结合openCV学习DIP之机器学习CNN
综述
结合openCV学习DIP之传统图像特征与匹配
图像特征
图像的浅层特征主要是颜色、纹理和形状
图像特征是指: 可以表达图像中对象的主要信息, 并且以此为依据可以从其他未知图像中检测出相似或相同的该对象A.
在特征提取上,传统的图像处理都是自行设计提取固定特征的算子,在深度学习上主要是利用CNN网络来广泛的提取图像的特征.
笔记以吴恩达课程为基础, 全面介绍机器学习相关术语, 再以李航《统计学习方法》和周志华《机器学习》以及《学习openCV3》为基础,记录学习内容, 将不定期更新.
机器学习-吴恩达课程笔记
本章以吴恩达机器学习课程为基础, 记录期间的学习笔记,该课程和本笔记仅以入门为目标, 即不涉及理论具体推导.
第一课-基本术语和LogisticRegression
目的: 将一个图片输入到一个 (暂称为)机构 中, 自动对其进行分类
分类的结果有二类分类和多类分类, 根据分类结果不同,可以将分类器分为:
二类分类: 感知机,支持向量机SVM, Adaboost提升方法,Logistic回归模型
多类分类: k近邻树(k近邻法),朴素贝叶斯法,决策树,Logistic回归模型,最大熵模型
如何遍历一个包含了N个图片的集合? 一般是for循环,但是这种费时.
回归:简单理解为两组数据关系的统计分析方法
对于一张图片一般是3个通道,假设图片size是64x64, 那么将这张图片记为x, x通过维度变换为nx1的列向量,如下图所示:

假设训练集train set记为X有m个样本,每个样本是![]() ,其中
,其中![]() 表示第i个样本的标签, 标签的信息即分类信息, 比如猫or狗
表示第i个样本的标签, 标签的信息即分类信息, 比如猫or狗
上述![]() 是一个n维列向量
是一个n维列向量![]() ,显然, 训练集X是一个n行m列的矩阵,同理标签Y如下
,显然, 训练集X是一个n行m列的矩阵,同理标签Y如下

LogisticRegression 逻辑回归模型
![]() 为预测值,
为预测值,  为标签真实值, X为输入的图片集合记号, 对其有表达式:
为标签真实值, X为输入的图片集合记号, 对其有表达式:
![]() 得到一个线性的模型, 但是输出的范围变成了∞, 想要函数值限定在[0,1]
得到一个线性的模型, 但是输出的范围变成了∞, 想要函数值限定在[0,1]
![]() 其中
其中![]() , 该表达式将其值域锁定在了[0,1]上
, 该表达式将其值域锁定在了[0,1]上
Loss function损失函数和Cost function成本函数
loss function是对于单个样本而言, 目的是求 真实值 和 预测值之间的差距, 自然是越小越好,其数学表达式为:
![]()
由于y是标签值,自然是不变的, 而![]() 是预测值, 其值和w和b有密切关系,将
是预测值, 其值和w和b有密切关系,将![]()
带入L()中![]()
cost function是对于群体样本而言, 其数学表达式为:
![J(w,b) = [\frac{1}{m} \cdot \sum_{i-n}^{m}L(\hat{y}^{(i)}, y^{(i)}) ]](http://img.e-com-net.com/image/info8/bd2ba99afa524ef9bbb608d08cd9f053.gif)
上述问题转换成: 如何确定 w和b的值, 使得L和J 存在最小值, 即使得分类的错误率最低?
答案: GradientDescent 梯度下降法
梯度下降法或最速下降法steepest descent 是求解无约束最优化问题的一种常用方法
graditent descent是一种迭代算法, 选取适当的初值![]() ,不断迭代更新x的值,将目标函数值最小化,直到收敛.
,不断迭代更新x的值,将目标函数值最小化,直到收敛.
负梯度方向是使函数值 下降 最快的方向, 应当以负梯度方向更新x值

书中或许不太容易理解, 作图理解如下: 注意parameter学习率

对于上图抛出的问题,
该曲线的递减部分, 其斜率为负, 梯度负方向,负负得正,w+正数,因此w向右移动, 递增部分, 斜率为正, 梯度负方向,w+负数,因此w向左移动
w在初始化时, 不能=0,应尽量random 而b在初始化时,可以=0, 原因在于: w初始化=0, 每个单元都在做为0的same things, 无意义
在上述的问题中, 如何通过计算得到的损失函数的值, 自动更新输入的w和b的值呢? 从而自动调整模型的参数,使得预测能力的错误率降低?
为了回答这个问题, 引入正向传播和反向传播的概念, 在下图的反向传播中,  就是将来参数b 在梯度下降时需要的梯度值,其方向取- ,这里
就是将来参数b 在梯度下降时需要的梯度值,其方向取- ,这里![]() 就是反向传播中如何求取(简单的高数知识)
就是反向传播中如何求取(简单的高数知识)

例子1: 单个样本
假设有样本![]() , 因为
, 因为 ![]() , 那么
, 那么![]()
显然x是列向量, w应该为行向量, b则为1x1的单数值
根据logistic 回归模型,有
![]()
![]()
![L(\hat{y},y) = L(a,y)=L(\sigma(z),y) = -[y\cdot loga+(1-y)\cdot log(1-a)]](http://img.e-com-net.com/image/info8/7d6ba1c3dcf244128fe54401176a2754.gif)
对w1和w2和b进行gradient descent, 引入学习率

例子2: 多个样本
成本函数
假设有样本![]() , 因为
, 因为 ![]() , 那么
, 那么![]() ,
, ![]()
直接将其看成矩阵,然后求即可
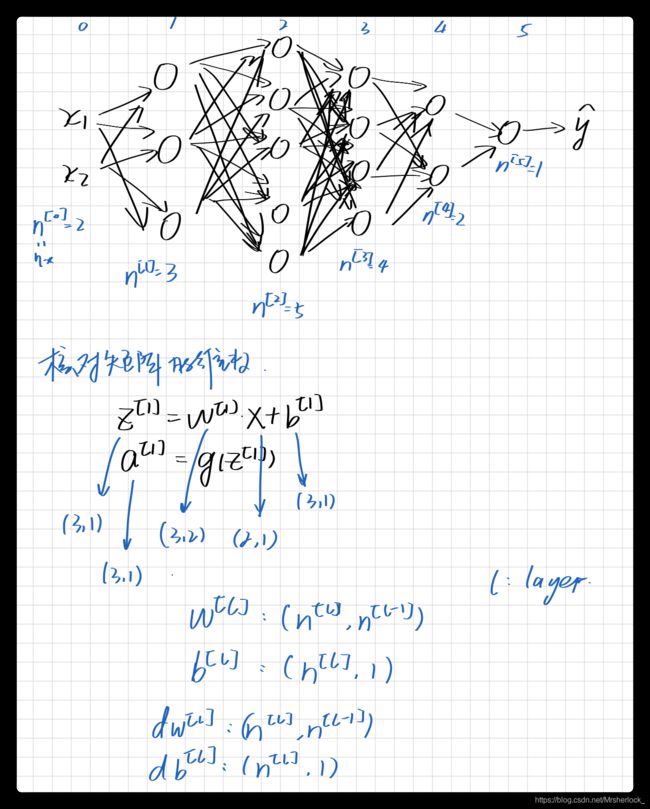
Nerual Network
2 layers nerual network
为了区分, 现将[i]表示网络第i层, (i)表示第i个样本(方便理解,可以把每个样本理解成一张图片)
下图中![a^{[1]}](http://img.e-com-net.com/image/info8/87c755b93b1b422c90d28d738001ef47.gif) 表示第1层的激活函数activation function, 该函数的表达式暂且不表.应当注意
表示第1层的激活函数activation function, 该函数的表达式暂且不表.应当注意![a^{[1]} = \begin{bmatrix}a^{[1]}_1 \\ a^{[1]}_2 \\ a^{[1]}_3 \\ a^{[1]}_4 \end{bmatrix}](http://img.e-com-net.com/image/info8/975d623d7c85414aba7da720f7fab3c6.gif) 即 下图中的第一层
即 下图中的第一层

应该根据输入的X维度和输出的分类结果Y的维度, 从第一层开始逐步推出每一层的维度

激活函数 ActivationFunction
上述的网络引入了新的概念: 激活函数
激活函数的作用是什么? 表达式一般是什么样的?
上述的![]() 就是一种激活函数, 该函数的值域在[0,1]
就是一种激活函数, 该函数的值域在[0,1]
另一种激活函数![]() ,该函数值域在[-1,1]
,该函数值域在[-1,1]

![]() 和
和![]() 的缺点是: 两者在趋于∞时, 梯度变化很不明显
的缺点是: 两者在趋于∞时, 梯度变化很不明显
当分类时, 作为输出结果,显然值域[0,1]的![]() 更适合做输出层的激活函数
更适合做输出层的激活函数
修正线性单元Rectified Linear Unit, 即ReLU函数
由于上述两者的缺点在趋于∞时梯度变化不明显,且值域应尽量在[0,1],基于此引入ReLU函数
![]() 其中
其中 ![]()

综上所述:
在binary classification 二值分类中, output layer的activation function应为![]() , hide layers的activation function应为ReLU
, hide layers的activation function应为ReLU
![]() liner activation function
liner activation function
![]() ,
, ![]() 和ReLu 都是non liner activation function
和ReLu 都是non liner activation function
至此, 对于一个简单网络来说, 有parameters: w,b, dw,db 有hyper paramters:  学习率
学习率
hyper-parameters超参数: 用于控制,调整paramters的参数,如可以在gradient descent时控制参数更新的步长
第二课-网络参数详解
BIas&Variance
参数
一个网络,需要考虑的参数有:
layers, hidden units, learnings rates:, activation function等
本节课主要讲的是neural network中常见的hyper-paramters和基本的parameters以及相应的调试方法和算法优化
训练集,验证集,测试集
一般来说,当数据量较小时:
training set 和test set分别在数据量的70%和30% ,存在验证集时,training set/develpment set/test set分别占60%/20%/20%,
当数据量较大时:
trianing set/development set/test set分别占99%/0.5%/0.5%或98%/1%/1%
数据分布 trian/test distribution
一般而言,要确保: dev set/test set come from same distribution
bias, variance 偏差和方差
正确理解bias 和variance的概念
bias决定了能中几环,值越大越偏
variance决定了发挥的稳定程度, 就是离散程度, 值越大越离散
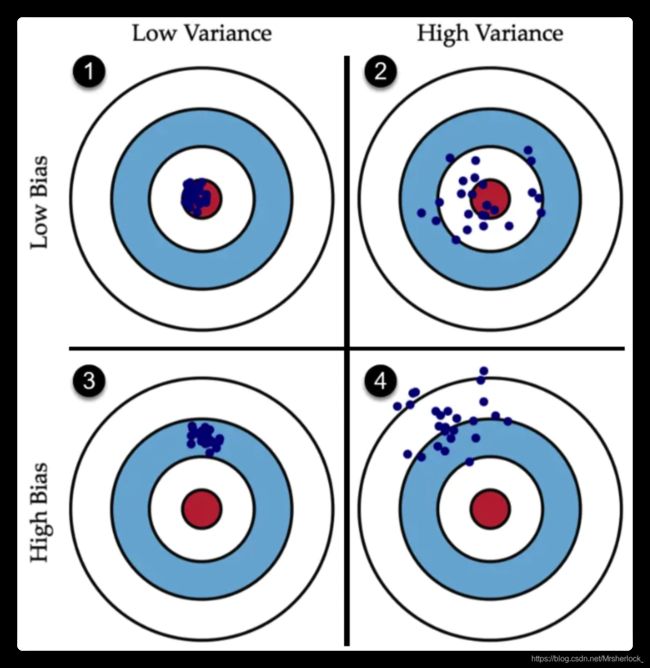
拟合: 把平面上一系列的点, 通过一条光滑的曲线连接起来,该曲线常可以用函数来表示.
如果函数是线性的,则线性拟合,线性回归, 反之非线性拟合,非线性回归
将拟合与bias, variance结合来看:


Regularization
L2 Regularization L2范数正则化
以Logistic regression的J(w,b)为例, 对表达式引入正则化项

其中, 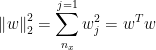 为向量w的L2范数的平方,
为向量w的L2范数的平方,
关于范数:
L0范数 ![]() , 0表示0次幂
, 0表示0次幂
L1范数![]() , 1表示1次幂
, 1表示1次幂
L2范数![]() ,2表示2次幂
,2表示2次幂
那么:
J(w,b)+系数*w的L0范数=L0范数正则化,
J(w,b)+系数*w的L1范数=L1范数正则化, ![]()
J(w,b)+系数*w的L2范数=L2范数正则化,
上述 为regularization parameter正则化参数, 也是hyper-parameter
为regularization parameter正则化参数, 也是hyper-parameter
以neural network为例, 引入regularization parameter
假设有m个样本,NN layers = l
![]() 其中F表示Frobenius范数, 为regularization parameter
其中F表示Frobenius范数, 为regularization parameter
Frobenius范数:![\left \| w^{[l]} \right \|^{2}_{F} = \sum_{i=1}^{n^{[l-1]}} \sum_{i=1}^{n^{[l]}}(w^{[l]}_{ij})^{2}](http://img.e-com-net.com/image/info8/cad6effc218b467590b4790fd21247fa.gif)
引入正则化项 直接导致 矩阵乘了了一个![]() 的权重, 该值<1, 当足够大时,
的权重, 该值<1, 当足够大时, ![]() 也就是说
也就是说
第l层的权值w=0, 那么该层的输入x就不纳入计算,消除了对应x的作用, 优化了网络结构,降低high variance.
为什么正则化就可以降低high variance呢?
因为variance之所以很高是因为model比较复杂导致overfitting, 降低variance的方法就是添加regularization项.
也可以想想variance过高, 离散程度很大, 导致一些不需要考虑进来的样本, 也考虑进来了
降低高bias时, 可能会导致高variance, 反之亦然
但引入正则化项的弊端在于: 可能产生high bias

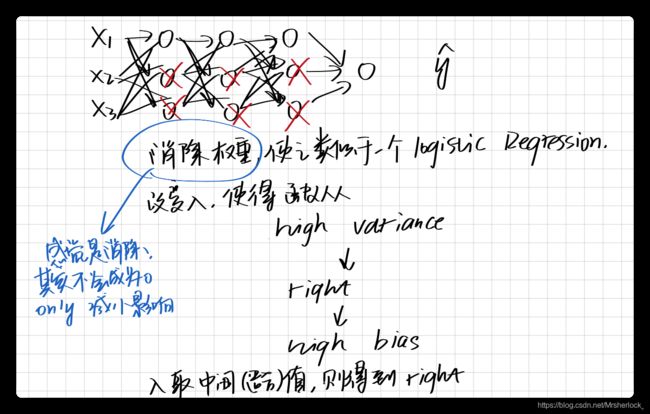
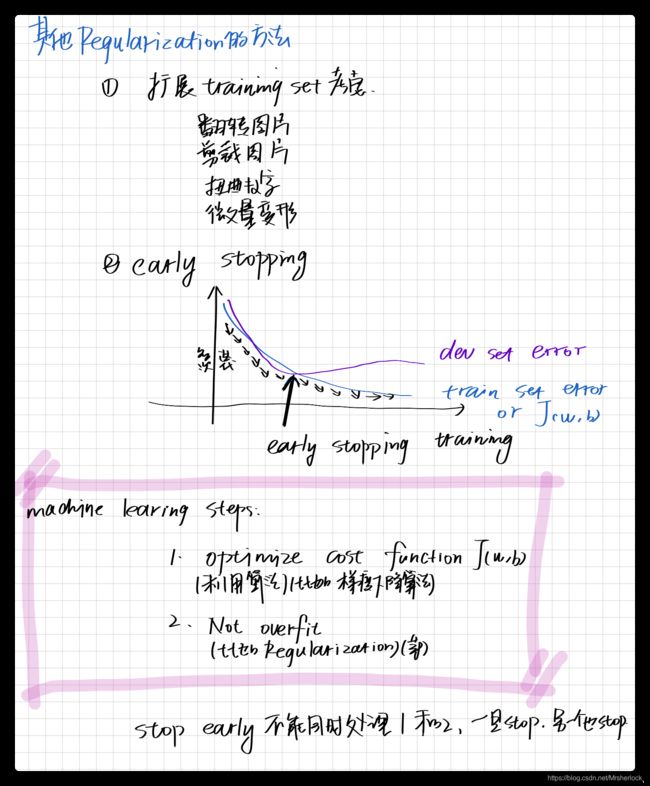
Dropout随机失活-另一个正则化技术
DropoutRegularization
每一层的每个神经单元都会以P的概率决定是否参与计算,一般P=0.2, 0.5,0.8
每一层的P的值是不同的

一般而言, 正则化项只存在于training期间, test时并不适用
dropout常用在computer vision中
Dropout的缺点: J(w,b)不再明确,一般现将P=1,将J调参到J单调递减,然后再打开P=(0.2, 0.5,0.8)
Vanishing/exploding gradient 梯度消失/爆炸

解决办法: 一些paper指出,调整激活函数对应的w值
g(z), w=1/n
ReLU, ![]()
tanh, ![]()
GradientDescent的优化算法
BatchGradientDescent, 之前提到的就是
1⃣️Mini-Batch GradientDescent
把train set按照size分成若干批次,size也是一个hyperparameter

当train set个数小于等于2000时, 适用batch gradient descent
当trainset个数大于2000时, 令mini batch per-size包含的数据:
64,128,256,512,具体选哪个应该和GPU或者CPU的memory大小匹配
2⃣️Momentum GradientDescent
引入概念 指数加权平均数
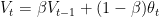
- θ_t:为第 t 天的实际观察值,
- V_t: 是要代替 θ_t 的估计值,也就是第 t 天的指数加权平均值,
- β: 为 V_{t-1} 的权重,是可调节的超参。( 0 < β < 1 ), 该超参数的意义在于, 对于任意的
 有:
有: 也就是说:
也就是说:
指数加权平均数就是最近![]() 的样本的平均值
的样本的平均值
β 越小,噪音越多,虽然能够很快的适应温度的变化,但是更容易出现奇异值。
β 越大,得到的曲线越平坦,因为多平均了几天的温度,这个曲线的波动更小。
但有个缺点是,因为只有 0.02 的权重给了当天的值,而之前的数值权重占了 0.98 ,
曲线进一步右移,在温度变化时就会适应地更缓慢一些,会出现一定延迟。
通过上面的内容可知,β 也是一个很重要的超参数,不同的值有不同的效果,需要调节来达到最佳效果,一般 0.9 的效果就很好。
指数加权平均,作为原数据的估计值,可以抚平短期波动,起到了平滑的作用,
Momentum 梯度下降法,就是计算了梯度的指数加权平均数,并以此来更新权重,它的运行速度几乎总是快于标准的梯度下降算法。
也就是说, 在使用上述的mini-batch做gradient descent,得到dw 和db ,再计算dw和db的指数加权平均数, 用此值更新w和b
![]()
![]()
![]()
![]()
至此, 引入了两个hyper-parameters: mini-batch 的size 和momentumGD的 ![]() =0.9
=0.9
Bias correction偏差修正
在估测初期,一般需要进行偏差修正,如![]()
3⃣️RMSProp
root mean square propagation 均方根传播算法
在第t次迭代中, 通过mini-batch得到dw和db ,计算Sdw和Sdb更新w和b
![]()
![]()
![]()
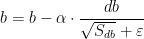
其中![]() 都是hyper-parameter,
都是hyper-parameter,  是为了防止
是为了防止![]() 和
和 , 因此其值一般为
, 因此其值一般为![]()
RMS prop是从学习率的角度解决振荡和加快学习速度的,实际上是对AdaGrad和AdaDelta的改进(基本思路是对于每个参数W或b,自动的适配其对应的学习率,而不是使用全局统一的学习率)。
RMS prop的思路是,如果某个参数方向的摆动幅度大(噪音或振荡大),那么就说明这一参数的方差大,那么如果动态的将该参数方向的学习率降低,就能够减小梯度下降步长,从而减小摆动幅度,反之增加步长,使其能够更快的到达最优点。因此在RMS Prop中,用梯度除以该参数的指数加权平均方差来实现这一功能。

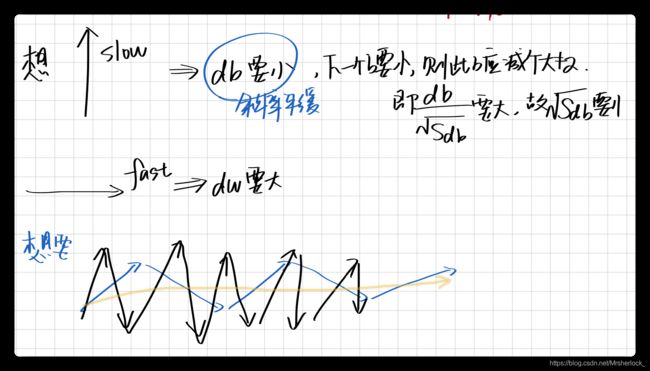
momentum和RMSProp都是从gradient descent的摆动消除出发,加速算法
4⃣️Adam optimization algorithm
Adam=momentum+RMSProp
①令![]()
②利用mini-batchGD进行迭代, 假设当前为第t次, 得到![]()
③使用momentum和RMSProp, 一般![]()
![]()
![]()
![]()
![]()
④bias-correction, t为当前迭代次数
![]()

![]()
![]()
⑤更新参数w和b,其中![]() ,学习率取值待定
,学习率取值待定
![]()
![]()
5⃣️Learning rate decay学习率衰减
学习率在初期往往较大, 学习率越大, 在上下前后方向的步长就很大, 震荡太强

为了调整学习率,引入decay rate即衰减率参数
有三种方法可以使得学习率衰减,
①![]()

②![]()
③![]() , t为迭代次数
, t为迭代次数
调试时,参数的优先性

![]()
Robust
使得网络更具鲁棒性
1⃣️Batch Normalizing Batch归一化
这里涉及到的是高数概率论的知识,就是将分布调整为正态分布, 首先要计算方差和期望
举例1:
假设在第l层有![]() ,
, ![]() ,参数b可以不要, 以mini-batch为单位处理, 每个mini-batch的方差和期望统一
,参数b可以不要, 以mini-batch为单位处理, 每个mini-batch的方差和期望统一
期望![]()
方差![]()
归一化为标准正态分布:![]() , 其中
, 其中![]() 是防止分母为0
是防止分母为0
更新:![]() 这里的
这里的 ,
, ![]() 是新的hyper- parameter, 其值的更新类似w和b,也是利用反向传播进行更新
是新的hyper- parameter, 其值的更新类似w和b,也是利用反向传播进行更新

上述只是对neural network的一层进行了网络的第l层 归一化, 其实BN可以对网络的input layer和hidden layer进行归一化
举例2
对整个网络使用BN
假设使用的是mini-batch gradient descent

为什么BN可以加速网络训练??
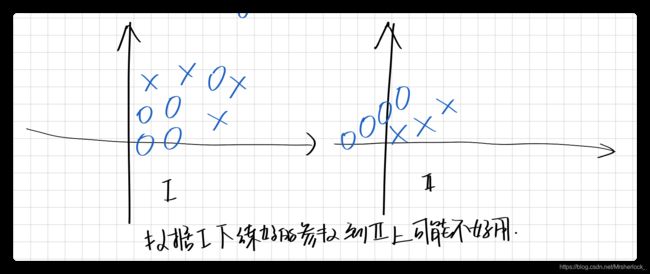
BN做的就是无论数据怎么变化, 都可以保证均值(期望)和方差不变
数据可以是来自input layer的X,也可以是hidden layer[l-1]传给[l]层的输入
防止了[l-1]层的参数更新导致[l]层的数据分布变化
相当于减弱了各层之间的联系,每层都处于独立学习状态
BN是以mini-batch为单位逐一处理,那么如何以样本为单位逐一处理呢?

多类分类
到目前为止的logistic regression因输出层函数的问题,一直是二类分类0or1
引入softmax regression
通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布。
softmax函数引入了指数函数
指数函数曲线呈现递增趋势,最重要的是斜率逐渐增大,也就是说在x轴上一个很小的变化,可以导致y轴上很大的变化。这种函数曲线能够将输出的数值拉开距离。
指数函数的曲线斜率逐渐增大虽然能够将输出值拉开距离,但是也带来了缺点, 值非常大的话,计算得到的数值也会变的非常大,数值可能会溢出。
当使用Softmax函数作为输出节点的激活函数的时候,一般使用交叉熵作为损失函数。
由于Softmax函数的数值计算过程中,很容易因为输出节点的输出值比较大而发生数值溢出的现象,在计算交叉熵的时候也可能会出现数值溢出的问题。
softmax函数
[l]表示layer, C表示输出类别总个数,c表示第c个类别, i表示第i个样本
![]()
![\huge \hat y = a^{[l]}_{(i)} = \frac{e^{z^{[l]}_{(i)}}}{\sum_{C}^{c=1}e^{z^{[l]}_{(c)}}}](http://img.e-com-net.com/image/info8/1e63a863e72340af80f31a6acf492f7e.gif)

交叉熵
第三课-机器学习策略
第四课-CNN
不管输入图像的深度为多少,经过一个卷积核(filter) ,这个卷积核(filter)的channel数等于输入的channel, 大小Size为设计好固定的, 或者为一个网络参数,通过反向传播更新的值.
无论怎样, 最后都通过下面的公式变成一个深度为1矩阵。
第L层的filter的个数, 就是L+1层的channel数
CNN入门
CNN一般包括三类网络层,
Convolution CONV卷积层, Pooling Pool池化层, Fully connection FC全链接层
1⃣️卷积层
灰度图片的边缘检测
灰度图像只有一个色道,即 有一个6*6*1的灰度图像,kernel核, filter过滤器 *表示卷积运算符

然后蓝色框框右移得到4*4的第一行第二列的元素

6*6是一个灰色的样本图片, 3*3的filter过滤器, 4*4可以看成生成的另一个图片

这些在之前的文章都有提到,那现在的问题是:
如何将卷积做成CNN的基本模块并建立CNN呢?
- 接下来你要学会区分正边,负边, 就是由亮到暗还是由暗到亮, 也就是边缘的过渡, 和其他边缘的过渡, 以及这些算法的使用
-
上边的那个filter过滤器, 是1\0\-1这些组合, 计算机视觉学术中也讨论到底怎么组合最好, filter的维数一般是奇数,这样有个中心点
-
sobel filter

-
scharr filter(也是垂直边缘检测, 实际上翻转90度就是水平检测了)

-
对于filter的size, 现在我们并不喜欢用固定的数, 而是让它成为hyperparameters
-
(可以用反向传播来找出这些w_i)
-
这种filter对数据的捕捉能力很强!
-
任何角度的边缘都可以检测,利用这些参数, 利用数据的反馈来调整他们, 很棒
-
-
-
Padding卷积的基本操作
-
给出一个图片是n*n像素的, 再给出一个filter是f*f的, 你会得到一个
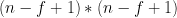 的输出
的输出-
缺点:
-
每次卷积你的图片都小了,
-
原图角落的像素值利用率很低, 中间部分的利用率过高, 相当于丢掉了原图边框角落的图像
-
-
解决:
-
可以在原图的外边填充一圈全是0的像素点, p就是填充数量, 填充一圈是p=1
-
-
根据填充多少分成了Valid和Same convolutions两类卷积
-
Valid convolution 不填充 no padding
-
Same convolution 填充padding 导致输入输出都一样的卷积
-
-
-
-
卷积步长是CNN的基本操作 strided convolutions
-
输出维度计算
-
有边界填充时,输入n*n filter是f*f, padding是p, 步长stride是s, 输入和filter通道数一致, 则输出宽高是
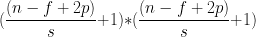 , 其输出的channel=本次filter个数
, 其输出的channel=本次filter个数 -
无边界填充p=0,公式一致
-
-
如果输出((n+2p-f)/s+1) * ((n+2p-f)/s+1) 不是一个整数, 我们一般向下取整, 其实就是只要蓝色框有一部分不在原图中,就不计算了
-
上述做的操作, 技术上有时候被称为互相关, 而不是卷积, 卷积是在filter参与运算前, 把filter的元素上下镜像, 左右镜像, 再参加运算, 在深度学习的惯例中, 依然把互相关当成卷积
多通道图片边缘检测
-
牢记上述的维度计算
-
之前已经会做二维卷积了, 那三维卷积怎么搞?
-
之前是灰度图像,现在是彩色图像就是n*n*3
-

-
如果你想同时检测多个角度的边缘该怎么办?也可以是个多维的, 其中的2就是2个不同的filter, 一般属于的图片都是n*n*n_channels(通道数)

单层卷积神经网络
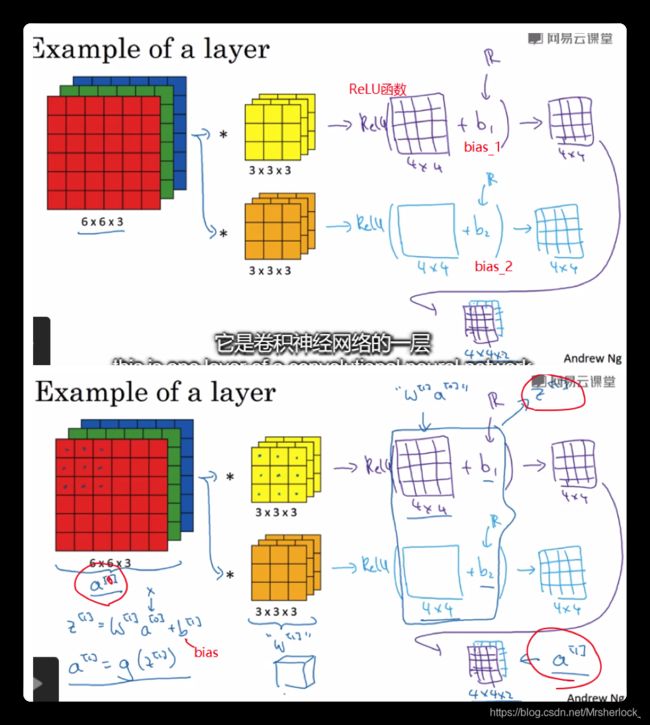
上图用两个卷积核(filter),每个filter检测目的不同, 但和输入保持相同channels, 由于有两个卷积核,所以输出的channels是2(图中右下角), 没有进行边界填充p=0,步长s=1, 其维度变换按照公式![]()
黄色和深黄色检测图片,得到两张4x4特征图(图中浅蓝和紫色矩阵), 将特征图视为激活函数的输入, 这里用的是ReLU, 分别得到一张计算过的4x4的矩阵, 将两个矩阵放到一起,如右下角
CNN的一个特征:
如果每个filter的元素都是一个参数, 那么还有bias_1和bias_2等等bias, 看起来参数会很多, 但也只有这些参数了, 因为原图如果是很大, 也不会影响参数的数量, 只取决于filter, 这就是避免过拟合
以L层为例,进行维度求取总结

2⃣️POOL pooling池化层
pooling翻译成池化不太容易理解, 还有个意思是“合并”, 可以将pooling层理解成合并同类元素层
pooling池化层--静态属性, 不需要 设置变量参数
作用:缩减模型大小, 提高计算速度,同时提高所提取特征的鲁棒性
pooling层根据算法不同,可以分为最大池化层, 平均池化层
max pooling 最大池化
最大值为什么呢? 就是要在任何一个象限内提取到某个特征值, 然后保留在max pooling的输出中,其实就是把卷积时的 元素相乘求和变成了 求最大值
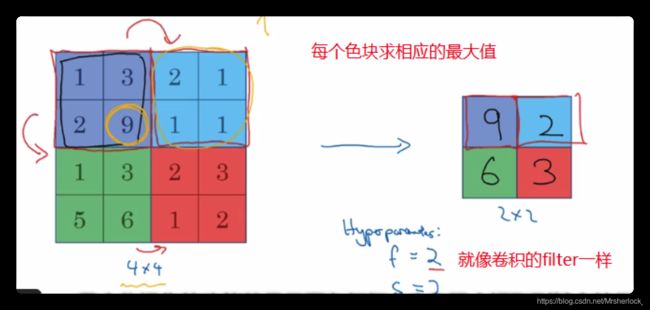
Average pooling 平均池化
一样, 就是把 元素相乘相加 改成 求平均值了
FC全链接层
全连接层就是将最后一层卷积得到的特征图(矩阵)展开成一维向量,并为分类器提供输入。
全连接层在整个网络卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话(特征提取+选择的过程),全连接层则起到将学到的特征表示映射到样本的标记空间的作用。换句话说,就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
缺点:
CNN(带有FC层)的输入图片尺寸必须是固定的, 其原因:全连接层要求固定的输入维度
(在图像预处理时需要统一resize图片的大小)
简单的CNN例子:

典型的CNN
几个典型的CNN (classic networks)
-
LeNet-5(上个世纪的)
-
AlexNet
-
VGG
-
ResNet(残差网络)(它到了152层, 并且在如何有效训练方面,总结出了很多窍门)
-
Inception
LeNet-5(主要针对的gray灰度图片)

AlexNet
这个论文让计算机视觉开始重视深度学习

VGG(VGG-16)
专注做卷积层, 简化了CNN
16是指包含了16个卷积层和全连接层, 大约有1亿多个参数,, 但是很规整, CONV层后紧跟着POOL层, 用来压缩图片, 减小图片H和W数值
论文揭示了:随着网络的加深, 图像的H和W都在以一定的规律不断缩小, 每次池化后刚好缩小一半, 而channnels不断增加, 也刚好是翻倍增加, 也就是说图片的缩小和信道的增加是有规律的

Residual Networks (ResNets) 残差网络
-
非常深的CNN是很难训练的, 存在着梯度消失和梯度爆炸的问题
-
学习一下skip connections(跳远连接), 它可以从某一网络层获取激活, 然后迅速的反馈到另一层, 甚至是最深的那一层, 我可以利用skip connection 构建能够训练CNN的ResNets, 有时可以超过100层
-
Residual block 残差块


为什么ResNets这么厉害呢???
在training set上训练好ResNet是第一步
一个网络越深, 它在训练集上训练网络的效率会有所减弱, 有了残差块就不一样了

跳远连接证明了a[l]=a[l+2], 显然后来增加的这两层没什么卵用,不会影响什么, 显然这个残差块加进去不会影响网络的传输结果
如果残差块传递过去的维度不同, 就加个参数,维持维度平衡

GOOGLE 的 Inception网络/层
先介绍1*1的卷积
这样保持了各个参数不变的情况下加入了ReLU非线性函数
这个卷积的重要性在于, 你可以根据自己想的,随便改变输出的channel数量, 并保持H和W不变

Inception网络/层
filter的参数f到底是多少, 要不要加入pool层?? 这些问题, inception给你决定, 虽然玩过架构变得复杂了, 但是表现不错
不同的filter堆叠起来, 自动选择需要哪些不同的filter

完整的inception module (注意inception就是盗梦空间的英文名)
inception做的就是将这些模块连接起来

很难通过论文来复制别人的成果, 因为涉及到了很多参数要调整,很多学者都习惯把自己成果开源放在github上, 如果你有个想法, 你可以先去开源网站看看, 能不能用别人的成果来实现, 要比你从头开始要快得多
-
如果你正在开发一个计算机视觉的应用
-
选一个你喜欢的架构
-
找一个开源的实现从GitHub上下载下来, 以此为基础开始构建
-
这样好就好在别人经过完美的训练了已经, 你可以迁移学习放在自己的项目上试试
-
-
-
迁移学习 (计算机视觉很常用)
-
不要从头开始训练权重参数之类的了, 你直接下载别人训练好的参数就行了,进展会很快, 当做预训练,然后迁移到你的任务上就行, 计算机视觉社区很喜欢把一些数据集放到网上, 比如ImageNet 和MS COCO 或者Pascal类型的数据集, 这些都有很多训练员拿来当做数据集训练过他们的算法了, 你只要把你们的公共数据集的知识迁移到自己的问题上 , 就节省了很多时间
-
看看怎么做, transfer learning迁移学习
-
你识别一些猫, 可是你的训练集很小, 没几张图片,建议先去网上把开源的实现的项目下载下来, 不仅下载代码, 也把权重下载下来, 有很多训练好的网络, 你都可以下载,
-
比如你可以去掉softmax输出层, 构建自己的softmax输出层, 因为别人的可能输出1000选几个, 你需要输出3个
-
意思就是你把除了softmax输出层外的layers都看成冻结的,只训练这一层的参数, 这样你就充分使用了吧别人在前几层训练好的权重
-
很多框架都支持你来选定专门训练哪一层的参数
-
-
-
-
-
数据增强是增强你计算机视觉系统表现的一个方法
-
计算机视觉: 输入一个图片, 解析像素, 然后弄清楚图片中有什么, 似乎你需要一个复杂方程, 数据越多越有帮助哦
-
当下计算机视觉的主要问题还是无法获得充足的数据, 对于一般的机器学习应用是可以的, 但是对于计算机视觉来说是不够的
-
因此当训练计算机模型的时候, 数据增强会有所帮助
-
-
常见的数据增强方法:
-
一张图片垂直镜像对称
-
对一张图片随机剪裁
-
当然旋转\扭曲变换都是可以的,但是太复杂了运用很少
-
色彩转换, 比如滤镜, 通常是RGB三色道进行修改参数值, 这样会使得你的系统对颜色的变换更具有robust鲁棒性
-
对RGB有不同的采样方式
-
其中一种影响色彩扭曲的算法是PCA, 即主成分分析, 有时候被称为PCA 色彩增强, 意思就是如果含红蓝比较多绿色比较少, 那么久不断增加红蓝,不怎么加绿色
-
-
-
-

-
当看到机器学习的应用时, 学习算法一般有两种知识来源
-
知识来源是一个被标记的数据, (x,y)
-
第二个是手工工程,精心设计的系统
-
正是由于数据的缺乏, 计算机视觉很大程度上以来手工工程, 所以一些网络架构很复杂,很多参数
-
-
-
大多数的计算机视觉研究者会深入研究benchmarks基准, 这样发论文比较快, 你不会真的不说一个应用程序或者生产一个系统, 你可以让人们做的事在你的基准上
第四课-CNN与目标检测
-
目标检测是计算机视觉领域的一个新兴的应用方向
-
先了解一下方向定位
-
图片分类已经懂了, 就是算法遍历图片,判断对象是不是汽车
-
定位分类:不仅要对它进行分类, 还要定位出她的位置, 用边框或者红色框圈出来, 定位就是判断汽车在图片中的具体位置
-
今天讲的分类定位问题, 就是一个图片中有大部分你要定位的东西, 只有一个object需要你识别和定位
-
-

而对象检测问题中, 图片可以包含多个对象,单张图片可以有不同的分类对象

图片分类帮助学习定位分类, 定位分类可以帮助对象检测
分类和定位
输入一个图片给CNN, 得到一个特征向量,然后交给softmax层最终得到你的预测值, 可能有车,行人, 树等等
当然这个图片也可以是已经处理过的特征图
想圈出来预测的东西, 就让你的CNN输出一组 边界框的参数, 比如左上角右上角这种参数,
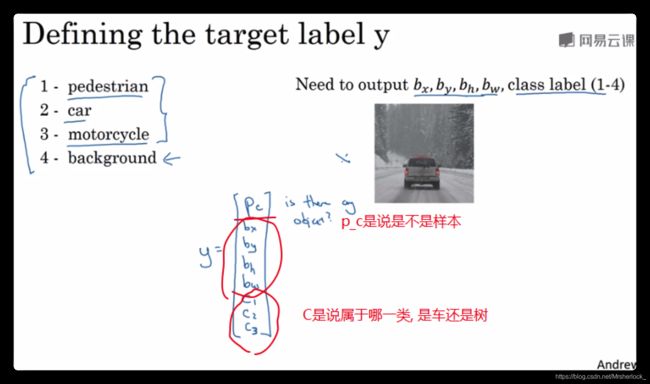
约定一下符号
training set不仅包含神经网络要预测的对象分类标签, 还包含边界框的四个数字(注意我们学的是监督学习),分别是x,y height,width

如何为监督学习任务定义目标标签y
y包含的Pc表示是不是样本, bx by bh bw是感兴趣框的位置参数, c1,c2,c3是3种类别

神经网络的损失函数L(y^, y)

构建一个检测块:(特征点检测)
把神经网络的输出的实数集看成一个回归任务(毕竟输出的也是个向量)
神经网络可以通过输出图片上特征点的(x,y)坐标来实现对目标特征的识别定位, 看几个例子:
如果你正在做一个人脸识别的应用, 你希望算法给出眼角的具体位置
你可以让CNN多输出一组特征点数值, 作为眼角坐标值
假设脸上有100个特征点, 生成包含这些特征点的标签训练集, 然后让CNN输出脸部关键特征点的位置
准备一个卷积神经网络和一些特征集, 将人脸图片输入CNN, 输出或许是1或者0, 然后再继续输出x1,y1; x2,y2 .......等等很多, 就可以框出你想要的,如果输出到x64, y64,就有 64*2+1=129个特征单元(列向量Y)
你的特征集就是包含图片和相对标签的数据集, 这些特征点都是人类辛苦标记的
注意你的输出标签要和别人标记好的保持一致, 不然就标记眼睛却说是嘴巴了

目标检测
上述是定位和特征点检测, 开始构建一个对象检测算法:
通过卷积网络convnet来进行对象检测,采用基于滑动窗口的目标检测算法
例子: 假如你想要构建一个汽车检测算法
1⃣️先创建一个标签训练集 X和Y, 表示适当剪切的汽车图片样本,(图片是个正样本, 因为他是个汽车)

2⃣️构建算法
输入图片X, convnet输出y, 0\1表示有无汽车, 训练完training set就能实现滑动窗口目标检测
sliding windows detection滑动窗口目标检测步骤:
给出特定图片:

选定一个特定大小的窗口, 当然你可以输入更大的方块比如

将这个小方块窗口输入卷积网络, 卷积网络开始预测, 就是判断红色方框内有没有汽车
小方块内有就输出1没有就0

继续移动小方块, 向右滑动,然后把方块内部的图片输入给卷积网络, 注意只是方块内部

反复很多次, 滑动过每一个角落, 就是固定步幅然后遍历图像每个区域, 就像filter一样, 每次把和小方块重叠的部分发送给convnet, 对每个位置进行01分类
sliding windows detection缺点:
-
计算成本, 剪切了太多的小方块, CNN要一个个的处理, 如果扩大方块, 就会影响你的应用性能,反之会增大计算量
-
除非使用很小的方块和很小的步长否则很难检测好
convnet的sliding windows detection的实现
讨论一下如何在卷积层上应用这个算法, 尽管他的efficiency很低
首先要会如何把CNN的全连接层转成卷积层
给一个结构如下, y改成列向量,因为要输出坐标等信息

全连接层前用400个filter来操作
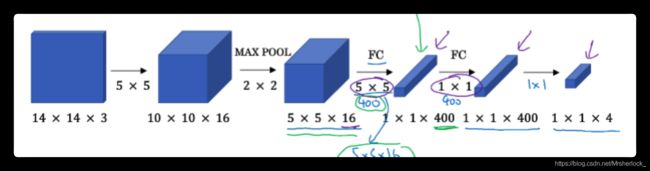
CNN实现SWD
一样的CNN的output layer就是softmax单元的输出, 只是改成了1*1*4的形式

蓝色的就是之前说的小红色方框,黄色的是待检测图片

不是让小方块把图片分成4块(这个例子是4)后, 分别逐一求, 而是一起算出来之后, 再分别输出, 而且公共部分有很多相似的区域
缺点:边界框可能不准确
Bounding Box预测
YOLO算法
就是本来是对一个图片整体来进行图像分类和对象定位的, 这次把一个图片分割成9\18\等很多个格子, 对每个各自进行之前的操作如下图:

图中的y没有写全,只写了4个颜色, 实际 是9个列向量, 例如: 第一个是y1, y1是一个8个元素的列向量,
交并比
如何判断对象检测算法运作良好呢?
交并比函数用来专门做这个评价的 intersection over union IoU函数
IoU函数就是计算两个边界框交集和并集之比

一般约定∩/∪大于等于0.5就是正确的

非极大值抑制
你的算法可能对同一个对象进行多次检测, 所以算法不是对某个对象检测一次,而是检测多次, 而非最大值抑制这个方法可以确保只检测一次for each example
非最大值就是你只输出概率最大的分类结果, 抑制那些不是最大概率的结果

Anchor Boxes
目前你只能让一个红方框内检测一个object, 如何同时检测出多个objects呢?
Anchor boxes
人工的给出两个box_1和box_2, 这两个box是不同的形状
把预测结果和这两个anchor box关联起来,一般你会定义出很多个box
把预测结果向量y, 重新定义,不再是每个格子之前那样定的
而是重复定义两次,(当然box此处是两个) 
因为人更像box1所以y中的前8个你可以认为是和人相关的元素
去检测到的对象(红色), 和box1和box2的形状对比一下(紫色),iou高的就是了,显然这个对象是分配了两个box中了
YOLO对象检测算法
构造你的training set
假设你要训练一个算法检测行人\汽车\摩托,这里有3个标签

第一个格子是输出0和0表示什么都没有, 倒数第二个格子输出0 1表示是个车
每一个格子都会去产生两个anchor box
利用非最大值抑制,抛弃iou低的, 类别不同要单独运行非最大值抑制 
RPN网络
Region Proposal Network
候选区域算法
运行卷积算法对图片每个格子同时输出时, 如果有的格子是没有任何对象的区域, 再去计算他就是浪费时间,如何避免??
R-CNN算法
带区域的卷积网络 region proposal
这个算法会选出一些区域(没有任何分类对象的区域)
图像分割法(选出候选区域)

得到右边的图片后, 对不同的色块圈起来, 跑不跑卷积算法, 看看是不是你要的

R-CNN还是很慢,R-CNN基本思想仍然是使用某种算法求出候选区域,对每个候选区域跑一跑分类器, 每个区域输出一个标签,表示有没有车\人\树等, 并输出一个方框
Fast R-CNN
Faster R-CNN
openCV中的目标检测
cascade classifier级连分类器
级联分类器
训练速度很慢,检测速度很快,可以作为一个实时检测框架,训练时往往采用5000个正样本300万个负样本人脸数据
扩展思路,只要我们通过haar和LBP特征对要检测的目标进行特征描述,我们都可以利用级联分类器进行训练,然后检测,只要你有足够的数据集,你几乎可以利用haar和LBP特征,来构造检测任何物体的级联分类器
利用的算法是AdaBoost算法,可以看蓝皮书,简单说就是几个弱分类器通过线性组合成一个强分类器,级联分类器就是把多个强分类器组合,统一命名为级联分类器,一般而言,opencv支持5-20个强分类器的级联
cv::CascadeClassifier类
openCV同样使用了抽象类对象,具体算法用方法或派生来实现的思路, 对于这个类CascadeClassifier可以存储,加载,训练级联分类器,并且提供了接口供测试调用
级联分类器在测试的时候是需要load.()一个xml文件, 这个文件存储了级联分类器的训练信息,每个级联分类器都在训练后保存一个xml文件,下次再使用时直接load该文件即可
//CascadeClassifier
CascadeClassifier (const String &filename);
//Loads a classifier from a file. More...
~CascadeClassifier ();
void detectMultiScale (InputArray image, //输入图像
std::vector< Rect > &objects, //结果boxes
double scaleFactor=1.1,
//scaleFactor 决定每个尺度之间的条件有多大将其设置为一个较大的只意味着算法可能错过某些尺寸人脸的检测为代价换取更快的计算时间。
int minNeighbors=3,
// 这个参数是对阻止错误检测的控制,实际图像中人脸的定位倾向于在同一目标获得多个命中框
//将其设置为3意味着至少存在3个重叠的框,才会认为人脸存在。
int flags=0, //忽略,opencv1.x版本才考虑
Size minSize=Size(),
//minSize和maxSize都是人脸区域的面积值,实际使用时可以过滤噪声人脸如取Size(30,30)
Size maxSize=Size());
void detectMultiScale (InputArray image,
std::vector< Rect > &objects,
std::vector< int > &numDetections,
double scaleFactor=1.1,
int minNeighbors=3,
int flags=0, Size minSize=Size(),
Size maxSize=Size());
void detectMultiScale (InputArray image,
std::vector< Rect > &objects,
std::vector< int > &rejectLevels,
std::vector< double > &levelWeights,
double scaleFactor=1.1,
int minNeighbors=3,
int flags=0, Size minSize=Size(),
Size maxSize=Size(), bool outputRejectLevels=false);
bool empty () const;
int getFeatureType () const;
Ptr< BaseCascadeClassifier::MaskGenerator > getMaskGenerator ();
void * getOldCascade ();
Size getOriginalWindowSize () const;
bool isOldFormatCascade () const;
bool load (const String &filename);//加载训练好的cascade分类器xml文件
bool read (const FileNode &node);
void setMaskGenerator (const Ptr< BaseCascadeClassifier::MaskGenerator > &maskGenerator);如何训练一个CascadeClassifier呢?
步骤:
确定数据集格式;
收集样本数据;
训练cascadeclassifer
第一步opencv_createsamples.exe获得需要的vec文件,
第二步通过openv_traincascade.exe 获得xml文件,即cascadeclassifer的训练信息文件
1⃣️数据集相关
数据集的文件存储层级,Myfaces为相对根目录
Myfaces/
Positive/
img/
face_1jpg
face_2.jpg
face_3.jpg
...
positive.dat
Negative/
img/
negativeImgBL_1.jpg
negativeImgTL_1.jpg
...
negative.txt数据集格式:
把数据集进行一个整合,正样本要是固定尺寸的人脸,负样本只要没有人脸就行了,正负样本数量1:3,最好是1万个正样本,越多越好
在training set中:
对于正样本
需要两种文件, 第一种是.jpg/.png等图片文件, 另一种是.dat文件,该文件存储关于训练图片中人脸的信息,如下:
(为了方便,可以直接摄像头获取人脸然后resize只保留人脸部分,这样bndbox的左上角全部写成0,0 bndbox的宽高就是该图片的宽高, 当然也可以使用常规数据集,这里使用前者)
//info.dat
img/01/s1.png 1 0 0 176 176
img/01/s10.png 1 0 0 105 105
// img文件夹/01类文件夹(这里是第一个人的人脸数据)/图片
// 数字1 是表示该图有1个人脸, 0 0表示对应的bndbox左上角的坐标, 176 176 是图像宽高对于负样本
也需要两种,一种是jpg/png另一种是txt文件.内容如下
//bg.txt
C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgBL_2.jpg
C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgBR_2.jpg
// 直接是在负样本文件夹中/图片
// 尺寸随便选择获取数据集
人脸数据集网上有很多,这里我只写出我自己人脸的获取和描述文件生成,构建我自己人脸的数据集 opencv提供了一些已经训练好的cascade classifier的xml文件,在“opencv3.4.10/build/etc/haarcascades/”文件夹中(安装了contrib的需要去install/etc/haarcascades/查看)
使用这个xml直接创建cv::CascadeClassifier对象
收集时用到的代码(没有封装)
#include "QtWidgetsApplication1.h"
#include
//C++头文件
#include
#include
#include
#include
#include
/*人脸数据采集部分*/
using namespace cv;
using namespace std;
//加载haar库的人脸特征数据
string haar_face_datapath = "C:/opencv/newBuild/install/etc/haarcascades/haarcascade_frontalface_alt_tree.xml";
int main(int argc, char** argv) {
VideoCapture capture(0); // open camera
if (!capture.isOpened()) {
printf("could not open camera.../n");
return -1;
}
Size S = Size((int)capture.get(CAP_PROP_FRAME_WIDTH), (int)capture.get(CAP_PROP_FRAME_HEIGHT));
//获取数据宽度高度
int fps = capture.get(CAP_PROP_FPS);
//获取图片的帧数
CascadeClassifier faceDetector;//级联分类器
faceDetector.load(haar_face_datapath);//把人脸特征加入到分类器中
Mat frame;
namedWindow("camera-demo", WINDOW_FULLSCREEN);
vector faces; //创建一个人脸目标序列
int count = 0;
fstream filePos("C:/Users/sherlock/Documents/Myfaces/Positive/positive.txt",ios::trunc|ios::_Noreplace|ios::in|ios::out);//创建文件对象, 打开时清空,不存在时创建
fstream fileNeg("C:/Users/sherlock/Documents/Myfaces/Negative/negative.txt", ios::trunc | ios::_Noreplace | ios::in | ios::out);//创建文件对象, 打开时清空,不存在时创建
//需要提前清空Myfaces文件夹
if (filePos.is_open())
{
while (capture.read(frame)) {
flip(frame, frame, 1); //防止左右颠倒
faceDetector.detectMultiScale(frame, faces, 1.1, 1, 0, Size(100, 120), Size(400, 450));//对每一帧检测到的人脸框存到vector中
for (int i = 0; i < faces.size(); i++) {
//生成正样本
Mat dst;
resize(frame(faces[i]), dst, Size(500, 500));//把每个图片都设置成同样的尺寸
rectangle(frame, faces[i], Scalar(0, 0, 255), 2, 8, 0);//绘制矩形框
//保存正样本 每次人脸样本图片宽高并不相同
imwrite(format("C:/Users/sherlock/Documents/Myfaces/Positive/img/face_%d.jpg", count), dst);
filePos << format("img/face_%d.jpg 1 0 0 %d %d\n", count, faces[i].width, faces[i].height);
//生成负样本, 个数和正样本1:4,为了方便,取该帧和正样本宽高相同的四个角
Mat dstNegTL = frame(Rect(0, 0, faces[i].width, faces[i].height));
//Mat dstNegTR = frame(Rect(0, 0, faces[i].width, faces[i].height));
//Mat dstNegBL = frame(Rect(0, 0, faces[i].width, faces[i].height));
//Mat dstNegBR = frame(Rect(0, 0, faces[i].width, faces[i].height));
imwrite(format("C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgTL_%d.jpg", count), dstNegTL);
//imwrite(format("C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgTR_%d.jpg", count), dstNegTR);
//imwrite(format("C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgBL_%d.jpg", count), dstNegBL);
//imwrite(format("C:/Users/sherlock/Documents/Myfaces/Negative/img/negativeImgBR_%d.jpg", count), dstNegBR);
fileNeg << format("img/negativeImgTL_%d.jpg\n",count);
//fileNeg << format("img/negativeImgTR_%d.jpg\n", count);
//fileNeg << format("img/negativeImgBL_%d.jpg\n", count);
//fileNeg << format("img/negativeImgBR_%d.jpg\n", count);
count++;
}
imshow("camera-demo", frame);
char c = waitKey(10);
if (c == 27) {
break;
}
}
}
else
{
cout << "no file open" << endl;
}
filePos.close();
fileNeg.close();
capture.release();
waitKey(0);
return 0;
} 2⃣️训练关于人脸(我)的cascade classifier
这里用到openCV提供的两个文件
opencv3.4.10\build\x64\vc14\bin\opencv_createsamples.exe
opencv3.4.10\build\x64\vc14\bin\openv_traincascade.exeopencv_createsamples.exe
.vec文件是正样本文件,需要opencv_createsamples.exe生成

结果:

openv_traincascade.exe
结果:

【N HR FA】
9 0.996429 0.667
N表示当前强分类器的弱分类器(即决策树)的训练得到的数量,HR表示当前强分类器的识别率,FA表示当前强分类器的错误率。我们从倒数第2行开始,此时训练得到了10棵决策树,识别率为99.6429%,错误率为66.7%,识别率满足了要求,即大于最小识别率99%,但是错误率不满足要求,即它最大错误率为50%,所以还需要继续训练,当又得到一颗决策树时,(此时有10棵决策时),识别率和错误率都满足了要求。(99.5714% > 99%,43.5% < 50%)
表示此时该级的强分类器已经得到,因为识别率和错误率都满足了要求,所以此级分类器的训练结束。
【Training until now has taken 2 days 17 hours 55 minutes 49 seconds】
表示到目前为止,训练级联分类器共用时2天17时55分49秒
问题:traincascade's error (Required leaf false alarm rate achieved. Branch training terminated.)
解析:虚警率已经达标 不再继续训练 ,这里不能说是一个错误,只能说制作出来的xml文件可能较差
解决办法:先测试一下生成的cascade.xml,如果效果没有达到你的预期,有以下几个解决方案:
1:maxfalsealarm值应该设定到0.4 - 0.5之间
2:正负样本数太少,增大样本数