R语言线性模型与广义线性模型—建立预测保险费用模型
目录
数据预处理
读取insurance.csv中的数据
声明各变量类型,并将数据储存为R数据框
对因变量charges进行对数转换
查看各分类变量的频数表
随机抽取70%的观测放入学习数据集,剩余30%放入测试数据集。
将学习数据集和测试数据集存入.csv 文件。
使用线性模型
根据学习数据集建立线性模型
查看模型诊断图并点评
计算线性模型对测试数据集中保险费用预测的均方根误差。
使用Iasso模型
根据学习数据集建立Iasso模型,使用交叉验证选择调节参数。
计算 Lasso 模型对测试数据集中保险费用预测的均方根误差。
使用随机森林进行预测
直接上随机森林
对测试数据集中保险费用预测的均方根误差。
项目源码:
数据预处理
读取insurance.csv中的数据
insurance<- read.csv(file="E:\\R\\TEST\\insurance.csv",header=T,fileEncoding = "utf-8")
声明各变量类型,并将数据储存为R数据框
数据预处理把所有的字符变成数字形式,以方便我们进行回归预测
sex,性别,取值为“Female”(0)和“Male”(1)
smoker是否是吸烟者,取值为“Yes”(1)和“No”(0)
region地区,取值为“northeast”(1)、“northwest”(2)、“southeast”(3)、"southwest”(4)
for(i in 1:length(insurance$sex)){if(insurance$sex[i]=='female'){insurance$sex[i]=as.numeric(0)}}
for(i in 1:length(insurance$sex)){if(insurance$sex[i]=='male'){insurance$sex[i]=as.numeric(1)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='northeast'){insurance$region[i]=as.numeric(1)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='northwest'){insurance$region[i]=as.numeric(2)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='southeast'){insurance$region[i]=as.numeric(3)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='southwest'){insurance$region[i]=as.numeric(4)}}
for(i in 1:length(insurance$smoker)){if(insurance$smoker[i]=='yes'){insurance$smoker[i]=as.numeric(1)}}
for(i in 1:length(insurance$smoker)){if(insurance$smoker[i]=='no'){insurance$smoker[i]=as.numeric(0)}}
但是存在一个问题:
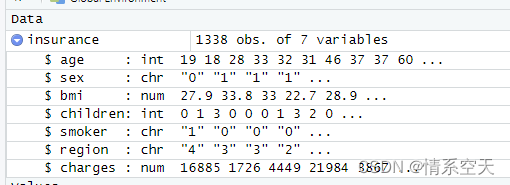
不是数值类型,所以要强制转换为数值类型:
insurance=as.data.frame(lapply(insurance,as.numeric))
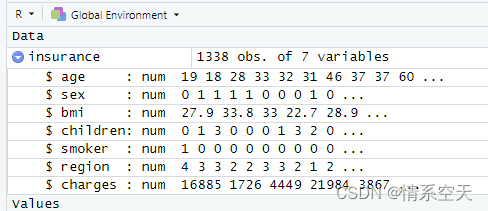
成功转换
对因变量charges进行对数转换
自建一个函数用来进行对数转换
signedlog10 = function(x) {
ifelse(abs(x) <= 1, 0, sign(x)*log10(abs(x)))
}
insurance$charges = signedlog10(insurance$charges)

转换成功
查看各分类变量的频数表
mytable<-with(insurance,table(charges))
prop.table(mytable)
mytable<-with(insurance,table(children))
prop.table(mytable)
mytable<-with(insurance,table(sex))
prop.table(mytable)
mytable<-with(insurance,table(bmi))
prop.table(mytable)
mytable<-with(insurance,table(region))
prop.table(mytable)
mytable<-with(insurance,table(smoker))
prop.table(mytable)
mytable<-with(insurance,table(age))
prop.table(mytable)






声明各变量类型:
保险费用 = insurance$charges
年龄 = insurance$age
性别 = insurance$sex
身体健康指数 = insurance$bmi
子女数量 = insurance$children
是否吸烟= insurance$smoker
地区 = insurance$region
d=data.frame(年龄,性别,身体健康指数,子女数量,地区,是否吸烟,保险费用)


相关度分析cor(d)

library(psych)
描述性统计
des <- describe(insurance)

随机抽取70%的观测放入学习数据集,剩余30%放入测试数据集。
train <- sample(nrow(insurance), 0.7*nrow(insurance))
insurance.train <- insurance[train,]
insurance.test <-insurance[-train,]

将学习数据集和测试数据集存入.csv 文件。
write.table(insurance.train,"insurance_train.csv",row.names=FALSE,col.names=TRUE,sep=",")
write.table(insurance.test,"insurance_test.csv",row.names=FALSE,col.names=TRUE,sep=",")
使用线性模型
根据学习数据集建立线性模型
lm.sol=lm(保险费用~年龄+性别+身体健康指数+子女数量+地区+是否吸烟,data=insurance.train)
summary(lm.sol)

根据图表得出公式:
yuce=insurance.test$age*0.0150507+insurance.test$sex*-0.0327203+0.0053343*insurance.test$bmi+0.0444696*insurance.test$children+-0.0206753*insurance.test$region+0.6730863*insurance.test$smoker+3.0798527
查看模型诊断图并点评



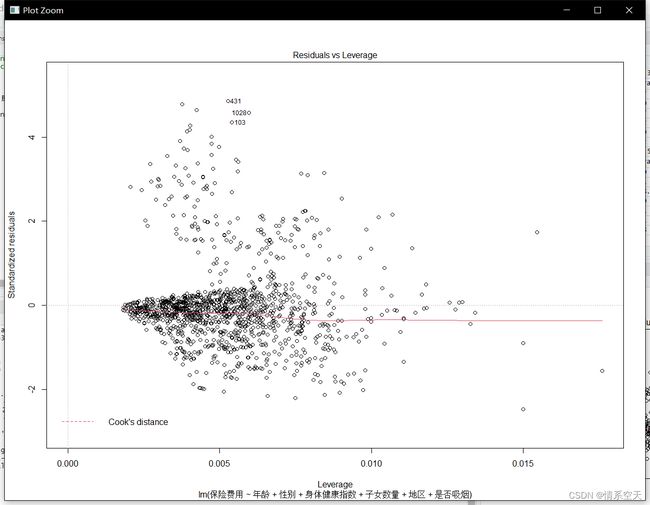
查看观测值的离群点:103 431 1028
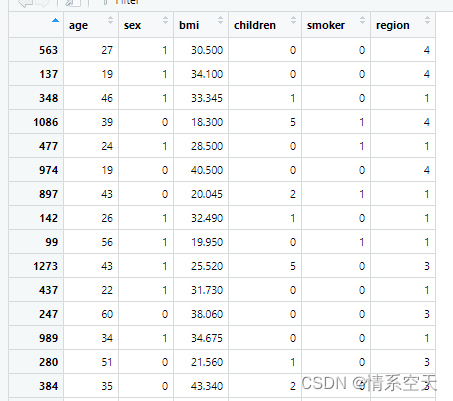
insurance[c(103,431,1028),1:7]

本应该删除这些离群值,但是分析发现,并不对本数据构成很大的影响,反而有助于帮助我们分析观测预测
计算线性模型对测试数据集中保险费用预测的均方根误差。
yuces= data.frame(zhenshi,yuce)
fit=lm(zhenshi~yuce)
sqrt(mean(fit$residuals^2))

方差值很低,证明预测效果好
预测结果如下:


使用Iasso模型
根据学习数据集建立Iasso模型,使用交叉验证选择调节参数。
编写相应函数:
A<-as.matrix(insurance.train[,1:6])
B<-as.matrix(insurance.test[,1:6])
转换为矩阵

计算 Lasso 模型对测试数据集中保险费用预测的均方根误差。
f1 = glmnet(x=A,y=insurance.train$charges,family="gaussian", nlambda=100, alpha=1) #这里alpha=1为LASSO回归,如果等于0就是岭回归
#参数 family 规定了回归模型的类型:
#family="gaussian" 适用于一维连续因变量(univariate)
#family="mgaussian"适用于多维连续因变量(multivariate)
#family="poisson" 适用于非负次数因变量(count)
#family="binomial" 适用于二元离散因变量(binary)
#family="multinomial" 适用于多元离散因变量(category)
#我们这里结局指标是2分类变量,所以使用binomial
print(f1)#把f1结果输出可以看到随着lambdas增加,自由度和残差减少,最小lambda为0.000913
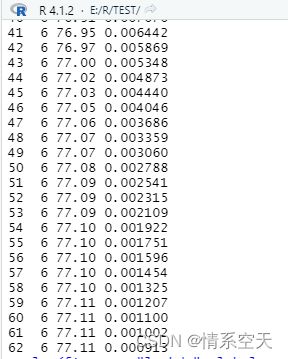
输出图形
plot(f1, xvar="lambda", label=TRUE)
横坐标为随着lambdas的对数,纵坐标为变量系数,可以看到随着lambdas增加变量系数不断减少,部分变量系数变为0(等于没有这个变量了)
下面进行交叉验证

然后通过glmnet自带函数进行交叉检验,并输出图形
cvfit=cv.glmnet(A,y=insurance.train$charges)
plot(cvfit)
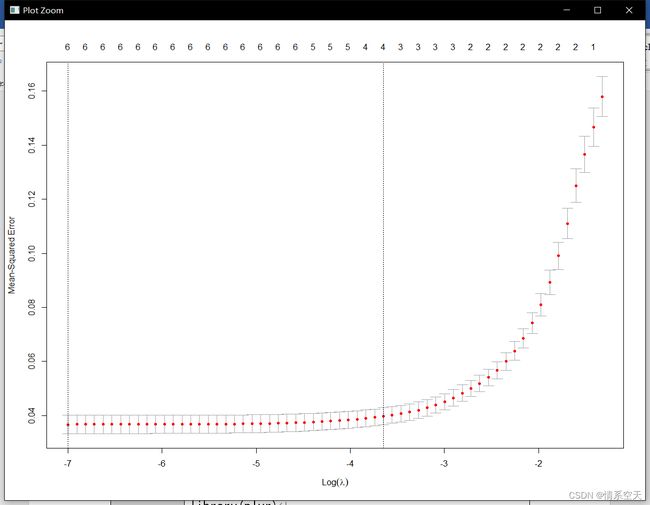
虚线是均方误差最小时的λ值
cvfit$lambda.min#求出最小值
cvfit$lambda.1se#求出最小值一个标准误的λ值

第一个有缺省值我们忽略
得出公式
yuce=insurance.test$age*0.014915656+insurance.test$sex*-0.024815476+0.004887561*insurance.test$bmi+0.047083988*insurance.test$children+-0.020269303*insurance.test$region+0.6730863*insurance.test$smoker+3.086221324
zhenshi=insurance.test$charges
yucess= data.frame(zhenshi,yuce)
fit=lm(zhenshi~yuce)

方差值很低,证明预测效果好
预测结果:


使用随机森林进行预测
直接上随机森林
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 100) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(4) #设置上面的任务数,几折就是几个任务
for (i in 1:4){
train <- insurance.train #刚才通过cvgroup生成的函数
test <- insurance.test
model <-randomForest(charges~.,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -charges)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =charges),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}

对测试数据集中保险费用预测的均方根误差。
fit=lm(temp$charges~temp$prediction)
sqrt(mean(fit$residuals^2))

方差值更低,效果更好
预测结果:

项目源码:
insurance<- read.csv(file="E:\\R\\TEST\\insurance.csv",header=T,fileEncoding = "utf-8")
for(i in 1:length(insurance$sex)){if(insurance$sex[i]=='female'){insurance$sex[i]=as.numeric(0)}}
for(i in 1:length(insurance$sex)){if(insurance$sex[i]=='male'){insurance$sex[i]=as.numeric(1)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='northeast'){insurance$region[i]=as.numeric(1)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='northwest'){insurance$region[i]=as.numeric(2)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='southeast'){insurance$region[i]=as.numeric(3)}}
for(i in 1:length(insurance$region)){if(insurance$region[i]=='southwest'){insurance$region[i]=as.numeric(4)}}
for(i in 1:length(insurance$smoker)){if(insurance$smoker[i]=='yes'){insurance$smoker[i]=as.numeric(1)}}
for(i in 1:length(insurance$smoker)){if(insurance$smoker[i]=='no'){insurance$smoker[i]=as.numeric(0)}}
insurance=as.data.frame(lapply(insurance,as.numeric))
signedlog10 = function(x) {
ifelse(abs(x) <= 1, 0, sign(x)*log10(abs(x)))
}
insurance$charges = signedlog10(insurance$charges)
mytable<-with(insurance,table(charges))
prop.table(mytable)
mytable<-with(insurance,table(children))
prop.table(mytable)
mytable<-with(insurance,table(sex))
prop.table(mytable)
mytable<-with(insurance,table(bmi))
prop.table(mytable)
mytable<-with(insurance,table(region))
prop.table(mytable)
mytable<-with(insurance,table(smoker))
prop.table(mytable)
mytable<-with(insurance,table(age))
prop.table(mytable)
保险费用 = insurance$charges
年龄 = insurance$age
性别 = insurance$sex
身体健康指数 = insurance$bmi
子女数量 = insurance$children
是否吸烟= insurance$smoker
地区 = insurance$region
d=data.frame(年龄,性别,身体健康指数,子女数量,地区,是否吸烟,保险费用)
cor(d)
library(psych)
des <- describe(insurance)
train <- sample(nrow(insurance), 0.7*nrow(insurance))
insurance.train <- insurance[train,]
insurance.test <-insurance[-train,]
write.table(insurance.train,"insurance_train.csv",row.names=FALSE,col.names=TRUE,sep=",")
write.table(insurance.test,"insurance_test.csv",row.names=FALSE,col.names=TRUE,sep=",")
#多元线性回归预测
lm.sol=lm(保险费用~年龄+性别+身体健康指数+子女数量+地区+是否吸烟,data=insurance.train)
summary(lm.sol)
yuce=insurance.test$age*0.0150507+insurance.test$sex*-0.0327203+0.0053343*insurance.test$bmi+0.0444696*insurance.test$children+-0.0206753*insurance.test$region+0.6730863*insurance.test$smoker*+3.0798527
zhenshi=insurance.test$charges
plot(lm.sol)
insurance[c(103,431,1028),1:7]
yuces= data.frame(zhenshi,yuce)
fit=lm(zhenshi~yuce)
sqrt(mean(fit$residuals^2))
#随机森林交叉验证
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 100) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(4) #设置上面的任务数,几折就是几个任务
for (i in 1:4){
train <- insurance.train #刚才通过cvgroup生成的函数
test <- insurance.test
model <-randomForest(charges~.,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -charges)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =charges),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}
write.table(temp,"yuce.csv",row.names=FALSE,col.names=TRUE,sep=",")
temp
fit=lm(temp$charges~temp$prediction)
sqrt(mean(fit$residuals^2))
library('glmnet')
######################
A<-as.matrix(insurance.train[,1:6])
B<-as.matrix(insurance.test[,1:6])
f1 = glmnet(x=A,y=insurance.train$charges,family="gaussian", nlambda=100, alpha=1) #这里alpha=1为LASSO回归,如果等于0就是岭回归
#参数 family 规定了回归模型的类型:
#family="gaussian" 适用于一维连续因变量(univariate)
#family="mgaussian"适用于多维连续因变量(multivariate)
#family="poisson" 适用于非负次数因变量(count)
#family="binomial" 适用于二元离散因变量(binary)
#family="multinomial" 适用于多元离散因变量(category)
#我们这里结局指标是2分类变量,所以使用binomial
print(f1)#把f1结果输出
plot(f1, xvar="lambda", label=TRUE)
predict(f1, newx=B, type = "response")
cvfit=cv.glmnet(A,y=insurance.train$charges)
plot(cvfit)
cvfit$lambda.min#求出最小值
cvfit$lambda.1se#求出最小值一个标准误的λ值
l.coef2<-coef(cvfit$glmnet.fit,s=0.0009130997,exact = F)
l.coef1<-coef(cvfit$glmnet.fit,s=0.02369516,exact = F)
l.coef1
l.coef2
yuce=insurance.test$age*0.014915656+insurance.test$sex*-0.024815476+0.004887561*insurance.test$bmi+0.047083988*insurance.test$children+-0.020269303*insurance.test$region+0.6730863*insurance.test$smoker+3.086221324
zhenshi=insurance.test$charges
yucess= data.frame(zhenshi,yuce)
fit=lm(zhenshi~yuce)
sqrt(mean(fit$residuals^2))