]+', '[URL]', content)
# Replaces user with the word FORWARD
content = re.sub(r'(\/\/){0,1}@.*?(:|:| )', '[FORWARD]', content)
# Replaces number with the word [N]
content = re.sub(r'\d+', '[N]', content)
# Replace 2+ dots with space
content = re.sub(r'[\.。…]{2,}', '。', content)
# Replace 2+ ~~ 为 ~
content = re.sub(r'~{2,}', '~', content)
# Replace 2+ 叹号 为 一个叹号
content = re.sub(r'[!!]{2,}', '!', content)
# Replace 2+ 叹号 为 一个问号
content = re.sub(r'[??]{2,}', '?', content)
# 去掉 //
content = re.sub(r'//', ' ', content)
# 去掉 引号
content = re.sub(r'["“”\'‘’]', '', content)
pynlpir.open(encoding='utf_8', encoding_errors='ignore')
segments = pynlpir.segment(content, pos_tagging=False)
i = 1
count = len(segments) - 1
for segment in segments:
if re.match(r'\s+', segment): # 过滤掉空格
i = i + 1
continue
segment = re.sub(r'@[\S]+', '[USER_MENTION]', segment)
processed_content.append(segment.strip())
if (i == count) & (segment == '[USER_MENTION]'): # 过滤掉最后一个单独的字
break
i = i + 1
pynlpir.close()
return processed_content
通过json模型我们可以读取原始数据集进行清洗和分词后存储到下来(方便后续的加载),源码如下:
ignore_chars = ["/","@","【","】","#",":","[","]"]
def datasetProcess(org_path,save_path,stop_words):
"""
功能:过滤出微博内容重点中文并进行分词
"""
outcome = []
with open(org_path,"r",encoding="utf-8") as fp:
for idx,item in enumerate(json.load(fp)):
print("processing item {}".format(idx))
content = item.get("content")
label = item.get("label")
# content = "".join(regex.findall(chinese,content))
seg_list = weibo_process(content)
# seg_list = jieba.cut(content,cut_all=False)
words = []
for word in seg_list:
if word in ignore_chars:
continue
if word not in stop_words:
words.append(word)
outcome.append({"content":words,"label":label})
with open(save_path,"w",encoding="utf-8") as fp:
json.dump(outcome,fp,ensure_ascii=False)
停用词表选用的是哈工大的,清洗完成后数据集变成了下面栗子中的样式:
{"content": ["[心]", "健康", "平安", "[FORWARD]", "致敬", "疫情", "前线", "医护", "人员", "愿", "所有", "人", "都", "健康", "平安", "白衣天使", "致敬", "[心]"], "label": "happy"}
完成数据集的清洗和预处理后,我又对清洗后的数据集进行了一波分析,其中训练集和测试机中每条数据(分词后)的平均长度分别为19和20。然后我又分析了各种标签的数据在训练集和测试中的分布:

可以看出,六种标签在训练集和测试集上的分布是基本一致的,由此我们不需要对数据集进行打乱和重新划分。此外,由于神经网络输入的必须是数值类型的数据,因此我们必须得将单词映射为数值,这就需要构建一个单词词典,其对应的源码如下:
def getWordDict(data_path,min_count=5):
"""
功能:构建单词词典
"""
word2id = {}
# 统计词频
with open(data_path,"r",encoding="utf-8") as fp:
for item in json.load(fp):
for word in item['content']:
if word2id.get(word) == None:
word2id[word] = 1
else:
word2id[word] += 1
# 过滤低频词
vocab = set()
for word,count in word2id.items():
if count >= min_count:
vocab.add(word)
# 构成单词到索引的映射词典
word2id = {"PAD":0,"UNK":1}
length = 2
for word in vocab:
word2id[word] = length
length += 1
with open("datasets/word2id.json",'w',encoding="utf-8") as fp:
json.dump(word2id,fp,ensure_ascii=False)
调用该函数得到的单词词典中共包含3493个词,包括"PAD"和"UNK"两个额外添加的词,其中"PAD"主要是用来完成填充词的映射,因为微博句子的长度不同,但神经网络的输入必须要一致,因此就需要进行填充操作。而"UNK"的为了完成未在词典中出现的词的映射。
2.3 Wrod2Vec词嵌入的生成
对于词嵌入的生成,本实验中提供了两种策略:
- 直接调用Pytorch中的
nn.Embedding先随机初始化,然后在训练的过程中不断更新其权重参数。 - 利用
gensim库来生成word2vec词嵌入,然后用nn.Embedding加载该词嵌入,训练的过程中就可以不更新嵌入层的权重。
在本实验中,利用清洗后的训练集来生成word2vec词嵌入的源码如下所示:
train_path = "datasets/train.txt"
sents = []
with open(train_path,"r",encoding="utf-8") as fp:
for item in json.load(fp):
sents.append(item['content'])
model = word2vec.Word2Vec(sents, vector_size=100, window=10, min_count=5,epochs=15,sg=1)
model.wv.save_word2vec_format('word2vec.bin',binary=False)
由源码可见生成的词嵌入维度为100,由于训练的语料库比较小,因此增大了迭代的次数,另外我发现使用Skip-Gram模式得到的词嵌入的效果要比使用CBOW的效果要好。
此外,由于"PAD"和"UNK"两个词在数据集中没有,参考自然语言处理这篇文章,采取的策略是"PAD"的词嵌入向量采用全零初始化,而"UNK"的词嵌入采用的是np.random.randn(embedding_dim)的初始化方式。
2.4 数据集的加载
对于数据集的加载,采用的是基础torch.utils.data.Dataset来自定义数据集,对应的源码如下:
import json
import torch
import torch.utils.data as data
word2id = json.load(open("datasets/word2id.json","r",encoding="utf-8"))
label2id = {
'neural':0,
'happy':1,
'angry':2,
'sad':3,
'fear':4,
'surprise':5
}
# maxlen为每条文本的平均单词数+2倍标准差
class WeiBoDataset(data.Dataset):
def __init__(self,data_path,maxlen=84) -> None:
super(WeiBoDataset,self).__init__()
self.maxlen = maxlen
self.sents,self.labels = self.loadDataset(data_path)
def loadDataset(self,data_path):
sents,labels = [],[]
with open(data_path,"r",encoding="utf-8") as fp:
for item in json.load(fp):
ids = []
for ch in item['content'][:self.maxlen]:
ids.append(word2id.get(ch,word2id["UNK"]))
ids = ids[:self.maxlen] if len(ids) > self.maxlen else ids + [word2id["PAD"]] * (self.maxlen - len(ids))
sents.append(ids)
labels.append(label2id.get(item['label']))
f = torch.LongTensor
return f(sents),f(labels)
def __len__(self):
return len(self.labels)
def __getitem__(self, index):
return self.sents[index],self.labels[index]
在数据集,需要对微博内容的长度进行统一,过长的句子需要截断,过短的句子用"PAD"来填充,句子设置的最大长度maxlen为84。
三.模型设计与实现
对于情感分析,我采用的是BiGRU+Linear模型,其中BiGRU来完成句子信息的抽取,然后通过线性层来对句子进行分类,模型的结构图如下所示:
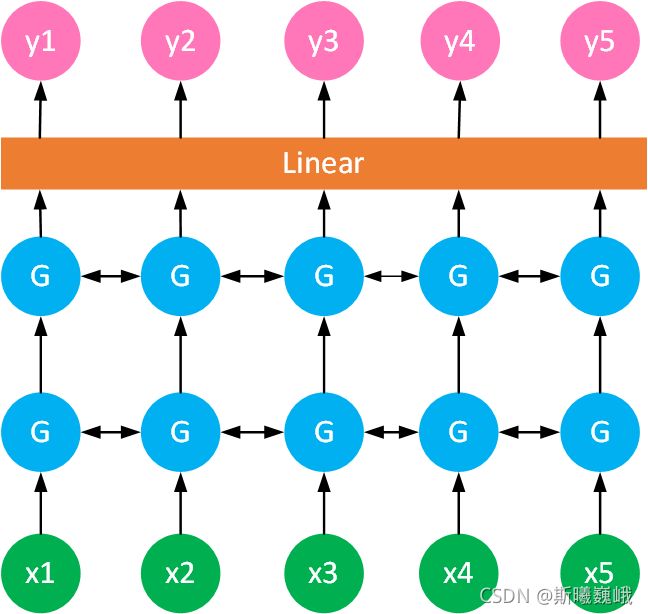
从图中可以看出,模型为双层双向GRU+线性层,关于模型中的词嵌入,我实现了2.3小节中说的两种策略,具体源码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from data_loader import word2id
from gensim_word2vec import build_embdding_matrix
embedding_path="word2vec.bin"
class BiGRU(nn.Module):
def __init__(self,embedding_dim,hidden_size,output_size,drop_prob,extra_embedding=True):
super(BiGRU,self).__init__()
if extra_embedding:
embedding_matrix = build_embdding_matrix(
word_dict=word2id,
embedding_path=embedding_path,
embedding_dim=embedding_dim)
embedding_weight = torch.from_numpy(embedding_matrix).float()
self.embeds = nn.Embedding.from_pretrained(embedding_weight)
else:
self.embeds = nn.Embedding(len(word2id),embedding_dim)
nn.init.uniform_(self.embeds.weight)
self.gru = nn.GRU(
bidirectional=True,
num_layers=2,
input_size=embedding_dim,
hidden_size=hidden_size,
batch_first=True,
dropout=drop_prob
)
self.batchnorm = nn.BatchNorm1d(84)
self.dropout = nn.Dropout(drop_prob)
self.decoder = nn.Linear(hidden_size * 2,output_size)
def forward(self,x):
x = self.embeds(x)
x,_ = self.gru(x)
x = self.batchnorm(x)
x = self.dropout(x)
x = self.decoder(torch.mean(x,dim=1))
return x
对于从GRU抽取到的句子的表示,本实验采取的做法是将各个隐藏层状态值求平均。另外,为了减缓模型的过拟合,模型中还添加了Dropout和BatchNorm策略。
四.实验与结果分析
4.1 实验配置
本次实验中的超级参数配置如下表所示:
| Parameter | Configuration |
|---|---|
| learning rate | 1e-4 |
| batch size | 64 |
| hidden size | 128 |
| weight_decay | 5e-4 |
| dropout rate | 0.5 |
| epochs | 100 |
实验采用的优化器为Adam,为了减缓过拟合,优化器添加了权重衰减策略。
4.2 实验结果
下面展示的是训练集和测试机的loss变化和预测准确率随epoch的变化情况,可以看出测试集上的loss在训练过程中的后期后上升的趋势,说明模型还是过拟合了。另外,在实验的过程中,博主方向学习率为0.01时,训练后期过拟合的趋势更加明显,训练集上准确率急剧上升(超过90%),但测试集的性能却会下降的比较厉害,主要原因是利用训练集作为语料库太小了,得到的词嵌入的性能一般。对此可以考虑,引入更大的语料库来进行训练,或者使用Google开源的语言预训练模型BERT。


五.结语
完整项目源码(有条件的支持一下,感谢!!!)
以上便是本文的全部内容,要是觉得不错的话就点个赞或关注一下博主吧,你们的支持是博主继续创作的不解动力,当然若是有任何问题也敬请批评指正!!!