YOLOv5 detect.py文件部分参数使用
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--max-det', type=int, default=1000, help='maximum number of detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
opt = parser.parse_args()
- parser.add_argument(’–weights’, nargs=’+’, type=str, default=‘yolov5s.pt’, help=‘model.pt path(s)’)
- default=’ ’ 可选参数如下
- yolov5s.pt
- yolov5m.pt
- yolov5l.pt
- yolov5x.pt
- yolov5s6.pt
- yolov5m6.pt
- yolov5l6.pt
- yolov5x6.pt
- default=’ ’ 可选参数如下
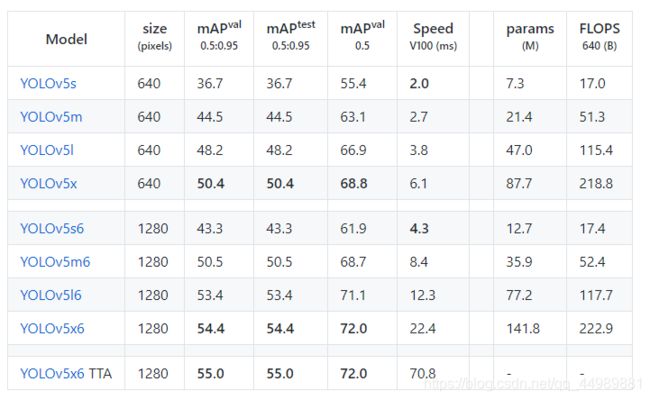
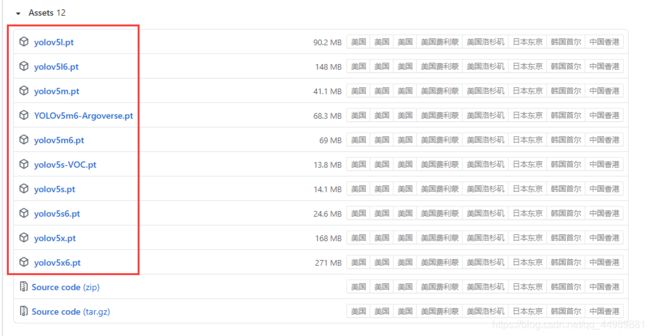
注: 第一次加载会从 github上下载训练好的神经网络 yolov5s.pt 文件,如果无法下载,可以从 yolov5 的官方网址中找到如下图,根据不同的模型进行对比,选择需要的模型进行下载。
下载好以后,放在项目的根目录下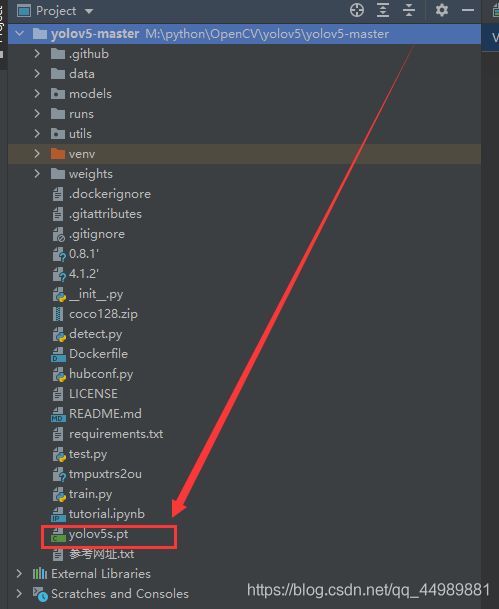
在文件夹中所在的位置

-
parser.add_argument(’–source’, type=str, default=‘data/images’, help=‘source’)
- 根据需要可以对视频,图片进行检测
- default=‘data/images’:对该文件夹下的所有图片进行检测
- default=‘data/images/test.jpg’:对该图片进行检测
- default=‘data/video/demo.mp4’:对该视频进行检测
- default=‘0’:调用摄像头(如果是笔记本,调用笔记本自带摄像头)
- default=‘1’:调用usb摄像头
- 根据需要可以对视频,图片进行检测
-
parser.add_argument(’–img-size’, type=int, default=640, help=‘inference size (pixels)’)
- 在训练的过程中对图片的尺寸进行缩放,输入图片和输出的图片尺寸不发生改变。
- default=640
- default=1290
- 在训练的过程中对图片的尺寸进行缩放,输入图片和输出的图片尺寸不发生改变。
-
parser.add_argument(’–conf-thres’, type=float, default=0.25, help=‘object confidence threshold’)
- 检测目标的概率大于 默认值 就会在图像中标记出来。
- default=0.25:检测目标的概率大于 0.25 就会在图像中标记出来
- default=0.68:检测目标的概率大于 0.68 就会在图像中标记出来
- 检测目标的概率大于 默认值 就会在图像中标记出来。
-
parser.add_argument(’–iou-thres’, type=float, default=0.45, help=‘IOU threshold for NMS’)
- IoU是两个区域重叠的部分除以两个区域的集合部分得出的结果,通过设定的阈值,与这个IoU计算结果比较。
- 以下是IOU的计算公式

当IOU = 0,IOU = 0.25,IOU = 1时如下图所示:
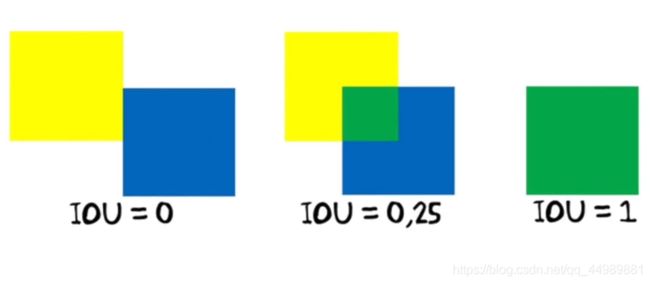
IOU实际上衡量了两个边界框重叠地相对大小,预测框和真实框重叠越大。

-
parser.add_argument(’–device’, default=’’, help=‘cuda device, i.e. 0 or 0,1,2,3 or cpu’)
- 选择使用的设备例如:CPU或CUDA
-
parser.add_argument(’–view-img’, action=‘store_true’, help=‘display results’)
- 在命令行中使用或在PyCharm中调用可以实时看到检测结果。
在Parameters中设置python detect.py --view-img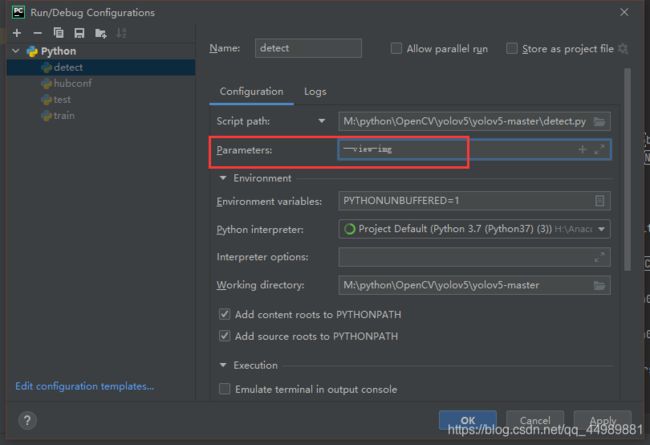
注:调用 --view-img 后会自动变为 view_img=True,在不调用的情况下位view_img=False.

- 在命令行中使用或在PyCharm中调用可以实时看到检测结果。
-
parser.add_argument(’–save-txt’, action=‘store_true’, help=‘save results to *.txt’)
- 将结果保存为txt文件,在PyCharm中调用

以下为运行结果:
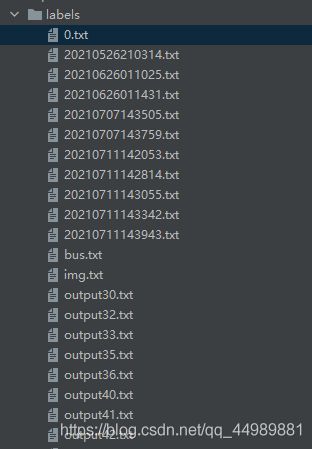

- 将结果保存为txt文件,在PyCharm中调用
-
parser.add_argument(’–classes’, nargs=’+’, type=int, help=‘filter by class: --class 0, or --class 0 2 3’)
- 只保留指定类别
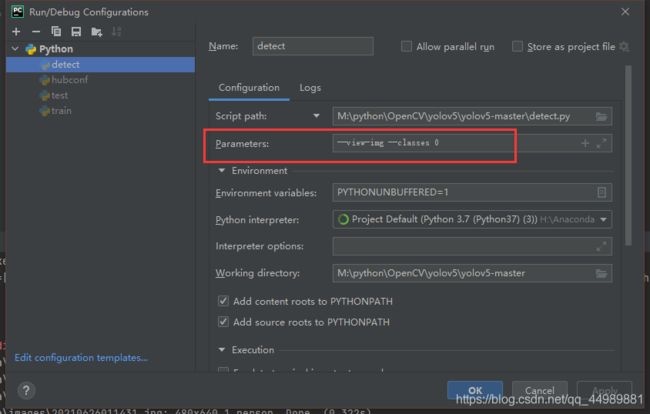
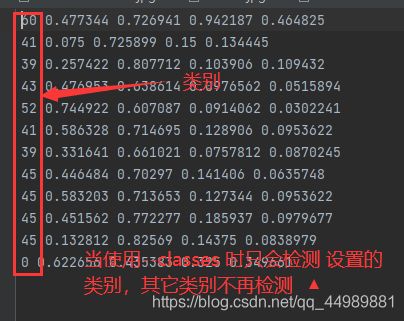
例如:–classes 0 :只检测0这类目标,0在yolov5中给的对应的类别为人

检测结果如下图:
例如:–classes 5 :只检测5这类目标,5在yolov5中给的对应的类别为车
- 只保留指定类别
-
parser.add_argument(’–augment’, action=‘store_true’, help=‘augmented inference’)
- 增强检测结果,可以提高检测结果的概率
-
parser.add_argument(’–project’, default=‘runs/detect’, help=‘save results to project/name’)
- 默认将保存结果,保存在 runs/detect 目录下,通过修改 default 可以自定义保存目录。
-
parser.add_argument(’–name’, default=‘exp’, help=‘save results to project/name’)
- 指定保存结果的文件名,默认文件名为exp,通过修改 default 可以自定义保存的文件名。
-
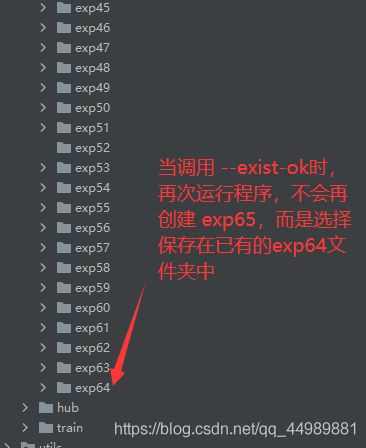
parser.add_argument(’–exist-ok’, action=‘store_true’, help=‘existing project/name ok, do not increment’)
- 当调用 --exist-ok 时,每次启动检测时,检测的结果不会再创建新的文件夹,而是将结果存放在在目前已有文件夹中。

- 当调用 --exist-ok 时,每次启动检测时,检测的结果不会再创建新的文件夹,而是将结果存放在在目前已有文件夹中。