Instruction Tuning|谷歌Quoc V.Le团队提出精调新范式!香过Prompt!
卷友们好,我是rumor。
前两天在Arxiv刷到个比较牛的论文题目:
Finetuned Language Models Are Zero-Shot Learners
是不是跟GPT-3有些像:
Language Models are Few-Shot Learners
以为是蹭热度,就没点进去,结果今天点进去仔细一看,好家伙居然出自Quoc V.Le团队:

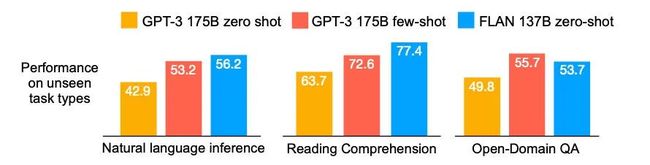
于是我摆正心态,仔细看了之后还是发现不少东西。这个文章提出了一个Instruction tuning的概念,用这种方式精调大模型之后可以显著提升大模型在NLI和阅读理解的表现:
更重要的是!Open AI居然不谋而合,虽然没发论文,但也在官网放出了类似模型的Beta版本:

从官网给的几个例子,可以看到Instruct版本的模型相比于GPT-3可以更好的完成问答、分类和生成任务,是更符合实际应用需求的模型。
而看到这里想必大家和我一样疑惑,这个Instruction怎么和前阵子的网红Prompt有些像???感觉傻傻分不清楚???
不急,我们这就来好好看看。
什么是Instruction Tuning
让我们先抛开脑子里的一切概念,把自己当成一个模型。我给你两个任务:
带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!
判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差
你觉得哪个任务简单?请把序号打在公屏上。做判别是不是比做生成要容易?Prompt就是第一种模式,Instruction就是第二种。
Instruction Tuning和Prompt的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,它的模版是这样的:

而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action。比如NLI/分类任务:
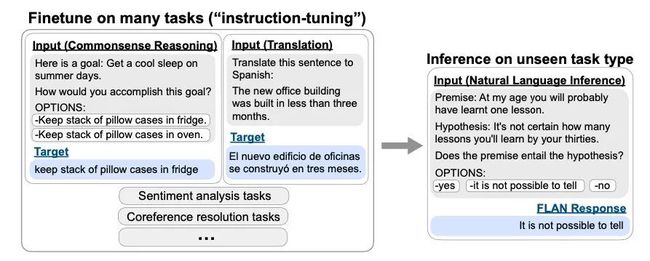
还有一个不同点,就是Prompt在没精调的模型上也能有一定效果,而Instruction Tuning则必须对模型精调,让模型知道这种指令模式。
但是,Prompt也有精调呀,经过Prompt tuning之后,模型也就学习到了这个Prompt模式,精调之后跟Instruction Tuning有啥区别呢?
这就是Instruction Tuning巧妙的地方了,(我看到的)Prompt tuning都是针对一个任务的,比如做个情感分析任务的prompt tuning,精调完的模型只能用于情感分析任务,而经过Instruction Tuning多任务精调后,可以用于其他任务的zero-shot!!!
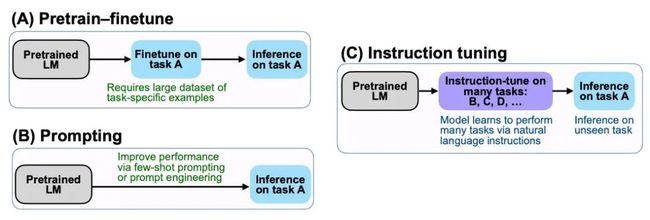
我知道上面的解释有些绕,请深深体会一下。
怎么做Instruction Tuning
理解了Instruction Tuning的概念之后,再看实验方法就清晰多了。作者把62个NLP任务分成了12个类,训练时在11个上面精调,在1个上面测试zero-shot效果,这样可以保证模型真的没见过那类任务,看模型是不是真的能理解「指令」:
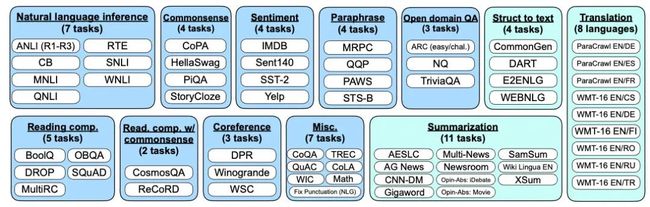
像Prompt一样,作者也会为每个任务设计10个指令模版,测试时看平均和最好的表现:
效果
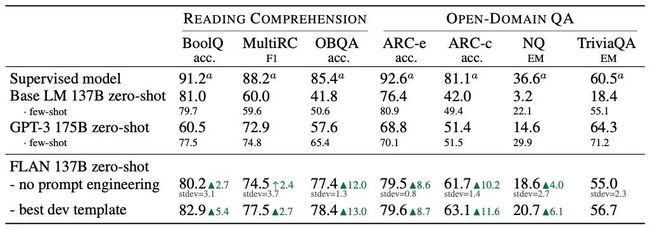
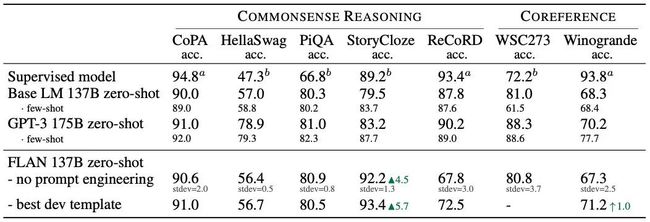
通过上述多任务指令精调的FLAN模型在大部分情况可以超过GPT-3的zero-shot(绿色箭头)甚至是few-shot(绿色三角)表现,其中有监督模型a=T5 11B,b=BERT-large:


同时也可以和Prompt相结合,会有更大提升:
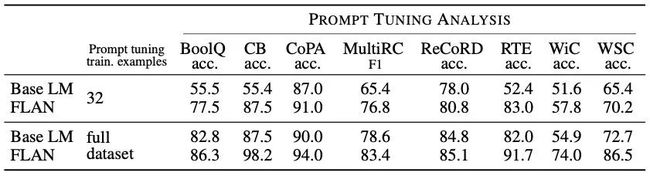
但遗憾的是,这个方法只在大模型上有效果,小模型上甚至会降低表现。作者认为是小模型容量有限,只学一个任务的知识就很不容易了:

总结
当时看这篇文章的第一反应,是觉得这个idea难得没有很多人做过吗?Prompt、Instruction,从GPT-2开始就有了吧。然而仔细想,却发现之前研究主要是针对单任务的少样本情况,并没有研究这种多任务的Prompt、指令泛化。
这个研究的应用潜力显然更大,而且谷歌和OpenAI居然不谋而合都在做,同时在应用时使用者还可以对任务进行一定的精调:

再往深想,Instruction和Prompt一样存在手工设计模版的问题,怎样把模版参数化、或者自动挖掘大量模版从而提升指令精调的效果,也是一个方向。
请老板多给我几块儿GPU吧。


大家好我是rumor
一个热爱技术,有一点点幽默的妹子
欢迎关注我
带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「感觉我Paper要发出来了」