【论文阅读-强化学习】基于深度强化学习的多区域MEC网络中支持缓存的计算卸载
Caching-Enabled Computation Offloading in Multi-Region MEC Network via Deep Reinforcement Learning
文章目录
-
- I.Introduction
- II.Related Works
- III.System Model
-
- A. Computation Model
-
- Local Computation Model
- Offloading Computation Model
-
- 卸载到边缘
- 卸载到云
- B. Result Caching Model
- C. Mobility Model
- D. Problem Formulation
- IV. Proposed Solution
-
- A. Single-Region Offloading Decision Algorithm based on DDPG
-
- 状态
- 动作
- 奖励
- DDPG
- B. Cooperative Caching Algorithm
- V.仿真结果
-
- A. Single-Region Offloading Decision Algorithm based on DDPG
- B. Cooperative Caching Algorithm
- *实现笔记
-
- 原论文里的模型
-
- 状态
- 动作
- 需要随机分配的变量
摘要:随着互联网的快速发展,出现了越来越多的计算密集型应用,对计算延迟和能耗提出了更高的要求。最近,使用移动边缘计算服务器进行辅助计算被认为是减少延迟和能耗的有效方法。此外,自动驾驶等应用将产生大量重复任务。使用缓存存储流行任务的计算结果可以避免重复处理造成的开销。本文研究 多区域用户的计算卸载问题。优化目标表示为选择卸载策略和缓存策略,以最小化所有区域的总延迟和能量消耗。我们首先使用深度强化学习深度确定性策略梯度(DDPG)框架来解决单个区域中的计算卸载问题。我们还展示了现有的多区域协作缓存方法的低效性,并提出了一种新的协作缓存算法(CCA),以提高系统的整体缓存命中率。最后,我们集成了DDPG和CCA算法,为所有区域形成了一个整体高效的缓存和卸载策略。仿真结果表明,该算法可以显著提高缓存命中率,并在降低系统总开销方面具有优异的性能。
之前没接触过这个领域,所以还是翻一下introduction~
I.Introduction
云计算可以通过互联网向用户提供可扩展的虚拟化资源软件和数据服务,使用户能够按需获取计算资源和存储资源[1]。然而,随着5G技术的快速发展和移动设备流量的快速增长,传统蜂窝网络通信模式的缺点已经开始显现。人们对未来5G网络的研究计划表明,5G网络需要承载高带宽要求的虚拟现实和超高清视频等服务内容,并可以在物联网场景中提供商业体验,如具有高延迟要求的车联网和工业制造[2]。在此背景下,云计算技术的核心网络压力太大,难以解决过度延迟和带宽不足造成的瓶颈问题。幸运的是,提出了 多址边缘计算(MEC) [3]来解决上述问题。MEC是一种新的计算模型,它将计算资源和存储资源部署在靠近移动设备或传感器的网络边缘。因此,大多数数据请求不需要(直接)从云计算中心获得响应,这大大降低了对网络带宽和整个系统延迟的压力[4]。
计算卸载是MEC中一个非常重要的问题,即将移动终端的计算任务卸载到网络边缘执行,以提高计算服务质量(QoS)。然而,由于边缘服务器的计算资源是有限的,当设备数量足够大时,将所有计算任务不假思索地卸载到网络边缘执行将超过收益。在这种情况下,多个设备需要竞争边缘服务器的计算资源。为了更有效地利用计算资源,需要设计一种高效快速的算法来确定卸载策略和计算资源分配策略。
在计算卸载中引入一些稳健的方法可以进一步提高性能。用户设备通常请求重复内容或生成重复计算任务,在边缘服务器上配备缓存以存储这些高度流行的内容被认为是有效的。当用户请求的内容存在于缓存中时,可以直接返回。当存在多个边缘服务器时,如果可以组合它们的缓存,则可以在一定程度上提高缓存命中率。然而,由于缓存的容量也是有限的,并且只能存储有限的内容,因此还需要设计有效的算法来确定每个时刻缓存的内容。此外,中央云拥有丰富的计算资源。云中的一些计算资源可用于辅助计算,以向用户提供额外的选择。
本文研究了MEC中的多区域计算卸载问题,综合考虑了用户迁移、缓存之间的协作和计算卸载问题。本文的主要贡献总结如下:
- 我们提出了一种缓存增强的计算卸载系统模型,该模型能够将单个区域的本地缓存扩展到MEC网络中多个区域之间的协作缓存。
- 我们首先在MEC中提出了一种协作缓存算法(CCA),以提高系统的整体缓存命中率。随后,我们提出了一种基于深度强化学习的计算卸载决策方法,并将其与CCA算法相结合以输出最终卸载决策。
- 仿真结果表明,所提出的CCA算法比传统的缓存算法具有更好的性能,并且将CCA算法与深度强化学习相结合可以显著降低系统的总体开销。
II.Related Works
计算卸载 到目前为止,计算卸载的研究工作已经在许多领域取得了大量成果。Jeong等人[5]使用计算卸载的思想在移动设备上运行计算复杂的深度神经网络(DNN)模型。他们将客户端的DNN模型划分为多个分区,并提出了一种基于块的神经网络增量卸载技术,以提高模型的训练速度。在[6]中,作者提出了一种基于元强化学习的任务共享方法,该方法解决了如何允许具有多个相关任务的应用程序执行计算卸载的问题。袁等人[7]提出了一种用于边缘计算的创新分布式协作视频流处理框架,以解决计算卸载视频流任务的问题。Zhu等人[8]提出了一种联合计算卸载和资源分配方案,该方案在光纤陀螺无线接入网络(F-RAN)中实现了次优解决方案。[9] 将无线功率传输技术-无线功率传输(WPT)与计算卸载技术相结合,解决具有多个边缘设备的WP-MEC网络的最大计算完成率的调度问题。由于边缘的计算能力与中心云相比非常有限,因此将所有用户的计算任务传输到边缘进行计算的成本很高。因此,设计合理的卸载机制尤为重要。深度学习和强化学习由于其低延迟和对动态系统的强适应性也受到了广泛关注。[10] 提出了一种基于深度强化学习的在线卸载框架,以解决在无线信道条件动态变化的环境中任务的完全卸载问题。[11] 提出了一种基于多智能体深度强化学习和博弈论的算法,在保证用户隐私的前提下确定服务提供商的最优定价策略。
多区域 上述工作是在仅具有一个边缘服务器的单个区域的情况下进行的。然而,在现实生活中,通常需要考虑具有多个区域和多个边缘服务器的场景。Zhang等人[12]研究了服务器计算能力和计算任务随时间变化的动态MEC网络中的任务协作卸载机制,并提出了两种基于深度强化学习的改进算法来解决设备之间的协调问题。Gong[13]针对分布式边缘计算问题提出了一种高效的计算分配算法和通信调度算法,旨在使用边缘设备并行执行计算,以大大减少计算延迟。[14]中的工作提出了一种基于强化学习的联合计算卸载和迁移方案,以解决用户在多个区域移动时计算完全卸载的问题。Wang等人[15]研究了具有同频干扰的车联网环境中的任务卸载问题。他们设计了一个车联网(IoV)系统架构,并使用双深度Q网络来解决用户移动导致的网络状态实时变化的问题。Li等人[16]研究了车联网环境下的车辆协同计算问题,并提出了一种基于DDPG的算法来确定车辆的任务分配、计算和结果交付策略。
缓存机制 已经验证了边缘服务器侧的缓存机制,以避免任务的重复传输和计算。[17]中的研究将缓存机制引入MEC网络,作者使用门递归单元(GRU)算法预测任务的流行度,然后使用多智能体深度Q网络(DQN)算法根据预测确定缓存策略。他等人[18]研究了配备共享缓存的IoV中的完整任务卸载问题,以提高用户体验的质量。Li等人[19]通过最小化系统成本来解决超密集MEC网络中的移动性感知内容缓存和用户关联问题,并提出了一种基于移动性的在线缓存算法。为了减少车辆联网环境中车辆任务的交付延迟和系统成本,乔等人[20]提出了一种基于DDPG的协作缓存方案,该方案借助于宏小区站、路边单元和智能汽车。在[21]中,作者研究了具有随机任务到达的缓存辅助多用户MEC系统中的动态缓存、计算卸载和资源分配问题,并提出了一种基于DDPG的动态调度策略来解决这些问题。
使用中央云帮助卸载 引入计算卸载中心云以减轻边缘服务器的压力也是进一步提高系统性能的常用方法。[22]-[24]结合边缘计算和云计算,实现物联网设备的任务卸载。[25]使用云辅助移动边缘计算框架来研究计算分流和资源分配问题,并提出了双深度Q网络(DDQN)卸载算法,以避免过度的状态空间和高估问题。Guo等人[26]研究计算密集型应用的计算卸载和带宽分配。作者使用云来执行辅助计算,并提出了一种启发式算法来解决该问题。赵等人[27]研究了车联网环境中的计算卸载问题,并提出了一种基于MEC和云计算的协作方法,将服务卸载到车联网中的汽车上。
然而,大多数现有工作通常很少考虑用户在多个区域之间迁移的问题。此外,大多数将缓存机制引入计算卸载的研究通常侧重于内容缓存,而很少关注计算结果的存储。并且基本上不考虑边缘服务器缓存之间的协作。基于上述情况,很少有研究引入中心云来辅助计算。基于以上三点的综合考虑,本文以最小化整个系统的总体成本为优化目标,解决了多区域MEC网络中支持缓存的计算卸载问题。表1显示了本文与其他相关文献之间的差异,其中用户迁移、协作缓存和中央云分别表明,作者在研究中考虑了用户在多个区域之间迁移的问题,使用了协作缓存,并使用中央云进行辅助卸载,以及结果缓存和内容缓存。

III.System Model

- 区域数为 M M M,每个区域有一个基站(BS, base station),每个基站给 N N N个用户提供服务(UE, user equipment),每个用户只与一个基站相连。
- MEC服务器具有足够的计算资源,其与BS一起部署,以向该区域中的多个用户提供计算服务。
- 每个基站配一个边缘服务器(ES, edge server)。移动云计算(MCC,Mobile Cloud Computing)服务器拥有更丰富的计算资源,并部署在远离用户的地区。
- 假设每个用户将同时生成计算密集型和延迟敏感型任务,我们考虑用户生成的任务将被重用的场景。在现实生活中,用户生成重复任务是非常常见的。例如,在在线游戏中,用户将根据自己设备的实际配置请求具有不同渲染质量的公共地图。此类请求可能在短时间内大量触发。如果可以直接缓存对应的图像,则可以避免图像的复杂处理;用户还将在游戏期间根据设备的模型和当前状态请求调整的游戏参数。如果可以直接缓存公共状态的结果,则可以避免大量重复分析计算。边缘服务器的计算资源有限且宝贵。如果这些重复任务的计算结果可以重用,则可以在很大程度上避免资源浪费。
- 任务集合 X X X,结果大小集合 Y Y Y,一个区域里的 N N N个用户产生的任务集合 J J J,第 n n n个用户的任务可表示为 J n = { b n , d n , Y n } J_n=\{b_n,d_n,Y_n\} Jn={bn,dn,Yn}, b n b_n bn表示在传输过程中要处理的任务的计算数据的大小, d n d_n dn表示完成任务所需的CPU时钟周期数。
- 每个区域的用户对不同的任务有不同程度的偏好,即生成每种类型任务的概率不同。我们假设用户在每个区域中从 X X X生成任务的概率服从不同的 zipf 分布,并且生成的任务在第 m m m个区域中的概率分布表示为 η m = { η 1 , η 2 , η 3 . . . } \eta_m=\{\eta_1,\eta_2,\eta_3...\} ηm={η1,η2,η3...}
- 我们假设所有边缘服务器都配备了相同大小的缓存来存储任务的计算结果,以避免重复计算,并且具有相同的计算能力。多个边缘服务器可以通过网络通信共享缓存,从而形成协作缓存网络。此外,用户可以在区域之间移动。如果用户在边缘服务器获得计算结果之前移动到另一个区域,则必须迁移计算结果,从而导致额外的迁移开销。
A. Computation Model
为了确保计算结果的完整性,我们假设用户生成的任务要么本地执行计算,要么完全执行卸载计算。为了便于表达并避免繁琐的上标和下标,我们在本文的其余部分省略了符号的标记m和k,其中m表示区域数,k表示时隙数。默认情况下,它表示用户在当前时隙k中所处的区域m。例如,变量 f n e d f^{ed}_n fned表示当前时隙中位于区域 m m m中的用户 n n n从边缘服务器分配的计算资源。为了避免混淆,我们保留了标签,并在可能存在误解的地方用()标记。
我们定义一个变量 a n a_n an来表示用户 n n n的卸载决策。
- 当 a n = 0 a_n=0 an=0时,用户选择在本地执行任务;
- 当 a n = 1 a_n=1 an=1时,用户选择卸载到边缘服务器以执行任务
- a n = 2 a_n=2 an=2表示用户将任务发送到云以执行任务。
Local Computation Model
如果用户 n n n选择在本地执行任务,对于任务 J n J_n Jn,任务的执行时间:

( d n d_n dn表示完成任务所需的CPU时钟周期数) f n l o c f_n^{loc} fnloc表示用户n的移动设备的算力,用每单位时间可执行的CPU周期数表示。我们假设所有移动设备具有相同的计算能力,计算过程中的能耗可以表示为:

Offloading Computation Model
卸载到边缘
如果 a n = 1 a_n=1 an=1,用户需要首先通过无线网络访问当前区域中的小型基站(SBS),然后将任务卸载到边缘服务器以执行计算。因此,与本地执行任务不同,卸载执行任务将导致额外的传输延迟和能耗开销。首先,用户需要将任务交付给边缘服务器。将 r n r_n rn定义为用户 n n n向边缘服务器传递任务的上行链路传输速率, r n r_n rn可以表示为:
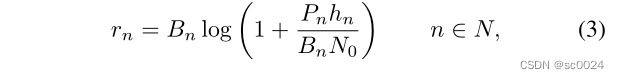
其中 B n B_n Bn是在当前信道条件下由用户设备 U E n UE_n UEn分配的带宽。我们假设所有用户平均分配带宽, P n P_n Pn是 U E n UE_n UEn的传输功率, h n h_n hn是 U E n UE_n UEn的信道增益, N 0 N_0 N0是高斯白噪声信道方差。用户 n n n的任务【传输延迟】可以表示为:

此时,边缘服务器将处理计算任务。如果边缘服务器提供的总计算能力是 F e d F_{ed} Fed,分配给用户 n n n的边缘服务器的计算能力为 f n e d f ^{ed}_n fned,则任务的【计算延迟】可以表示为:
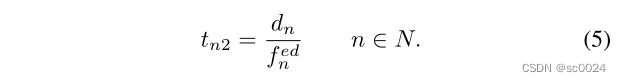
最后,边缘服务器将结果发送回用户。任务计算结果的数据量通常非常小,我们将忽略此过程导致的传输开销。基于上述分析,用户在上述过程中产生的能耗支出可以得到:

其中 P n e d P^{ed}_n Pned是任务传输过程中用户的传输功率, P n i P^i_n Pni表示用户设备的空闲功率。
卸载到云
类似地,如果用户选择将任务卸载到中央云执行,则首先需要将任务传输到云,然后在云中执行任务,最后将计算结果返回给用户。总延迟可以表示为:
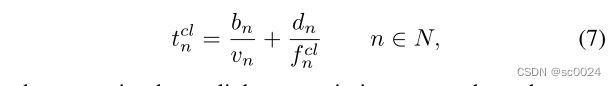
其中, v n v_n vn是用户向中心云传输任务时的上行链路传输速率, f n c l f^{cl}_n fncl是分配给用户n的云计算能力。本文假设向云的区域传输任务的速率恒定为 V V V,云可以提供的最大计算能力为 F c l F_{cl} Fcl。将任务卸载到云的所有用户将平均分配这些任务。整个卸载过程的能耗成本可以表示为:

P n c l P^{cl}_n Pncl是用户在向云传输任务的过程中的传输功率。
B. Result Caching Model
我们假设当用户生成计算任务时,缓存在第m个区域的边缘服务器中的任务数为 k k k,缓存内容表示为 C a c h e m = { λ 1 , λ 2 , … , λ k } Cache_m=\{λ_1,λ_2,…,λ_k\} Cachem={λ1,λ2,…,λk},所有区域的缓存一起形成缓存网络。
在执行计算任务之前,用户将首先与区域中的边缘服务器通信,以查询其缓存信息。如果任务的计算结果已存储在缓存中,则可以直接返回,从而避免任务的重复计算。如果本地缓存未命中,边缘服务器将与其他边缘服务器通信以获取其缓存信息。如果任务的计算结果缓存在协作缓存中,则计算结果将首先发送回当前边缘服务器,然后返回给用户。与查询本地缓存相比,此过程将产生一定的额外开销,包括边缘服务器之间的通信开销和结果返回开销。虽然在查询和缓存过程中会产生一定的开销,但任务的计算结果通常非常小,并且开销远小于计算任务的实际执行。但是,查询缓存造成的开销是不可忽略的。如果本地缓存和协作缓存都丢失,将对系统性能产生负面影响。因此,必须确保高缓存命中率。
设 q n q_n qn表示用户n的查询缓存的命中指示符,其中 q n ∈ { 0 , 1 , 2 } , n ∈ N q_n\in\{0,1,2\},n∈ N qn∈{0,1,2},n∈N。 q n = 0 q_n=0 qn=0表示缓存未命中, q n = 1 q_n=1 qn=1表示本地缓存命中,而 q n = 2 q_n=2 qn=2表示协作缓存命中。
C. Mobility Model
在现实生活中,用户的移动是不可避免的,简单地将用户固定在一个区域显然是不合理的。用户在该区域的平均停留时间由 β β β表示,并且假设 β β β服从高斯分布。该值可通过分析该地区所有用户的历史停留数据获得[14]。基于上述假设,如果用户在生成计算任务时处于区域中,则 用户在一段时间 t t t 之后将停留在该区域中的概率 可以表示为:
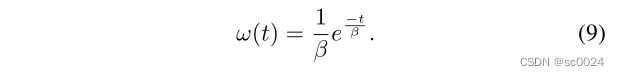
如果用户选择在边缘服务器上执行计算任务,假设完成计算任务所需的时间为 t c t^c tc,则当边缘服务器准备好发送计算结果时,用户仍将停留在区域中的概率可以表示为:

用户此时离开该区域的概率为 ω 2 = 1 − ω 1 ω2=1-ω1 ω2=1−ω1。如果用户在边缘服务器获得计算结果之前已经离开该区域,则计算结果需要在边缘服务器之间传输,然后才能返回给用户。此过程将导致不可忽略的开销。为了简化问题并便于计算,本文假设用户迁移导致的开销与计算任务的结果大小成正比。如果任务计算结果的大小为Y,则用户因迁移而造成的损失可以表示为

基于上述讨论,我们需要修改上述计算模型。如果在不考虑用户迁移的情况下完成计算任务的总成本为 C n c C^c_n Cnc,则需要将总计算成本公式修改为:

D. Problem Formulation
为了最大限度地利用缓存,假设用户在计算问题发生后首先查询本地缓存和协作缓存,并在缓存未命中的情况下选择执行本地计算或卸载计算。为了简化问题并便于定量分析,我们假设所有用户查询本地缓存的成本为 z 1 z_1 z1,查询协作缓存的成本是 z 2 z_2 z2,查询两个缓存的总成本表示为 z = z 1 + z 2 z=z_1+z_2 z=z1+z2。
设 δ n δn δn表示用户 n n n的最终决定,其中 δ n ∈ { 0 , 1 , 2 , 3 , 4 } , n ∈ N δ_n∈ \{0,1,2,3,4\},n∈ N δn∈{0,1,2,3,4},n∈N。
δ n = 0 、 1 、 2 δ_n=0、1、2 δn=0、1、2分别取用户选择本地、卸载到边缘服务器、卸载到云来执行任务, δ n = 3 δ_n=3 δn=3表示用户已在本地缓存中获得任务的计算结果, δ n = 4 δ_n=4 δn=4表示用户已获得协同缓存中任务的计算结果。
设 α α α表示用户对低延迟和低能耗的偏好, α α α越接近1,用户越希望在更短的时间内获得结果,不同决策下用户的总计算成本可以表示为

我们的最终目标是为所有用户制定适当的卸载策略(以 R a Ra Ra表示),并确定边缘服务器分配给每个用户的计算资源(以 R f Rf Rf表示),以便每个用户完成计算任务所产生的平均计算开销尽可能小。
(Remind that M M M是区域数, N N N是一个区域里的用户数)
R a Ra Ra表示当前时隙k中所有用户的卸载决策,定义为 R a ( k ) = [ R a 1 ( k ) , R a 2 ( k ) , . . . , R a M ( k ) ] Ra_{{(k)}}=[ Ra_{1(k)},Ra_{2(k)},...,Ra_{M(k)}] Ra(k)=[Ra1(k),Ra2(k),...,RaM(k)],而 R a M ( k ) Ra_{M(k)} RaM(k)表示当前时隙 k k k中,,位于区域m中的所有用户的卸载决策向量,定义为 R a M ( k ) = [ δ 1 ( m ) k , δ 2 ( m ) k , . . . , δ N ( m ) k ] Ra_{M(k)}=[δ^k_{1(m)},δ^k_{2(m)},...,δ^k_{N(m)}] RaM(k)=[δ1(m)k,δ2(m)k,...,δN(m)k]。
类似地, R f Rf Rf表示每个用户在时隙 k k k中从边缘服务器分配的计算资源,其被定义为 R f ( k ) = [ R f 1 ( k ) , R f 2 ( k ) , . . . , R f M ( k ) ] Rf_{{(k)}}=[ Rf_{1(k)},Rf_{2(k)},...,Rf_{M(k)}] Rf(k)=[Rf1(k),Rf2(k),...,RfM(k)], R f m ( k ) Rf_{m(k)} Rfm(k)表示位于区域 m m m中的所有用户在时隙 k k k中从边缘服务器获得的计算资源分配向量,其定义为 R f M ( k ) = [ f 1 ( m k ) e d , f 2 ( m k ) e d , . . . , f N ( m k ) e d ] Rf_{M(k)}=[ f^{ed}_{1(mk)},f^{ed}_{2(mk)},...,f^{ed}_{N(mk)}] RfM(k)=[f1(mk)ed,f2(mk)ed,...,fN(mk)ed]。目标函数可以表示如下:
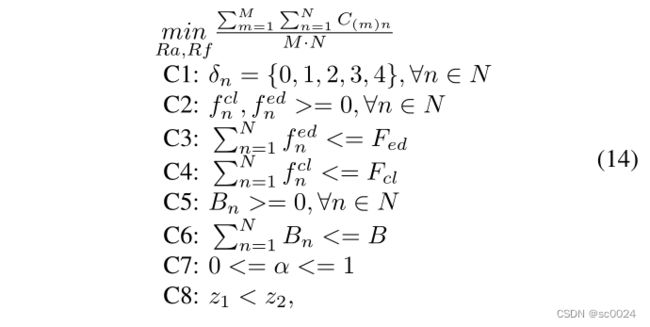
C1定义用户的决策范围
C2确保边缘服务器和云分配给每个用户的计算资源为非负
C3和C4确保所有用户分配的计算资源不超过边缘服务器和云端拥有的计算资源
C5确保每个用户占用的带宽为非负
C6确保所有用户占用的带宽不超过该区域的最大带宽
C7确保延迟和能耗选择系数在0和1之间
C8确保查询本地缓存的成本小于查询协作缓存的成本
IV. Proposed Solution
A. Single-Region Offloading Decision Algorithm based on DDPG
强化学习是通过环境中的数据分析,允许代理不断学习在特定状态下应执行的策略[29]。深度强化学习(DRL)结合了深度学习和强化学习的优点,既保留了深度学习的优秀决策能力,又保留了强化学习的感知能力。常用的DRL算法包括DQN算法、actor-critic算法和DDPG算法。DQN是处理离散动作问题的强大工具,但在大动作空间的情况下,它容易发生维数灾难。DDPG算法可以在 连续动作空间 中更有效地学习,同时在一定程度上 缓解了actor-critic网络的缓慢收敛。
MEC网络是一个动态系统,用户在此网络下对实时结果有很高的要求。许多传统算法的时间复杂度太高,难以满足用户对时延的要求。为了在特定环境下快速获得合适的决策,本文使用深度强化学习中的DDPG算法为用户制定合适的卸载策略和资源分配策略。
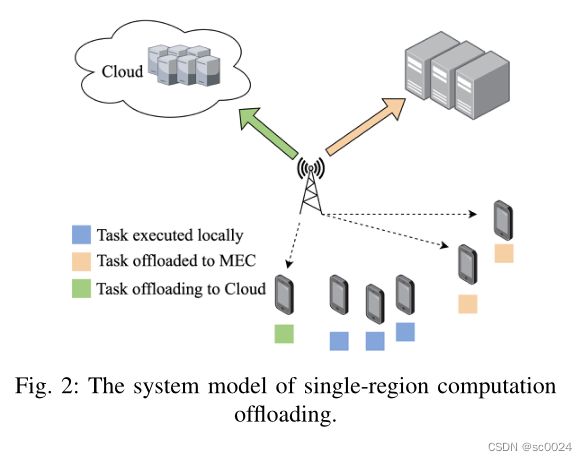
我们讨论了图2所示的单区域计算卸载问题,并将该问题表示为马尔可夫决策过程(MDP)。MDP定义为四元组(S, A, T, R),其中S是环境状态集,A是动作集,T是传递函数,R是奖励函数。在本文中,状态、动作和奖励函数的详细定义如下:
状态
我们将时间划分为多个时隙,并假设用户在一个时隙开始时生成计算任务,并在下一个时隙开始前完成任务。本文中的状态定义为 s t a t e = ( C n , k − 1 , F e d r , R a k − 1 , R f k − 1 ) state=(C_{n,k−1},F^r_{ed},Ra_{k−1},Rf_{k−1}) state=(Cn,k−1,Fedr,Rak−1,Rfk−1) .
- k k k表示时隙号
- C n , k − 1 C_{n,k−1} Cn,k−1是所有用户在前一个时隙中完成所有计算任务所导致的总系统开销
- F e d r F^r_{ed} Fedr表示边缘服务器的剩余计算资源
- R a k − 1 Ra_{k−1} Rak−1是前一时隙中用户的卸载决策向量
- R f k − 1 Rf_{k−1} Rfk−1是由前一时隙的边缘服务器分配给每个用户的计算资源组成的资源分配向量
在第一时隙中,假设用户正在本地执行计算任务。因此,在初始状态下, C n , k − 1 C_{n,k−1} Cn,k−1是所有用户在本地完成计算任务所造成的延迟和能耗之和, F e d r F^r_{ed} Fedr等于边缘服务器拥有的最大计算资源, R a k − 1 Ra_{k−1} Rak−1和 R f k − 1 Rf_{k−1} Rfk−1都是零向量,这意味着用户在本地执行计算。
动作
我们将Action定义为 A c t i o n = ( R a , R f ) Action=(Ra,Rf) Action=(Ra,Rf),其中 R a Ra Ra表示所有用户的卸载决策向量, R f Rf Rf表示边缘服务器分配给用户的计算资源的决策向量。
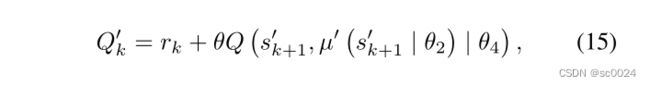
奖励
在特定状态下执行某个动作后,代理将从环境中获得反馈。我们将奖励函数定义为:

(这里的开销已经把时延和功耗统一起来了)
- ψ n k l o c a l ψ^{local}_{nk} ψnklocal是所有用户选择本地计算任务所导致的总系统开销,称为“本地成本”。
- ψ n k e d g e ψ^{edge}_{nk} ψnkedge是所有用户选择将任务卸载到边缘服务器所导致的总系统开销,称为“卸载成本”。
- ψ n k m i n ψ^{min}_{nk} ψnkmin是 ψ n k l o c a l ψ^{local}_{nk} ψnklocal和 ψ n k e d g e ψ^{edge}_{nk} ψnkedge之间的较小值。
- ψ n k ψ_{nk} ψnk是由于执行DDPG输出的卸载决策而导致的系统开销。考虑到用户移出的可能性,它由等式(13)计算。(actor决定了一种动作之后,就会得到一个 ψ n k ψ_{nk} ψnk,去和 ψ n k l o c a l ψ^{local}_{nk} ψnklocal或 ψ n k e d g e ψ^{edge}_{nk} ψnkedge比较)
与其他研究不同,我们在设计奖励时考虑了所有任务都在边缘服务器上执行的情况。当用户数量足够大时,在本地执行所有计算任务比在边缘服务器上执行所有计算工作更有利。奖励的实际含义是在特定状态下执行动作与在该状态下执行所有本地计算的动作的性能比。
引入卸载成本的目的是确保算法做出的决策比尽可能将所有任务卸载到边缘的决策更好。只有当与算法生成的卸载决策相对应的总系统开销小于本地成本或卸载成本时,奖励才是正的(第二种情况),而其他研究通常只考虑在奖励设计中任务全部在本地执行的情况。
µ1、µ2和µ3是放大系数。其目的是酌情扩大或缩小奖励,以便模型能够快速收敛。因为在训练的早期阶段,与大多数动作相对应的奖励是负的。如果与良好行为对应的奖励不够大,则代理不容易从环境中学习,因此我们选择适当放大良好行为产生的奖励。在本文中,µ1、µ2和µ3的值分别设置为2、1和10。
DDPG
我们采用的DDPG算法由4个神经网络组成,即actual actor网络、target actor 网络、actual critic 网络和target critic 网络。我们将4个网络的参数表示为 θ 1 θ_1 θ1、 θ 2 θ_2 θ2、 θ 3 θ_3 θ3、 θ 4 θ_4 θ4,算法流程如算法1和图3所示。


自己画了一份图↓

- 通过观察所有用户生成的任务和上一个时隙的卸载决策,可以获得系统状态,然后通过DDPG算法输出卸载决策。执行决策后,我们可以从环境中获得相应的反馈,系统也将转换到下一个状态,上述过程可以用四元组 ( s k , a k , r k , s k + 1 ′ ) (s_k, a_k, r_k, s^\prime_{k+1}) (sk,ak,rk,sk+1′)表示,并存储在经验池 D D D中。
- 随后,我们从经验池中随机抽取 p p p个样本,以更新 critic 网络。对于每个样本,我们首先将 s k s_k sk和 a k a_k ak输入到 actual critic 网络中,以获得实际的Q值。
- 然后将状态 s k + 1 ′ s^\prime_{k+1} sk+1′ 输入到 target actor 网络中以得到动作 a k + 1 ′ a^\prime_{k+1} ak+1′ 。
- 接下来,我们将 s k + 1 ′ s^\prime_{k+1} sk+1′ 和 a k + 1 ′ a^\prime_{k+1} ak+1′ 输入到 target critic 网络中,以获得 Q ( s k + 1 ′ , a k + 1 ′ ) Q(s^\prime_{k+1},a^\prime_{k+1}) Q(sk+1′,ak+1′),目标Q值可以通过等式(15)计算,其中θ表示未来奖励的衰减值,其值介于0和1之间。θ越接近1,未来的值越重要。
- Q ( s k + 1 ′ , μ ′ ( s k + 1 ′ ∣ θ 2 ) ∣ θ 4 ) Q\left(s^\prime_{k+1},\mu^\prime(s^\prime_{k+1}|\theta_2)|\theta_4\right) Q(sk+1′,μ′(sk+1′∣θ2)∣θ4)表示 target critic 网络输出的 Q ( s k + 1 ′ , a k + 1 ′ ) Q(s^\prime_{k+1},a^\prime_{k+1}) Q(sk+1′,ak+1′)。其中 μ ′ ( s k + 1 ′ ∣ θ 2 ) \mu^\prime(s^\prime_{k+1}|\theta_2) μ′(sk+1′∣θ2)表示 target actor 在状态 s k + 1 ′ s^\prime_{k+1} sk+1′下生成的动作。
- 由于我们希望 actual critic 网络输出的Q值尽可能等于target critic 网络的输出,因此该问题成为有监督学习问题。在每个训练步骤中,从D中提取一小批tuples,tuples的数量用 p p p表示,然后我们可以通过最小化等式(17)中所示的均方损失函数来反向传播和更新 actual critic 网络的参数:

其中 Q ( s k , a k ∣ θ 3 ) Q(s_k,a_k|θ_3) Q(sk,ak∣θ3)表示 actual critic 网络输出的 Q ( s k , a k ) Q(s_k,a_k) Q(sk,ak)。 - 最后,我们采用梯度上升来更新 actual actor 网络的参数。策略梯度可以由等式(18)表示。在每个训练步骤中,将根据 critic 网络的建议更新 actor 网络的参数,以更可能获得大的Q值。
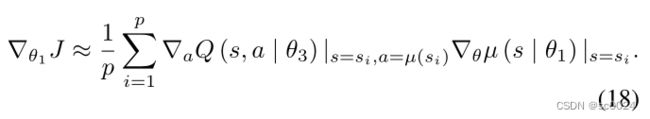
- 此外,每次完成一定数量的训练时,使用 actual actor 和actual critic 网络来更新 target actor 和 target critic 网络。我们采用软参数替换方法根据等式(19)更新目标网络的参数,其中 τ = 0.01 τ=0.01 τ=0.01。

把状态、动作、奖励定义好之后,就是套用标准的DDPG进行优化。DDPG以最小化时延和功耗为目标,解决了单区域的计算卸载问题,5选1。
B. Cooperative Caching Algorithm
当系统中的区域数量扩展到多个时,为了实现等式(14)中的优化目标(最小化总的计算开销),我们提出了一种协作缓存算法,以确定向边缘服务器的缓存添加、删除、交换和交换内容的时间。
在每个时隙开始时,所有区域中的所有用户将根据其区域中的任务分布生成计算任务。假设时隙k的区域m中的所有用户生成的任务集为 J m k = { J m k 1 , J m k 2 , … , J m k n } J_{mk}=\{J_{mk1},J_{mk2},…,J_{mkn}\} Jmk={Jmk1,Jmk2,…,Jmkn}。先查询本地缓存和协作缓存,然后统计每个区域中错过缓存查询的所有用户,收集其任务信息,应用算法1找到当前时隙中所有用户的卸载策略和计算资源分配策略。
要在区域中的边缘服务器上计算的任务集是 J m k e d J^{ed}_{mk} Jmked,与缓存在 C a c h e m Cache_m Cachem中的任务计算结果相对应的实际任务集是 J m k c a c h e J^{cache}_{mk} Jmkcache, J m k c a c h e J^{cache}_{mk} Jmkcache和 J m k e d J^{ed}_{mk} Jmked的并集表示为 J m k m e r g e J^{merge}_{mk} Jmkmerge。
此外,我们将时隙 k 开始时,边缘服务器在区域m中缓存的剩余空间表示为 ζ m k r ζ^r_{mk} ζmkr,并将所有区域中所有用户的最近T个时隙请求(包括当前时隙)的任务集表示为 J T J_T JT,我们可以得到

整个算法的流程如算法2所示。我们首先判断每个区域中边缘服务器缓存的剩余空间是否足以容纳所有选择卸载的任务的结果,并用 m a r k m mark_m markm标记其状态。
假设在 J m k e d J^{ed}_{mk} Jmked中存储所有任务的计算结果所需的缓冲容量为 o o o,如果 o ≤ ζ m k r o≤ ζ^r_{mk} o≤ζmkr,则 m a r k m = 1 mark_m=1 markm=1,否则 m a r k m = 0 mark_m=0 markm=0。
然后,我们根据等式(21)计算 J m k m e r g e J^{merge}_{mk} Jmkmerge中每个任务的适合度。

先计算缓存空间够不够,够的话mark=1,不够的话mark=0
计算每一个任务的适合度
如果缓存不够,就用操作1清缓存
用操作2向缓存m加入尽可能不同的内容
如果缓存不够,缓存m存的内容和别的区域有重叠,并且适合度更低,就用操作3进行二次删除,再用操作2补加一些内容。
这里没有用太多算法,只是定义了一个fit的计算公式

- 其中 m m m和 x x x分别是区域编号和任务编号
- ψ m x l o c a l ψ^{local}_{mx} ψmxlocal和 ψ m x e d g e ψ^{edge}_{mx} ψmxedge分别是在本地和边缘服务器上计算任务的系统开销。
- F x F_x Fx是最后T个时间片中任务的发生频率
- F a v g F_{avg} Favg是最后T时间片中生成的所有任务的平均发生频率, ε ε ε是比例因子。
- 适应度通过乘法符号分为三个部分:
- 第一部分表明,该区域中的用户执行此类任务的概率越大,此类任务的适应度越大。
- 第二部分中的分子表示卸载计算与本地计算相比的成本节约。分母表示这类任务结果的大小,这意味着缓存容量的单位大小节省的成本越大,适应性就越强。
- 第三部分表明,此类任务的频率越高,适应度越大。
在获得适应度水平后,我们将对所有区域的缓存执行操作1和操作2。
操作1:第一次,删除所有区域的缓存。消除缓存中最近 a a a个时隙中未请求的任务和近 b b b个时隙中任务请求数小于 σ σ σ的任务的计算结果,其中 σ = u ⋅ f b σ=u·f_b σ=u⋅fb, u u u是缩放因子, f b f_b fb是近 b b b个时隙中所有任务的平均请求数。
操作2:将内容添加到每个区域的缓存中。根据适合度将 J m k e d J^{ed}_{mk} Jmked中的任务从高到低排序,并尝试将其计算结果按顺序添加到缓存中,直到缓存容量不足以添加任何任务的计算结果。
在上述操作之后,多个区域中的缓存可能具有重叠内容。为了最大限度地利用缓存,需要删除这些重复内容,并且在所有缓存中最多只保留每种类型任务的计算结果的一个副本。我们采用的策略是执行操作3。
操作3:第二次删除缓存。比较不同缓存中重复内容的适合度,并仅保留适合度最高的内容。
最后,如果某个区域的边缘服务器在第二次删除过程中删除了内容,它将对第二次添加执行操作2,尽可能地填充缓存的剩余空间,以缓存更多任务的计算结果。
在上述操作过程中,如果 m a r k m = 1 mark_m=1 markm=1,将跳过区域缓存的两个删除过程。
V.仿真结果
A. Single-Region Offloading Decision Algorithm based on DDPG
在仿真中,多个用户共同使用边缘服务器进行辅助计算,用户生成的任务大小均匀分布在(800,900)kb之间。为了便于模型输出更好的卸载决策,假设当该区域的用户数量很小(小于等于6)时,不进行局部计算,所有用户都选择卸载计算。我们将DDPG模型中的行动者网络和批评网络的学习率分别设为0.0001和0.0002。每个训练步骤从经验池中抽取的批大小为50,每轮训练迭代次数为3000次,共进行20轮训练。此外,其余系统模型参数见表3。

我们将DDPG与三种基准算法和近端策略优化(PPO)算法进行了比较,以验证其性能。
- 在ALC (All Local Computing)算法中,所有用户在本地处理任务。
- 在全边缘计算(All Edge Computing, AEC)算法中,所有用户选择卸载到边缘服务器上执行任务。
- 在随机计算(RC)算法中,所有用户随机生成一个卸载策略。
如图4所示,整个系统的总成本随着该地区用户数量的增加而变化。可以看出,随着用户数量的增加,整个系统的总开销逐渐增加。与其他三种基准算法相比,本文算法和PPO算法有明显的性能提升。

reward曲线:
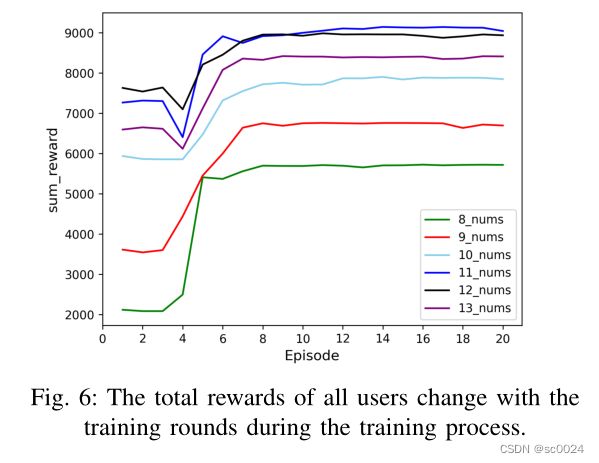
loss曲线:

B. Cooperative Caching Algorithm
为了验证我们提出的CCA + DDPG算法的性能,我们考虑了一个多区域的MEC网络,每个区域都配备了一个边缘服务器来辅助计算,所有用户都可以将任务转移到云端进行计算。我们随机生成50种类型的任务,每种类型任务的大小在[800,900]kb之间,存储每种类型任务的结果信息所需的缓存开销在[2,4]kb之间。我们假设每个区域有12个用户,每个边缘服务器的缓存容量为14kb,用户在每个区域的平均停留时间为10秒。其余系统的主要参数如表4所示。

比较了CCA算法与FIFO、LFU和LRU三种常用的缓存算法的性能。我们观察3000个时隙中所有用户的缓存命中和平均系统开销。图8(a)、8(b)、8(c)分别显示了当区域数量从3增加到6时,本地缓存命中、合作缓存命中和总体缓存命中。

我们可以看到,随着区域数量的增加,四种缓存算法的局部缓存命中率趋于稳定,协同缓存命中率有明显的上升趋势。这是因为区域数量的增加带来了缓存总内容的扩展。这使得它更容易击中协作缓存,而本地缓存不会受到它的影响。在这四种算法中,LRU算法和FIFO算法的性能比较接近,但性能并不理想。LFU算法在局部缓存命中率指标上表现最佳,CCA算法在协同缓存命中率和总缓存命中率方面表现最佳。从整体上看,虽然CCA算法在局部缓存的性能上略逊于LFU算法,但在协同缓存的性能上与其他算法相比有了明显的提升,因此具有最佳的整体缓存命中率。这是因为CCA算法通过计算适应度来决定缓存的添加和删除策略。在适应度计算过程中,同时考虑了局部任务分布和任务在所有区域的出现情况,第二次删除确保所有区域的缓存中不存在重叠,以最大限度地提高缓存率的整体命中率。
CCA算法的思想是通过牺牲少量的本地缓存命中率来尽可能地提高整体缓存性能。图9也证实了这一点。它展示了使用四种缓存算法和DDPG算法的用户在进行卸载决策时,随着区域数量的增加而产生的平均系统开销。我们可以看到,与其他三种算法相比,CCA算法可以显著降低系统的平均开销。
显然,为了提高系统的整体性能,在可接受的范围内牺牲本地缓存命中率是完全可以接受的。
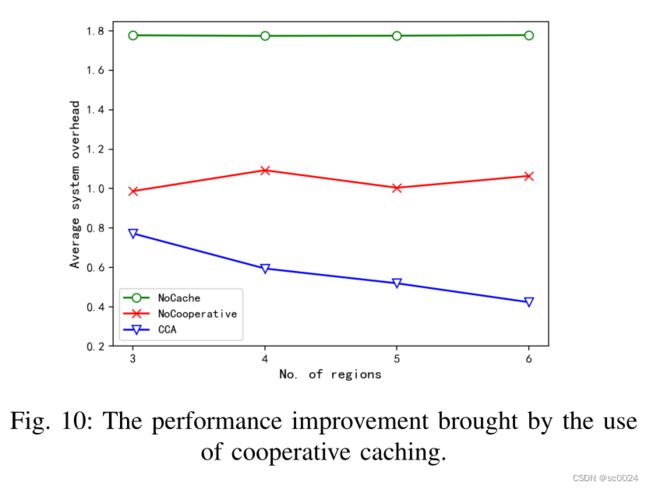
图10显示了使用协作缓存带来的性能改进(纵轴是平均系统开销)。
- NoCache方法表示不使用缓存机制,仅使用DDPG算法进行卸载决策。
- Cooperative method是指不使用协同缓存机制,用户只能通过本地缓存获取计算结果,缓存算法采用LFU算法。
我们可以看到,由于只需要考虑区域的当前状态,随着区域数量的增加,NoCache和NoCooperative方法对应的平均用户系统开销保持相对稳定,使用缓存比不使用缓存可以带来较大的性能提升。使用联合缓存带来的性能改善也比只使用局部缓存带来的性能改善非常明显,这也证实了我们提出的CCA算法的优越性。
*实现笔记
原论文里的模型
DDPG负责单区域,一个基站对应一个服务器,N个用户,每个用户在每个时隙产生1个任务。
状态
s t a t e = ( C n , k − 1 , F e d r , R a k − 1 , R f k − 1 ) state=(C_{n,k−1},F^r_{ed},Ra_{k−1},Rf_{k−1}) state=(Cn,k−1,Fedr,Rak−1,Rfk−1) .
- C n , k − 1 C_{n,k−1} Cn,k−1是所有用户在前一个时隙中完成所有计算任务所导致的总系统开销(单个数值)
- F e d r F^r_{ed} Fedr表示边缘服务器的剩余计算资源(数值)
- R a k − 1 Ra_{k−1} Rak−1是前一时隙中用户的卸载决策向量(M*N)
- R f k − 1 Rf_{k−1} Rfk−1是由前一时隙的边缘服务器分配给每个用户的计算资源组成的资源分配向量(M*N)
初始化,即reset:在第一时隙中,假设用户正在本地执行计算任务。因此,在初始状态下, C n , k − 1 C_{n,k−1} Cn,k−1是所有用户在本地完成计算任务所造成的延迟和能耗之和, F e d r F^r_{ed} Fedr等于边缘服务器拥有的最大计算资源, R a k − 1 Ra_{k−1} Rak−1和 R f k − 1 Rf_{k−1} Rfk−1都是零向量,这意味着用户在本地执行计算。
动作
A c t i o n = ( R a , R f ) Action=(Ra,Rf) Action=(Ra,Rf)
R a Ra Ra表示当前时隙k中所有用户的卸载决策,定义为 R a ( k ) = [ R a 1 ( k ) , R a 2 ( k ) , . . . , R a M ( k ) ] Ra_{{(k)}}=[ Ra_{1(k)},Ra_{2(k)},...,Ra_{M(k)}] Ra(k)=[Ra1(k),Ra2(k),...,RaM(k)],而 R a M ( k ) Ra_{M(k)} RaM(k)表示当前时隙 k k k中,,位于区域m中的所有用户的卸载决策向量,定义为 R a M ( k ) = [ δ 1 ( m ) k , δ 2 ( m ) k , . . . , δ N ( m ) k ] Ra_{M(k)}=[δ^k_{1(m)},δ^k_{2(m)},...,δ^k_{N(m)}] RaM(k)=[δ1(m)k,δ2(m)k,...,δN(m)k]。
类似地, R f Rf Rf表示每个用户在时隙 k k k中从边缘服务器分配的计算资源,其被定义为 R f ( k ) = [ R f 1 ( k ) , R f 2 ( k ) , . . . , R f M ( k ) ] Rf_{{(k)}}=[ Rf_{1(k)},Rf_{2(k)},...,Rf_{M(k)}] Rf(k)=[Rf1(k),Rf2(k),...,RfM(k)], R f m ( k ) Rf_{m(k)} Rfm(k)表示位于区域 m m m中的所有用户在时隙 k k k中从边缘服务器获得的计算资源分配向量,其定义为 R f M ( k ) = [ f 1 ( m k ) e d , f 2 ( m k ) e d , . . . , f N ( m k ) e d ] Rf_{M(k)}=[ f^{ed}_{1(mk)},f^{ed}_{2(mk)},...,f^{ed}_{N(mk)}] RfM(k)=[f1(mk)ed,f2(mk)ed,...,fN(mk)ed]
如果不考虑协同缓存的话,区域和区域间是独立的,仿真只需要考虑单区域,Ra和Rf是1*N的一维向量即可。
需要随机分配的变量
- 完成任务所需的CPU时钟数 d n d_n dn,