从机器学习到大模型(零基础)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
一、机器学习
1.监督学习
(1)线性回归模型
(2)多元线性回归模型
(3)二元分类模型
(4)注意事项
(5)深度学习
(6)模型评估
(7)决策树
2.非监督学习
(1)聚类
(2)异常检测
(3)推荐系统
3.强化学习
二、RNN
三、RCNN
四、LSTM
五、Encoder-Decoder
六、Transformer
七、Bert
总结
参考资料
前言
从计算机之父Alan Turing 的 Computer Machinery and Intelligence 开始,将机器与思维联系到了一起,提出了著名的“图灵测试”,此后无数的科学家大牛们在这场“模仿游戏”中玩的不亦乐乎,将数学结合计算机形成了解决问题的系统,并且不断的深入,变得越来越复杂,从最初的的机器学习到现在动则几百亿参数的大模型;关于机器是否会拥有智能,硅基生物是否有一天会拥有自己的意识,当机器数据的规模不断增大,是否会量变引起质变,涌现出自己的思想,没有人可以给出一个肯定的回答,但是我们这个时代注定要见证许多的不平凡,过于先进的科技对于普通人来说就像魔法一样,希望通过自己不断地学习可以悟出魔法的奥秘。
一、机器学习
机器学习可以简单分为监督学习、非监督学习与强化学习。
监督学习是给出算法实例和答案,对输出进行预测或者分类,相对应用的比较多;
非监督学习是根据数据自己进行学习,例如给标签的数量自己进行分组集群(聚类/异常检测/降维);
强化学习是根据环境的反馈进行强化学习。
1.监督学习
在监督学习中主要分为线性回归模型和分类模型
(1)线性回归模型
最简单的线性回归模型,就是给出数据,找到一条最合适的线(函数)来对其进行拟合,之后可以进行预测。线性回归模型和分类的区别之一就是分类的输出一般是有限的,而线性回归模型的输出基本是无限的。
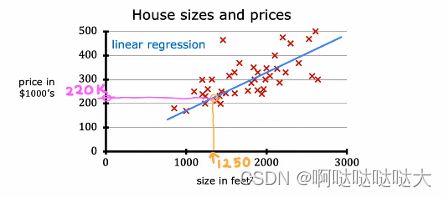
所以我们只要给定训练数据xi和yi,假设函数为f,预测输出为y-hat
其中f就是要训练的模型,简单的可以是一元一次方程,复杂的可以有几百个参数。
那么问题就来了,我们该如何去找到这个 f 呢?
换句话说,要找到 f,就是要找到函数中的参数,也就是w和b,所以我们的目标转移到了找w,b的问题上。
在最开始我们先随便选择参数,构建一个预测函数,之后不断的调整使它更贴合训练集,所以我们的目标又转移到了如何去调整参数之上。
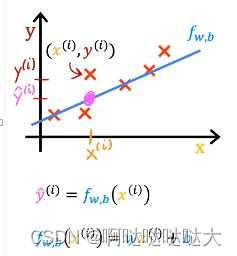 我们现在的预测模型代入xi可以得到预测值,也可以看到它与真实值的差距,利用这个特点,我们就可以通过反向传播去训练这个参数,让预测值与真实值的差距越来越小,而反向传播的关键之一就是损失函数。
我们现在的预测模型代入xi可以得到预测值,也可以看到它与真实值的差距,利用这个特点,我们就可以通过反向传播去训练这个参数,让预测值与真实值的差距越来越小,而反向传播的关键之一就是损失函数。
不要忘记我们的目的是去找w,b,而损失函数就是一个重点。

可以看到损失函数占大头的就是对所有训练集的预测值减去真实值的平方求和,之后除以2倍的训练集数量,只要知道他和那个“差值”是正相关的就足够,差越大,损失函数越大。如果我们暂时去除b这个参数,对w进行随机取值,得到的损失函数是这样的(如果加上b则变成3维图像):
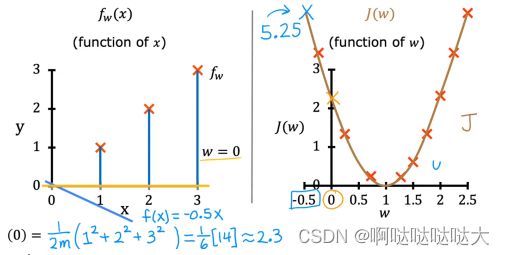 J对于w的函数图像
J对于w的函数图像
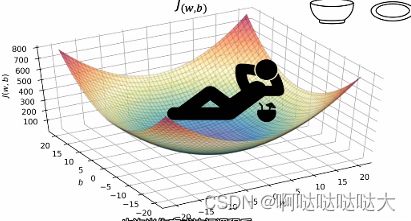 J对于w,b的函数图像
J对于w,b的函数图像
可以看到是存在w,b使得损失函数最小的,我们的目的是为了找到这个最合适的w,b,也就是为了减小这个损失函数、减小差值,于是又引出了梯度下降的概念。

梯度下降的目的就是为了找到这个最合适的w,b,也就是损失函数中的最小值所对应的参数。
在一开始我们随机给出了w,b,带入到损失函数之中,可以求出这个位置的偏导数,用现在的w减去学习率α与偏导的乘积,可以找到下一个更合适的位置;因为偏导为负数则为“下坡路”,减去负数得正前进继续下降找更小,反之上坡后退找更小,最终找到那个最低点。其中的学习率α也是线性回归模型中的超参数之一,是需要我们自己去设定的。在此也补充一下有关机器学习的相关概念,有助于对于以后内容的理解。
概念解释:
学习率α:机器学习的超参数之一,为了控制找最优w,b的步长,太大了容易爆炸,太小了找的太慢(也有可能找到了局部最优解就跳不出去了),建议是0.01~0.001刚开始可以用,在一定的epoch之后减缓,如果是迁移学习微调的话建议<0.0001
batch_size:批大小,一次训练的样本数目,在内存效率和内存容量之间找平衡
iteration:迭代 ,一次迭代即上次输出的参数值作为下次的输入
epoch:训练集样本全部训练一次
batchnorm:特征均值为0方差为1
layernorm:数据转置 样本均值为0 方差为1 样本标准化
之后我们便可以将训练集代入公式进行一次次的训练,一次次地反向传播调整参数,最终大概率便可以得到最合适的w,b

(2)多元线性回归模型
在上一部分当中我们学会了对于一元一次函数也就是线性回归模型通过梯度下降找到损失函数的最低点——找到最低点对应的参数w,b——找到“差值”最小的函数——找到最佳预测模型,那么如果我们的输入不止是一元,而是多个x构成的多元函数呢?对应于实际生活当中就是对于结果的影响因素不止一个,可能有很多个,这也就对应了很多个xi,也对应了很多个w(b永远都是一个),这种情况我们如何去类推呢?
方法都是一样的,只不过数值运算变成了向量运算,而这也是计算机所擅长的事情
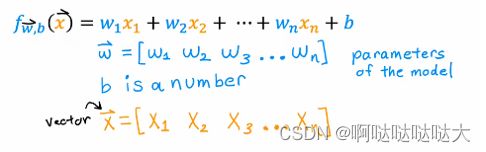
输入的值由xi变成了向量x,对应的w也变成了向量w,同时加上不变的小b
对应的,梯度下降由求导变成了求微分:
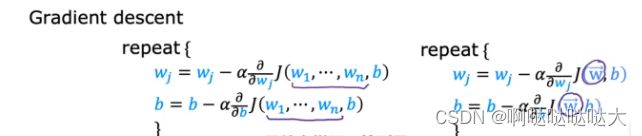
于是将损失函数代入多元回归的梯度下降变成了酱紫:
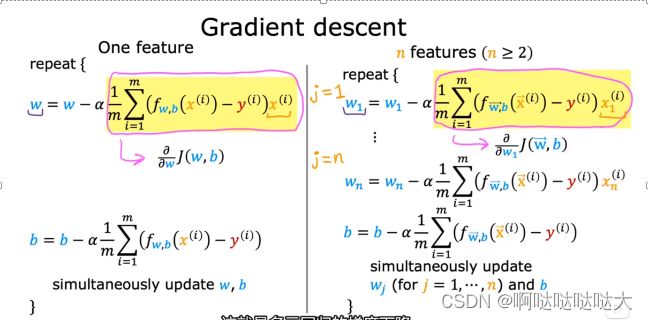
需要注意的是偏导的计算,后面乘的xn(i)不要写错了,对w1-wn一个个算就完事了
(3)二元分类模型
二元分类,即输出为0/1,只有两种可能。

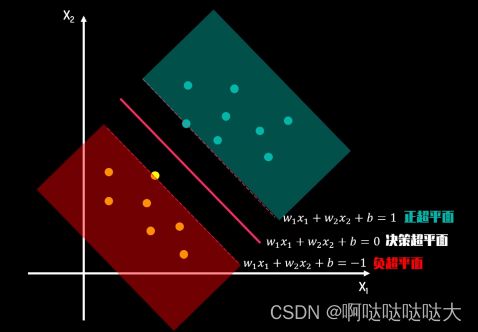
我们所要做的,就是找到0/1对应数据之间的那条分界线——决策边
针对于此,我们在线性回归模型的基础之上加上了一个函数,形成了用逻辑回归算法来进行分类
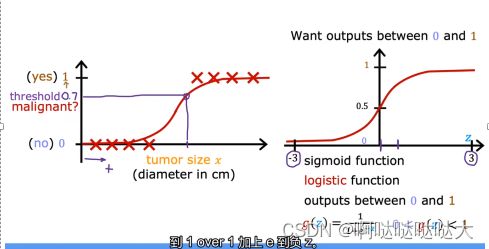
其中,g(z)=![]() ,这也是sigmoid激活函数,它的特点就是上面图形的S型,不管输入是什么输出都能变为0/1。这不就正和我们二分类的想法一致,于是就可以用它了。那么肯定会有问题,z是什么?我们之前不都是对x进行的运算吗?
,这也是sigmoid激活函数,它的特点就是上面图形的S型,不管输入是什么输出都能变为0/1。这不就正和我们二分类的想法一致,于是就可以用它了。那么肯定会有问题,z是什么?我们之前不都是对x进行的运算吗?
z还是w、b的函数,加了sigmoid之后是让w,b改变将输出y(现在是z)控制在+-之间从而使最终结果在0/1之间,相当于多了一步成了一个复合函数,变量还是w,b,这就是逻辑回归。

之后就是要定一个决策边界,g(z)的值大于它输出就是1,小于就是0
决策边界就是能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)

之后我们的目的就是找到这个决策边界,怎么找到这个决策边界呢?
还是要找到对应的最合适的w,b。接下来就是熟悉的步骤了,只不过损失函数和梯度下降有所改变

可以看到线性回归的损失函数是平滑的,而逻辑回归的损失函数是不平滑的,这是因为输出不是连续的值所以损失函数也不连续了,这时候梯度下降算法就要改了
损失函数变成了这样:
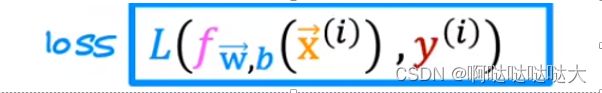
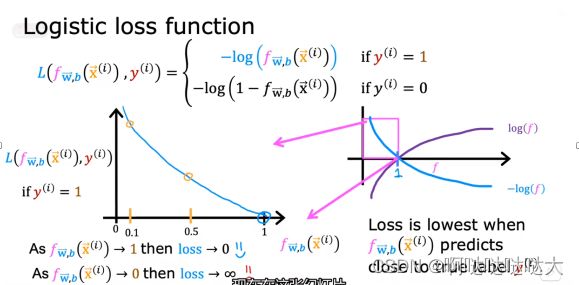
因为输出是0/1,所以对0和1分开来看 用-log来算损失函数的值
这样损失函数分两种可能有点麻烦,将函数合为一体变成了最终的损失函数:

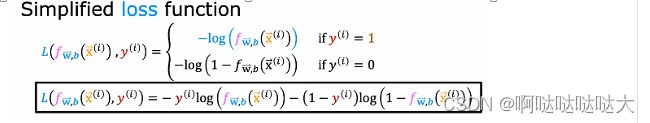
同样的,之后还是要进行梯度下降找最优解,梯度下降也有所改变:

需要注意的是,逻辑回归中因为加了sigmoid激活函数所以 f 和线性回归是不同的。
之后就和线性回归模型一样不断的训练得到最合适w,b的值就可以了,关于多元分类模型在下一部分深度学习中会提到。
在此提一下同样是分类模型的SVM支持向量机,它只能二分类,主要就是为了找到决策边界,其中有软间隔硬间隔等概念,目的是为了分类,可以提升维度进行更复杂的分类(应用核技巧),它与逻辑回归本质上是损失函数不同,而且SVM只能看到边界附近的点,对于非线性问题的处理也有所不同。
(4)注意事项
为了使机器学习模型更好的训练,还有一些方法值得学习:
特征缩放:每个特征x维度不一样,比如家庭人员个数/家庭财产,分别对应3个/100000元,不是一个数量级,所以要缩放成差不多的,这样w大小也就差不多
How?:都除以最大值/均值归一化(减去均值后除以最大小之差)/Z-score 高斯分布标准差

可以进行多次缩放调整到合适的,这种缩放是不影响训练的,只是改变权重而已,最后可以怎么改过来的怎么变回去, 不用担心对于预测的影响。
梯度下降的收敛:迭代到一定的次数后J会收敛,测试为当一次迭代(iteration)J下降小于一个值(0.001之类的),则判断收敛,w,b则是合格的,就不用再继续训练浪费时间了。
α很重要:选择合适的学习率,如果特别小的学习率还不下降说明代码有问题,吴恩达大佬建议对于α的尝试为: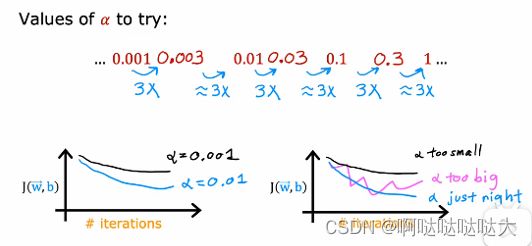
特征工程:组合原始特征形成新特征(x1+x2、x1²……)
过拟合的问题:下面三个函数分别对应了欠拟合,合适,过拟合
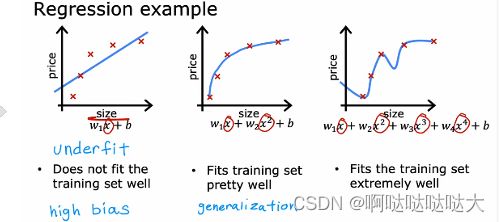
过拟合是什么?就是w太多太大,导致和训练集符合的太过了,这样的函数只会在训练集上得到好的评分,但是在实际中是无法应用的。为了解决过拟合,可以用特征选择的方法,和正则化
正则化:为了解决w太大造成过拟合的问题

可以看到,就是在损失函数中加了个函数,为w平方和除以2倍的数据数量再乘以lambda,这样损失函数和w大小也形成了正相关。
并且lambda也变成了很重要的一个超参数,要合适,不能太大或者太小,线性回归和逻辑回归都需要它。
机器学习至此告一段落,下一部分会介绍在机器学习的基础上构建更复杂的网络,也就是深度学习
(5)深度学习
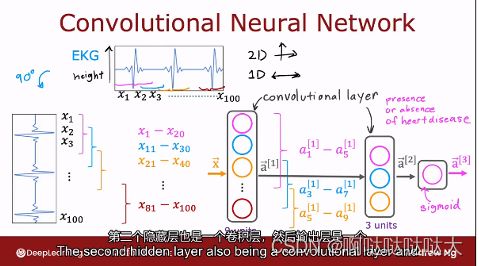
人工神经网络:人工神经网络由神经元构成,往往分为几层:输入层、隐藏层、输出层,输出还是一个预测。每个神经元就是我们刚刚学习到的回归模型。

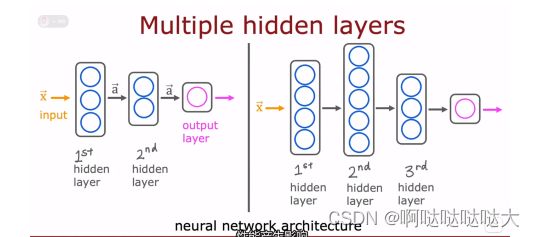
其中层数不同,神经元不同,最后的模型都不一样。对于输入层的处理可以有卷积、自注意力机制等等,而隐藏层神经网络如下:
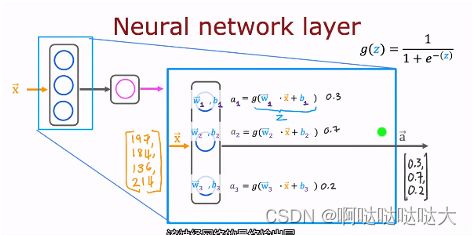
在上图中,每个隐藏层中的神经元都是一个逻辑回归模型
输入的向量x分别输入到每个神经元中去做计算,每个神经元都通过训练得到自己的w,b
得到的输出也是一个向量,输入到下一层之中,上标的[]表示第几层的输出
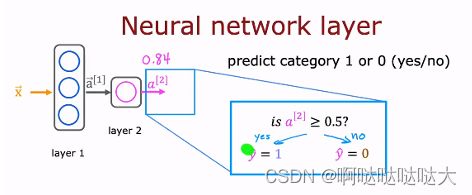
值得注意的是对上下标理解正确,上层下元,其余的都和机器学习大同小异
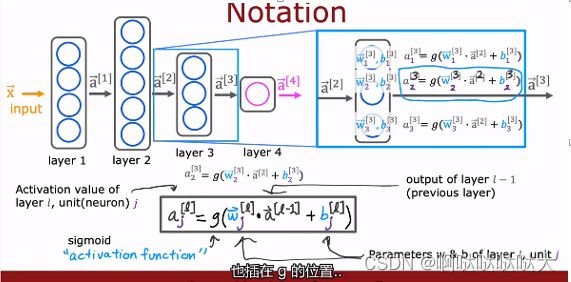
在二分类模型中我们提到了sigmoid激活函数,也就是那条经典的S曲线,在人工神经网络之中不止这一种激活函数,还有ReLU:它的特点是>=0,>0是线性的

如何去选择隐藏层的激活函数,大部分都是ReLU,注意不能直接用线性回归模型,因为那样的话人工神经网络就是一个大型的线性回归模型就鸡肋了。
选择输出层的激活函数:输出层函数有所讲究,主要看需要的输出类型是什么样的,对应的激活函数的特点。二元分类用sigmoid,回归y分为正负用线性,y大于0用relu

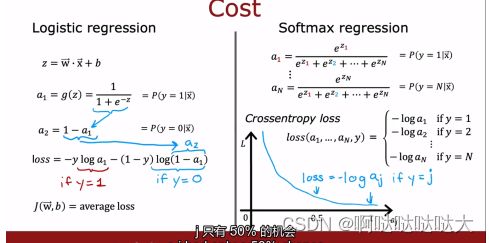
多分类模型:在之前提到了二分类模型,那么如果有多个输出的话,即多分类,应该如何进行?其实就采用了softmax多分类模型,简单来说是对输出又做了一个求比重的运算,从而得到多输出。

通过计算最后得到的输出ax就是对应x的概率
加入softmax之后损失函数也有所改变,变为对每个输出单独求损失函数
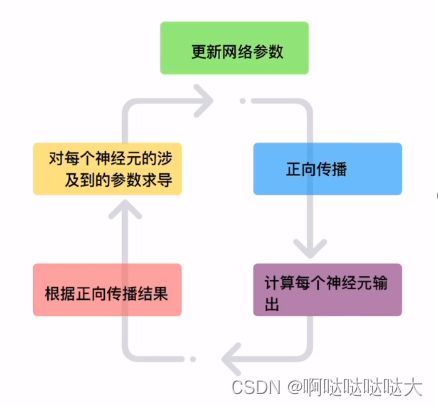
之后的流程也是大同小异,通过正向传播和反向传播更新参数,最终得到训练好的模型,如下:
值得一提的事还有其他的算法可以取代梯度下降的算法,比如Adam算法等,很多比梯度下降好用
卷积神经网络(CNN):卷积神经网络即CNN,Convolutional Neural Networks,就是在人工神经网络NN的基础之上,对输入层做改变,使每个神经元看一部分的输入,从而减小运算量。C代表的卷积,是对输入的一种处理,用来处理图像特征,卷积层拥有多个卷积核,每个卷积核都有自己的特征,之后对图像进行卷积处理,几个内核就会扫出来几张图。


提取出的特征图中矩阵的维数=[(input的维数-卷积核的维数+2*zero-padding)/stride]+1
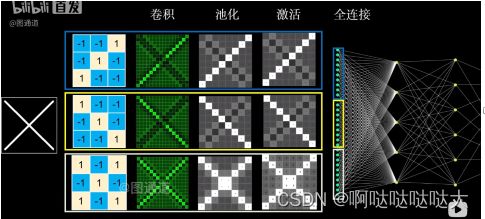
然后进行池化,就相当于压缩降维,每一块之中取最大值或者平均值来减小冗余,这也是下采样中的一种,拥有平移不变性。
卷积层的特征进行合并或者取样输入全连接层
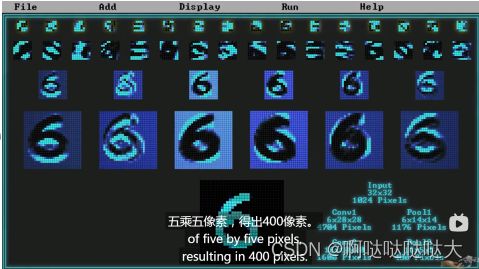
最后的效果如下:
(6)模型评估
当我们构建出一个又一个的模型之后,如何知道我们的模型是好是坏,以及如何进行修改,就涉及到了许多新的有关模型评估的概念。
首先是增加了交叉测试集Cross validation(cv or val),简单来说就是对于你的训练集来说,如果有许多高阶多项式的话你的J train可能效果很好,但是J test很差,所以又增加了中间的一个缓冲地带交叉测试集:

这样的话当你在训练集上训练了十个模型都差不多的时候,可以选择在交叉验证集上效果最好的来应用到测试集上。

偏差方差:偏差bias—在测试集上的差;方差variance—在交叉测试集上的差
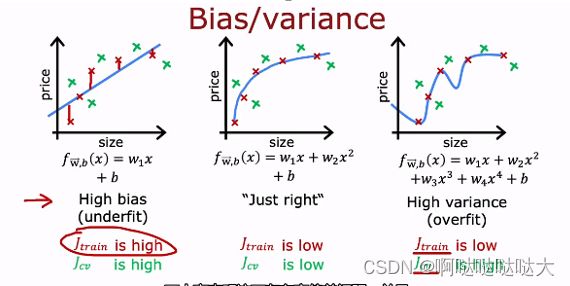
高偏差说明没训练好欠拟合,高方差低偏差说明过拟合,最好的结果是低偏差低方差
之前我们介绍α的概念之中提到了如何选择α,但是提到兰姆达![]() 的时候却没有提,因为要先有交叉验证集才能选择它。通过不断的尝试
的时候却没有提,因为要先有交叉验证集才能选择它。通过不断的尝试![]() 选择在cv上最合适的作为最终选项
选择在cv上最合适的作为最终选项

选择![]() 的时候也可以构建出对应的偏差和方差,得到最合适的点对应的兰姆达。专门看偏差和方差的函数称为学习曲线。
的时候也可以构建出对应的偏差和方差,得到最合适的点对应的兰姆达。专门看偏差和方差的函数称为学习曲线。
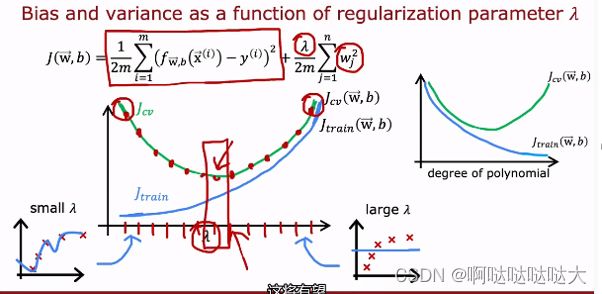
高偏差的话有可能是模型问题,看看增加数据,或者模型太简单,用更复杂的函数;
高方差的话考虑过拟合了,可以增加训练集的数量

通过观察偏差和方差可以有助于我们训练自己的模型,其它的方法还有数据增强,迁移学习等技巧,迁移学习在目前应用比较普遍,把已经训练好的模型应用于自己的数据之中,一般有两种选择,一是只再训练输出层;二是训练所有的参数
精确率和召回率:

精确率:预测1中有多少是正确的,预测正确率
召回率:真实的1中被预测中了多少

F1score用来算召回率和精确率的得分,进而评估模型。

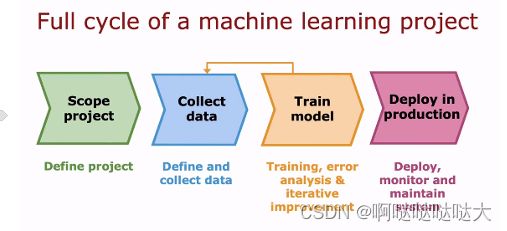
最后是深度学习的完整训练周期:
(7)决策树
决策树没好好学,只能简单介绍一下大概:
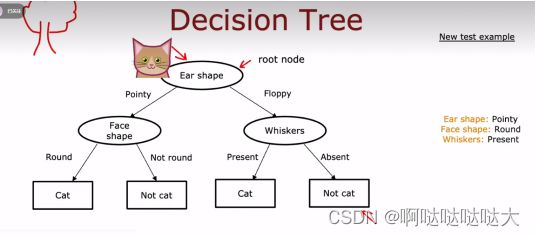
由根节点 决策节点 叶子节点构成
主要的问题是怎么去分特征最好?这个靠的是纯度
其次是分到什么程度?分到都是100%或者到最深的了
运用到了香农的信息论,H(p)熵

熵的图像如上所示,在p=0.5的时候最大为1
然后是选择分的节点
每个特征分完都有熵的大小和纯度,先求总的熵,再减去权重乘每部分的熵,得出的值越大说明减小的熵越多,就选这个点来分

有关决策树的内容如下:

或者使用one-hot编码:
每个特征是或者不是填入0/1,最后给出是或者不是0/1,形成一个表格,然后直接进行分类训练
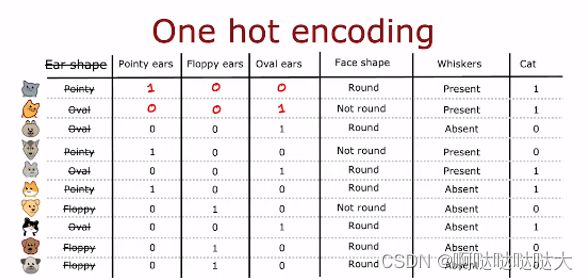
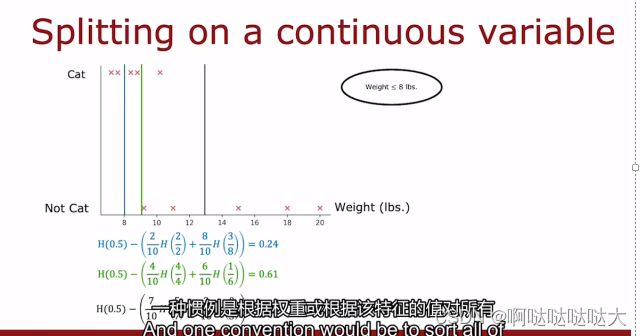
算出来每一个weights 。
多个决策树:随机森林

有关决策树和神经网络的对比,目前应用的更多的还是神经网络,但是决策树相对于神经网络最大的优势就是可解释性,这也是神经网络被诟病的原因之一。

2.非监督学习
非监督学习主要分为聚类、异常检测和推荐系统。
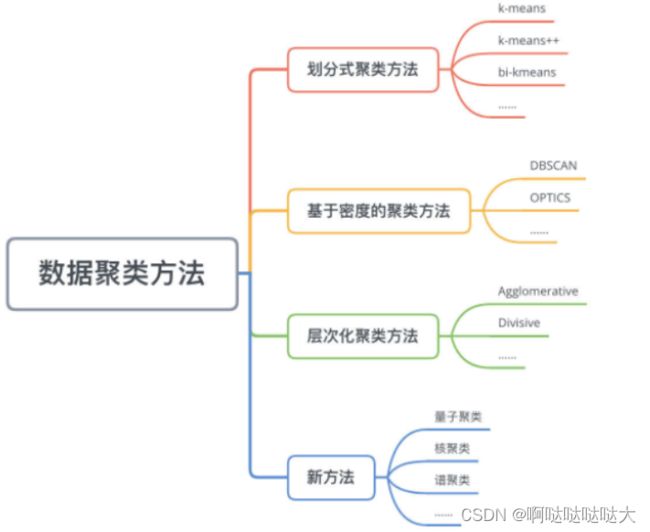
(1)聚类
聚类的方法有很多:
在这我们主要学习一下经典的K-means算法来找集群中心。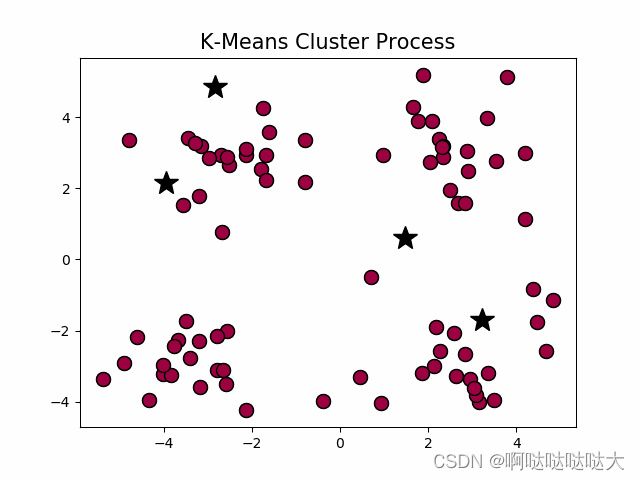
首先随机猜测中心在哪里,然后根据中心划分,之后再重新算这些数据的中心,以此反复找到最合适的中心点。

其中聚类也有损失函数,也是要找到损失函数的最小值。

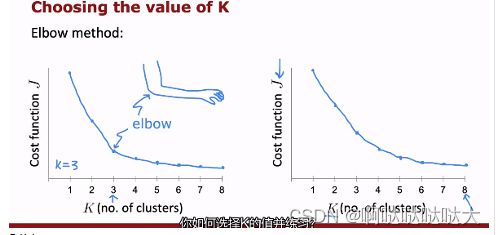
聚类中关于K的数量的选择采用“肘法”
(2)异常检测
可以通过密度算法来找异常,也可以通过高斯分布来找异常,或者通过选择特征和加数值最后变成高斯分布来找异常。

步骤如下:
1、选取参与概率计算的特征值,必要时进行处理。
2、对于每个特征值,计算μ、δ,进而计算出每个特征值的概率公式pj(x)。
3、将所有参与计算的特征值的概率公式相乘,得到总的概率公式p(x)。注意,这里有个前提,是这些特征互相之间不想关,即互相独立。这种计算方式,称为极大似然估计(maximum likelihood estimation),也是概率论中的一种计算概率的方式。
4、对于一个给定的样本x,计算p(x),如果p(x)<ε,则认为这个异常;否则正常。ε是一个比较小的数字,如0.02等,对于选择ε,应用到我们之前提到的F1算法,可以通过几个不同的ε,运用交叉验证,看哪个ε最终计算出来的F1最大,则使用那个ε。

(3)推荐系统
协同过滤算法,此处略
3.强化学习
有关强化学习目前仍处于新兴阶段,其中主要应用的是反馈奖励机制。

s位置 a 方向 R(s)回报,s'下一个位置
其中回报有折扣因子

每一个状态的奖励 由方向,方向上的奖励,折扣因子决定,机器所要做的找奖励最高的策略

其中应用到了马尔科夫决策 (MDP)
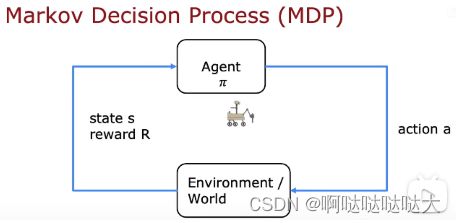
Q函数:s,a 状态和方向得到的奖励值

有个这函数之后,在某个位置可以选择选择最大的a
之后又引入了贝尔曼方程


这样就可以得到每个位置的最优路线
随机马尔科夫决策模型

强化学习这部分囫囵吞枣理解的并不透彻,如想详细了解可以看强化学习(Reinforcement Learning)知识整理 - 知乎
二、RNN
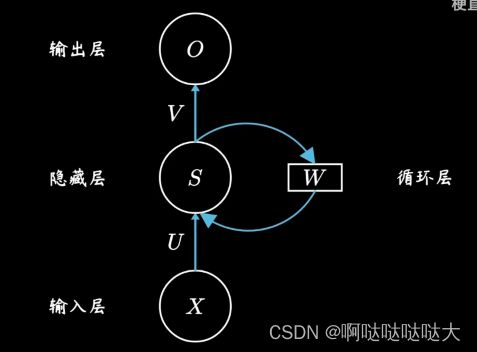
RNN在神经网络的基础上引入了时间向量,将每一个w和上一刻的w连接了起来,这样在时间上引入了变量,主要应用于自然语言处理。

在翻译中t就是输入词的顺序。
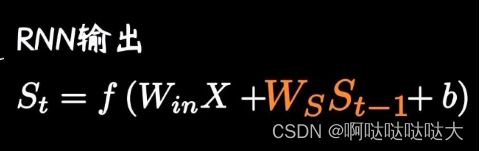
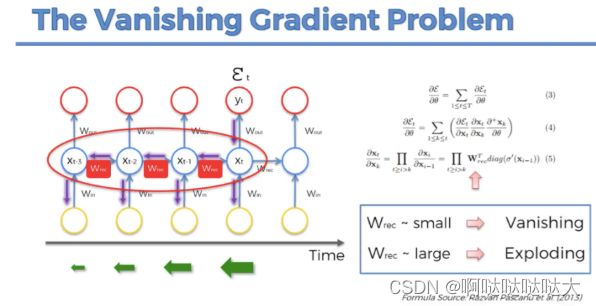
但是只要是RNN,就会有梯度消失问题,核心原因是递归的方式,作用在同一个权值矩阵上,使得如果这个矩阵满足条件的话,其最大的特征值要是小于1的话,那就一定会出现梯度消失问题。后来的LSTM和GRU也仅仅能缓解这个问题
三、RCNN
两阶段目标检测代表作,在CNN输入层基础之上加入了候选框提取,随机选取2000个
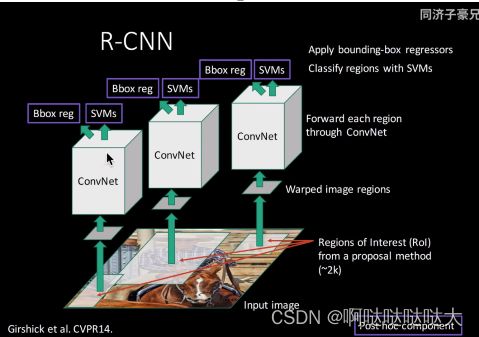

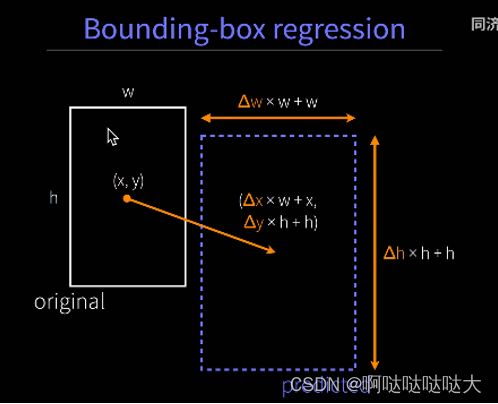
关于其中的BBX回归:

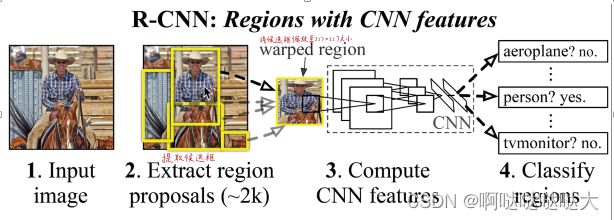
首先随机选2000个框,然后缩放成统一大小(227*227 ),输入到CNN神经网络里
神经网络有4096个特征
输出用svm支持向量机,20个类别就20个SVM,每个SVM判断是或者不是这个分类
BBXregression回归用来回去修改预测框让他更准一点
R(region)—CNN,主要是两阶段训练,先提取了候选框
两阶段所以不是端到端,每一部分分开进行
卷积层比较重要,预训练用的也是卷积层
最后得出结果SVM特征4096*N和前面算完的矩阵乘法就行,对于计算机来说矩阵乘法很高效
finetuning-小碎步调参 微调
bounding box :线性回归模型预测新框 相对于以前的偏移量
知识补充:
Bleu score: bilingual evaluation understudy BLUE将机器翻译的结果与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。注意BLEU算法是句子之间的比较,不是词组,也不是段落。
注意力机制:关注值得注意的东西
随意线索被称之为查询:随着注意力的(query )
每个输入是一个值(value) 和不随意线索(key) 的对
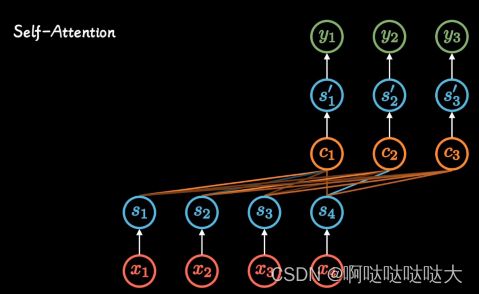
自注意力机制
四、LSTM
长短期记忆网络,缓解RNN长期依赖的问题
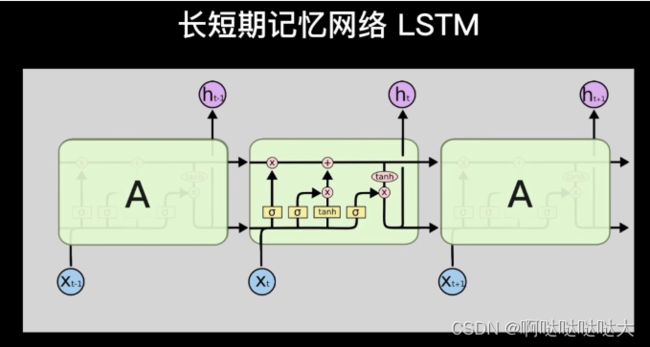
相当于对RNN加了一个“日记本”
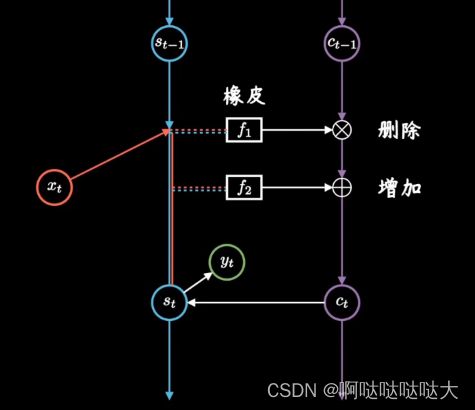
删除旧日记,增添新日记
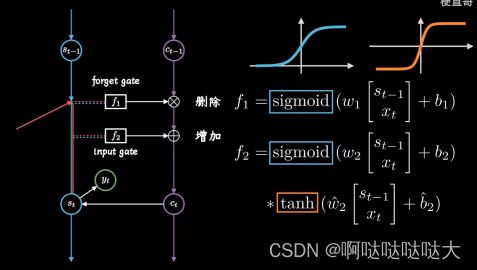
sigmoid函数0-1 矩阵相乘抹除为0的元素,删除了旧日记



五、Encoder-Decoder
模型如其名,它主要由编码器和解码器构成
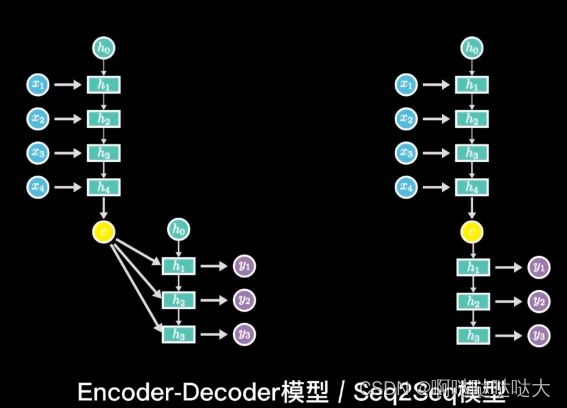
输入输出不等长,用自注意力机制
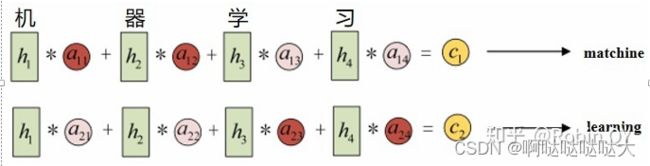 不同的权重,最后得到不同的值
不同的权重,最后得到不同的值
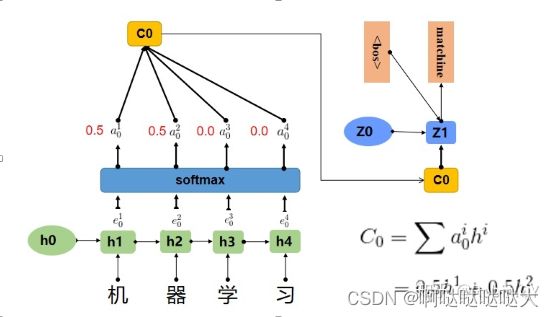
编码器解码器:
编码:x1-xn zt表示第t个词的向量表示
解码器:输出ym 解码词一个一个生成(自回归)
输入z向量(z1……zn),输出yt ,跟yt-1也有关系

六、Transformer
分为两大部分,编码器和解码器,编码器有多头注意力机制和前馈网络,解码器多了mask部分
先embedding向量表示,之后加上位置编码进入编码器,第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入一个可以重复很多次的模块。该模块可以分成三块来看,第一块也是Attention层,第二块是cross Attention,不是Self-Attention,第三块是全连接层。也用了跳跃连接和Normalization。
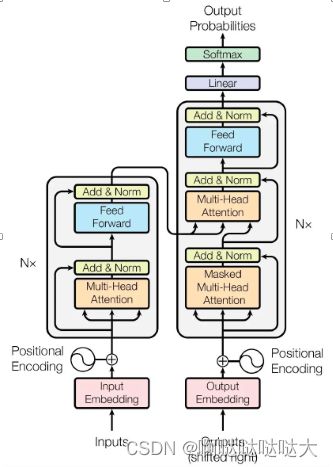
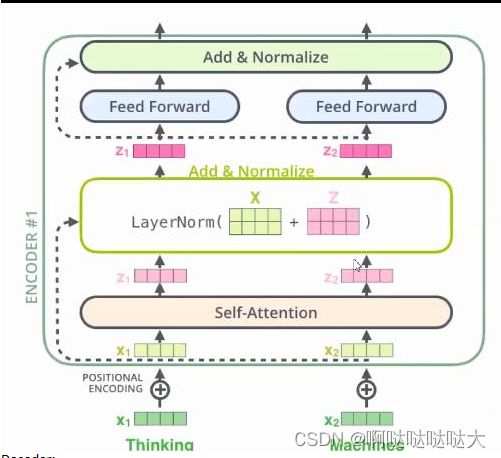
编码器:六个完全一样的层,每个层里面有两个子层,多头注意力机制和MLP+残差连接
MLP就是多层感知器,也就是之前讲的人工神经网络

X1 x2两个单词输入进去,经过自注意力机制互相包含了对方的信息,之后通过两个分开的全连接神经网络得到r1
经过前馈神经网络之后,ADD表示残差连接,Norm表示layernormorlization
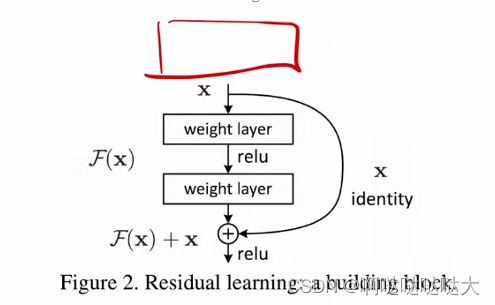
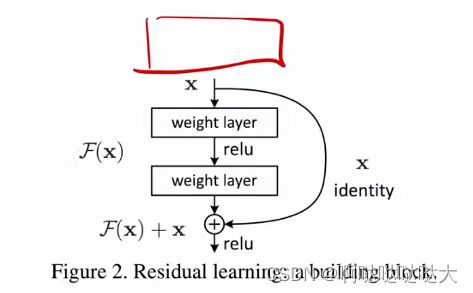
残差连接(ResNet)网络:做图像方便增加层数,当网络加深的时候很容易出问题,所以深层网络的时候输入加上一个原始的输入,并且使用batch normalization加速训练(丢弃drop out)
学的东西H(x) 输出X 之后要新加一层 输入是什么呢?是H(x)-x ——学到的东西和真实的东西的差
输出F(x)
最后深的输出F(x)+浅的x

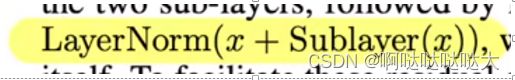
将数据进行layernorm与batchnorm的区别,对数据进行标准化处理


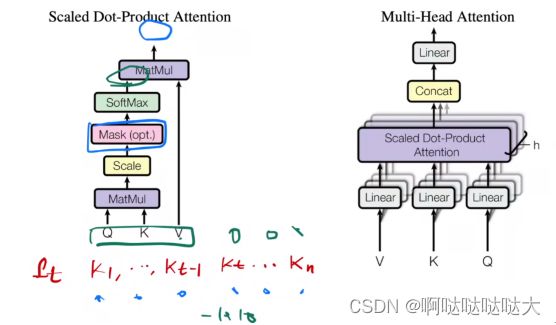
自注意力机制,query和key的相似度决定对v的权重
q k内积 除以根号dk(长度相同)
再用softmax做分类 得到n个非负加起来等于一的权重——每行做 各行之间独立
作用于value上面得到输出,还是一行

最后简化到了用两个矩阵乘法就搞定了
除以根号dk 为了softmax梯度

Encoder:
Decoder:
Decoder的初始输入:训练集的标签Y,并且需要整体右移(Shifted Right)一位
Shifted Right的原因:T-1时刻需要预测T时刻的输出,所以Decoder的输入需要整体后移一位

Transformer Decoder的输入:
- 初始输入:前一时刻Decoder输入+前一时刻Decoder的预测结果 + Positional Encoding
- 中间输入:Encoder Embedding
Encoder告诉我key和value是什么,我现在要做的就是产生query。

网络中的mask是干什么用的?保证t时刻看不到t时刻之后的输入 和实际情况一致


两个线性层 扩四倍再缩回去

七、Bert
机器人军团 大模型的代表
多个解码器——GPT
解决单向限制
ELMo—基于特征的预训练
GPT——基于微调的预训练
带掩码的语言模型 完形填空(双向)+transformer 非监督预训练
多层双向transformer编码器
调了三个参数
L layer个数 H 隐藏层大小 A 自注意力头

嵌入层 参数

输入可以是句子对
两个句子变成一个序列
切词 ——30000词典就够了

15%mask

句子之间 50%

一对句子的形式,加输出层
1个亿、3个亿参数
总结
本文从机器学习讲起,直到现在流行的各种模型,其中问题还有很多,在不断学习的过程中也会不断改进,也算是我这段时间的学习笔记,想把机器学习的相关知识用人话讲出来,但是到Transformer和Bert模型这部分脑细胞有点不够了,等以后再详细的补上,并且有些地方理解还是不够深刻,请大佬们多多指点。
参考资料:
吴恩达机器学习课程(强推|双字)2022吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili
李沐论文精读系列
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
同济子豪兄论文精读系列
【精读AI论文】R-CNN深度学习目标检测算法_哔哩哔哩_bilibili
常用聚类算法 - 知乎
Self-Attention和Transformer - machine-learning-notes
【梯度下降】3D可视化讲解通俗易懂_哔哩哔哩_bilibili
LSTM原理详解_yanglee0的博客-CSDN博客_lstm神经网络原理