9-图像分割之BiSeNet
1.前置
分割常用损失函数:
交叉熵:兼容大部分语义分割场景,但是在二分类场景中如果某一类所占像素特别多那么模型会偏向这一类,分割效果不好。
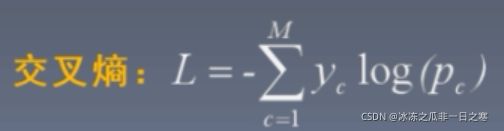
加权交叉熵:顾名思义,在交叉熵前面加一个权重,可以有效缓解类不平衡问题。

BCELoss:可以理解为二分类情况下的交叉熵,通常接sigmoid激活函数

Focal Loss:主要是为了解决难易样本数量不平衡的问题(即样本中容易区分的占大多数,使得模型偏向于区分简单样本,而不去优化对于难区分样本的判断),同时对交叉熵函数引入参数调节,也可以同时处理正负样本不平衡的问题(举例来说就是前景和背景所占比例差别很大),目前主要使用二分类问题。

(以y=1为例,当p很小时,此时代表难分类,则损失基本不变,但是当p很大时,此时代表易分类,损失会急剧下降,达到抑制易分类的效果)
Dice Loss:

Dice系数: 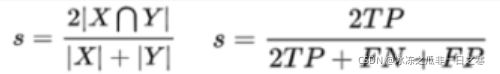
DiceLoss适用样本极度不平衡的情况,一般情况下使用DiceLoss会对反向传播有不利影响,使训练不稳定
IoULoss:
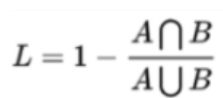
Dice Loss和 IoULoss是通过直接优化最终的指标(例如IoU)来达到目的,而之前的交叉熵等损失函数是通过找到指标的各种映射,通过优化映射关系来达到目的。


分类器的评价指标不能单单用准确率这一个指标,单个指标的评价有时候会比较片面(尤其是数据分布不均衡的情况下),还可以参照其他指标如精确率,召回率等。
2.摘要
- 背景介绍:语义分割同时要求丰富的空间信息和相当大的感受野。然而通常我们为了达到实时的推理速度,会降低图像的空间分辨率,从而导致效果很差
- 算法组成:本文提出了双向的语义分割网络。首先,采用空间分支保持空间信息并生成高分辨率的特征图。其次,采用快速下采样策略的上下文分支去获得丰富的感受野。最后,引入了特征融合模块结合两个分支的特征
- 模型评估:所提出的结构在兼顾速度的同时,在Cityscapes、CamVid.和COCO-Stuff数据集上取到了很好的性能。
针对语义分割两个重要关注点:感受野和分辨率,文章提出了两个模块Spatial Path和Content Path,前者对应保留图像分辨率以获得更好的位置信息,后者则保证了足够大的感受野以获得更多的上下文信息,并且提出了特征融合模块和注意力模块来对预测进行优化。
关于全局平均池化:
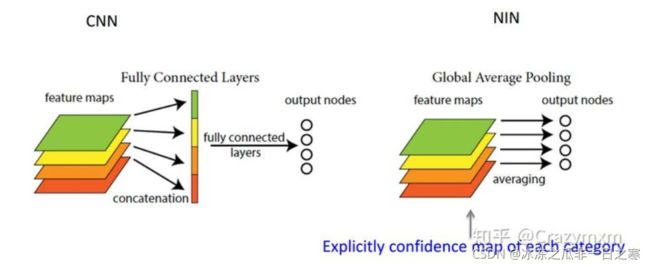
如图,CNN一般最后要接一个或n个全连接层,然后再做softmax分类,弊端是带来参数量爆炸,模型变得很臃肿,而且容易出现过拟合;而GAP的话则是有点像把GAP功能合二为一了,举例来说:将N个W×H的feature map降维成1*N大小的feature map,再用class个1*1卷积核将1*N的feature map卷成1*class的向量,节省了大量参数,但是使用GAP可能会使收敛变慢。另外既然名字叫池化,那么它也具有增大感受野,获取上下文信息的作用。
3.Pytorch实现BiSeNet

from PIL import Image
import torch
from torch import nn
import torch.nn.functional as F
import torchvision.models as models
class resnet18(torch.nn.Module):
def __init__(self,pretrained=True):
super().__init__()
self.features=models.resnet18(pretrained=pretrained)
self.conv1=self.features.conv1
self.bn1=self.features.bn1
self.relu=self.features.relu
self.maxpool1=self.features.maxpool
self.layer1=self.features.layer1
self.layer2 = self.features.layer2
self.layer3 = self.features.layer3
self.layer4 = self.features.layer4
self.avgpool=nn.AdaptiveAvgPool2d(output_size=(1,1))
def forward(self,input):
x=self.conv1(input)
x=self.relu(self.bn1(x))
x=self.maxpool1(x)
feature1=self.layer1(x) #1/4
feature2=self.layer2(feature1)#1/8
feature3 = self.layer3(feature2)#1/16
feature4 = self.layer4(feature3)#1/32
tail=self.avgpool(feature4)
return feature3,feature4,tail
class AttentionRefinementModule(torch.nn.Module):
def __init__(self,in_channels,out_channels):
super().__init__()
self.conv=nn.Conv2d(in_channels,out_channels,kernel_size=1)
self.bn=nn.BatchNorm2d(out_channels)
self.sigmoid=nn.Sigmoid()
self.in_channels=in_channels
self.avgpool=nn.AdaptiveAvgPool2d(output_size=(1,1))
def forward(self,input):
#global average pooling
x=self.avgpool(input)
assert self.in_channels==x.size(1),'in_channels and out_channels should all be {}'.format(x.size(1))
x=self.conv(x)
x=self.sigmoid(x)
x=torch.mul(input,x)#逐元素相乘
return x
class FeatureFusionModule(torch.nn.Module):
def __init__(self,num_classes,in_channels):
super().__init__()
self.in_channels=in_channels
self.convblock=ConvBlock(in_channels=self.in_channels,out_channels=num_classes,stride=1)
self.conv1=nn.Conv2d(num_classes,num_classes,kernel_size=1)
self.relu=nn.ReLU()
self.conv2=nn.Conv2d(num_classes,num_classes,kernel_size=1)
self.sigmoid=nn.Sigmoid()
self.avgpool=nn.AdaptiveAvgPool2d(output_size=(1,1))
def forward(self,input_1,input_2):
x=torch.cat((input_1,input_2),dim=1)
assert self.in_channels==x.size(1),'in_channels of ConvBlock should be {}'.format(x.size(1))
feature=self.convblock(x)
x=self.avgpool(feature)
x=self.relu(self.conv1(x))
x=self.sigmoid(self.conv2(x))
x=torch.mul(feature,x)
x=torch.add(x,feature)
return x
class ConvBlock(torch.nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,stride=2,padding=1):
super().__init__()
self.conv1=nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,stride=stride,padding=padding,bias=False)
self.bn=nn.BatchNorm2d(out_channels)
self.relu=nn.ReLU()
def forward(self,input):
x=self.conv1(input)
return self.relu(self.bn(x))
class Spatial_path(torch.nn.Module):
def __init__(self):
super().__init__()
self.convblock1=ConvBlock(in_channels=3,out_channels=64)
self.convblock2=ConvBlock(in_channels=64,out_channels=128)
self.convblock3=ConvBlock(in_channels=128,out_channels=256)
def forward(self,input):
x=self.convblock1(input)
x=self.convblock2(x)
x=self.convblock3(x)
return x
class BiSeNet(torch.nn.Module):
def __init__(self,num_classes):
super().__init__()
self.saptial_path=Spatial_path()
self.context_path=resnet18(pretrained=True)
self.attention_refinement_module1=AttentionRefinementModule(256,256)
self.attention_refinement_module2 = AttentionRefinementModule(512, 512)
self.supervision1=nn.Conv2d(in_channels=256,out_channels=num_classes,kernel_size=1)
self.supervision2 = nn.Conv2d(in_channels=512, out_channels=num_classes, kernel_size=1)
self.feature_fusion_module=FeatureFusionModule(num_classes,1024)
self.conv=nn.Conv2d(in_channels=num_classes,out_channels=num_classes,kernel_size=1)
def forward(self,input):
sp=self.saptial_path(input)
cx1,cx2,tail=self.context_path(input)
cx1=self.attention_refinement_module1(cx1)
cx2=self.attention_refinement_module2(cx2)
cx2=torch.mul(cx2,tail)
cx1=torch.nn.functional.interpolate(cx1,size=sp.size()[-2:],mode='bilinear')
cx2 = torch.nn.functional.interpolate(cx2, size=sp.size()[-2:], mode='bilinear')
cx=torch.cat((cx1,cx2),dim=1)
if self.training==True:
cx1_sup=self.supervision1(cx1)
cx2_sup=self.supervision2(cx2)
cx1_sup=torch.nn.functional.interpolate(cx1_sup,size=input.size()[-2:],mode='bilinear')
cx2_sup = torch.nn.functional.interpolate(cx2_sup, size=input.size()[-2:], mode='bilinear')
result=self.feature_fusion_module(sp,cx)
result=torch.nn.functional.interpolate(result, size=input.size()[-2:], mode='bilinear')
result=self.conv(result)
if self.training==True:
return result,cx1_sup,cx2_sup
return result
if __name__ =='__main__':
import torch as t
rgb=t.randn(1,3,352,480)
net=BiSeNet(19).eval()
out=net(rgb)
print(out.shape)参考:
B站深度之眼
为什么使用全局平均池化层? - 知乎