比较图像相似的三种方法
转载自:https://blog.csdn.net/Alieon/article/details/97924522
前言
本来想自己写一篇总结图像相似hash算法,无意之中看到一篇博客真的是总结地很精妙。感觉自己远远不及,于是转载过来并添以补充代码实现。
原文链接:https://www.cnblogs.com/Kalafinaian/p/11260808.html
度量两张图片的相似度有许多算法,本文讲介绍工程领域中最常用的图片相似度算法之一——Hash算法。Hash算法准确的说有三种,分别为平均哈希算法(aHash)、感知哈希算法你(pHash)和差异哈哈希算法(dHash)。
三种Hash算法都是通过获取图片的hash值,再比较两张图片hash值的汉明距离来度量两张图片是否相似。两张图片越相似,那么两张图片的hash数的汉明距离越小。下面本文将分别介绍这三种Hash算法。
一,平均哈希算法(aHash)
1.1 算法步骤
平均哈希算法是三种Hash算法中最简单的一种,它通过下面几个步骤来获得图片的Hash值,这几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 算像素均值;(4)根据相似均值计算指纹。具体算法如下所示:
| 步骤 | 具体内容 |
|---|---|
| 缩放图片 | 输入图片大小尺寸各异,为了统一图片的输入,统一将图片尺寸缩放为8*8,一共得到了64个像素点。 |
| 转灰度图 | 输入图片有些为单通道灰度图,有些RGB三通道彩色图,有些为RGBA四通道彩色图。也为了统一下一步输入标准,将非单通道图片都转为单通道灰度图。 |
| 算像素均值 | 通过上一步可得一个8x8的整数矩阵G,计算这个矩阵中所有元素的平均值,假设其值为a |
| 据像素均值计算指纹 | 初始化输入图片的ahash = “” 。从左到右一行一行地遍历矩阵G每一个像素如果第i行j列元素G(i,j) >= a,则ahash += "1"如果第i行j列元素G(i,j) |
得到图片的ahash值后,比较两张图片ahash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
1.2 具体实例
图片以Lena为例:
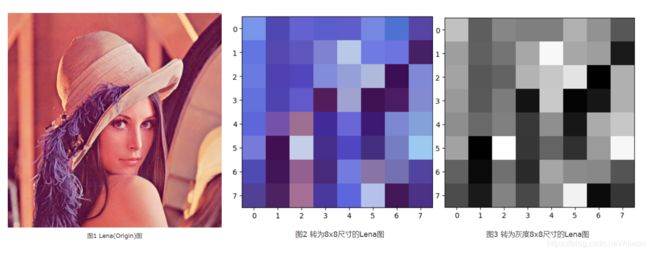
其中转为8x8尺寸的灰度Lena对应的数据矩阵为:
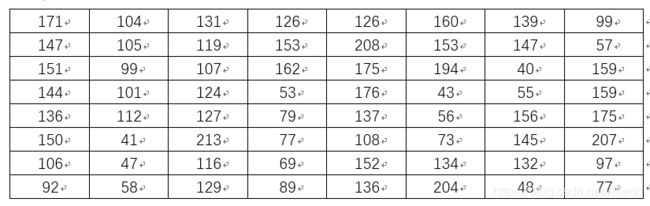
得到如上矩阵所有元素的均值a= 121.328125, 将上述矩阵中大于或等于a的元素置为1, 小于a的元素置为0,可得:
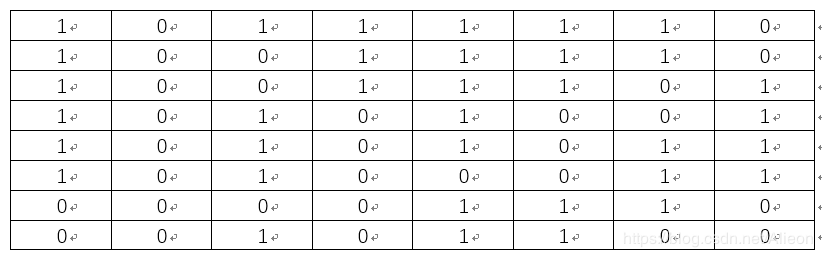
所以可得Lena图的aHash为:
1011111010011110100111011010100110101011101000110000111000101100
为了测试aHash算法的效果,我们用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验,其中Lena(noise)和Barbara如下:

通过aHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:
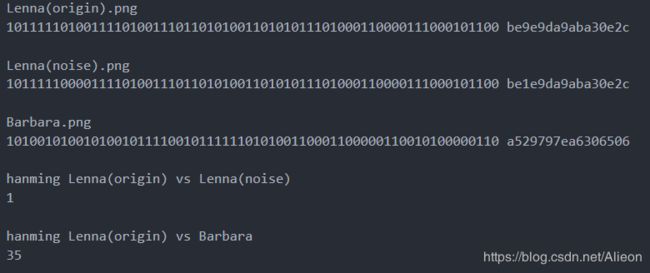
由上图可见aHash能区别相似图片和差异大的图片。
1.3 (补充)代码实现
用C++来实现算法如下:
string aHashValue(Mat& src) { Mat img; string rst(64); double dldex[64]; double mean = 0.0; int k = 0;if (src.channels() == 3) { cvtColor(src, src, CV_BGR2GRAY); } img = Mat_<double>(src); // 缩放尺寸 resize(img, img, Size(8, 8)); // 计算平均像素 for (int i = 0; i < 8; i++) { for (int j = 0; j < 8; j++) { dldex[k] = img.at<double>(i, j); mean += img.at<double>(i, j) / 64; k++; } } // 计算哈希值 for (int i = 0; i < 64; i++) { if (dldex[i] >= mean) { rst[i] = "1"; } else { rst[i] = "0"; } } return rst;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
二,感知哈希算法(pHash)
2.1 算法步骤
感知哈希算法是三种Hash算法中较为复杂的一种,它是基于DCT(离散余弦变换)来得到图片的hash值(补充:关于DCT具体如何转换参考 https://www.jianshu.com/p/b923cd47ac4a ),其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 计算DCT;(4)缩小DCT; (5)算平均值;(6) 计算指纹。具体算法如下所示:
| 步骤 | 具体内容 |
|---|---|
| 缩放图片 | 统一将图片尺寸缩放为32*32,一共得到了1024个像素点。 |
| 转灰度图 | 统一下一步输入标准,将非单通道图片都转为单通道灰度图。 |
| 计算DCT | 计算32x32数据矩阵的离散余弦变换后对应的32x32数据矩阵 |
| 缩小DCT | 取上一步得到32x32数据矩阵左上角8x8子区域 |
| 算平均值 | 通过上一步可得一个8x8的整数矩阵G, 计算这个矩阵中所有元素的平均值,假设其值为a |
| 计算指纹 | 初始化输入图片的phash = “”。从左到右一行一行地遍历矩阵G每一个像素,如果第i行j列元素G(i,j) >= a,则phash += “1”;如果第i行j列元素G(i,j) |
得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
(补充:为什么缩小DCT只需要取左上角的8x8区域呢?简单来说,经过DCT变换后数值主要集中在左上角,而右下角的像素基本为0,被称为高频区域。变换后数据量会变得很小,这也是DCT的优点所在。)
2.2 具体实例
仍用Lena图为例:

通过计算可得灰度32x32Lenna图对应的DCT矩阵左上角8x8区域子矩阵为:
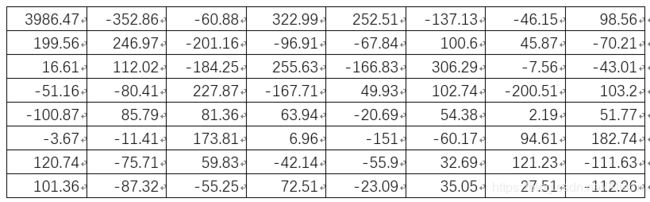
得到如上矩阵所有元素的均值a= 77.35, 将上述矩阵中大于或等于a的元素置为1, 小于a的元素置为0,可得:
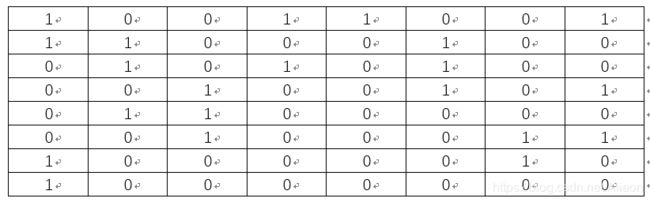
所以可得Lena图的pHash为:
1001100111000100010101000010010101100000001000111000001010000000
为了测试pHash算法的效果,同样用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验。通过pHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:
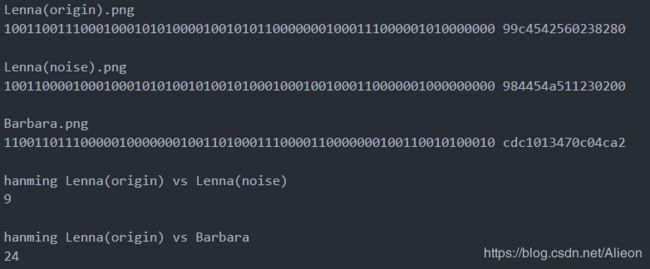
由上图可见pHash能区别相似图片和差异大的图片。
2.3 (补充)代码实现
string pHashValue(Mat& src) { Mat img, dst; string rst(64); double dldex[64]; double mean = 0.0; int k = 0;if (src.channels() == 3) { cvtColor(src, src, CV_BGR2GRAY); } img = Mat_<double>(src); // 缩放尺寸 resize(img, img, Size(32, 32)); // 离散余弦变换,DCT系数求取 dct(img, dst); // 取DCT系数均值(取左上角的8x8低频区域) for (int i = 0; i < 8; i++) { for (int j = 0; j < 8; j++) { dldex[k] = dst.at<double>(i, j); mean += dst.at<double>(i, j) / 64; k++; } } // 计算哈希值 for (int i = 0; i < 64; i++) { if (dldex[i] >= mean) { rst[i] = "1"; } else { rst[i] = ""0; } } return rst;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
三,差异哈希算法(dHash)
3.1 算法步骤
相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。其算法几个步骤分别是(1) 缩放图片(2)转灰度图; (3)算差异值;
(4)算平均值; (5)计算指纹。具体算法如下所示:
| 步骤 | 具体内容 |
|---|---|
| 缩放图片 | 统一将图片尺寸缩放为9x8,一共得到了72个像素点。 |
| 转灰度图 | 统一下一步输入标准,将非单通道图片都转为单通道灰度图。 |
| 算差异值 | 当前行像素值-前一行像素值, 从第二到第九行共8行,又因为矩阵有8列,所以得到一个8x8差分矩阵G |
| 算平均值 | 通过上一步可得一个8x8的整数矩阵G, 计算这个矩阵中所有元素的平均值,假设其值为a |
| 计算指纹 | 初始化输入图片的dhash = “”。从左到右一行一行地遍历矩阵G每一个像素,如果第i行j列元素G(i,j) >= a,则dhash += “1”;如果第i行j列元素G(i,j) |
得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
3.2 具体实例
仍用Lena图为例:
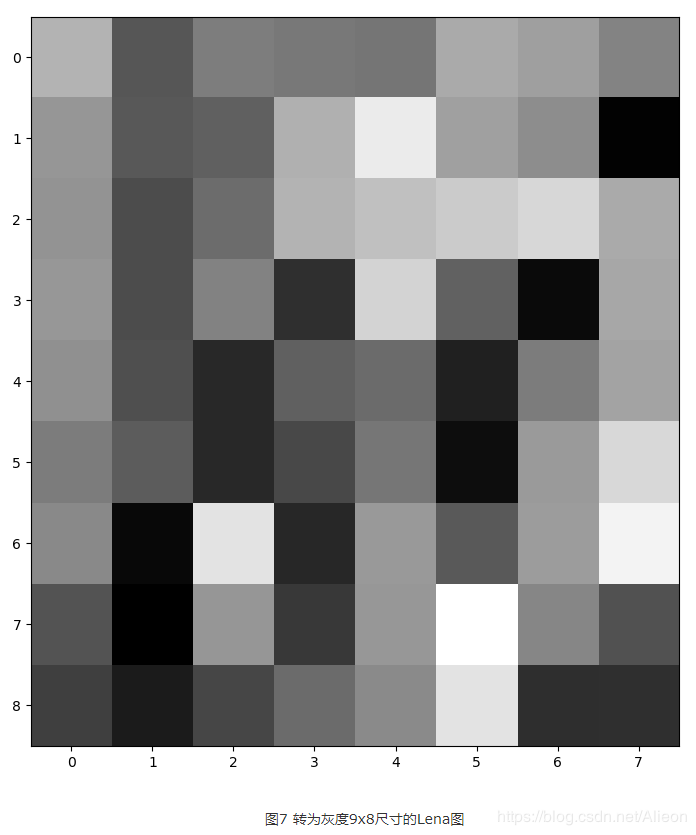
通过计算可得灰度9x8Lenna图数据矩阵的8x8差分矩阵为:
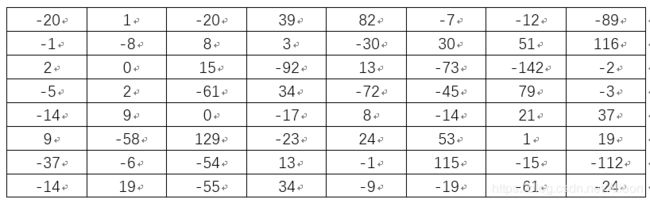 将上述矩阵中大于或等于0元素置为1, 小于a的元素置为0,可得:
将上述矩阵中大于或等于0元素置为1, 小于a的元素置为0,可得:
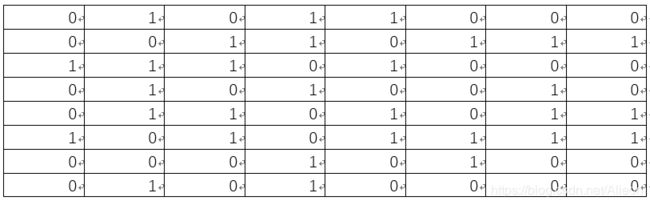
所以可得Lena图的dHash为:
0101100000110111111010000101001001101011101011110001010001010000
为了测试dHash算法的效果,同样用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验。通过pHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:
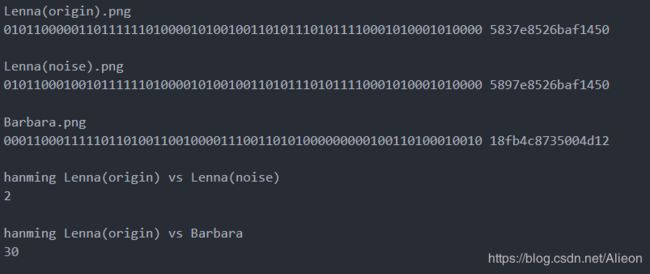
由上图可见dHash能区别相似图片和差异大的图片。
3.3 (补充)代码实现
string dHashValue(Mat& src) { Mat img; string rst(64); double dldex[64]; double mean = 0.0; int k = 0;if (src.channels() == 3) { cvtColor(src, src, CV_BGR2GRAY); } img = Mat_<double>(src); // 缩放尺寸 resize(img, img, Size(8, 9)); imshow("test", img); waitKey(0); // 计算平均像素 for (int i = 0; i < 8; i++) { for (int j = 0; j < 8; j++) { dldex[k] = img.at<double>(i+1, j)-img.at<double>(i,j); mean += dldex[k] / 64; k++; } } // 计算哈希值 for (int i = 0; i < 64; i++) { if (dldex[i] >= mean) { rst[i] = "1"; } else { rst[i] = "0"; } } return rst;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
四,总结
关于图像相似度算法除了Hash算法,在传统算法领域中还有基于SIFT的匹配算法,基于Gist特征的匹配算法;在深度学习领域中有基于ResNet全连接的匹配算法。感兴趣的读者可以通过google来了解这些算法。