kaggle实战:Titanic
文章目录
- 一、问题重述
-
- 1.1 问题描述
- 1.2 数据集
- 1.3 提交格式
- 二、问题求解:决策树
-
- 2.1导入模块
- 2.2载入数据
- 2.3探索数据
- 2.4数据预处理
-
- 2.4.1 无关变量处理
- 2.4.2缺失值的处理
- 2.4.3 非数值变量处理
- 2.5 获取特征矩阵和目标矩阵
- 2.5 划分测试集和训练集
- 2.6模型建立
一、问题重述
1.1 问题描述
泰坦尼克号的沉没是历史上最臭名昭著的沉船之一。1912 年 4 月 15 日,在她的初次航行期间,被广泛认为“不沉”的泰坦尼克号在与冰山相撞后沉没。不幸的是,船上的每个人都没有足够的救生艇,导致 2224 名乘客和船员中有 1502 人死亡。虽然幸存下来有一些运气因素,但似乎有些人比其他人更有可能幸存下来。在这个挑战中,我们要求您构建一个预测模型来回答这个问题:“什么样的人更有可能生存?” 使用乘客数据(即姓名、年龄、性别、社会经济阶层等)。
1.2 数据集
在本次比赛中,您将获得两个相似的数据集,其中包括姓名、年龄、性别、社会经济等级等乘客信息。一个数据集名为“train.csv”,另一个名为“test.csv” .
Train.csv 将包含一部分乘客的详细信息(确切地说是 891 名),重要的是,将揭示他们是否幸存下来,也被称为“地面真相”。
test.csv 数据集包含类似的信息,但没有透露每位乘客的“真实情况”。预测这些结果是你的工作。
使用您在 train.csv 数据中找到的模式,预测船上的其他 418 名乘客(在 test.csv 中找到)是否幸存下来。
1.3 提交格式
提交文件格式:您应该提交一个包含 418 个条目和一个标题行的 csv 文件。如果您有额外的列(PassengerId 和 Survived 之外)或行,您的提交将显示错误。
该文件应该正好有 2 列:
- 乘客 ID(按任意顺序排序)
- 幸存(包含您的二元预测:1 表示幸存,0 表示已故)
二、问题求解:决策树
2.1导入模块
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV, cross_val_score
import numpy as np
2.2载入数据
#导入数据
data=pd.read_csv("E:/21国赛/Titannic/train.csv")
2.3探索数据
#探索数据
data.head()#展示数据表前几行数据
输出结果:

data.info()#展示数据表缺失值
输出结果:
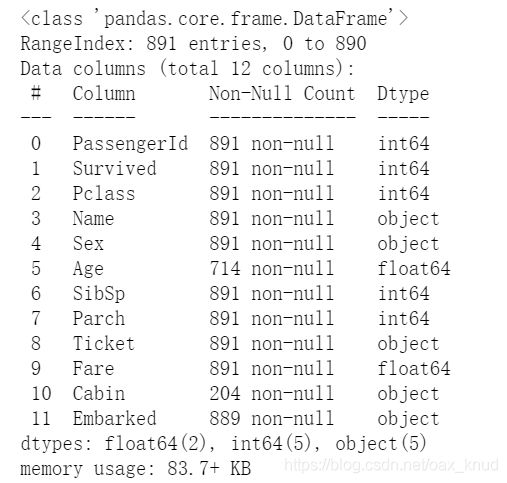
可以看出数据表总共优891个数据,其中Age,Cabin,Embarked存在缺失值。因此我们要对缺失值进行处理。
2.4数据预处理
2.4.1 无关变量处理
通过分析,我们可以假设,Name,Ticket,Cabin与乘客的生存情况无关,因此,我们将这三个变量从数据表中除去。
data.drop(['Cabin','Name','Ticket'],inplace=True,axis=1)
输出结果:
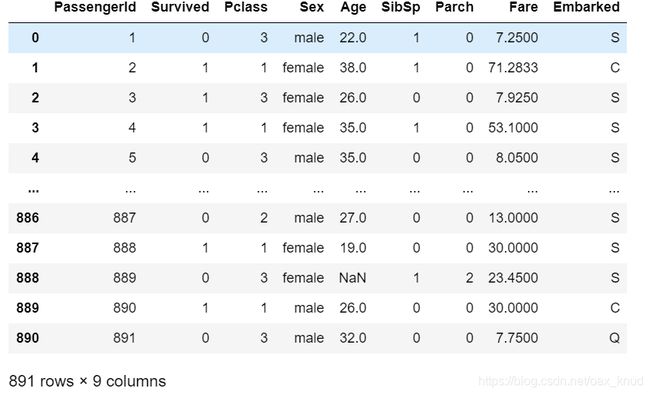
2.4.2缺失值的处理
对于Cabin由于变量与成可存活相关性不大,且缺失值过多,我们直接将其除去。
对于Age,有缺失值较小,我们将期使用平均值填补。
data["Age"]=data["Age"].fillna(data["Age"].mean())
输出结果:

由于Embarked的缺失值只有两个,因此,我们将这两行删除
data=data.dropna(axis=0)
输出结果:
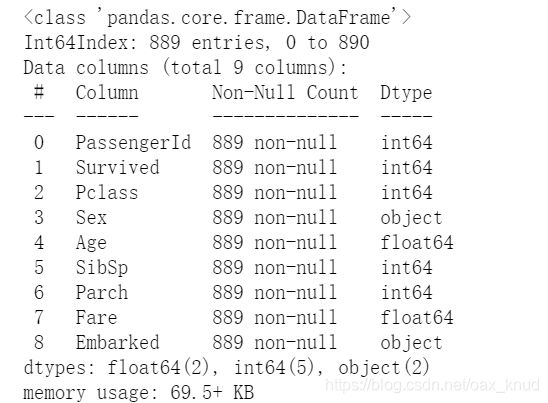
2.4.3 非数值变量处理
对于Embarked和Sex两个变量,可以看出他们的值为非数值类型,因此,我们将其转化为数值类型。
labels=data["Embarked"].unique().tolist()
data["Embarked"]=data["Embarked"].apply(lambda x:labels.index(x))
data["Sex"]=(data["Sex"]=='male').astype("int")
输出结果:
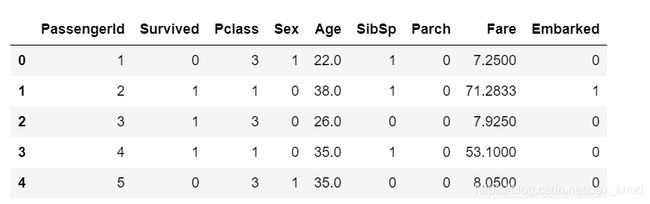
2.5 获取特征矩阵和目标矩阵
X = data.iloc[:,data.columns != "Survived"]#特征矩阵
y = data.iloc[:,data.columns == "Survived"]#目标矩阵
输出结果:
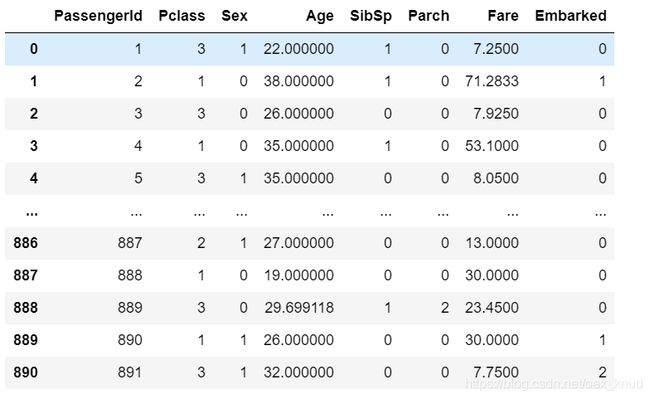
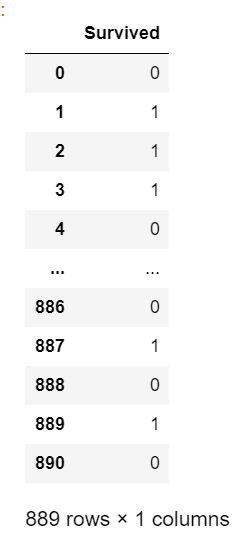
2.5 划分测试集和训练集
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#将训练集和测试集索引排序
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
Xtrain
输出训练集的特征数据:
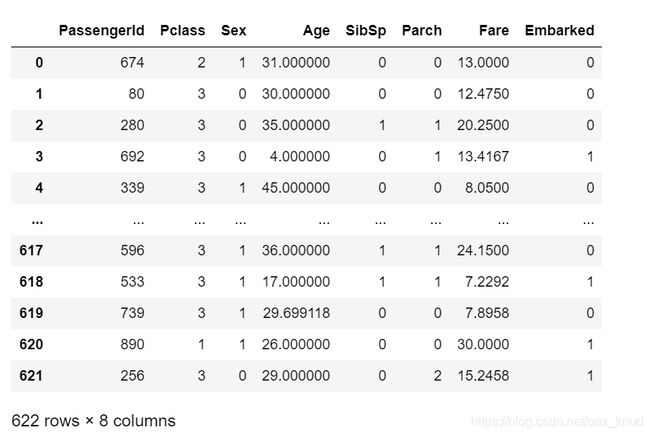
2.6模型建立
采用决策树分类树:
clf=DecisionTreeClassifier(random_state=25)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
print(score)
输出结果:

采用交叉验证:
clf=DecisionTreeClassifier(random_state=25)
score=cross_val_score(clf,X,y,cv=10).mean()
print(score)
输出结果:

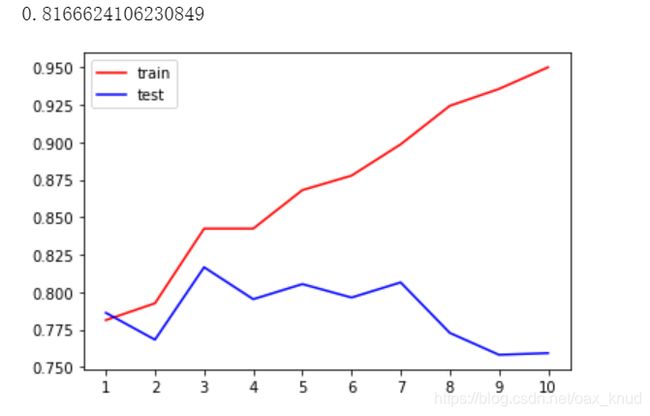
采用单参数优化:
tr=[]
te=[]
for i in range(10):
clf=DecisionTreeClassifier(criterion='entropy'
,random_state=25
,max_depth=i+1
)
clf.fit(Xtrain,Ytrain)
score_train=clf.score(Xtrain,Ytrain)
score_test=cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_train)
te.append(score_test)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
输出结果:
采用网格搜索多参数优化:
#网格搜索:能够帮助我们同时调整多个参数的技术,枚举技术
gini_threholds=np.linspace(0,0.5,50)
#entropy_threholds=np.linspace(0,50,50)
clf=DecisionTreeClassifier(random_state=25)
#一串参数以及这些参数对应的取值范围
parameters={"criterion":("gini","entropy")
,"splitter":("best","random")
,"max_depth":[*range(1,10)]
,"min_samples_leaf":[*range(1,50,5)]
,"min_impurity_decrease":[*np.linspace(0,0.5,50)]
}
GS=GridSearchCV(clf,parameters,cv=10)
GS.fit(Xtrain,Ytrain)
输出结果:

得到最终模型:
clf=DecisionTreeClassifier(criterion='entropy'
,random_state=25
,splitter='random'
,max_depth=4
# ,min_impurity_split=0.0
,min_samples_leaf=1
)
score=cross_val_score(clf,X,y,cv=10).mean()
print(score)
准确率:0.8087717058222677