pytorch学习笔记:模型的构建
模型构建基础知识
构建神经网络的典型流程
* 定义一个拥有可学习参数的神经网络
* 遍历训练数据集
* 通过网络处理数据
* 计算损失值(loss)
* 将网络参数的梯度进行反向传播(loss.backward)
* 更新网络的权重
1、神经网络的构造
1.1 Model类的介绍(定义一个简单的神经网络)
Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。该类是一个可供⾃由组建的部件。它的子类既可以是⼀个层(如PyTorch提供的 Linear 类),⼜可以是一个模型(如这里定义的 MLP 类),或者是模型的⼀个部分。
例如:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个简单的网络类,继承model
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
# 线性层,实现类似y = wx+b 的功能
self.hidden = nn.Linear(500, 128)
# 激活函数,将小于0的值截至为0
self.act = nn.ReLU()
# 输出层
self.output = nn.Linear(128, 2)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
if __name__=='__main__':
X = torch.rand(2,500)
net = MLP()
print(net)
print(net(X))
结果:
MLP(
(hidden): Linear(in_features=500, out_features=128, bias=True)
(act): ReLU()
(output): Linear(in_features=128, out_features=2, bias=True)
)
tensor([[-0.0850, 0.2141],
[-0.1615, 0.1114]], grad_fn=<AddmmBackward0>)
1.2、神经网络中参加的层
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。
虽然PyTorch提供了⼤量常用的层,但有时候我们依然希望⾃定义层。这里我们会介绍如何使用 Module 来自定义层,从而可以被反复调用
1.2.1 自定义层
不含模型参数的层
# 不含模型参数的层
# 下面构造了一个将输入减去均值后输出的层,层的计算定义在forward中
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
if __name__=='__main__':
layer = MyLayer()
x = torch.tensor([1,2,3,4,5],dtype=torch.float)
print(layer(x))
>>> out:
>>>tensor([-2., -1., 0., 1., 2.])
含模型参数的层
使用Parameter函数,它可以将不可训练的张量转化为可训练的参数类型,同时将转化后的张量绑定到模型可训练参数的列表中,当更新模型的参数时一并将其更新
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
self.linear.weight = torch.nn.Parameter(torch.zeros(input_dim, output_dim))
self.linear.bias = torch.nn.Parameter(torch.ones(output_dim))
def forward(self, input_array):
output = self.linear(input_array)
return output
net = NeuralNetwork(2, 3)
for param in net.parameters():
print(param)
结果:
Parameter containing:
tensor([[0., 0., 0.],
[0., 0., 0.]], requires_grad=True)
Parameter containing:
tensor([1., 1., 1.], requires_grad=True)
1.2.2 参加的一些神经网络层
- 二维卷积层 参考连接
import torch.nn as nn
conv2d=nn.conv2d(
# 输入的四维张量[N, C, H, W]中的C了,即输入张量的channels数
in_channels: int,
# 期望的四维输出张量的channels数
out_channels: int,
# 卷积核的大小,注意需要写一个tuple:(2,3)
kernel_size: _size_2_t,
# 卷积核在图像窗口上每次平移的间隔,即所谓的步长
stride: _size_2_t = 1,
# 图像填充
padding: _size_2_t = 0,
# 是否采用空洞卷积,默认为1(不采用)
dilation: _size_2_t = 1,
# 是否采用分组卷积
groups: int = 1,
# 是否要添加偏置参数作为可学习参数的一个,默认为True。
bias: bool = True,
# 即padding的模式,默认采用零填充。
padding_mode: str = 'zeros' # TODO: refine this type)
# 其shape必须为4维的,将数据转成四维
x = torch.linspace(1, 1000, 1000).view(1, 10, 20,5)
conv2d = nn.Conv2d(10,20, kernel_size=(2,2))
y = conv2d(x)
print('y shape = ', y.shape)
print('weight shape = ', conv2d.weight.shape)
>>>y shape = torch.Size([1, 20, 19, 4])
>>>weight shape = torch.Size([20, 10, 2, 2])
- 池化层 参考链接
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。 不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。 该运算也分别叫做最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始, 按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
torch.nn.MaxPool2d(
# 池化窗口大小
kernel_size,
# 移动步长
stride=None,
# 输入的每一条边补充0的层数
padding=0,
# 控制池化窗口中元素歩幅的参数
dilation=1,
# 如果等于True,会返回输出最大值的序号
return_indices=False,
# 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
ceil_mode=False)
pool = torch.nn.MaxPool2d(3, stride=1)
#在这里插入代码片#import torch.autograd # 该方法用来包装tensor和梯度
x = torch.autograd.Variable(torch.randn(20, 16, 50))
out = pool(x)
out.shape
1.3 实现简单的分类模型
参考连接
- 构建用于分类的数据集
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
# 先构建数据集
n_data=torch.ones(100,2)
x_0=torch.normal(2*n_data,1)
#x_0的shape是(100,2),值的均值为2*1,标准差为1
y_0=torch.zeros(100)
#y_0的shape是(100,)
x_1=torch.normal(-2*n_data,1)
#x_1的shape是(100,2),值的均值为-2*1,标准差为1
y_1=torch.ones(100)
#y_1的shape是(100,)
x=torch.cat((x_0,x_1))
#默认沿着列的方向合并
y=torch.cat((y_0,y_1)).type(torch.LongTensor)
#!!!必须得修改类型,否则之后报错
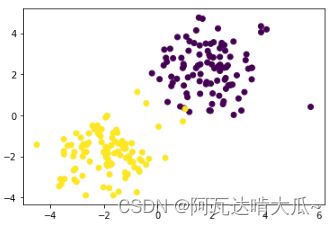
#数据可视化
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
- 构建神经网络
class Net(torch.nn.Module):
def __init__(self,n_input,n_hidden,n_output):
super(Net,self).__init__()
# 构建一个隐藏层
self.hidden=torch.nn.Linear(n_input,n_hidden)
# 构建一个输出层
self.out=torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x=F.relu(self.hidden(x))
x= self.out(x)
return x
- 模型的训练
# 选择优化器SGD随机梯度下降算法
# torch.optim是一个实现了各种优化算法的库
optimizer=torch.optim.SGD(net.parameters(),lr=0.2)
#定义损失函数
loss_func=torch.nn.CrossEntropyLoss()
#模型训练
for epoch in range(100):
# 预测值
prediction = net(x)
# 计算误差
loss = loss_func(prediction,y)
# 清空参与更新的参数值
optimizer.zero_grad()
# 误差反向传播,计算参数更新值
loss.backward()
# #将参数更新值施加到net的parameters上
optimizer.step()
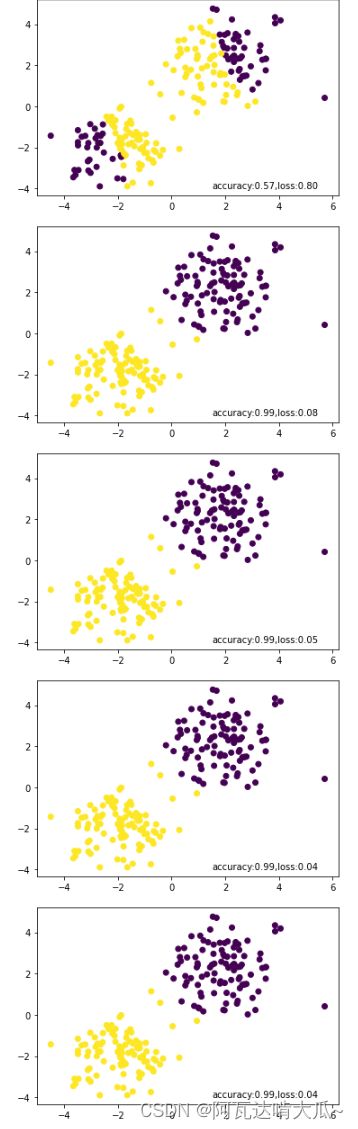
if epoch%10==0:
# 获取预测真实值
predict=torch.max(F.softmax(prediction,dim=0),axis=1)[1]
# 计算准确率
predict=predict.data.numpy()
target=y.data.numpy()
accuracy=sum(predict==target)/predict.size
#分类结果可视化
plt.scatter(x[:,0],x[:,1],c=predict)
plt.text(1.5,-4,'accuracy:{acc:.2f},loss:{loss:.2f}'.format(acc=accuracy,loss=loss))
plt.show()
结果如下: