用Python实现小组排名
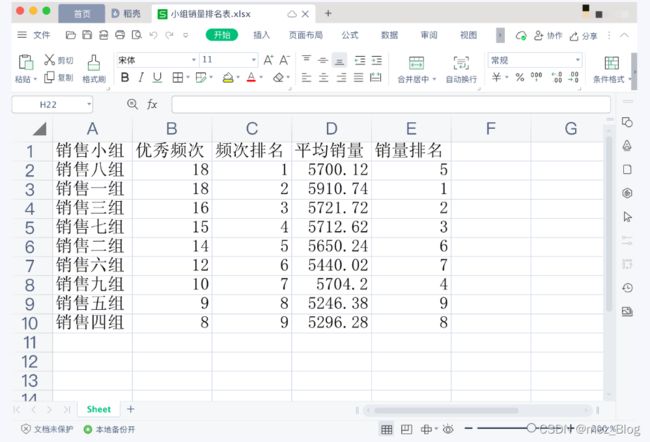
我们要依据【等级一销售表.xlsx】和【销售总表.xlsx】对各小组进行优秀频次排名及平均销量排名,并将排名结果保存为【小组销量排名表.xlsx】,需要学习的新知识点有 2 个,分别是list.index()和dict.items()。
 我们要实现
我们要实现小组排名功能,可以拆解为以下 3 个小步骤,
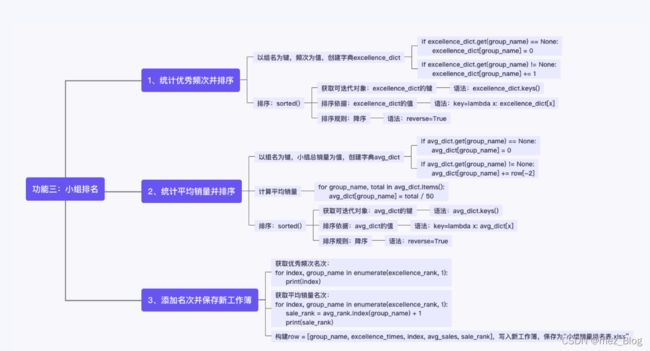
1)统计【等级一销售表.xlsx】中各个小组人员数量,并按照数量对各个小组做排序;
2)统计并计算【销售总表.xlsx】中各个小组的平均销量,根据平均销量对各个小组做排序;
3)创建新工作簿,写入表头“销售小组”、“优秀频次”、“频次排名”、“平均销量”、“销量排名”,根据“优秀频次”和“平均销量”的排序结果添加名次,将新表保存成【小组销量排名表.xlsx】。

2 小组排名
2.1 统计优秀频次并排序
关于“优秀频次”的定义,在前面的时候就有介绍,即【等级一销售表.xlsx】中各小组出现的频次。
每个小组都应该有对应的频次,因此我们可以用键值对的形式去保存这种一一对应的关系,即将小组名称作为键,频次数量作为值。
由于一开始我们也不知道频次数量,需要进行统计。因此在开始计数之前需要先定义一个空字典 excellence_dict,然后通过读取表格数据,累加出现的频次,以此得到各小组的优秀频次。
注意,这里在新建键值对的时候不需要手动写 9 次,下面会教大家一个小技巧。
get() 这个用法,如果 dict.get(key) 返回的结果是 None,表明 key 键不在字典中,如果 dict.get(key) 返回的结果不为 None,则表示 key 键在字典中,此时 dict.get(key) 等价于dict[key]。
# 定义字典
dict_test = {'A': 1, 'B': 2, 'C': 3}
# 'C'键存在
print(dict_test.get('C'))
# 'D'键不存在
print(dict_test.get('D')) 
因为 'C' 键存在,所以 dict_test.get('C') 相当于 dict_test['C'] ,直接打印 3,而 'D' 键不存在,打印结果是 None。
# 定义字典
dict_test = {'A': 1, 'B': 2, 'C': 3}
# 判断'D'键是否存在,若不存在,新增键值对'D':0
if 'D' not in dict_test:
dict_test['D']=0
print(dict_test)# 定义字典
dict_test = {'A': 1, 'B': 2, 'C': 3}
# 判断'D'键是否存在,若不存在,新增键值对'D':0
if dict_test.get('D') == None:
dict_test['D'] = 0
print(dict_test)
回到项目本身,要新建 9 个键值对,首先打开【等级一销售表.xlsx】,从第 2 行开始遍历,取出每一行的第二项,即组名,赋值给变量 group_name,然后判断 excellence_dict.get(group_name) 是否为 None。
如果 excellence_dict.get(group_name) == None ,代表字典中不存在变量 group_name 对应的键,我们就要初始化 excellence_dict[group_name] = 0 ,完成新键值对的添加。
添加完键值对,就要开始统计优秀频次了,这一步的逻辑是在循环中每读取到一次 group_name,则 group_name 键对应的频次就加1
from openpyxl import load_workbook
# 读取销售总表
wb = load_workbook('./等级销售表/等级一销售表.xlsx')
sheet = wb.active
# 初始化一个优秀频次字典
excellence_dict = {}
# 遍历数据
for row in sheet.iter_rows(min_row=2, values_only=True):
# 取出组名
group_name = row[1]
# 判断该组在字典中存不存在,不存在则初始化为0
if excellence_dict.get(group_name) == None:
excellence_dict[group_name] = 0
# 给该组计数加一
excellence_dict[group_name]+=1
print(excellence_dict) 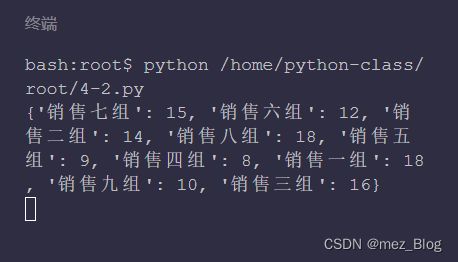
由打印的结果就可以看到优秀频次统计完成啦。
得到优秀频次后,还需要对频次进行排序,我们依旧选择用sorted()结合lambda表达式完成排序。
和汇总排序功能的排序不同的是,这里的对象不是列表而是字典,为了便于后面获取各个销售组对应的排名,这里需要把各个销售小组拿出来,因此要用 dict.keys() 先获得字典的键,我们可以先看看 dict.keys() 是怎么用的。
# 定义字典
dict_test = {'A': 1, 'B': 2, 'C': 3}
# 提取出所有的键
print(dict_test.keys())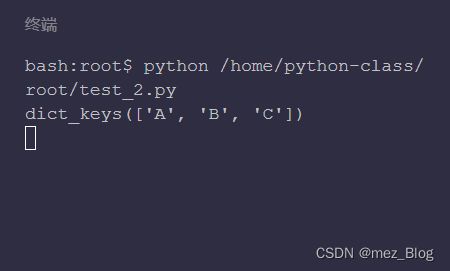
运行结果为 dict_keys(['A', 'B', 'C']),它的类型是 dict_keys,也是一个可迭代对象,通过 for 循环遍历 dict_test.keys() 就可以分别得到 'A', 'B', 'C'。
为了便于理解,我们可以把它转换为列表格式,即 list(dict_test.keys()),得到一个由键组成的列表 ['A', 'B', 'C']。其实直接用 dict.keys() 也是可以的,因为用 sorted() 排序后会返回一个列表。
说到 sorted(),还记得在项目中我们要掌握的 sorted() 的3个参数吗?
第一个参数位置要传入可迭代对象;
第二个参数 key 取的是可迭代对象中用于比较排序的元素;
第三个参数 reverse 是用于控制升序(从小到大)/降序(从大到小),默认是 reverse = False,表示升序。
这里我们已经确定要传给 sorted() 的可迭代对象就是 list(excellence_dict.keys()),那么 lambda 表达式要怎么写呢?
因为是以优秀频次作为排序的依据,也就是说 lambda 表达式冒号右边的返回值必须是优秀频次,而冒号左边的参数是键,因此可以通过字典 excellence_dict 将参数和返回值联系起来。
最后就是做降序排序啦。
from openpyxl import load_workbook
# 读取销售总表
wb = load_workbook('./等级销售表/等级一销售表.xlsx')
sheet = wb.active
# 初始化一个优秀频次字典
excellence_dict = {}
# 遍历数据
for row in sheet.iter_rows(min_row=2, values_only=True):
# 取出组名
group_name = row[1]
# 判断该组在字典中存不存在,不存在则初始化为0
if excellence_dict.get(group_name) == None:
excellence_dict[group_name] = 0
# 给该组计数加一
excellence_dict[group_name] += 1
# 根据小组的优秀频次进行排序
excellence_rank = sorted(list(excellence_dict.keys()), key=lambda x: excellence_dict[x], reverse=True)
print(excellence_rank)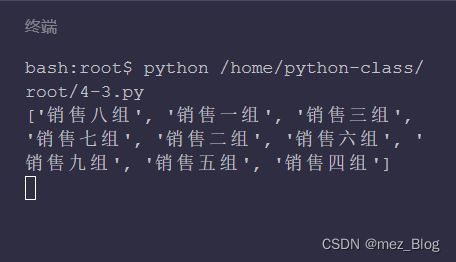
2.2 统计平均销量并排序
统计平均销量需要先读取销售总表,根据每行的组名分类统计各组的"总计"列的总和,最后处以组人数得到每个小组的平均销量。
而平均销量排序和优秀频次排序是类似的,需要先定义一个空字典 avg_dict,只不过是把值变成了累加各组每个人的“总计/瓶”数据,也就是说键为组名,值为小组平均销量。
接下来我们先尝试求取每组的总销量。
# 取出在汇总排序功能中最后得到的total_rows的一小部分数据
total_rows = [['陈洁', '销售七组', 10393, 815, 2993, 971, 1833, 889, 1128, 8629, 1], ['刘波', '销售七组', 10133, 1496, 2667, 774, 1924, 315, 1142, 8318, 2], ['陈涛', '销售六组', 10140, 1481, 2267, 568, 1989, 1236, 741, 8282, 3], ['张华', '销售二组', 10212, 1395, 2908, 490, 1485, 1149, 837, 8264, 4], ['陈伟', '销售八组', 10427, 1289, 2828, 502, 1279, 1354, 972, 8224, 5], ['李冬梅', '销售六组', 10195, 326, 2946, 886, 1963, 1309, 657, 8087, 6], ['杨秀兰', '销售五组', 10371, 509, 2715, 992, 1394, 1301, 1174, 8085, 7], ['杨林', '销售四组', 10063, 862, 2766, 799, 1611, 964, 1077, 8079, 8], ['李波', '销售一组', 10044, 1380, 2995, 886, 946, 1468, 327, 8002, 9], ['李雪梅', '销售二组', 10078, 1099, 2448, 760, 1574, 1215, 889, 7985, 10]]
# 初始化平均销量字典
avg_dict = {}
# 遍历数据
for row in total_rows:
# 取出组名
group_name = row[1]
# 判断该组在字典中存不存在,不存在则初始化为0
if avg_dict.get(group_name) is None:
avg_dict[group_name] = 0
# 统计总销售额
avg_dict[group_name] += row[9]
print(avg_dict)

因为是要对平均销量排序,不是对小组总销量排序,所以还需要再进一步求平均销量,然后覆盖掉原键值对中的值,由 组名:小组总销量 变为 组名:平均销量。
这里我们需要同时获取到 avg_dict 的键和值。
对于字典,如果要同时得到键和值,可以用dict.items(),dict.items()通常会结合for循环使用,先看一个简单的例子:
dict1 = {'A': 1, 'B': 2, 'C': 3}
# 定义变量key,value分别存放键和值
for key, value in dict1.items():
print(key, value)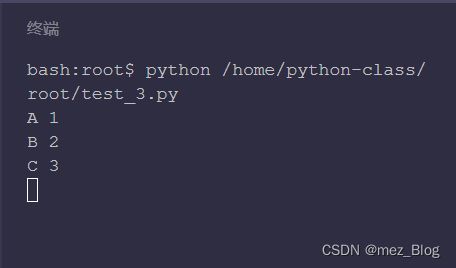
结果分别打印了字典的键和值,回到我们的项目中,求得平均销量:
avg_dict = {'销售七组': 16947, '销售六组': 16369, '销售二组': 16249, '销售八组': 8224, '销售五组': 8085, '销售四组': 8079, '销售一组': 8002}
# 求平均值,每个小组均为50人
for group_name, total in avg_dict.items():
avg_dict[group_name] = total / 50
print(avg_dict)
对了,最后计算完别忘了再给平均销量做排序哦。
2.3 添加名次并保存新工作簿
新建工作簿,创建工作表,写入表头['销售小组', '优秀频次', '频次排名', '平均销量', '销量排名'],现在就只差频次排名、销量排名两列数据未得到,下面一起看看如何获得这些数据吧。
在前面,我们曾经使用过enumerate()添加排名,如果已经遗忘了也不要紧哦,可以回头看看前面的示例代码。
前面在做好优秀频次排序的时候,我们已经得到了关于小组排名的数据,并将其赋值给变量 excellence_rank,如果将 excellence_rank 作为 enumerate() 的参数进行遍历,并从 1 开始计数,就能得到“频次排名”了。
excellence_rank = ['销售八组', '销售一组', '销售三组', '销售七组', '销售二组', '销售六组', '销售九组', '销售五组', '销售四组']
# 按优秀频次排序写入数据
for index, group_name in enumerate(excellence_rank, 1):
print(index ,group_name) 
可以看到 index 就是对应各小组优秀频次的排名。
还剩销量排名这一项未得到,理论上我们也可以用上面的代码逻辑获取销量排名,但就又需要写一个 for 循环,既然 excellence_rank 和 avg_rank 都是由 group_name 组成的列表,并且这里已经得到了 group_name,有没有办法把两个 for 循环合并到一起呢?
答案当然是可以,不过需要学习一个新的知识点——list.index()。
list.index()可用于从列表中找出某个值第一个匹配项的索引位置,举个例子:
# 定义列表
list_info = ['a', 'b', 'c', 'b', 'd']
# 返回'c'在list_info中出现时的索引
print(list_info.index('c'))
# 返回'b'在list_info中第一次出现时的索引
print(list_info.index('b')) 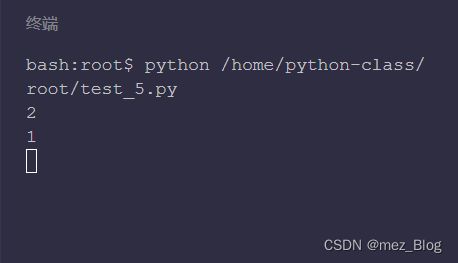
运行后分别打印 2 和 1,也就是 'c' 和 'b' 在 list_info 中第一次出现时的索引。
回到项目中,平均销量的排序结果是 avg_rank,按索引顺序0、1、2……进行排列,其实也就是平均销量的名次,所以只要得到了 avg_rank 中各项的索引值就等同于获取了各小组的名次。又因为名次是从 1 开始算起,所以获取到的索引值要再加 1 才是真正的销量排名。
# 优秀频次排序结果
excellence_rank = ['销售八组', '销售一组', '销售三组', '销售七组', '销售二组', '销售六组', '销售九组', '销售五组', '销售四组']
# 平均销量排序结果
avg_rank = ['销售一组', '销售三组', '销售七组', '销售九组', '销售八组', '销售二组', '销售六组', '销售四组', '销售五组']
# 按优秀频次排序获取频次排名
for index, group_name in enumerate(excellence_rank, 1):
# 获取销量排名
sale_rank = avg_rank.index(group_name) + 1
print(sale_rank) 
至此,“销售小组”,“优秀频次'”,“频次排名'”,“平均销量”,“销量排名”这 5 项数据我们就都拿到了,最后要做的就是新建一个列表,将 5 项数据都添加进去,然后把数据写进新工作表,保存为【小组销量排名表.xlsx】。
from openpyxl import Workbook
excellence_dict = {'销售七组': 15, '销售六组': 12, '销售二组': 14, '销售八组': 18, '销售五组': 9, '销售四组': 8, '销售一组': 18, '销售九组': 10, '销售三组': 16}
excellence_rank = ['销售八组', '销售一组', '销售三组', '销售七组', '销售二组', '销售六组', '销售九组', '销售五组', '销售四组']
avg_dict = {'销售七组': 285631, '销售六组': 272001, '销售二组': 282512, '销售八组': 285006, '销售五组': 262319, '销售四组': 264814, '销售一组': 295537, '销售九组': 285210, '销售三组': 286086}
avg_rank = ['销售一组', '销售三组', '销售七组', '销售九组', '销售八组', '销售二组', '销售六组', '销售四组', '销售五组']
# 新建表
new_wb = Workbook()
new_sheet = new_wb.active
# 写入表头
new_sheet.append(['销售小组', '优秀频次', '频次排名', '平均销量', '销量排名'])
# 按优秀频次排序写入数据
for index, group_name in enumerate(excellence_rank, 1):
# 获取优秀频次
excellence_times = excellence_dict[group_name]
# 获取平均销量
avg_sales = avg_dict[group_name]
# 获取销量排名
sale_rank = avg_rank.index(group_name) + 1
# 写入数据
row = [group_name, excellence_times, index, avg_sales, sale_rank]
new_sheet.append(row)
# 保存
new_wb.save('./小组销量排名表.xlsx')
3 总结
完成了小组排名的功能,本次实操项目所有表格数据处理的部分就完成啦,我们再来看一下知识点。