ClickHouse
一、简介
1.1 ClickHouse是一个用于联机分析的列式数据库管理系统。
1.2 特点:
开源的列式数据库管理系统,支持线性扩展,简单方便,高可靠性
1.3 优点
真正的面向列的DBMS(ClickHouse是一个DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置和重新启动服务器)
数据压缩(一些面向列的DBMS(INFINIDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实是提高了性能)
磁盘存储的数据(许多面向列的DBMS(SPA HANA和GooglePowerDrill))只能在内存中工作。但即使在数千台服务器上,内存也太小了。)
多核并行处理(多核多节点并行化大型查询)
在多个服务器上分布式处理(在clickhouse中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分片上并行处理)
SQL支持(ClickHouse sql 跟真正的sql有不一样的函数名称。不过语法基本跟SQL语法兼容,支持 JOIN/FROM/IN 和JOIN子句及标量子查询支持子查询)
向量化引擎(数据不仅按列式存储,而且由矢量-列的部分进行处理,这使得开发者能够实现高CPU性能)
实时数据更新(ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中)
支持近似计算(统计全国到底有多少人?143456754 14.3E)
数据复制和对数据完整性的支持(ClickHouse使用异步多主复制。写入任何可用的复本后,数据将 分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复)
1.4 缺点
没有完整的事务支持,不支持Transaction
缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅用于批删除或修改数据。
聚合结果必须小于一台服务器的内存大小
二、系统架构
column:一列数据
field:列中某一个值
DataType:列的数据类型
Block:属于column、DataType、列名的集合,ClickHouse操作的对象是Block
BlockStream:负责块数据的读入和写出
Format:向客户端展示数据的方式
数据读写IO:有一个缓冲区负责数据的读写
数据表table:多个列的一个集合,读取数据以表为单位进行操作,操作的时候以Block Stream操作Stream
解析器和解释器:对SQL语句进行解析
函数Function:单行函数,组函数
Cluster和Replication
三、数据定义
3.1 数据类型
3.1.1 基本数据类型
基本数据类型Int8、Int16、Int32 和 Int64


浮点数Float32 和 Float64

定点数Decimal32、Decimal64 和Decimal128


布尔UInt8 限制值为0或1
3.1.2 字符串
String、FixedString 和 UUID
String不限制长度,相当于Varchar、Text、Clob 和 Blob 等字符类型
FixedString(N)相当于Char,长度固定,数据长度不够时,添加空字节(null);长度过长返回错误消息
UUID:32位,格式8-4-4-4-12,如果未被赋值,则用0填充
3.1.3 日期时间
Date、DateTime、DateTime64 ,Date: 2020-02-02 精确到天,DateTime: 2020-02-02 20:20:20 精确到秒,DateTime64: 2020-02-02 20:20:20.335 精确到亚秒,可以设置精度
3.1.4 复合类型
数组:array(T)或[],类型必须相同
元组:由多个元素组成,允许不同类型,创建数据:(T1, T2, …),Tuple(T1, T2, …)
枚举类型:ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。
枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应(String:Int8)和(String:Int16)
用(String:Int) Key/Value键值对的形式定义数据,键值对不能同时为空,不允许重复,key允许为空字符串,需要看到对应的值进行转换:

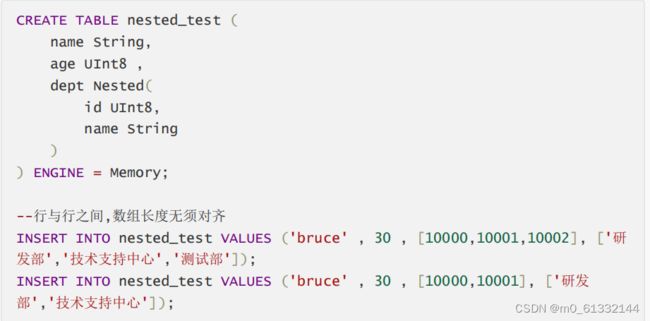
嵌套类型:Nested(Name1 Type1,Name2 Type2,…)
,相当于表中嵌套一张表,插入时相当于一个多维数组的格式,一个字段对应一个数组
3.1.5 其他类型
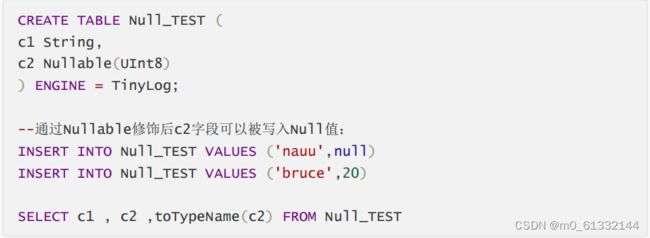
Nullable(TypeName)
只能与基础数据类型搭配使用,表示某个类型的值可以为NULL;Nullable(Int8)表示可以存储Int8类型的值,没有值时存NULL
注意:
不能与复合类型数据一起使用、 不能作为索引字段,尽量避免使用,字段被Nullable修饰后会额外生成[Column].null.bin 文件保存Null值,增加开销
Domain
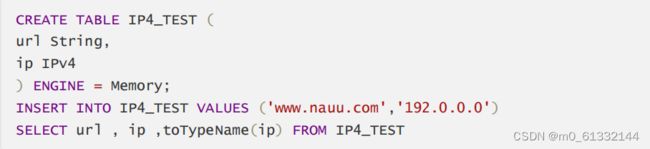
PV4使用 UInt32 存储。如 116.253.40.133
IPV6使用 FixedString(16) 存储。如 2a02:aa08:e000:3100::2
3.2 数据库
数据库起到了命名空间的作用,可以有效规避命名冲突的问题,也为后续的数据隔离提供了支撑。任何一张数据表,都必须归属在某个数据库之下。
操作语法

数据库引擎
Ordinary:默认引擎
在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引擎。
Dictionary:字典引擎
此类数据库会自动为所有数据字典创建它们的数据表,关于数据字典的详细介绍会在第5章展开。
Memory:内存引擎
用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除。
Lazy:日志引擎
此类数据库下只能使用Log系列的表引擎,关于Log表引擎的详细介绍会在第8章展开。
MySql:MySql引擎
此类数据库下会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表
3.3 数据表
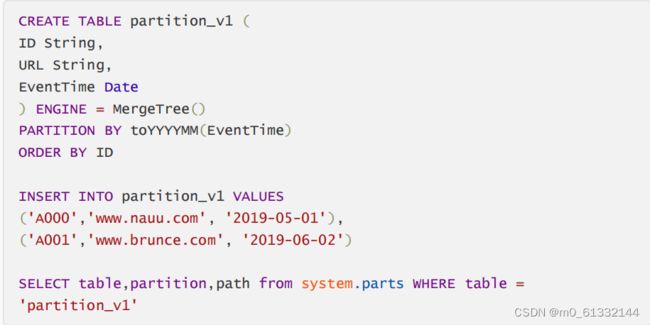
分区表
数据分区(partition)和数据分片(shard)是完全不同的两个概念。
数据分区是针对本地数据而言的,是数据的一种纵向切分。而数据分片是数据的一种横向切分
案例
3.4 视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理。
普通视图
![]()
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义的作用,对查询性能不会有任何增强。
物化视图

物化视图支持表引擎,数据保存形式由它的表引擎决定
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。
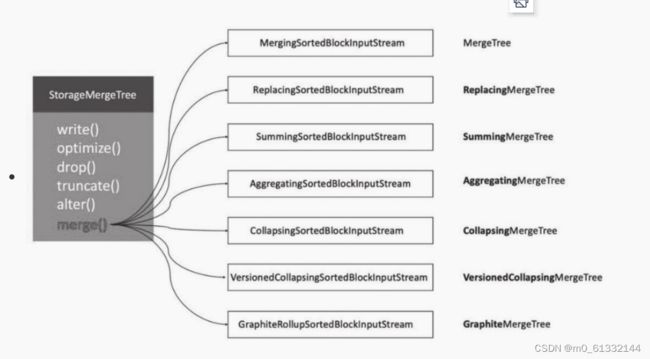
四、MergeTree
表引擎是ClickHouse设计实现中的一大特色
ClickHouse拥有非常庞大的表引擎体系,其共拥有合并树、外部存储、内存、文件、接口和其他6大类20多种表引擎。
合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有所长。
4.1 创建于存储
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。 为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片 段会被合成一个新的片段。 这种数据片段往复合并的特点,也正是合并树名称的由来。
4.1.1 创建方式
语法

配置选项
PARTITION BY [选填]:分区键,用于指定表数据以何种标准进行分区。
分分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。 如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
DRDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。
默认情况下主键(PRIMARY KEY)与排序键相同。 排序键既可以是单个列字段,例如ORDER BY CounterID,也可以通过元组的形式使用 多个列字段,例如ORDERBY(CounterID,EventDate)。当使用多个列字段排序时,以ORDERBY(CounterID,EventDate)为例,在单个数据片段内,数据首先会以CounterID排序,相同CounterID的数据再按EventDate排序。
PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主键字段生成一级索引,用于加速表查询。
默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主 键,无须刻意通过PRIMARY KEY声明。所以在一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数据(ReplacingMergeTree可以去
SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标准进行采样。如果使用了此配置项,那么在主键的配置中也需要声明同样的表达式,抽样表达式需要配合SAMPLE子查询使用,这项功能对于选取抽样数据十分有用
SETTINGS:
Index_granularity [选填]:index_granularity对于MergeTree而言是一项非常重要的参数,它表示索引的粒度,默认值为8192。 MergeTree的索引在默认情况下,每间隔8192行数据才生成一条索引
index_granularity_bytes [选填] 在19.11版本之前,ClickHouse只支持固定大小的索引间隔,由index_granularity控制,默认为8192。 在新版本中,它增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。 而数据的体量大小,正是由index_granularity_bytes参数控制的,默认为 10M(10×1024×1024),设置为0表示不启动自适应功能。
enable_mixed_granularity_parts [选填] 设置是否开启自适应索引间隔的功能,默认开启。
merge_with_ttl_timeout [选填] 从19.6版本开始,MergeTree提供了数据TTL的功能
storage_policy [选填]:从19.15版本开始,MergeTree提供了多路径的存储策略
4.1.2 存储格式
MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上

一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件
partition:分区目录,余下各类数据文件(primary.idx、[Column].mrk、[Column].bin等) 都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分区的数据,永远不会被合并在一起。
checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息
count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数,
primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDERBY或者PRIMARY KEY)。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
[Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字 段名称命名(例如CounterID.bin、EventDate.bin等)。
[Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与.bin文件一一对应,所以MergeTree通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系。即首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据。由于.mrk标记文件与.bin文件一一对应,所以MergeTree中的每个列字段都会拥有与其对应的.mrk标记文件(例如CounterID.mrk、EventDate.mrk等)。
[Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。它的工作原理和作用与.mrk标记文件相同。
Partition.dat与minmax_[Column].idx:如果使用了分区键,例如PARTITION BY。 EventTime,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。
skp_idx[Column].idx与skp_idx[Column].mrk:如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。二级索引在ClickHouse中又 称跳数索引,目前拥有minmax、set、ngrambf_v1和tokenbf_v1四种类型。这些索引的最终 目标与一级稀疏索引相同,都是为了进一步减少所需扫描的数据范围,以加速整个查询过程。
4.2 数据分区
4.2.1 数据分区规则
MergeTree数据分区的规则由分区ID决定,而具体到每个数据分区所对应的ID,则是由分区键的取值决定的。
分区键支持使用任何一个或一组字段表达式声明,其业务语义可以是年、月、日或者组织单位等任何一种规则。
针对取值数据类型的不同,分区ID的生成逻辑目前拥有四种规则:
不指定定分区键:如果不使用分区键,即不使用PARTITION BY声明任何分区表达式,则分区ID默认取名为all,所有的数据都会被写入这个all分区。
使用整型:
如果分区键取值属于整型(兼容UInt64,包括有符号整型和无符号整型),且无法转换为日期类型YYYYMMDD格式,则直接按照该整型的字符形式输出,作为分区ID的取值。
使用日期类型:
如果分区键取值属于日期类型,或者是能够转换为YYYYMMDD格式的整型,则使用按照YYYYMMDD进行格式化后的字符形式输出,并作为分区ID的取值。
使用其他类型:
如果分区键取值既不属于整型,也不属于日期类型,例如String、Float等,则通过128位Hash算法取其Hash值作为分区ID的取值。
4.2.2 分区目录命名
一个完整分区目录的命名公式

201905表示分区目录的ID;
1_1分别表示最小的数据块编号与最大的数据块编号;
而最后的_0则表示目前合并的层级。
PartitionID_MinBlockNum_MaxBlockNum_Level
PartitionID:分区ID
MinBlockNum和MaxBlockNum:顾名思义,最小数据块编号与最大数据块编号。
Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高 表示年龄越大。
4.2.3 分区目录合并
MergeTree的分区目录和传统意义上其他数据库有所不同。
首先,MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。
也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。
其次,它的分区目录在建立之后也并不是一成不变的。
在其他某些数据库的设计中,追加数据后目录自身不会发生变化,只是在相同分区目录中追加新的数据文件。
而MergeTree完全不同,伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生 成一批新的分区目录。
即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。 也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize查询语句) ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。 已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认 8分钟)。
新目录名称的合并方式遵循规则:
MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。 MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。 Level:取同一分区内最大Level值并加1。
名称变化过程
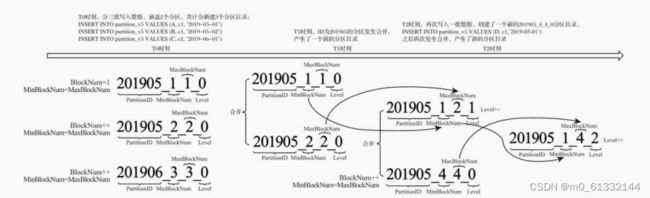
分区目录创建、合并、删除的过程

4.3 一级索引
MergeTree的主键使用PRIMARY KEY定义,待主键定义之后,MergeTree会依据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARYKEY排序。
4.3.1 稀疏索引
Primary.idx文件内的一级索引采用稀疏索引实现。
稠密索引中每一行索引标记都会对应到一行具体的数据记录。
稀疏索引中每一行索引标记对应的是一段数据,而不是一行。
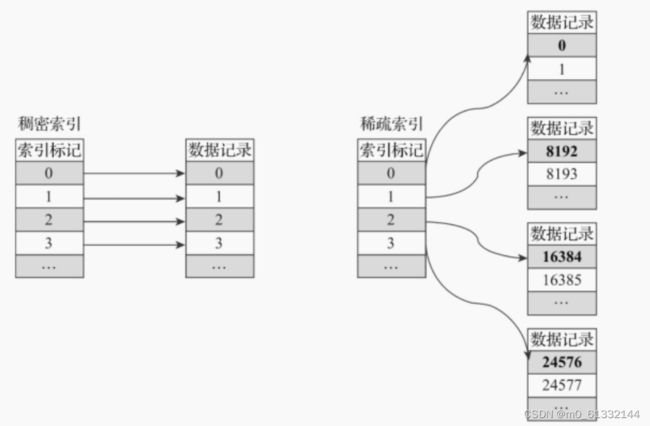
稀疏索引的优势是显而易见的,它仅需使用少量的索引标记就能够记录大量数据的区间位置信息, 且数据量越大优势越为明显。
以默认的索引粒度(8192)为例,MergeTree只需要12208行索引标记就能为1亿行数据记录 提供索引。
由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快。
4.3.2 索引粒度
索引粒度就如同标尺一般,会丈量整个数据的长度,并依照刻度对数据进行标注,最终将数据标记成多个间隔的小段
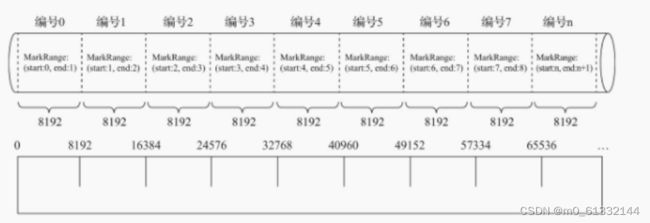
4.3.3 锁引规则
由于是稀疏索引,所以MergeTree需要间隔index_granularity行数据才会生成一条索引记录,其索引值会依据声明的主键字段获取。
单主键
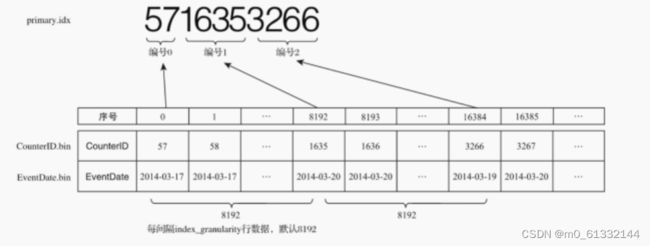
第0(81920)行CounterID取值57,第8192(81921)行CounterID取值1635,而第16384(8192*2)行CounterID取值3266 最终索引数据将会是5716353266。
多主键

4.3.4 索引查询过程
MarkRange
MarkRange在ClickHouse中是用于定义标记区间的对象。 MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成了多个小的间隔数 据段,一个具体的数据段即是一个MarkRange。 MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。通过与start及end对应的索引编号的取值,即能够得到它所对应的数值区间。而数值区间表示了此MarkRange包含的数据范围。
案例分析

主键ID为String类型,ID的取值从A000开始,后面依次为A001、A002……直至A189为止。 MergeTree的索引粒度index_granularity=3 MergeTree会将此数据片段划分成189/3=63个小的MarkRange索引查询其实就是两个数值区间的交集判断。 一个区间是由基于主键的查询条件转换而来的条件区间; 一个区间是刚才所讲述的与MarkRange对应的数值区间。
查询步骤
递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000,+inf)开始: 如果不存在交集,则直接通过剪枝算法优化此整段MarkRange。 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区 间,并重复此规则,继续做递归交集判断。如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
4.4 二级索引
二级索引又称跳数索引,由数据的聚合信息构建而成。
根据索引类型的不同,其聚合信息的内容也不同。跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
跳数索引在默认情况下是关闭的,需要设置allow_experimental_data_skipping_indices
SET allow_experimental_data_skipping_indices = 1
跳数索引需要在CREATE语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
4.4.1 粒度
granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
首先,按照index_granularity粒度间隔将数据划分成n段,总共有[0,n-1]个区间 (n=total_rows/index_granularity,向上取整) 接着,根据索引定义时声明的表达式,从0区间开始,依次按index_granularity粒度从数据中获取聚合信息,每次向前移动1步,聚合信息逐步累加。 最后,当移动granularity次区间时,则汇总并生成一行跳数索引数据。
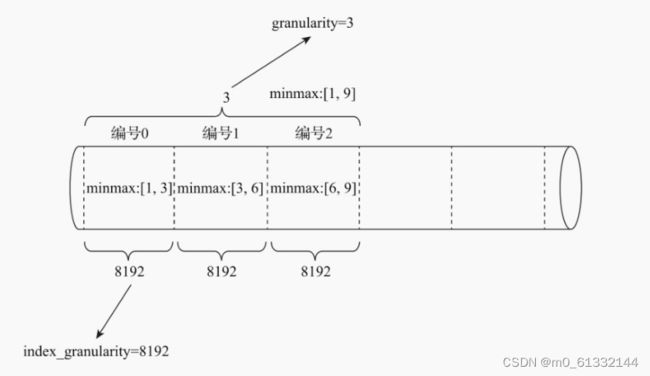
4.4.2 分类
MergeTree共支持4种跳数索引,分别是minmax、set、ngrambf_v1和tokenbf_v1。一张数据表支持同时声明多个跳数索引。
minmax:
minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索引,能够快速跳过无用的数据区间
set:
set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。
ngrambf_v1:
ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。
ngrambf_v1只能够提升in、notIn、like、equals和notEquals查询的性能
其完整形式为
ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_functions,random_seed)。
这些参数是一个布隆过滤器的标准输入,如果你接触过布隆过滤器,应该会对此十分熟 悉。它们具体的含义如下:
n:token长度,依据n的长度将数据切割为token短语。
size_of_bloom_filter_in_bytes:布隆过滤器的大小。
number_of_hash_functions:布隆过滤器中使用Hash函数的个数。
random_seed:Hash函数的随机种子。
tokenbf_v1:
tokenbf_v1索引是ngrambf_v1的变种,同样也是一种布隆过滤器索引。tokenbf_v1除了短语token的处理方法外,其他与ngrambf_v1是完全一样的。 tokenbf_v1会自动按照非字符的、数字的字符串分割token
4.5 数据存储
4.5.1 列式存储
在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。也正是这些.bin文件,最终承载着数据的物理存储。
数据文件以分区目录的形式被组织存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据
优势:一是可以更好地进行数据压缩。二是能够最小化数据扫描的范围
存储方式:
首先,数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用LZ4算法;
其次,数据会事先依照ORDER BY的声明排序;
最后,数据是以压缩数据块的形式被组织并写入.bin文件中的
4.5.2 数据压缩
一个压缩数据块由头信息和压缩数据两部分组成。
头信息固定使用9位字节表示,具体由1个UInt8(1字节)和2个UInt32(4字节)整数组成
分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小
bin压缩文件是由多个压缩数据块组成的,而每个压缩数据块的头信息则是基于CompressionMethod_CompressedSize_UncompressedSize公式生成的

每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB~1MB,其上下限分别由min_compress_block_size(默认65536)与max_compress_block_size(默认1048576)参数指定。
而一个压缩数据块最终的大小,则和一个间隔(index_granularity)内数据的实际大小相关
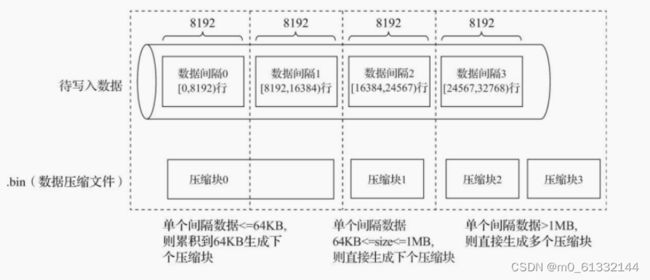
数据写入过程
MergeTree在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取8192行),按批次获取数据并进行处理
单个批次数据size<64KB :如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块。
单个批次数据64KB<=size<=1MB :如果单个批次数据大小恰好在64KB与1MB之间,则直接 生成下一个压缩数据块。
单个批次数据size>1MB :如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。
优势:
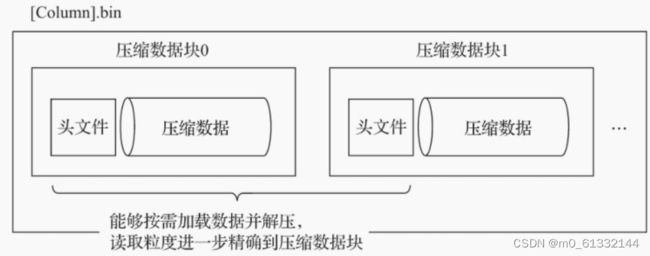
其一,虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率,但数据的压缩和解压动作,其本身也会带来额外的性能损耗。所以需要控制被压缩数据的大小,以求在性能损耗和压缩率之间寻求一种平衡。
其二,在具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围。
4.6 数据标记
4.6.1 生成规则
数据标记作为衔接一级索引和数据的桥梁,其像极了做过标记小抄的书签,而且书本中每个一级章节都拥有各自的书签。
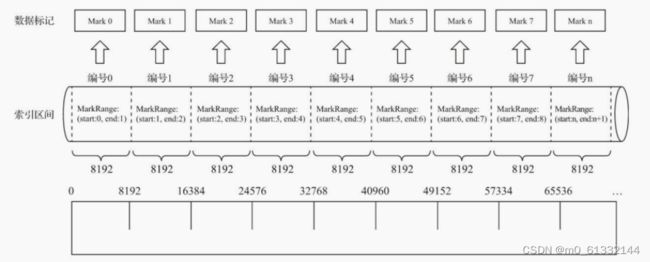
数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔。
为了能够与数据衔接,数据标记文件也与.bin文件一一对应。
每一列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。
他们分别表示在此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;
以及将该数据压缩块解压后,其未压缩数据的起始偏移量。
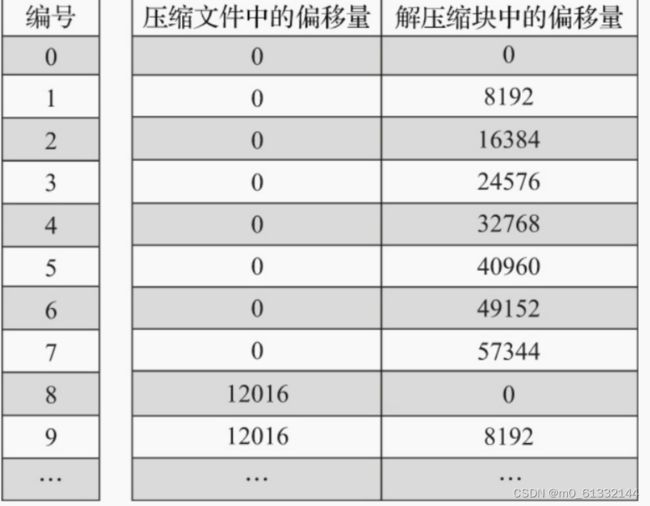
每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息。标记数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取 用速度。
4.6.2 工作方式
MergeTree在读取数据时,必须通过标记数据的位置信息才能够找到所需要的数据。整个查找过程大致可以分为读取压缩数据块和读取数据两个步骤
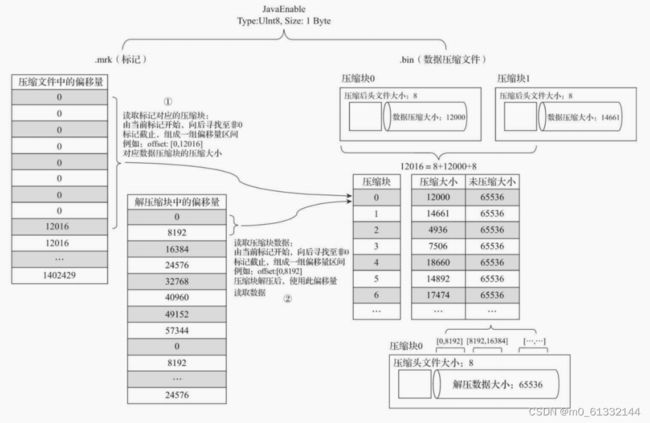
数据理解
1B*8192=8192B,64KB=65536B,65536/8192=8,头信息固定由9个字节组成,压缩后大小为8个字节,12016=8+12000+8
读取压缩数据块:
在查询某一列数据时,MergeTree无须一次性加载整个.bin文件,而是可以根据需要,只加载特定的压缩数据块。而这项特性需要借助标记文件中所保存的压缩文件中的偏移量。
读取数据:
在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要,以index_granularity的粒度加载特定的一小段。为了实现这项特性,需要借助标记文件中保 存的解压数据块中的偏移量。
4.7 数据标记与数据压缩
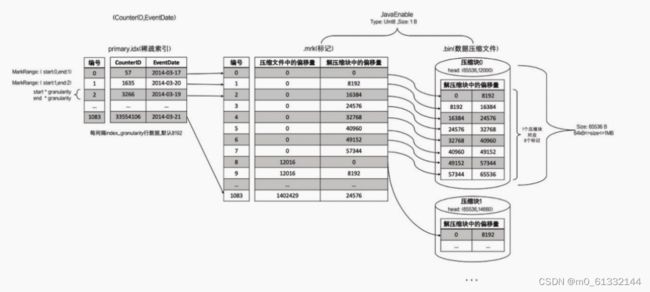
由于压缩数据块的划分,与一个间隔(index_granularity)内的数据大小相关,每个压缩数据块的体积都被严格控制在64KB~1MB。 而一个间隔(index_granularity)的数据,又只会产生一行数据标记。那么根据一个间隔内数据的实际字节大小,数据标记和压缩数据块之间会产生三种不同的对应关系。
4.7.1 多对一
多个数据标记对应一个压缩数据块
当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时
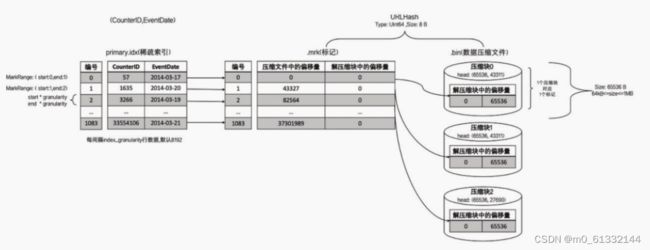
4.7.2 一对一
一个数据标记对应一个压缩数据块
当一个间隔(index_granularity)内的数据未压缩大小size大于等于64KB且小于等于1MB时
4.7.3 一对多
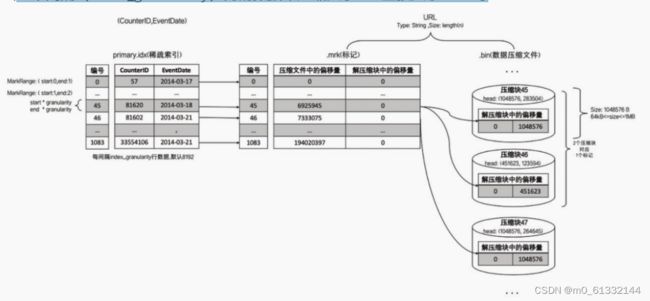
一个数据标记对应多个压缩数据块
当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时
4.8 数据读写流程
4.8.1 写入数据
数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后续的某一时刻,属于相同分区的目录会依照规则合并到一起;接着,按照index_granularity索引粒度,会分别生成primary.idx一级索引、每一个列字段的.mrk数据标记和.bin压缩数据文件。
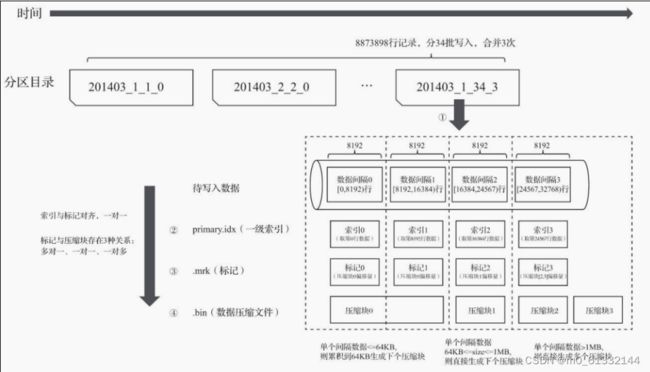
从分区目录201403_1_34_3能够得知,该分区数据共分34批写入,期间发生过3次合并。在数据写入的过程中,依据index_granularity的粒度,依次为每个区间的数据生成索引、标记和 压缩数据块。其中,索引和标记区间是对齐的,而标记与压缩块则根据区间数据大小的不同,会生成多对一、一对一和一对多三种关系。
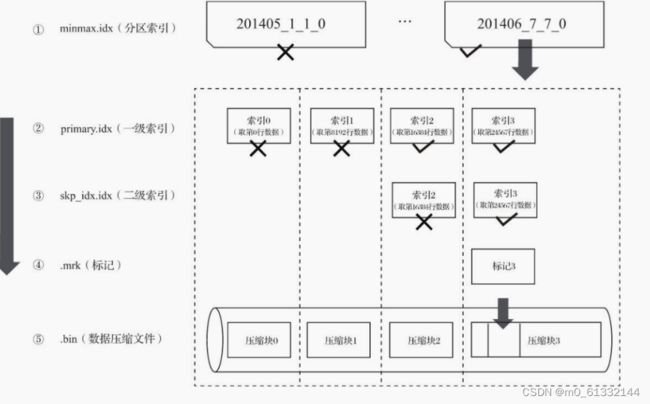
4.8.2 查询数据
数据查询的本质,可以看作一个不断减小数据范围的过程。在最理想的情况下,MergeTree首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将 需要解压与计算的数据范围缩至最小。
五、MergeTree Family
5.1 MergeTree
5.1.1 数据TTL
TTL即Time To Live,顾名思义,它表示数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。
当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据; 如果是表级别的TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,则会以先到期的那个为主。
设置TTL
INTERVAL完整的操作包括SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER和YEAR。
列级别设置TTL

ClickHouse没有提供取消列级别TTL的方法。
表级别设置TTL

TTL运行机制
如果一张MergeTree表被设置了TTL表达式,那么在写入数据时,会以数据分区为单位,在每个分区目录内生成一个名为ttl.txt的文件。
ttl.txt文件中通过一串JSON配置保存了TTL的相关信息
{"columns":[{"name":"code","min":1557478860,"max":1557651660}],"table":{"min":1557565200,"max":1557738000}},columns用于保存列级别TTL信息; table用于保存表级别TTL信息; min和max则保存了当前数据分区内,TTL指定日期字段的最小值、最大值分别与 INTERVAL表达式计算后的时间戳。
5.1.2 多路径存储策略
19.15版本之前,MergeTree只支持单路径存储,所有的数据都会被写入config.xml配置中path指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。
19.15版本开始,MergeTree实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
存储策略
默认策略:
MergeTree原本的存储策略,无须任何配置,所有分区会自动保存到config.xml配置中path指定的路径下
JBOD策略:
这种策略适合服务器挂载了多块磁盘,但没有做RAID的场景。JBOD的全称是Just a Bunch of Disks,它是一种轮询策略,每执行一次INSERT或者MERGE,所产生的新分区会轮询写入各个磁盘。
HOT/COLD策略:
这种策略适合服务器挂载了不同类型磁盘的场景。
将存储磁盘分为HOT与COLD两类区域。
HOT区域使用SSD这类高性能存储媒介,注重存取性能;
COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。
数据在写入MergeTree之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自行移动到COLD区域
5.2 ReplacingMerageTree
MergeTree拥有主键,但是它的主键却没有唯一键的约束。这意味着即便多行数据的主键相同,它们还是能够被正常写入。
ReplacingMergeTree就是在这种背景下为了数据去重而设计的,它能够在合并分区时删除重复的 数据。
ReplacingMergeTree是以分区为单位删除重复数据的。
只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。如果要求主键完全不重复,那么这张表就不能分区
操作方式
ENGINE = ReplacingMergeTree(ver)
ver是选填参数,会指定一个UInt*、Date或者DateTime类型的字段作为版本号。这个参数决定了数据去重时所使用的算法。


5.3 SummingMerageTree
终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY条件明确,且不会随意改变
原始方案:通过GROUP BY聚合查询,并利用SUM聚合函数汇总结果
存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据。
存在额外的查询开销:终端用户只关心汇总结果,虽然MergeTree性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗。
SummingMergeTree就是为了应对这类查询场景而生的。
它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行
这样既减少了数据行,又降低了后续汇总查询的开销。
操作方式:


5.4 AggregatingMerageTree
数据立方体
它通过以空间换时间的方法提升查询性能,将需要聚合的数据,预先计算出来,并将结果保起来
在后续进行聚合查询的时候,直接使用结果数据。
操作方式
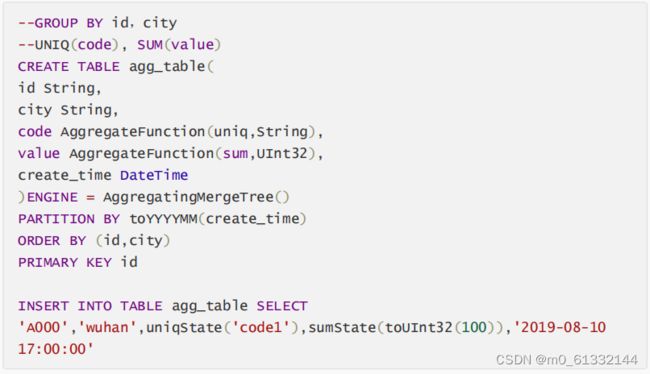
AggregatingMergeTree更为常见的应用方式是结合物化视图使用,将它作为物化视图的表引擎。 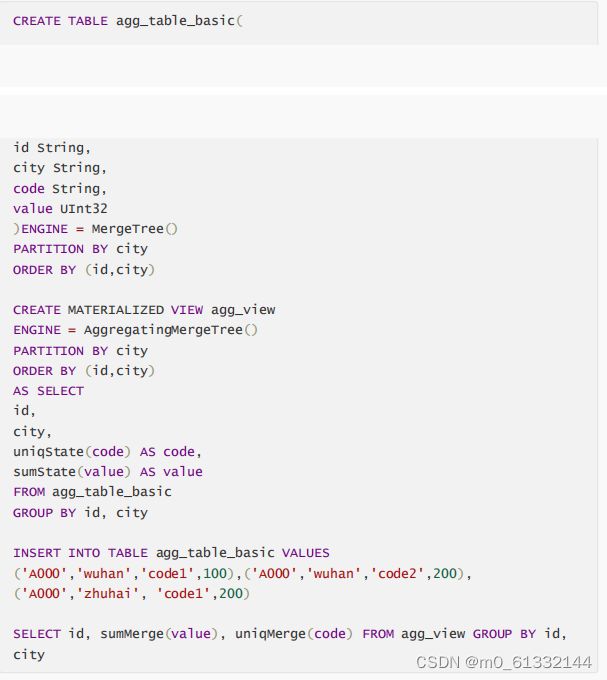
5.5 CollapsingMerageTree
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。
如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。 当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删 除。这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般。
操作方式:
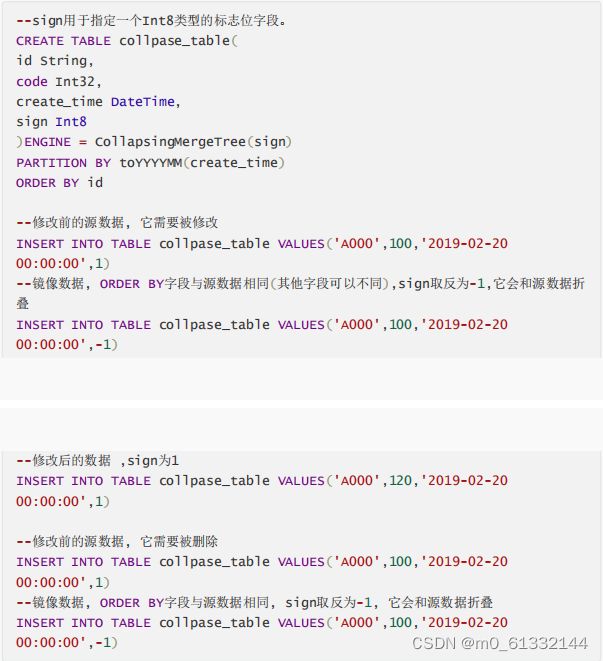
折叠规则
如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。 如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后 一行sign=1的数据。 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。 其余情况,ClickHouse会打印警告日志,但不会报错,在这种情形下,查询结果不可预知。
特点:折叠数据并不是实时触发的,和所有其他的MergeTree变种表引擎一样,这项特性也只有在分区合并的时候才会体现。
所以在分区合并之前,用户还是会看到旧的数据。解决这个问题的方式有两种。
在查询数据之前,使用optimize TABLE table_name FINAL命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
需要改变我们的查询方式 
只有相同分区内的数据才有可能被折叠。
CollapsingMergeTree对于写入数据的顺序有着严格要求。
先写入sign=1,再写入sign=-1,则能够正常折叠,先写入sign=-1,再写入sign=1,则不能够折叠
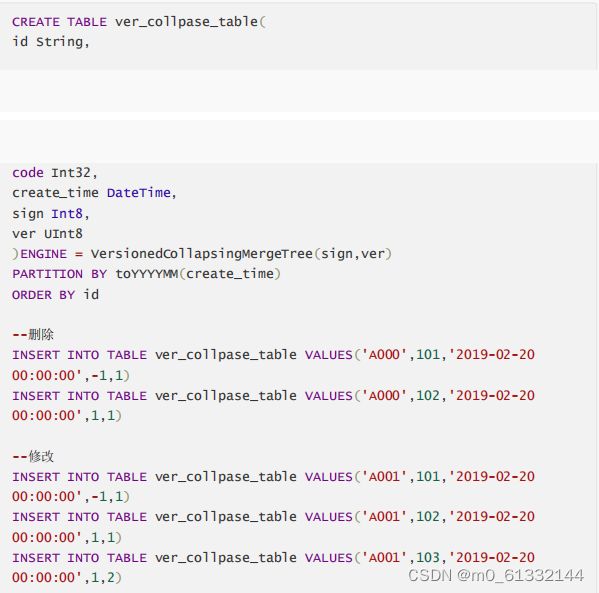
5.6 VersionedCollapsingMerageTree
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
操作方式:
5.7 MergeTree关系梳理
MergeTree表引擎向下派生出6个变种表引擎