文章目录
- 随机森林
- RandomForestClassifier
-
- 重点参数
-
- n_estimators 森林中的数量,一般越大越好,但要与所需性能平衡
- 对比n_estimators对模型效果的影响
- ***泛化误差*** 衡量模型在未知数据上的准确率
-
- 用sklearn自带的乳腺癌数据做一个调参案例(参考菜菜的教程)
-
随机森林
RandomForestClassifier
- 随机森林是非常具有代表性的bagging集成算法,它的所有基评估器都是决策树。分类树组成的森林就叫做随机森林分类器,回归树集成的森林就叫做随机森林回归器。这里使用的是随机森林分类器
重点参数
n_estimators 森林中的数量,一般越大越好,但要与所需性能平衡
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
%matplotlib inline
wine = load_wine()
from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(xtrain,ytrain)
rfc = rfc.fit(xtrain,ytrain)
score_c = clf.score(xtest,ytest)
score_r = rfc.score(xtest,ytest)
print(f'决策树的评分{score_c}',f'随机森林的评分{score_c}')
决策树的评分0.9259259259259259 随机森林的评分0.9259259259259259
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
clf =DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label="RandomForest")
plt.plot(range(1,11),clf_s,label="DecisionTree")
plt.legend()
plt.show()

对比n_estimators对模型效果的影响
superpa =[]
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
plt.figure()
plt.plot(range(1,201),superpa)
plt.show()
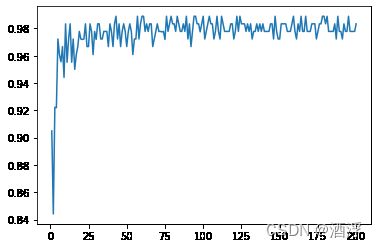
泛化误差 衡量模型在未知数据上的准确率
主观调参大法(按影响大小排序)
- n_estimators
- max_depth
- min_samples_leaf
- min_samples_split
- max_features
用sklearn自带的乳腺癌数据做一个调参案例(参考菜菜的教程)
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
导入数据集和建模
data = load_breast_cancer()
rfc = RandomForestClassifier(n_estimators=100,random_state=1)
score_pre = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score_pre
0.9631265664160402
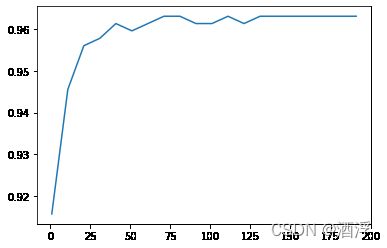
开始调参(n_estimators)
scorel =[]
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),'使分数最高的n_estimators值为:',scorel.index(max(scorel))*10+1)
plt.figure()
plt.plot(range(1,201,10),scorel)
plt.show()
0.9631265664160402 使分数最高的n_estimators值为: 71
网格搜索
param_grid = {'max_depth':np.arange(1,20,1)}
rfc = RandomForestClassifier(n_estimators=71,random_state=90)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
0.9666353383458647