SA-VQA: Structured Alignment of Visual and Semantic Representations for Visual Question Answering
视觉问答中视觉和语义的结构化对齐
摘要
以前的方法广泛使用实体级别的对齐,例如视觉区域与其语义标签之间的关联,或者问题词和对象特征之间的交互。这些尝试旨在改善跨模态表征,而忽略其内部关系。相反,本文应用结构化对齐,将视觉和文本内容用图来表示,旨在捕捉视觉和文本模式之间的深层联系。
为结构化对齐而进行表示和集成graph是非常重要的。本文首先首先将不同模态实体转换为序列节点和邻接图,然后将其合并用于结构化对齐来解决这个问题。实验结果表明,这种结构化对齐提高了推理性能。此外,我们的模型对每个生成的答案都具有更好的解释性。
介绍
挑战:如何对齐结构化场景图、视觉内容和问题中的特征,以及如何从中推断答案。

在 Transformer 结构中引入图结构信息来指导学习,借助结构化信息,即使在有限的训练数据下,也可以学习视觉和文本表示之间的深度对齐。
贡献:
提出了一种新的用于视觉问答的视觉和语义结构化对齐模型(SA-VQA),该模型能够从视觉和文本内容中学习相关性。
使用graph的挑战还有图像缺乏语言结构和语法规则
方法

方法概述:
首先,检测对象,包括对象标签、对象属性及其关系。然后,构造了三个不同的图,即语义图、视觉图和问题图。作者认为语义图和视觉图是互补的,语义图加速了结构化特征的集成,视觉图形提供了补充信息(这些信息可能会在语义图中错位)。问题图进一步允许推断去关注问题中的嵌入。
图的构建:
语义图:

将实体和属性都看作是节点,构成节点序列 ![]() 和相应的临接矩阵
和相应的临接矩阵 ![]() 。节点特征序列
。节点特征序列![]() 是由 MLP 处理节点序列
是由 MLP 处理节点序列 ![]() 的 GloVe 嵌入得到的。
的 GloVe 嵌入得到的。
bounding box标签候选的超节点选择(SNS)
使用现成的对象和属性模型(BUTD)来发现用于构造语义图的节点和边。然而不准确的对象和属性将导致较低的语义图,可能会对模型的学习造成误导。为了减少交叉语义图的影响,对每一个候选 bounding box ( 被视作超节点 )使用所有 top-K 预测结果。超节点覆盖了所有冗余的对象节点,并且对象的召回率也很高。
但是每个超节点也引入了噪声和不相关的信息,需要额外的机制来选择与给定问题最相关的信息。一种解决方案是学习为超节点中的每个对象分配不同的权重,然后超节点的语义特征 ( ![]() )可以表示为集合中每个对象的加权语义特征
)可以表示为集合中每个对象的加权语义特征 

因此,可以按照之前的步骤来构建具有超节点的图。
超节点选择:设计目标是为符合ground truth的对象标签分配更大的权重,为其他对象分配更小的权重。为了实现这一点,本文设计了两个并行的任务:
1)首先是使top-K语义特征比其他不在top-K集中的语义特征要更接近第i个对象区域的视觉特征。本文将这种任务看作是多示例学习( Multiple Instance Learning (MIL) ),使用MIL-NCE来执行这项任务,正候选是top-K的特征,而负候选是从对象词汇表中随机抽取的对象标签![]() 的语义特征。
的语义特征。
2)这是为超节点集![]() 中的节点设计的,目的是将ground truth的语义特征比top-K中的其他语义特征更靠近视觉对象区域特征。使用对比损失作为损失函数,其中正样本是ground truth,top-K集中的其他样本是负样本。
中的节点设计的,目的是将ground truth的语义特征比top-K中的其他语义特征更靠近视觉对象区域特征。使用对比损失作为损失函数,其中正样本是ground truth,top-K集中的其他样本是负样本。
另外,还计算了加权的语义特征 ![]() 和ground truth的语义特征
和ground truth的语义特征 ![]() 的L2距离,以进一步帮助学习每个超节点中的权重。总之,在 SNS 中的目标是通过最小化一下损失函数来获得最佳视觉特征
的L2距离,以进一步帮助学习每个超节点中的权重。总之,在 SNS 中的目标是通过最小化一下损失函数来获得最佳视觉特征  和语义特征 。
和语义特征 。

视觉图:
为了嵌入图像的视觉特征,还构建了视觉图,节点是由Faster R-CNN提取的区域特征,构建的视觉图是一种全连接图,它包含了冗余连接,旨在补偿语义图中错误连接和丢失连接。
视觉图的构建比较简单,包含了M个检测到的特征序列 ![]() 和全连接的邻接矩阵
和全连接的邻接矩阵![]()
问题图:
使用解析树来生成问题图,使用GloVe和MLP来表示每一个节点,对应的二元邻接矩阵![]() 表示解析树的边。
表示解析树的边。
结构化表示的集成
结构化对齐的注意力学习

本文试图结合结构化的图特征帮助注意力模块的学习,本文认为外部的图特征即使不完整或者不准确,仍然可以缩小注意力模块的搜索空间。因此,即使在有限的训练数据下,它也能够学习特征之间的关系。其中,注意力的计算将图作为额外的约束:

视觉Transformer(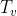 )
)
输入序列特征 ![]() 来自视觉图和问题图,
来自视觉图和问题图, ![]() 的图约束有三种类型:问题邻接矩阵
的图约束有三种类型:问题邻接矩阵 ![]() ,跨模态掩模
,跨模态掩模 ![]() 和视觉邻接矩阵
和视觉邻接矩阵 ![]() 。
。
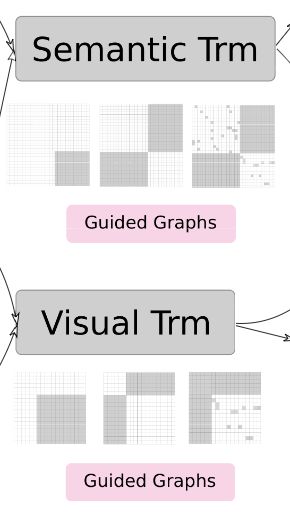
一共分为三种:首先只使用 region2 来引导更好的问题嵌入,然后将 region3 和 region4 设置为全1,这迫使编码器从图像和问题中学习特征之间的交叉注意力,最后包含了4个区域,这使得编码器关注视觉图和问题图中现有的连通性。
语义Transformer(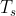 )
)
和视觉Transformer类似,输入序列特征是来自语义图和问题图。
输出表示
该模型有来自 ![]() 和 的两个输出流,分别计算视觉和语义流的交叉熵损失,还使用了早期融合和晚期融合的策略来融合两种类型的特征进行分类。
和 的两个输出流,分别计算视觉和语义流的交叉熵损失,还使用了早期融合和晚期融合的策略来融合两种类型的特征进行分类。
