深度强化学习-策略梯度算法(Reinforce)代码
引言
本文主要采用Pytorch来实现策略梯度算法,算法的原理可以参考我的这篇博文:深度强化学习-策略梯度算法推导,里面对该算法进行了详细推导。如果想深入理解策略梯度算法公式,可以参考我的另一篇博文:深度强化学习-策略梯度算法深入理解,里面将其与手写数字识别问题进行了类比,深入剖析了策略梯度算法公式。代码已经上传到我的Github上,喜欢的话可以点个小星星噢。
代码:https://github.com/indigoLovee/Reinforce_pytorch
1 Reinforce算法
强化学习的目标在于最大化累积奖励。采用含参函数![]() 近似最优策略,沿着策略梯度的方向,更新策略参数,可以实现累积奖励最大化。策略梯度定理如下:
近似最优策略,沿着策略梯度的方向,更新策略参数,可以实现累积奖励最大化。策略梯度定理如下:
策略梯度定理:
![\triangledown E_{\pi _{\theta }}\left [ G_{0} \right ]=E\left [ \sum_{t=0}^{+\infty }\gamma ^{t}G_{t}\triangledown ln\pi_{\theta } (A_{t}\mid S_{t}) \right ]](http://img.e-com-net.com/image/info8/c9ab9f0f0e3a40b3a0a117cf989e65ae.gif)
Reinforce算法的伪代码如下:

2 Reinforce算法实现
Reinforce算法代码如下(Reinforce_discrete.py脚本):
import torch as T
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
device = T.device("cuda:0" if T.cuda.is_available() else "cpu")
class PolicyNetwork(nn.Module):
def __init__(self, alpha, state_dim, action_dim, fc1_dim, fc2_dim):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, fc1_dim)
self.fc2 = nn.Linear(fc1_dim, fc2_dim)
self.prob = nn.Linear(fc2_dim, action_dim)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
self.to(device)
def forward(self, state):
x = T.relu(self.fc1(state))
x = T.relu(self.fc2(x))
prob = T.softmax(self.prob(x), dim=-1)
return prob
def save_checkpoint(self, checkpoint_file):
T.save(self.state_dict(), checkpoint_file, _use_new_zipfile_serialization=False)
def load_checkpoint(self, checkpoint_file):
self.load_state_dict(T.load(checkpoint_file))
class Reinforce:
def __init__(self, alpha, state_dim, action_dim, fc1_dim, fc2_dim, ckpt_dir, gamma=0.99):
self.gamma = gamma
self.checkpoint_dir = ckpt_dir
self.reward_memory = []
self.log_prob_memory = []
self.policy = PolicyNetwork(alpha=alpha, state_dim=state_dim, action_dim=action_dim,
fc1_dim=fc1_dim, fc2_dim=fc2_dim)
def choose_action(self, observation):
state = T.tensor([observation], dtype=T.float).to(device)
probabilities = self.policy.forward(state)
dist = Categorical(probabilities)
action = dist.sample()
log_prob = dist.log_prob(action)
self.log_prob_memory.append(log_prob)
return action.item()
def store_reward(self, reward):
self.reward_memory.append(reward)
def learn(self):
G_list = []
G_t = 0
for item in self.reward_memory[::-1]:
G_t = self.gamma * G_t + item
G_list.append(G_t)
G_list.reverse()
G_tensor = T.tensor(G_list, dtype=T.float).to(device)
loss = 0
for g, log_prob in zip(G_tensor, self.log_prob_memory):
loss += -g * log_prob
self.policy.optimizer.zero_grad()
loss.backward()
self.policy.optimizer.step()
self.reward_memory.clear()
self.log_prob_memory.clear()
def save_models(self, episode):
self.policy.save_checkpoint(self.checkpoint_dir + 'Reinforce_policy_{}.pth'.format(episode))
print('Saved the policy network successfully!')
def load_models(self, episode):
self.policy.load_checkpoint(self.checkpoint_dir + 'Reinforce_policy_{}.pth'.format(episode))
print('Loaded the policy network successfully!')
算法仿真环境为gym库中的LunarLander-v2,因此需要先配置好gym库。进入Anaconda3中对应的Python环境中,执行下面的指令
pip install gym但是,这样安装的gym库只包括少量的内置环境,如算法环境、简单文字游戏和经典控制环境,无法使用LunarLander-v2。因此还需要安装一些其他依赖项,具体可以参考我的这篇博文:AttributeError: module ‘gym.envs.box2d‘ has no attribute ‘LunarLander‘ 解决办法。
让智能体在环境中训练3000轮,训练代码如下(train.py脚本):
import gym
import numpy as np
import argparse
from utils import plot_learning_curve
from Reinforce_discrete import Reinforce
parser = argparse.ArgumentParser()
parser.add_argument('--max_episodes', type=int, default=3000)
parser.add_argument('--reward_path', type=str, default='./output_images/reward.png')
parser.add_argument('--ckpt_dir', type=str, default='./checkpoints/Reinforce_discrete/')
args = parser.parse_args()
def main():
env = gym.make('LunarLander-v2')
agent = Reinforce(alpha=0.0005, state_dim=env.observation_space.shape[0],
action_dim=env.action_space.n, fc1_dim=128, fc2_dim=128,
ckpt_dir=args.ckpt_dir, gamma=0.99)
total_rewards, avg_rewards = [], []
for episode in range(args.max_episodes):
total_reward = 0
done = False
observation = env.reset()
while not done:
action = agent.choose_action(observation)
observation_, reward, done, info = env.step(action)
agent.store_reward(reward)
total_reward += reward
observation = observation_
agent.learn()
total_rewards.append(total_reward)
avg_reward = np.mean(total_rewards[-100:])
avg_rewards.append(avg_reward)
print('EP:{} reward:{} avg_reward:{}'.format(episode + 1, total_reward, avg_reward))
if (episode + 1) % 300 == 0:
agent.save_models(episode + 1)
episodes = [i for i in range(args.max_episodes)]
plot_learning_curve(episodes, avg_rewards, 'Reward', 'reward', args.reward_path)
if __name__ == '__main__':
main()
训练时还会用到画图函数和创建文件夹函数,它们均放置在utils.py脚本中,具体代码如下:
import os
import matplotlib.pyplot as plt
import numpy as np
def plot_learning_curve(episodes, records, title, ylabel, figure_file):
plt.figure()
plt.plot(episodes, records, linestyle='-', color='r')
plt.title(title)
plt.xlabel('episode')
plt.ylabel(ylabel)
plt.show()
plt.savefig(figure_file)
def create_directory(path: str, sub_dirs: list):
for sub_dir in sub_dirs:
if os.path.exists(path + sub_dir):
print(path + sub_dir + ' is already exist!')
else:
os.makedirs(path + sub_dir, exist_ok=True)
print(path + sub_dir + ' create successfully!')
def scale_action(action, high, low):
action = np.clip(action, -1, 1)
weight = (high - low) / 2
bias = (high + low) / 2
action_ = action * weight + bias
return action_3 仿真结果
LunarLander-v2环境中动作空间为离散形式,仿真结果如下图所示。
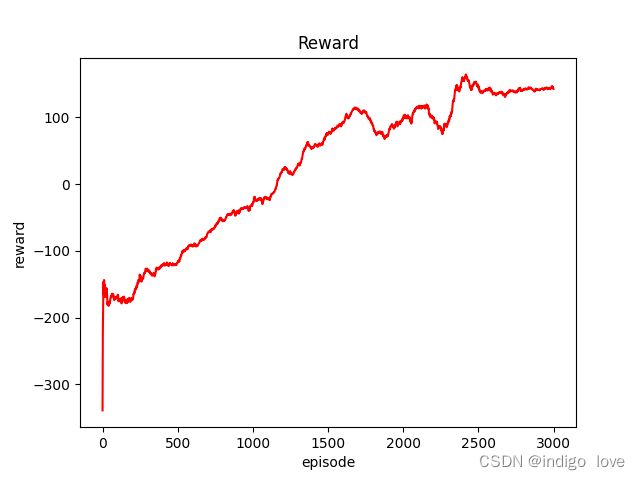
可以看出累积奖励在不断上升,说明通过策略梯度算法,可以不断改善智能体的策略。
其实,策略梯度算法主要针对的是连续问题。因此,我们在连续动作空间的环境LunarLanderContinuous-v2中对Reinforce算法进行了测试,但是测试效果不太理想,这部分的代码也已经放在我的Github里面,这里就不贴在博文中了。后面我们会介绍策略梯度算法的改善版本,敬请期待把!