深度学习-超参数调优
在机器学习中有很多调优的方式机器学习——超参数调优,深度学习中也存在同样的方式,接下来,介绍一下深度学习框架里边的自动调参模块。
1. 基于Tensorflow的Keras tuner
官方教程如下:Introduction to the Keras Tuner | TensorFlow Core (google.cn)
官网API极其更多细节:HyperParameters - Keras Tuner (keras-team.github.io)
超参数分为两种类型:
- 模型超参数(例如隐藏层的权重和数量)
- 算法超参数(例如SGD的学习率,KNN的K值等)
(1)定义模型
当建立模型进行超参数优化时,我们需要根据模型建立超参数搜索空间,建立hypermodel通常是两个途径:
- 使用模型建立函数(model builder function)
- 使用Keras Tuner API中HyperModel的子类HyperXception and HyperResNet
Keras Tuner API使用hp进行参数遍历,常用方法有
- hp.Int
hp_units = hp.Int('units', min_value=32, max_value=512, step=32) name: Str. 参数的名字,必须唯一
min_value: Int. 范围的最小值
max_value: Int. 范围的最大值
step: 步长
- hp.Choice
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4]) name: Str. 参数的名字,必须唯一
values: 可能值的list. 值的类型可以是int, float,str, or bool. 所有的值必须是一个类型
ordered: Whether the values passed should be considered to
have an ordering. This defaults to `True` for float/int
values. Must be `False` for any other values.
- hp.Float
hp_units = hp.Float('units', min_value=32.0, max_value=512.0, step=32.0) name: Str. 参数的名字,必须唯一
min_value: Float. 范围的最小值
max_value: Float. 范围的最大值
step: Optional. Float, e.g. 0.1.
smallest meaningful distance between two values.
Whether step should be specified is Oracle dependent,
since some Oracles can infer an optimal step automatically.
- hp.Boolean
name: Str. 参数的名字,必须唯一
default: Default value to return for the parameter.
If unspecified, the default value will be False.
- hp.Fixed
name: Str. 参数的名字,必须唯一
value: Value to use (can be any JSON-serializable
Python type).
建立builder function,主要对units和learning_rate两个参数进行了调优,代码如下:
def model_builder(hp):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# Tune the number of units in the first Dense layer
# Choose an optimal value between 32-512
hp_units = hp.Int('units', min_value=32, max_value=512, step=32)
model.add(keras.layers.Dense(units=hp_units, activation='relu'))
model.add(keras.layers.Dense(10))
# Tune the learning rate for the optimizer
# Choose an optimal value from 0.01, 0.001, or 0.0001
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
model.compile(optimizer=keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model(2)实例化调优器并进行调优
The Keras Tuner有四个调优器,分别是RandomSearch, Hyperband, BayesianOptimization, and Sklearn,这里主要是用了Hyperband,需要指定objective和max_epochs等参数,并在directory='my_dir'/project_name='intro_to_kt'的文件中记录训练细节。代码如下:
tuner = kt.Hyperband(model_builder,
objective='val_accuracy',
max_epochs=10,
factor=3,
directory='my_dir',
project_name='intro_to_kt')
#早停
stop_early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
tuner.search(img_train, label_train, epochs=50, validation_split=0.2, callbacks=[stop_early])
# Get the optimal hyperparameters
best_hps=tuner.get_best_hyperparameters(num_trials=1)[0]
print(f"""
The hyperparameter search is complete. The optimal number of units in the first densely-connected
layer is {best_hps.get('units')} and the optimal learning rate for the optimizer
is {best_hps.get('learning_rate')}.
""")(3)模型调优之后,可以通过最优参数进行重新training。
#利用搜索得到的超参数,找出最优epoch数来训练模型。
# Build the model with the optimal hyperparameters and train it on the data for 50 epochs
model = tuner.hypermodel.build(best_hps)
history = model.fit(img_train, label_train, epochs=50, validation_split=0.2)
val_acc_per_epoch = history.history['val_accuracy']
best_epoch = val_acc_per_epoch.index(max(val_acc_per_epoch)) + 1
print('Best epoch: %d' % (best_epoch,))
#重新实例化超模型,从上面用最优的纪元数训练它。
hypermodel = tuner.hypermodel.build(best_hps)
# Retrain the model
hypermodel.fit(img_train, label_train, epochs=best_epoch, validation_split=0.2)拓展:其他优化器的用法
import kerastuner as kt
from sklearn import ensemble
from sklearn import datasets
from sklearn import linear_model
from sklearn import metrics
from sklearn import model_selection
def build_model(hp):
model_type = hp.Choice('model_type', ['random_forest', 'ridge'])
if model_type == 'random_forest':
model = ensemble.RandomForestClassifier(
n_estimators=hp.Int('n_estimators', 10, 50, step=10),
max_depth=hp.Int('max_depth', 3, 10))
else:
model = linear_model.RidgeClassifier(
alpha=hp.Float('alpha', 1e-3, 1, sampling='log'))
return model
tuner = kt.tuners.Sklearn(
oracle=kt.oracles.BayesianOptimization(
objective=kt.Objective('score', 'max'),
max_trials=10),
hypermodel=build_model,
scoring=metrics.make_scorer(metrics.accuracy_score),
cv=model_selection.StratifiedKFold(5),
directory='.',
project_name='my_project')
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.2)
tuner.search(X_train, y_train)
best_model = tuner.get_best_models(num_models=1)[0]其他两个:
tuner = kt.tuners.BayesianOptimization(
hypermodel=model_builder,
objective='val_accuracy',
max_trials=4,
directory='.',
project_name='my_project')
tuner = kt.tuners.RandomSearch(
hypermodel=model_builder,
objective='val_accuracy',
max_trials=4,
directory='.',
project_name='my_project') 2.RAY tune
RAY现在仅支持Mac和Linux,Windows的wheels还没有。
(1)安装:
pip install 'ray[tune]'(2)优势:
- 支持多平台包括PyTorch, XGBoost, MXNet和Keras
- 自动管理检查点和记录到TensorBoard
(3)关键点
Ray tune的使用核心点主要如下图构成:
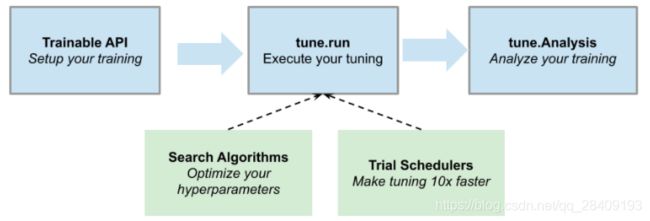
- Trainable:包装目标函数
#损失函数
def objective(x, a, b):
return a * (x ** 0.5) + b
#wrapper
def trainable(config):
# config (dict): A dict of hyperparameters.
for x in range(20):
score = objective(x, config["a"], config["b"])
tune.report(score=score) # This sends the score to Tune.- tune.run:执行参数优化
# Pass in a Trainable class or function to tune.run.
tune.run(trainable)- search space:建立搜索空间
config = {
"uniform": tune.uniform(-5, -1), # Uniform float between -5 and -1
"quniform": tune.quniform(3.2, 5.4, 0.2), # Round to increments of 0.2
"loguniform": tune.loguniform(1e-4, 1e-2), # Uniform float in log space
"qloguniform": tune.qloguniform(1e-4, 1e-1, 5e-4), # Round to increments of 0.0005
"randn": tune.randn(10, 2), # Normal distribution with mean 10 and sd 2
"qrandn": tune.qrandn(10, 2, 0.2), # Round to increments of 0.2
"randint": tune.randint(-9, 15), # Random integer between -9 and 15
"qrandint": tune.qrandint(-21, 12, 3), # Round to increments of 3 (includes 12)
"choice": tune.choice(["a", "b", "c"]), # Choose one of these options uniformly
"func": tune.sample_from(lambda spec: spec.config.uniform * 0.01), # Depends on other value
"grid": tune.grid_search([32, 64, 128]) # Search over all these values
}- search Algorithms(Search Algorithms (tune.suggest) — Ray v1.2.0所支持的搜索算法)
# Be sure to first run `pip install hyperopt`
import hyperopt as hp
from ray.tune.suggest.hyperopt import HyperOptSearch
# Create a HyperOpt search space
config = {
"a": tune.uniform(0, 1),
"b": tune.uniform(0, 20)
# Note: Arbitrary HyperOpt search spaces should be supported!
# "foo": tune.randn(0, 1))
}
# Specify the search space and maximize score
hyperopt = HyperOptSearch(metric="score", mode="max")
# Execute 20 trials using HyperOpt and stop after 20 iterations
tune.run(
trainable,
config=config,
search_alg=hyperopt,
num_samples=20,
stop={"training_iteration": 20}
)- Trial Schedulers:查看训练过程
- Analysis:分析训练过程
(4)使用
from ray import tune
def objective(step, alpha, beta):
return (0.1 + alpha * step / 100)**(-1) + beta * 0.1
def training_function(config):
# Hyperparameters
alpha, beta = config["alpha"], config["beta"]
for step in range(10):
# Iterative training function - can be any arbitrary training procedure.
intermediate_score = objective(step, alpha, beta)
# Feed the score back back to Tune.
tune.report(mean_loss=intermediate_score)
analysis = tune.run(
training_function,
config={
"alpha": tune.grid_search([0.001, 0.01, 0.1]),
"beta": tune.choice([1, 2, 3])
})
print("Best config: ", analysis.get_best_config(
metric="mean_loss", mode="min"))
# Get a dataframe for analyzing trial results.
df = analysis.results_df