R语言:企业风险分析(5)【输入建模,断点法】
本章介绍在数据不可获得的情况下,输入建模常用的断点法
数据不可用时的输入建模
如果我们没有数据来对模型中的不确定变量进行建模,那么我们必须使用我们能找到的任何东西,包括:
- 专家意见
- 物理或常规限制(可以提供界限)
- 过程的物理基础(可以建议适当的分布系列)
专家意见建模的两种通用方法:
- 断点法
- 均值和变异法
本章介绍常用的断点法:
案例
一个机动车辆部门,其运作如下:
每位客户都有一名接待员检查其文件的准确性。每个客户的服务时间(分钟)可以取2到5分钟之间的任何值。然后,每个客户都要求提供以下服务:
1.获取或更新驾驶执照 2.注册汽车 3. 离开。
(30%的客户获得或更新驾驶执照,50%的客户注册汽车,其余20%的客户退出服务)
获取或更新驾照的服务时间是 形状参数3和比例参数10进行伽马分布。
注册汽车是该部门向客户提供的一项新服务,因此管理层缺乏数据来找到代表该服务特点的最佳分布。然而,专家们认为,服务时间通常在10到35分钟之间,20%的几率小于15分钟,60%的几率小于25分钟,95%的几率小于30分钟。
接待员的人工成本为每小时20美元,服务人员领取或更新驾驶执照的人工成本为30美元,帮助客户登记汽车的人工成本为40美元。为该系统开发一个仿真模型,并回答以下问题:
a、 每位客户的服务时间平均值和标准差是多少(不包括等待时间)?
b、 每位客户的服务时间少于8分钟的概率是多少?每位客户的服务时间超过20分钟的概率是多少?
c、 每个客户提供此服务的人工成本的平均值和标准差是多少?
开始建模
假设有1000位客户,按照已知的不同服务需求分成3组
n <- 1000
groupA <- n*0.3 # 30%获得或更新驾驶执照
groupB <- n*0.5 # 50%的客户注册汽车
groupC <- n*0.2 # 20%的客户退出服务对于groupA ,先在接待处检查其文件的准确性,再根据伽马分布得到服务时间。第三列为总花费时间,第四列为人工成本的计算。
df_a <- data.frame(runif(groupA, 2, 5))
colnames(df_a) <- 'check_time'
df_a$service_time <- rgamma(groupA, shape = 3, scale = 10)
df_a$total_time <- df_a$check_time + df_a$service_time
df_a$labor_cost <- df_a$check_time/60*20 + df_a$service_time/60*30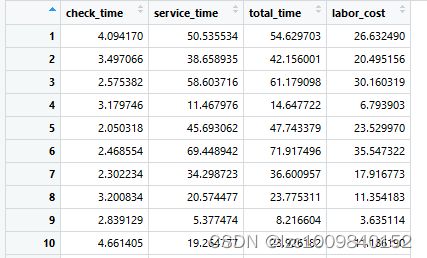
对于groupB ,先在接待处检查其文件的准确性,再根据断点法得到服务时间。第三列为总花费时间,第四列为人工成本的计算。
【本章的重点就是如何解决 ‘服务时间通常在10到35分钟之间,20%的几率小于15分钟,60%的几率小于25分钟,95%的几率小于30分钟。’】【也可以用if的方法,但当分段较多的时候,本文介绍的方法更为便利】
所以建立函数:
#breakpoints distribution using generic function
qbp <- function(p,probs,ints){
ifelse(p之后 groupB 和 groupA 一样的操作
df_b <- data.frame(runif(groupB, 2, 5))
colnames(df_b) <- 'check_time'
df_b$service_time <- rbp(groupB, probs = probs, ints = Ints)
df_b$total_time <- df_b$check_time + df_b$service_time
df_b$labor_cost <- df_b$check_time/60*20 + df_b$service_time/60*40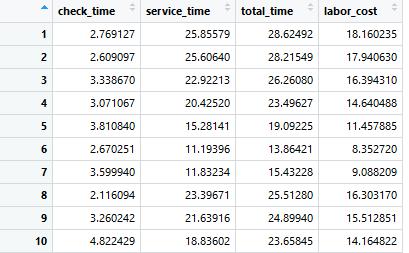
groupC也一样,最后将三表合并(因为在接待处后没有服务,直接离开,为0)
library(tidyverse) # %>% 用到
df_c <- data.frame(runif(groupC, 2, 5))
colnames(df_c) <- 'check_time'
df_c$service_time <- 0
df_c$total_time <- df_c$check_time + df_c$service_time
df_c$labor_cost <- df_c$check_time/60*20
df_3 <- rbind(df_a,df_b) %>% rbind(df_c) # 合并
rbind: 按行进行合并
回答问题
a、 每位客户的服务时间平均值和标准差是多少(不包括等待时间)?
mean(df_3$total_time)
sd(df_3$total_time) 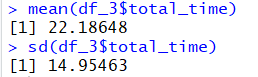
b、 每位客户的服务时间少于8分钟的概率是多少?每位客户的服务时间超过20分钟的概率是多少?
sum(df_3$total_time < 8)/n
sum(df_3$total_time > 20)/n 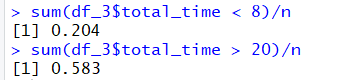
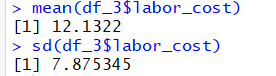
c、 每个客户提供此服务的人工成本的平均值和标准差是多少?
mean(df_3$labor_cost)
sd(df_3$labor_cost)
大功告成!
内容源于波士顿大学,感谢教授David Ritt