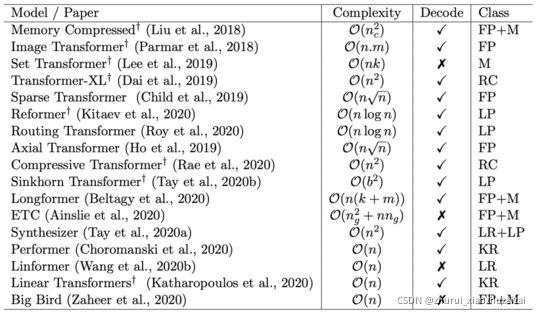
transformer的各种变体


https://mp.weixin.qq.com/s/iuuRS_M3cYm0DXFkZGjjBg
一 transformer 优化盘点:
- Fixed Patterns(固定模式):将视野限定为固定的预定义模式,例如局部窗口、固定步幅块,用于简化注意力矩阵;
- Learnable Patterns(可学习模式):以数据驱动的方式学习访问模式,关键在于确定token相关性。
- Memory(内存):利用可以一次访问多个token的内存模块,例如全局存储器。
- Low Rank(低秩):通过利用自注意力矩阵的低秩近似,来提高效率。
- Kernels(内核):通过内核化的方式提高效率,其中核是注意力矩阵的近似,可视为低秩方法的一种。
- Recurrence(递归):利用递归,连接矩阵分块法中的各个块,最终提高效率。
二. transformer 模型概要:
1、Memory Compressed Transformer(2018)
这是让Transformer能更好地处理长序列的早期尝试之一,主要修改了两个部分:定位范围注意、内存压缩注意。
其中,前者旨在将输入序列分为长度相似的模块,并在每个部分中运行自注意力机制,这样能保证每个部分的注意力成本不变,激活次数就能根据输入长度线性缩放。
后者则是采用跨步卷积,减少注意力矩阵的大小、以及注意力的计算量,减少的量取决于跨步的步幅。
2、Image Transformer(2018)
这是个受卷积神经网络启发的Transformer变种,重点是局部注意范围,即将接受域限制为局部领域,主要有两种方案:一维局部注意和二维局部注意。
不过,这种模型有一个限制条件,即要以失去全局接受域为代价,以降低存储和计算成本。
3、 Set Transformer(2019)
这个模型是为解决一种特殊应用场景而生的:输入是一组特征,输出是这组特征的函数。
它利用了稀疏高斯过程,将输入集大小的注意复杂度从二次降为线性。
4、Sparse Transformer(2019)
这个模型的关键思想,在于仅在一小部分稀疏的数据对上计算注意力,以将密集注意力矩阵简化为稀疏版本。
不过这个模型对硬件有所要求,需要自定义GPU内核,且无法直接在TPU等其他硬件上使用。
详见3.2
5、Axial Transformer(2019)
这个模型主要沿输入张量的单轴施加多个注意力,每个注意力都沿特定轴混合信息,从而使沿其他轴的信息保持独立。
由于任何单轴的长度通常都比元素总数小得多,因此这个模型可以显著地节省计算和内存。
Star-Transformer(2019)
详见3.8
6、Longformer(2020)
Sparse Transformer的变体,通过在注意力模式中留有空隙、增加感受野来实现更好的远程覆盖。
在分类任务上,Longformer采用可以访问所有输入序列的全局token(例如CLS token)。
详见3.3
7、Extended Transformer Construction(2020)
同样是Sparse Transformer的变体,引入了一种新的全局本地注意力机制,在引入全局token方面与Longformer相似。
但由于无法计算因果掩码,ETC不能用于自动回归解码。
8、BigBird(2020)
与Longformer一样,同样使用全局内存,但不同的是,它有独特的“内部变压器构造(ITC)”,即全局内存已扩展为在sequence中包含token,而不是简单的参数化内存。
然而,与ETC一样,BigBird同样不能用于自动回归解码。
详见3.7
9、Routing Transformer(2020)
提出了一种基于聚类的注意力机制,以数据驱动的方式学习注意力稀疏。为了确保集群中的token数量相似,模型会初始化聚类,计算每个token相对于聚类质心的距离。
详见3.5
10、Reformer(2020)
一个基于局部敏感哈希(LSH)的注意力模型,引入了可逆的Transformer层,有助于进一步减少内存占用量。
模型的关键思想,是附近的向量应获得相似的哈希值,而远距离的向量则不应获得相似的哈希值,因此被称为“局部敏感”。
11、Sinkhorn Transformer(2020)
这个模型属于分块模型,以分块的方式对输入键和值进行重新排序,并应用基于块的局部注意力机制来学习稀疏模式。
12、Linformer(2020)
这是基于低秩的自注意力机制的高效Transformer模型,主要在长度维度上进行低秩投影,在单次转换中按维度混合序列信息。
详见3.6
13、Linear Transformer(2020)
这个模型通过使用基于核的自注意力机制、和矩阵产品的关联特性,将自注意力的复杂性从二次降低为线性。
目前,它已经被证明可以在基本保持预测性能的情况下,将推理速度提高多达三个数量级。
14、Performer(2020)
这个模型利用正交随机特征(ORF),采用近似的方法避免存储和计算注意力矩阵。
15、Synthesizer models(2020)
这个模型研究了调节在自注意力机制中的作用,它合成了一个自注意力模块,近似了这个注意权重。
16、Transformer-XL(2020)
这个模型使用递归机制链接相邻的部分。基于块的递归可被视为与其他讨论的技术正交的方法,因为它没有明确稀疏密集的自注意力矩阵。
详见3.1
17、Compressive Transformers(2020)
这个模型是Transformer-XL的扩展,但不同于Transformer-XL,后者在跨段移动时会丢弃过去的激活,而它的关键思想则是保持对过去段激活的细粒度记忆。
18、Funnel-Transformer(2020)
采用标准的、非参数化的傅里叶变换替代自注意力子层
19、Fnet(2021)
漏斗型(Funnel)Transformer,随着层数增加,模型在序列方向变窄,从而节约空间开销,具体方法就是使用池化(Pooling)操作
20、Nyströmformer(2021)
以一个简单的双重softmax形式的线性Attention为出发点,逐步寻找更加接近标准Attention的线性Attention,从而得到Nyströmformer。
整体来说,这些经典模型的参数量如下:
三 transformer 模型细节:
3.1 Transformer-XL
论文标题: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
收录会议: ACL 2019
论文链接: https://arxiv.org/abs/1901.02860
代码链接: https://github.com/kimiyoung/transformer-xl


上图上标的是“Recurrence”,首先看看这篇文章聚焦的 2 个问题:
虽然 Transformer可以学习到输入文本的长距离依赖关系和全局特性,但是!需要事先设定输入长度,这导致了其对于长程关系的捕捉有了一定限制。
出于效率的考虑,需要对输入的整个文档进行分割(固定的),那么每个序列的计算相互独立,所以只能够学习到同个序列内的语义联系,整体上看,这将会导致文档语意上下文的碎片化(context fragmentation)。
那么如何学习更长语义联系?

segment-level Recurrence
segment-level 循环机制。如上图左边为原始 Transformer,右边为Transformer-XL,Transformer-XL模型的计算当中加入绿色连线,使得当层的输入取决于本序列和上一个序列前一层的输出。这样每个序列计算后的隐状态会参与到下一个序列的计算当中,使得模型能够学习到跨序列的语义联系(看动图可能更好理解)。
hrn是第r个 segment 的第 n 层隐向量,那么第 r+1 个的第 n 层的隐向量的计算,就是上面这套公式。
其中 SG 是是 stop-gradient,不再对st的隐向量做反向传播(这样虽然在计算中运用了前一个序列的计算结果,但是在反向传播中并不对其进行梯度的更新,毕竟前一个梯度肯定不受影响)。
h(r+1)(~n-1)是对两个隐向量序列沿长度 L 方向的拼接 。3 个 W 分别对应 query,key 和 value 的转化矩阵,需要注意的是!k 和 v 的 W 用的是 h(r+1)(n-1) ,而 q 是用的 h(r+1)(~n-1) ,即 kv 是用的拼接之后的 h,而 q 用的是原始序列的信息。感觉可以理解为以原始序列查拼接序列,这样可以得到一些前一个序列的部分信息以实现跨语义。
最后的公式是标准的 Transformer。
还有一点设计是,在评估预测模型的时候它是会连续计算前 L 个长度的隐向量的(训练的时候只有前一个,缓存在内存中)。
即每一个位置的隐向量,除了自己的位置,都跟下一层中前(L-1)个位置的 token 存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1),这样能使跨语义更加的深入。
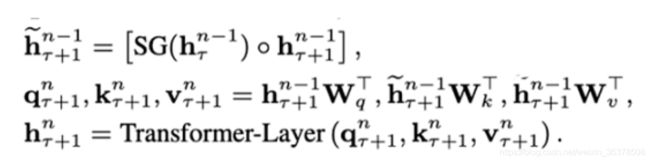

def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):
#w是上一层的输出,r是相对位置嵌入(在下一节),r_w_bias是u,r_r_bias是v向量
qlen, rlen, bsz = w.size(0), r.size(0), w.size(1)
if mems is not None: #mems就是前一些序列的向量,不为空
cat = torch.cat([mems, w], 0) #就拼起来
if self.pre_lnorm: #如果有正则化
w_heads = self.qkv_net(self.layer_norm(cat)) #这个net是nn.Linear,即qkv的变换矩阵W参数
else:
w_heads = self.qkv_net(cat)#没有正则就直接投影一下
r_head_k = self.r_net(r)#也是nn.Linear
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1) #复制3份
w_head_q = w_head_q[-qlen:] #q的W不要拼接的mems
else:#没有mems,就正常的计算
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0)
#qlen是序列长度,bsz是batch size,n_head是注意力头数,d_head是每个头的隐层维度
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
r_head_k = r_head_k.view(rlen, self.n_head, self.d_head) # qlen x n_head x d_head
####计算注意力的四个部分
#AC是指相对位置的公式里的a和c两个部分,相对位置在下一节做笔记
rw_head_q = w_head_q + r_w_bias # qlen x bsz x n_head x d_head
#爱因斯坦简记法求和sum,统一的方式表示各种各样的张量运算
AC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head
#BD是指相对位置的公式里的b和d两个部分
rr_head_q = w_head_q + r_r_bias
BD = torch.einsum('ibnd,jnd->ijbn', (rr_head_q, r_head_k)) # qlen x klen x bsz x n_head
BD = self._rel_shift(BD)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD #最后的结果
attn_score.mul_(self.scale)#进行放缩
Relative Position Encodings
相对位置编码。原始 Transformer采用了正弦/余弦函数来编码绝对位置信息。然而因为 Transformer-XL会有多个句子,所以还是绝对位置,那么两个句子的相同位置是同样的编码。 比如 [0, 1, 2, 3] 在两个句子 concat 之后就变成了 [0, 1, 2, 3, 0, 1, 2, 3],句子不连续,而且每次拼的句子会不一样,也不能找到适合的绝对位置编码。所以这里使用相对位置编码。
上图是原始 Transformer 和 Transformer-XL 的比较,其中 E 表示词的 Embedding,而 U表示绝对位置编码。这大一堆看起来奇奇怪怪,实际上 Transformer 的注意力计算是 的分解,即先编码 Q(当前词 i)和 K(其他的词 j)然后算内积,位置编码是直接 add 在词嵌入上面的。
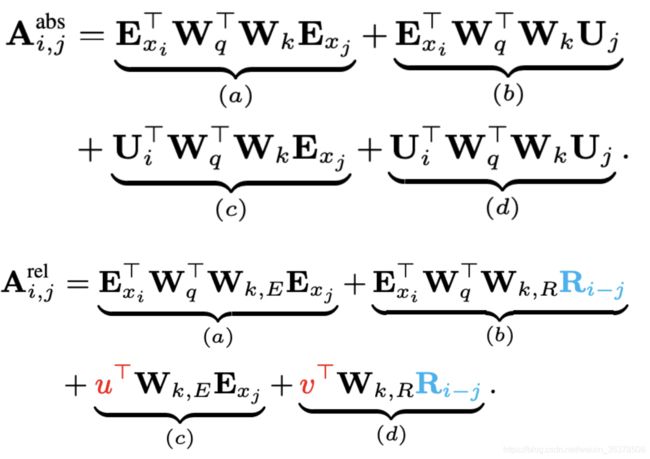
而 Transformer-XL 的改变是:
把 j 的绝对位置 U 换成了相对位置 R,该相对位置表示也是一个正弦函数表示(i 和 j的相对位置向量,j 是之前的序列,所以相减一定是正数)。R 不是通过学习得到的,好处是预测时,可以使用比训练距离更长的位置向量。
使用两个可学习参数 u 和 v 替代了中的 query i 的位置映射。这里是由于每次计算 query 向量是固定的,不需要编码。 每一层的Attention 计算都要相对位置编码。Transformer 里面只有 input 的时候会加,而 XL 需要每层。
细细思考,这 attention 的四个部分各有玄机:
a. 基于内容的“寻址”,即没有添加原始位置编码的原始向量, 查 。
b. 基于内容的位置偏置,即相对于当前内容的位置偏差, 查 。
c. 全局的内容偏置,用于衡量 key 的重要性,query 固定查 。
d. 全局的位置偏置,根据 query 和 key 之间的距离调整重要性,query 固定查 。
相对位置编码的代码为:
class PositionalEmbedding(nn.Module):
def __init__(self, demb):
super(PositionalEmbedding, self).__init__()
self.demb = demb #编码维度
inv_freq = 1 / (10000 ** (torch.arange(0.0, demb, 2.0) / demb)) #间隔频率
def forward(self, pos_seq):
sinusoid_inp = torch.ger(pos_seq, self.inv_freq) #序列的位置向量 operation 间隔
pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1) #正弦余弦
return pos_emb[:,None,:] #直接返回R,非学习矩阵R
使用 Transformer-XL 的预训练模型经典的就是 XLNet 啦,可以更好的处理较长的文本。
然后是关于 Transformer 的复杂度问题进行改进的文章。
3.2 Explicit Sparse Transformer
论文标题:
Explicit Sparse Transformer: Concentrated Attention Through
Explicit Selection
论文链接:https://arxiv.org/abs/1912.11637
代码链接:https://github.com/lancopku/Explicit-Sparse-Transformer

标准 Transformer 的复杂度为O(n平方),但是否序列内的所有元素都有必要被关注到,是否有方法可以简化这个机制?所以本文的“Sparse”重点就体现在只有少量的 token 参与 attention 分布的计算,以提升注意力机制的集中度。
即本来一个词只和少量的词有关,但是标准自注意力却会给所有的词都分配权重然后聚合,一种很自然的想法就是通过显式选择,只让模型关注少数几个元素就行。

模型图如上图,最左边是标准计算注意力的路线,中间的是 Sparse 的实现,可以看到区别就在于中间多了一个手工选择的Sparsification,最右则是它的执行示意图。简单来说就是在算 softmax 分数之前先进行 top-k
选择出少数的重要元素即可。
具体来说
先算内积;然后人工按内积分数过滤 top-k 个元素,即下式中的 M 操作,其他的 P则直接置为负无穷,这样强制只让 k 个元素被关注。最后再把分数回乘给 V
通过这种操作,可以使注意力更集中。这种减轻计算量的操作也让 GPT-3 等模型能够架得更大更暴力也取得了很好的但是玩不起效果。
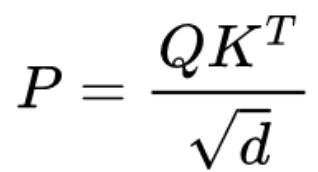


3.3 Longformer
论文标题:
Longformer: The Long-Document Transformer
论文链接:
https://arxiv.org/abs/2004.05150
代码链接:
https://github.com/allenai/longformer

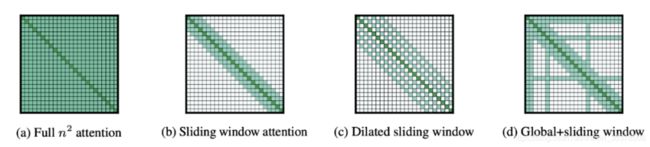
Longformer 也算是一种比较经典的 Sparse 的方法了吧。一共提出了 3 种策略:
Sliding Window:如上图 (b)所示,跟 CNN 很像,给定一个固定的窗口大小 w,其两边都有个 w/2 个 token 与其做 attention。计算复杂度降为 O(n x w),即复杂度与序列长度呈线性关系。而且如果为每一层设置不同的窗口 size 可以很好地平衡模型效率和表示能力。Dilated sliding window:如上图 © 所示,类似扩张CNN,可以在计算复杂度不变的情况下进一步扩大接收域。同样的,如果在多头注意力机制的每个头设置不同的扩张配置,可以关注文章的不同局部上下文,特别是通过这种Dilated 可以扩张甚至很远的地方。
Global Attention :如图 (d) 所示,计算全局 token 可能表征序列的整体特性。比如 BERT 中的 [CLS]这种功能,复杂度降为 O(n)。
3.4 Switch Transformer
论文标题:
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
论文链接: https://arxiv.org/abs/2101.03961
代码链接:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py

相比起 Sparse Attention 需要用到稀疏算子而很难发挥 GPU、TPU 硬件性能的问题。Switch Transformer不需要稀疏算子,可以更好的适应 GPU、TPU 等稠密硬件。主要的想法是简化稀疏路由。

即在自然语言 MoE (Mixture of experts)层中,只将 token表征发送给单个专家而不是多个的表现会更好。模型架构如上图,中间蓝色部分是比价关键的部分,可以看到每次 router 都只把信息传给分数 p最大的单个 FFN。而这个操作可以大大降低计算量。
然后另一方面,其成功的原因是有一个很秀的并行策略,其同时结合了数据并行 + 模型并行 + expert 并行。具体如下图:
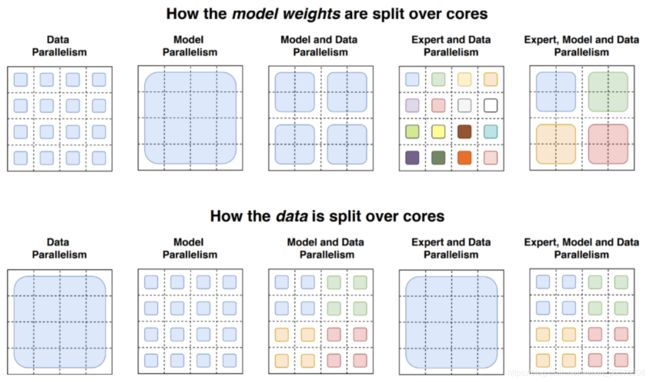
其实对应模型架构来看,experts 并行是算子间的并行,其对应的 FFN 内部有算子级的模型并行,而整个 experts在计算图上又是个多并行 FFN 分支,这是算子间模型并行,所以能够获得更低的通信开销,提高并行的效率。
3.5 Routing Transformers
论文标题: Efficient Content-Based Sparse Attention with Routing
Transformers 收录会议: TACL 2020 论文链接: https://arxiv.org/abs/2003.05997
代码链接:
https://github.com/google-research/google-research/tree/master/routing_transformer

和前两篇文章的目标一样,如何使标准 Transformer 的时间复杂度降低。Routing Transformer将该问题建模为一个路由问题,目的是让模型学会选择词例的稀疏聚类,所谓的聚类簇是关于每个键和查询的内容的函数,而不仅仅与它们的绝对或相对位置相关。
简单来说就是,作用差不多的词是可以变成聚类到一个表示的,这样来加速计算。

如上图与其他模型的对比,图中的每一行代表输出,每一列代表输入,对于 a 和 b图来说,着色的方块代表每一个输出行注意到的元素。对于路由注意力机制来说,不同的颜色代表输出词例的聚类中的成员。具体做法是先用一种公共的随机权重矩阵对键和查询的值进行投影:
然后把 R 中的向量用 k-means 聚类成 k 个簇,然后在每个簇 中加权求和上下文得到嵌入:
最后作者使用了 根号n个簇,所以时间复杂度降维 。详细可以看原论文和代码实现。


3.6 Linformer
论文标题: Linformer: Self-Attention with Linear Complexity
论文链接:
https://arxiv.org/abs/2006.04768
代码链接:
https://github.com/tatp22/linformer-pytorch

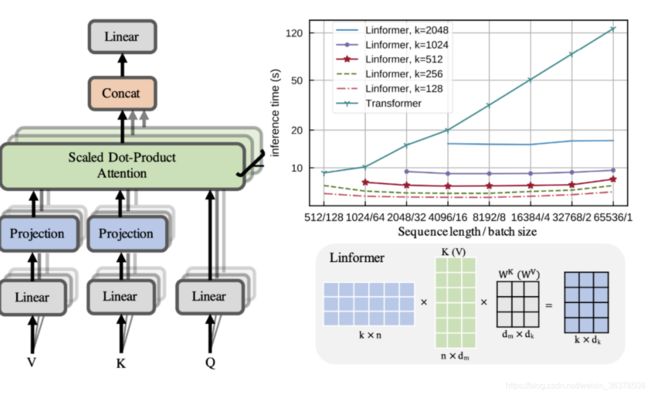
从 O(n的平方) 到 O(n)!
首先作者从理论和经验上证明了自注意机制所形成的随机矩阵可以近似为低秩矩阵,所以直接多引入线性投影将原始的缩放点积关注分解为多个较小的关注,也就是说这些小关注组合是标准注意力的低秩因数分解。即如上图,在计算键K 和值 V 时添加两个线性投影矩阵 E 和 F,即:
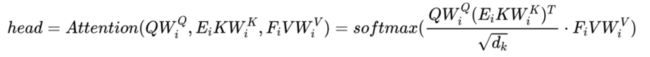
同时还提供三种层级的参数共享:
Headwise: 所有注意力头共享投影句子参数,即 Ei=E,Fi=F。
Key-Value:所有的注意力头的键值映射矩阵共享参数同一参数 ,即 Ei=Fi=E。
Layerwise: 所有层参数都共享。即对于所有层,都共享投射矩阵E。 完整内容可以看原文,原文有理论证明低秩和分析。
3.7 Big Bird
论文标题: Big Bird: Transformers for Longer Sequences
论文链接:
https://arxiv.org/abs/2007.14062


也是采用稀疏注意力机制,将复杂度下降到线性,即 O(N)。
如上图,big bird 主要包括三个部分的注意力:
Random Attention(随机注意力)。如图 a,对于每一个 token i,随机选择 r 个 token 计算注意力。
Window Attention(局部注意力)。如图 b,用滑动窗口表示注意力计算 token 的局部信息。
Global Attention(全局注意力)。如图 c,计算全局信息。这些在 Longformer 中也讲过,可以参考对应论文。
最后把这三部分注意力结合在一起得到注意力矩阵 A,如图 d 就是 BIGBIRD 的结果了,计算公式为:
H 是头数,N(i) 是所有需要计算的 token,这里就是由三部分得来的稀疏部分,QKV 则是老伙伴了。

3.8 Star-Transformer
论文标题: Star-Transformer
收录会议:NAACL 2019
论文链接:https://arxiv.org/abs/1902.09113
代码链接:https://github.com/fastnlp/fastNLP

问题:
Transformer 的自注意力机制每次都要计算所有词之间的注意力,其计算复杂度为输入长度的平方,结构很重
在语言序列中相邻的词往往本身就会有较强的相关性,似乎本来就不需要计算所有词之间
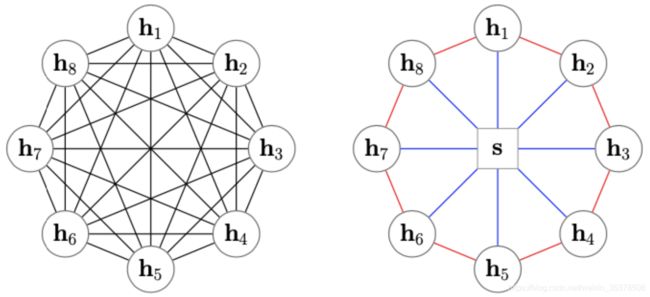
解决:
Star-Transformer 用星型拓扑结构代替了全连通结构如上图左边是 Transformer,而右边是Star-Transformer。在右边的图中,所有序列中直接相邻的词可以直接相互作用,而非直接相邻的元素则通过中心节点实现间接得信息传递,因此,复杂性从二次降低到线性,同时保留捕获局部成分和长期依赖关系的能力。
Radical connections,捕捉非局部信息。即每两个不相邻的卫星节点都是两跳邻居,可以通过两步更新接收非局部信息。
Ring connections,捕捉局部信息。由于文本输入是一个序列,相邻词相连以捕捉局部成分之间的关系。值得注意的是它第一个节点和最后一个节点也连接起来,形成环形连接。
具体实现算法如下:

在初始化阶段,卫星节点(周围的词节点)的初始值为各自相应的词向量 e1,e2,……en,而中心节点(集成节点)的初始值为所有词节点词向量的平均值ave(e1,e2,……en) 。
更新卫星节点。对于某卫星节点 i,先得到它的上下文信息 Cit,它由相邻节点hi-1,hi+1 ,中心节点s ,和这个节点对应的 token 词嵌入 ei组成。然后多头注意力更新特征,最后使用层归一化。 更新中心节点(relay node)。
中心节点与上一时刻和所有卫星信息的交互,所以同样是多头注意力multiATT(st-1,st-1) ,H 是可学习的位置编码(它在所有时刻都是一样的)。
交替更新 T步,over。
3.9 Funnel-Transformer
论文链接:https://arxiv.org/abs/2006.03236
代码链接:http://github.com/laiguokun/Funnel-Transformer
提出Funnel-Transformer,在序列长度方面“压缩”模型,使之具有更好的处理长序列的效率;
同时,引入Decoder,保持模型最后的输出可以和原序列长度一致,从而保持Transformer处理各类任务的能力;
在句子级别的任务上取得很好的效果,同时也可以扩展到其他任何任务

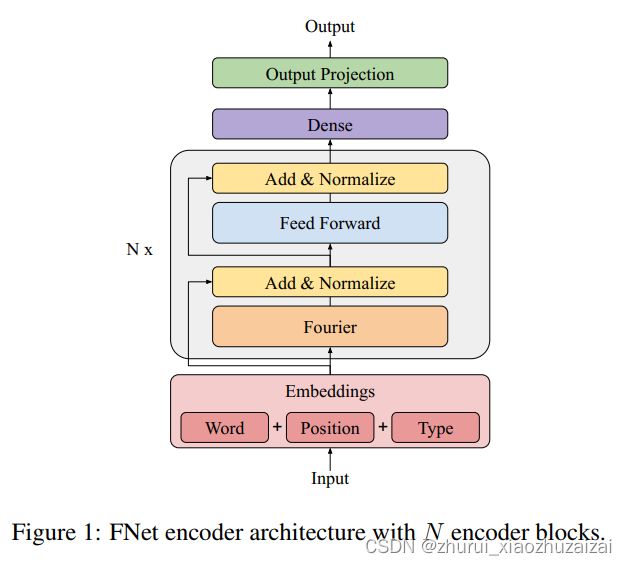
3.10 FNet
论文地址:https://arxiv.org/abs/2105.03824
代码地址:https://github.com/google-research/google-research/tree/master/f_net
采用标准的、非参数化的傅里叶变换替代自注意力子层,可以在 GLUE 基准测试中实现 92%~97%的 BERT 准确率,在标准的512输入长度的token中,在 GPU 上的训练时间快 80%,在 TPU 上的训练时间快 70%。在更长的输入长度上,FNet模型的训练时间更快。而且FNet 在Long Range Arena基准评估中,与所有的高效 transformer 具有竞争力,同时在所有序列长度上拥有更少的内存占用。
3.11 Nyströmformer:
论文地址:https://arxiv.org/abs/2102.03902
代码地址:https://github.com/mlpen/Nystromformer
基于矩阵分解的线性化Attention方案
聚类QK,迭代求伪逆
参考资料:https://spaces.ac.cn/archives/8180
四 transformer 模型应用:
4.1 PEGASUS:摘要提取
4.2 ProhetNet:预测Ngram
生成任务:
论文标题生成CSL, LCSTS
WebQA
微博新闻摘要
五 transformer 系列模型:
只使用encoder :
bert系列
只使用decoder:
OPT
GPTseq2seq:
BART
T5
参考文档:
Transformer模型大盘点,NLP学习必备