营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
✍ 本文作者:持信、悟放、因尘、逸冰
1. 引言
对广告业务来说,文案在其中的重要性无需多言,即使是以图片、视频为主要载体的广告中,文案创意也几乎不曾缺席,如何为广告主和智能创意提供更好的文案创意是我们一直在思考的问题。
在过往的工作中,我们聚焦在某几种热门风格文案的优化,努力解决其中的基本问题,比如文案生成的通顺度、准确性和多样性问题,在这个过程中我们积累了丰富的文案优化经验,为业务上的应用探索了道路,但是随之而来的瓶颈也逐渐显现出来。
由于近年来网络带宽的增加和网络技术的发展,媒体的表现形式变得多种多样,同时多媒体内容的制作成本也在不断降低,极大地降低了创作者的创作门槛,进一步造就了现在百花齐放的内容创作新时代。随之而来的对于文案创意也提出了新的要求,“说的对”、“说的好”已经不再是衡量优秀文案创意的唯二标准。
从宏观上,当前业务已经以各种形式深入各个媒体,我们所要思考的不只是怎样写好淘内文案,如何融入不同载体(图片、视频、信息流卡片等),如何契合不同媒体的风格调性,已经成为了我们更为关注的重点。
从微观上,对于广告业务来说,创意提效的重要手段之一是使用创意优选算法,但是创意优选算法对于创意深度(即创意的多样性)要求非常高,然而传统的通过算法手段解决文案多样性的方法,只能增加某种类型文案内部的差异,但是对文案风格的多样性束手无策。通过大量的线上实验,我们证明了相比文案内部差异,文案风格的差异恰恰是影响优选效果更重要的因素。
基于上述背景,我们对新一代的智能文案提出了两个方向的要求,第一是根据文案载体设计出时空恰当的文案,第二是根据投放媒体的风格生成出风格一致的文案。这两个问题目前在业界和学术界的研究都非常少,经过前期的调研和思考,我们将这两个问题转换成了下面四个任务,其中,我们期待通过“图上文案生成”、“视频解说长文案生成”任务解决第一个问题,“文本风格迁移”任务解决第二个问题,最后“详情页文案挖掘”任务可以帮助我们完成基础的素材积累,助力其他任务。
2. 任务及解决路径
2.1 图上文案生成
2.1.1 背景
广告主通常会给商品图片配上特定的装饰性文案以突出重点,提升商品的吸引力和信息量,这些文案通常包括产品名、产品介绍、卖点、点击引导、利益点等类型。然而为图片设计合适的图上文案通常需要雇佣专业写手和设计师来完成,成本较高且相对低效。
传统的图文创意是基于预设模板的方式,依赖设计师的模板去填充对应的文案,模板的多样性往往不足以匹配图片的多样性,导致模板的适配性不足,同时受限于模板的固定范式,要求我们具有明确指定各种文案类型和特定字数的文案生成能力,不够灵活且适配成本较高。
为此,我们希望提出一种自动化的图文创作方式,利用多模态的文案生成技术,综合考虑图片本身信息(如商品主体、商品主体位置和背景色)、商品文本信息、文本框位置layout以及多个框之间的相对位置关系等信息自适应地生成合适的文案。其中文本框位置可以通过其他手段获取,比如OCR工具或者layout模型生成等。

2.1.2 方法
现有的图像文案生成通常是对整张图片生成一个整体的叙述性文案,缺乏对图片在空间上与对应文案的交互关系。在这个任务中,我们将在图片上的多个位置生成多个与之对应的文案。

为此,我们提出了一种基于上下文的多模态图上文案的模型,充分利用各模态商品信息去生成合理且多样的图上文案。模型将图片、当前位置框、前后位置框、商品类目、商品标题、商品属性对等作为输入,去生成对应当前位置框的文案。以上所有输入信息分别进行信息嵌入后输入一个混合模态的多层transformer中,模型通过自回归的方式生成预测的文案。
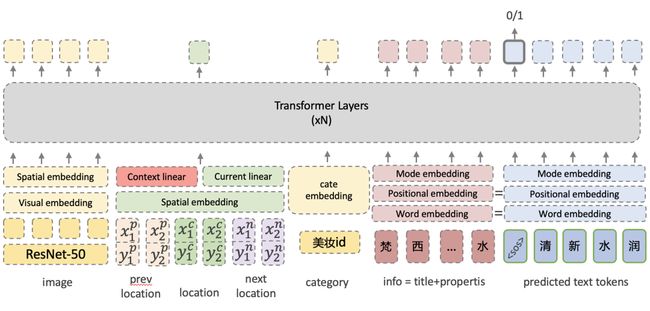
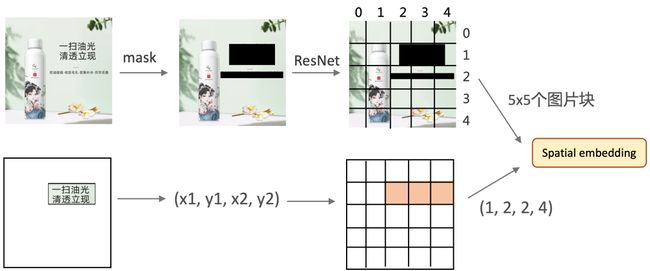
所有位置框的原始坐标为像素坐标,为了方便编码,我们将其进行离散化,具体来说,整张图从横纵两个方向切分为固定数量(示意图中以5X5为例)的格子patch,将位置框的坐标所在的patch的横纵坐标作为框的embedding id。图像部分的输入经过。在模型训练的过程中,由于图片上含有文字(即待生成的),为了避免模型坍塌成识别图上文字的OCR任务,我们对原图上的文字部分进行了mask。更多细节详见论文[1]。
2.1.3 结果
在实际使用阶段,我们使用近10亿张商品图片的大数据集进行训练,得到的模型在文案通顺度和合理性上都达到了很好的效果,经过渲染模型渲染后,已经达到可投放的程度。下面是我们在一些没有文案的空图上生成的文案样例,其中的文本框来自于上游的layout预测模型。



2.2 无监督文本风格迁移
2.2.1 背景
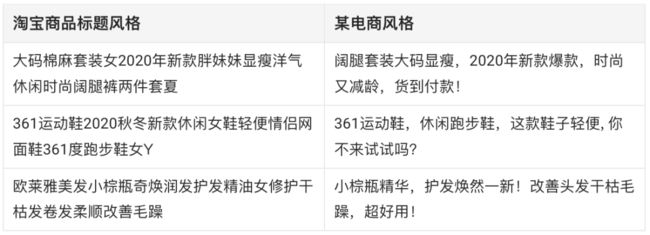
近年来,随着计算机视觉领域的图像风格迁移取得巨大成功,自然语言处理领域的文本风格迁移也越来越受到人们的关注。文本风格迁移,旨在保留文本内容的基础上,通过编辑或生成的方式改变文本的特定属性或风格(例如情感极性、性别和时态等)。文本风格迁移在广告文案制作时也有很多潜在的应用。如下图所示,广告文案在不同的平台往往具有不同的风格。

2.2.2 方法
下面介绍一下从淘宝商品标题风格迁移至某电商广告风格的技术方案。
Baseline
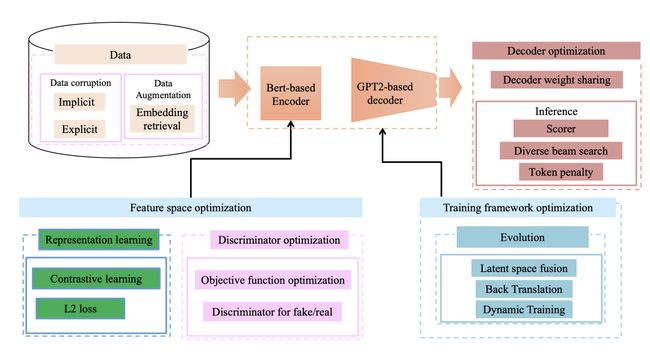
我们所使用的baseline是实现无监督文案风格迁移的一个通用框架,由一个encoder,一个discriminator和两个decoder组成。其中encoder的作用是建模文案的抽象语义分布,并从原始文案中去掉风格属性。Decoder的作用则是给抽象的语义表征加上风格信息,并形成最终的文案。我们使用对抗学习的方法来辅助训练,首先训练discriminator,使用的NLL loss,使其能够区分由encoder编码出来的来自不同风格域的句子表征。

改进方案
我们所做的改进工作共分为四大部分。首先是训练数据,我们进行了各种corruption方式的探索,用于后续的句子重建任务。同时通过隐向量检索构造高质量伪平行语料用于数据集扩充。对于encoder,我们通过增加新的学习任务以及优化判别器来促进encoder的能力,得到一个更加泛化与鲁棒的特征空间。对于decoder,我们使用了部分参数共享来提升模型的迁移性能,同时在inference阶段使用了多种策略对生成文本进行优化。对于训练框架,我们先后探索并实践了三种版本,最终确定了最优方案dynamic training。
2.2.3 结果
我们文本风格迁移的目标是基于无监督文案风格迁移的框架,实现目标场景的文案生成,同时保证文案的质量,与baseline相比,迁移文案的相关性与可读性都有了明显提升。我们对过审之后的文案质量进行分析,基于无监督风格迁移的文案质量在内容保留、语句逻辑和流畅度等方面均表现较佳,达到预期效果,以下为模型产出的实际case:
2.3 详情页文案挖掘
2.3.1 背景
淘宝商品详情页对于广告创意而言是一个内容丰富、规模庞大的素材库。详情页以图文并茂的方式对商品的卖点、用途、参数、使用说明、物流服务等做了生动和详细的描述,如何更好的挖掘和利用商品详情页文案也是我们工作的重点之一。!
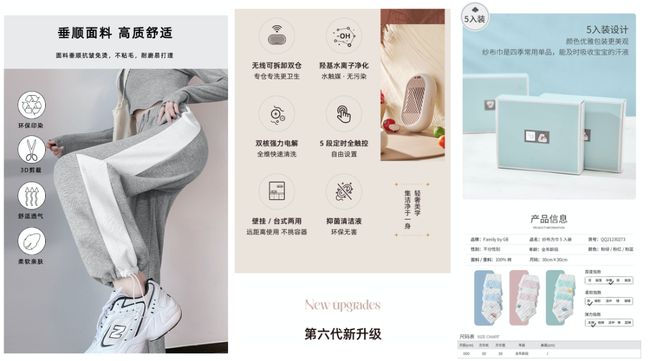 淘宝商品详情页
淘宝商品详情页
2.3.2 方法
详情页文案挖掘本身包含较多的技术问题。淘宝的商品详情页是由很多张的图片组成,没有直接提供文本内容和排版信息。首先需要通过OCR识别其中的文本元素。需要注意的是,OCR算法输出每个文本块的文本识别结果,但是不能识别文本排版的整体框架。同一个语义单元的文案可能折行的方式展示,可能以左右或者上下的顺序进行排版。商品的卖点可能以网格的方式进行排版,并且穿插图片。商品参数则大多是以表格的方式很规则地呈现。
所以对于OCR识别结果需要按照原有的语义结构进行组合,才能还原出商品文案。在最终使用之前,需要去除抽取的文案中无用的内容,按照文案的风格和用途进行分类,以方便下游业务更好的使用。我们采用的详情页文案挖掘流程如下:
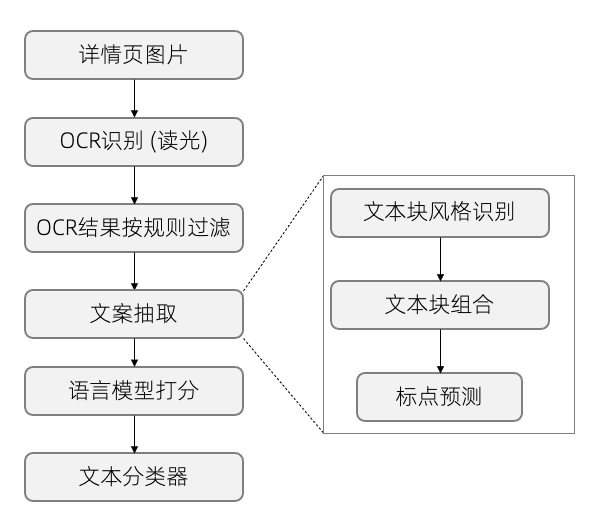 详情页文案挖掘流程图
详情页文案挖掘流程图
首先要对详情页进行OCR识别。我们采用的是读光OCR的识别结果,然后经过一些预定义的规则,去除不适合作为文案挖掘的详情页图和文本块。
接下来就是利用详情页图和OCR文本块的内容和位置信息抽取文案。这一步主要是把文本块按照原有的语义和排版结构还原成文案。这里我们没有使用标注数据,而是假设同一个语义单元的文本块聚集在彼此相邻的区域,并且具有相似的字体风格,用自监督的方式进行组合。字体编码模型训练完成后,我们以文本块之间的编码的cosine相似度作为字体相似度衡量。在对文本块进行组合时,需要考虑文本块是否相邻、相对距离是否小于阈值、字体风格相似度是否低于阈值。最后把每个组合的文本按照自然阅读顺序(从左到右、从上到下)进行排序。
经过以上步骤组合后的文本块,经过一个标点预测模型,拼接成完整的文案。标点预测模型基于BERT的文本对分类任务,以其他场景文案作为训练数据。
文案抽取步骤输出的文案候选,分别经过语言模型和文案分类模型进行打分和分类。语言模型是一个在其他场景文案上训练的GPT模型,可以用于计算文案的perplexity (ppl)。ppl主要用于初步过滤语义不完整、语法不流畅以及不适合作为文案的文本。然后,我们用未经过滤的详情页文案候选构建了超过10万的数据集,进行了人工标注,把每条文案标注为一个具体的风格类别(如“商品卖点”等)。然后以商品标题和文案组成的文本对作为输入训练了BERT分类模型。
2.3.3 实验&结果
为验证详情页文案挖掘流程的效果,这里选取了投放场景中的每日PV高于10的商品集作为输入商品集。下面展示了部分详情页文案挖掘结果:

2.4 视频解说长文案生成
2.4.1 背景
随着流量逐渐从图文媒体向视频媒体转移,视频场景在淘内外都变得越来越丰富和重要,相应地视频创意的覆盖场景也不断提升。
不可忽略的是,视频中的文案对于视频创意非常重要,尽管视频主体以图像的视觉表达为主,但是文案往往会在其中展现出画龙点睛的效果。视频广告中的文案主要可以分为两种形式展现,一是以文字贴片的形式直接通过视觉展现给用户,二是通过背景解说的形式通过音频输出,两种形式相互结合,使得广告主能够更容易地突出产品卖点并且把握用户心智,进而提升用户的购买欲。
但是文案创作本身对于中小广告主是有一定门槛的,尤其是编写篇幅较长、有逻辑性且吸引用户的文案更是会增加客户的负担,对于这个用户痛点,我们决定使用淘内海量的数据和我们的算法能力去解决问题。
2.4.2 方法
而广告场景的长文本生成则面临更多的挑战,首当其冲的是如何在更长的生成文案中保证产出文案的准确率,即不产出商品没有的卖点(无虚假广告);其次,在输入上有别于Story Generation的纯文本condition,针对淘宝商品文案生成的输入天然是多模态的,即输入中需要包含图(商品图)、文(商品标题)、结构化kv表格(商品属性)等才能更完整的表达商品。
为了解决上述问题,我们对模型提出了总体设计思路,使模型能更聚焦在重要的片段上,同时可以更充分理解视觉模态并将视觉模态的输入信息作为重要补充。基于此,我们设计了一个多模态多任务层次长文本生成模型,下图展示了模型的主要结构,更多细节详见论文[2]。
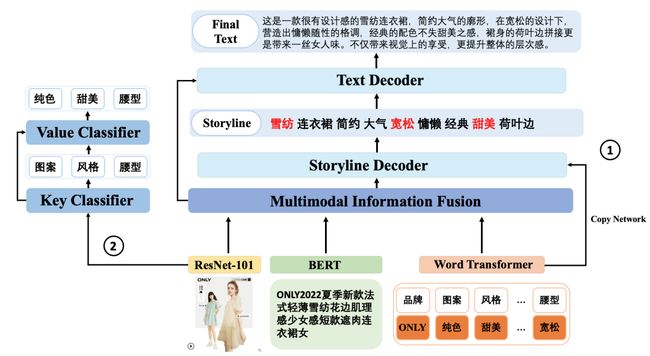 多模态多任务层次长文本生成模型结构
多模态多任务层次长文本生成模型结构
相比常见的文本生成模型,针对需求场景以及上面提到的两个亟需解决的问题,我们提出了两个主要的创新结构:
层次文本生成:我们将文案生成过程拆解成了两层,除了常规的groud truth文本作为上层text decoder的训练目标外,我们额外的增加了关键词作为下层storyline decoder的训练目标,并将storyline decoder的输出作为text decoder的输入;
图像属性分类:对于视觉模态的输入,我们增加了图像属性分类任务作为文本生成以外的额外任务,这样设计的主要目的是为了解决不同输入模态信息利用的不均衡问题。
2.4.3 结果
经过了一系列的改进,我们最终在近千万商品的训练语料上完成了模型的训练,相比改进之前的baseline,我们将整体文案的准确率提高了两倍以上,并成功落地到了多个视频工具中,为广告主带来了极大的效率提升。下面是一个应用在视频中的case:
3. 总结
我们的智能文案已经充分应用在了淘内外不同的广告业务场景上,支持了多个淘内BP、产品,并拿到了显著的业务收益。为了更好地通过算法能力服务广告主客户,我们与创意中心以及创意生态的同学合作共同建设了以“悉语”为名的智能文案产品,目前“悉语”月活用户超过15万。
 悉语智能文案工具https://chuangyi.taobao.com/pages/aiCopy
悉语智能文案工具https://chuangyi.taobao.com/pages/aiCopy
关于我们
我们是阿里妈妈创意&视频平台,专注于图片、视频、文案等各种形式创意的智能制作与投放,以及短视频广告多渠道投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP和推荐系统相关背景同学加入!
投递简历邮箱:[email protected]
Reference
[1] Yiqi Gao, Xinglin Hou, Yuanmeng Zhang, Tiezheng Ge, Yuning Jiang, Peng Wang: CapOnImage: Context-driven Dense-Captioning on Image.https://arxiv.org/pdf/2204.12974.pdf
[2] Zhipeng Zhang, Xinglin Hou, Kai Niu, Zhongzhen Huang, Tiezheng Ge, Yuning Jiang, Qi Wu, Peng Wang: Attract me to Buy: Advertisement Copywriting Generation with Multimodal Multi-structured Information.https://arxiv.org/pdf/2205.03534.pdf
END

也许你还想看
丨实现"模板自由"?阿里妈妈全自动无模板图文创意生成
丨告别拼接模板 —— 阿里妈妈动态描述广告创意
丨如何快速选对创意 —— 阿里妈妈广告创意优选


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓