论文阅读 Soft-Demapping for Short Reach Optical Communication: A Comparison of Deep Neural Networks and
这篇文章比较了相干系统中DNN和Volterra算法,系统主要损伤是器件非线性。
摘要:
在光纤通信系统中,光电器件都会引入非线性,因此需要有效方案对高速信号进行补偿,特别在短距通信中,器件是最大的非线性来源。Volterra是在接收端均衡器件非线性和缓解记忆效应的主流技术,但是Volterra非常复杂。
这篇文章研究了软解码DNN,作为非线性均衡和软判决解映射的替代方法。在相干92Gbaud双偏振64QAM背靠背系统测试中,算法的性能和复杂度都得到了评估。在15%的FEC下,将本文方案DNN均衡器(SDNNE)与5阶Volterra均衡器进行比较。在性能相同的情况下,计算复杂度降低了65%。在相同的复杂度下,光信噪比(OSNR)的性能提高了0.35 dB。
背景:
在现代通信系统中,软判决前向纠错(FEC)和高阶正交幅度调制(QAM)方案是实现高频谱效率(SE)的关键技术。软判决解码有效且应用广泛。
这篇文章主要研究系统损伤主要为光电器件导致的非线性的短距高带宽光通信系统。典型的使用案例包括范围为80-120 km的数据中心互连(DCI)。比较Volterra和NN复杂度的方法用的是D. I. Soloway and J. T. Bialasiewicz, “Neural network modeling of nonlinear systems based on volterra series extension of a linear model,” 1992. 通过泰勒展开从NN中提取线性和非线性核,并于Volterra核进行比较。
确定NN的结构,性能与复杂度需要折中,优化器adam,激活函数 tanh 比特映射不是one-hot

原理:
将DNNE扩展为Volterra序列,通过扩展,可以比较基于Volterra级数的两个均衡器的线性和非线性内核。
梯度和海森矩阵是:(我没有看懂这个数学公式,也不知道怎么就可比较了)
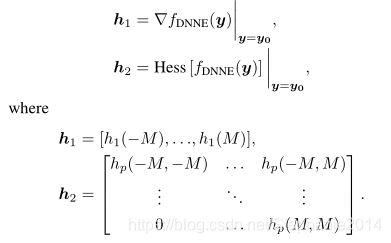
已经表明,针对发送的x(i)和接收的信号y(i)之间的均方误差(MSE)进行训练的DNNE有效地执行了基于符号的硬决策。尽管可以实现与VNLE相比硬判决(HD)BER的改进,但软判决(SD)FEC解码器的以下FEC后BER不是最佳的。
对于可训练软映射的按位解码损失函数:
软解码器计算软比特 ,的符号表示硬判决,如果>0,符号是0,如果<0,符号是1,的绝对值表示软解码器对于判决正确的概率
,的符号表示硬判决,如果>0,符号是0,如果<0,符号是1,的绝对值表示软解码器对于判决正确的概率
估算(这估算的是什么?GMI)

m是实数符号的比特位,比如m=3 对于64QAM,n是传输符号的数量,

将DNNE用作软解映射器。定义了具有线性激活函数的m个输出单位,以允许负值和正值。为了最大化速率,使用按位等值作为损失函数
![]()
b是传输比特,l是DNN输出,这个损失函数与二进制交叉熵是等价的,并且是最优的(是我的问题吗,我觉得这个loss有问题啊,哦应该没问题,因为l是sigmoid的输入,不是输出)
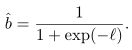
![]()

| b | l | b_hat | loss | |
| 0 | - | ~0 | 0 | 比较小,正确 |
| 0 | + | ~1 |  |
比较大,错误 |
| 1 | - | ~0 | |
比较大,错误 |
| 1 | + | ~1 | 0 | 比较小,正确 |
为什么要这样做啊?好奇怪,这不是常规操作吗?
最优的证明我等下再看。。
实验:
A实验装置
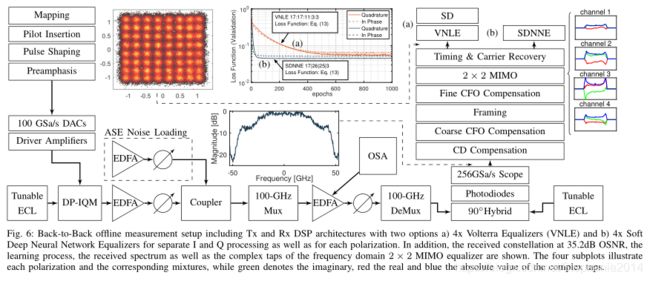
AWGN信道,没有光纤
92GBd DP-64QAM,总数据速率为1104Gb / s
在训练开销为1%且FEC开销为15%和20%的情况下,净比特率分别为950Gb / s和912Gb / s
四个具有40GHz 3dB带宽和6位分辨率的100GSa / s DA的信号输出功率设置为-6dBm
电放 22dB增益和60GHz 3dB带宽的SHF S804A放大器 有非线性内部调制失真 这部分非线性与调制器(MZM,FujitsuFTM7992HM-32GHz 驱动电压≤4.2Vpp)非线性失真混合
在光域中,分别在发射器和LO处使用两个可调谐的1kHz外腔激光器(ECL)
光调制信号被放大,然后与由EDFA产生的放大的自发发射(ASE)噪声混合。
考虑将100GHz Mux和Demux用于未来可能用到的波分复用(WDM)
接收机由一个90 hybrid和四个70GHz平衡光电二极管组成,光电二极管输入功率0dBm,线性工作范围
使用Keysight Infiniium实时示波器对电信号进行数字化处理,该示波器包括四个工作在256GSa / s,110GHz 3dB带宽的10位模数转换器
为了补偿发射器的非线性,ISI以及存储效应,接收器DSP堆栈除了经典相干信号恢复模块之外还包括VNLE+MLA(less complex max-log approximation)软判决解映射器和SDNNE。两种方案采样率均为1 sps。不同的非线性均衡器(NLE)在相同的功率归一化数据上运行。无论使用哪种均衡器,使用前都必须对特定的非线性进行训练。 每个OSNR值的第一个接收帧的有效负载的50%用作NLE训练,包含66,444个符号。为了防止过拟合,在训练阶段对剩余的50%有效载荷重复验证性能。训练后,将在六个新捕获帧的后半部分评估性能。
B性能分析

图7比较了线性均衡器,2-5阶VNLE和SDNNE的性能,VNLE阶数再增加也没有增益了,如图8所示,所有均衡器均已优化,输入都用了同时考虑之前和之后数据的输入。
VNLE的5阶内核增益明显,而4阶内核并没有产生明显的额外收益,这表明奇次谐波占主导地位。 5阶VNLE改善了OSNR较高区域的线性均衡基线曲线,最高可达〜0.09位/符号。在以ASE噪声为主要失真的较低OSNR范围内,增益会略微降低至〜0.07位/符号,适用于所有NLE体系结构。VNLE+MLA比VNLE+MSE提升约0.002bit/QAM。VNLE+MLA的改进很小,几乎可以忽略不计。
C Volterra非线性均衡器和软解码深层神经网络均衡器的核
Volterra的核为分析信道提供了很好的工具。VNLE表达式第一项代表系统的有限线性冲激响应,而高阶Volterra核代表高阶冲激响应,描述了非线性动力学行为。

这个是怎么提取的啊?我实在是不知道该提取网络的哪个参数。。可能我需要去看这篇D. I. Soloway and J. T. Bialasiewicz, “Neural network modeling of nonlinear systems based on volterra series extension of a linear model,” 1992.
看了,感觉像是三个比特输出对应的一阶输入
点评:
主要的信道损伤是器件,是电放和光放
没弄清楚核是怎么分析的