pandas学习笔记
一、pandas库的Series类型
1、初始化
1、一维Series可以用一维列表初始化
a=pd.Series([1,3,5,np.nan,6,5])
2、索引
1、默认的情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的
b=pd.Series([1,3,5,np.nan,6,5],index=['a','b','c','d','e','f'])
print(b)
2、索引——数据行标签
a.index
3、取值
a.values
4、切片
a[2:5]
5、索引赋值
a.index=list('abcdef')
6、根据默认索引取值
ser.value_count().index[0:2]
3、查看数据
1)Series.take(参数)
Series.take(indices, axis=0, convert=None, is_copy=True, **kwargs)
参数说明:
| 参数 | 说明 |
|---|---|
| indices | 一个整数数组,指示要采取的位置。 |
| axis | 选择元素的轴。0:行,1:列 |
| convert | 是否将负指数转换为正指数 |
| is_copy | 是否返回原始对象的副本。 |
Series.take(indices, axis=0, convert=None, is_copy=True, **kwargs)
例:
sr = pd.Series(['New York', 'Chicago', 'Toronto', 'Lisbon', 'Rio', 'Moscow'])
sr.take(indices = [0, 2])#获取了sr中第1个和第3元素
二、DataFrame类型
1、初始化
1)传入二维数组
df=pd.DataFrame(np.random.randn(6,4))
df ##默认使用0、1、2.。。作为索引index
2)传入一个字典
df1=pd.DataFrame({'A':1,'B':pd.Timestamp('20200101'),'C':pd.Series(1,index=list(range(4)),dtype=float),'D':np.array([3]*4,dtype=int),'E':pd.Categorical(['test','train','test','train']),'F':'abc'})
df1
3)读取文件
df_mv=pd.read_excel(r'路径')
4)列表重塑
li.reshape
#将系列重塑ser为具有 7 行 5 列的数据框
ser = pd.Series(np.random.randint(1, 10, 35))
df=pd.DataFrame(ser.values.reshape(7,5))
2、索引
1)df.columns=[列标]
设值列表
2)df.index=[行号]
3)df.loc[[index],[column]]
df.loc[[index],[column]]通过标签选择数据
df.loc[[index],[column]]通过标签选择数据
df_mv.loc[[1,3,4],['名字','评分']]
4)条件选择
df_mv[df_mv['产地']=='中国大陆'][:5]
df_mv[(df_mv.产地=='美国')&(df_mv.评分>9)].head()
df_mv[((df_mv.产地=='美国')|(df_mv.产地=='中国大陆'))&(df_mv.评分>9)].head()
5)df.rename()
于更改行列标签,即行和列的索引,可以传入一个字典或则一个函数。
df.rename(index={...}columns={...})
df.rename()用于更改行列标签,即行和列的索引,可以传入一个字典或则一个函数。
df.rename(lambda x:x+11)#索引从11开始排
df.rename(index={0:'a',1:'b'})
6)df.reindex()
重新索引:DataFrame
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
参数说明:
| 参数 | 说明 |
|---|---|
| labels | 新标签/索引使“ axis”指定的轴与之一致。 |
| index, columns | 要符合的新标签/索引。最好是一个Index对象,以避免重复数据 |
| axis | 轴到目标。可以是轴名称(“索引”,“列”)或数字(0、1)。 |
| method | {None,“ backfill” /“ bfill”,“ pad” /“ ffill”,“ nearest”},可选 |
| copy | 即使传递的索引相同,也返回一个新对象 |
| level | 在一个级别上广播,在传递的MultiIndex级别上匹配索引值 |
| fill_value | 在计算之前,请使用此值填充现有的缺失(NaN)值以及成功完成DataFrame对齐所需的任何新元素。如果两个对应的DataFrame位置中的数据均丢失,则结果将丢失。 |
| limit | 向前或向后填充的最大连续元素数 |
| tolerance | 不完全匹配的原始标签和新标签之间的最大距离。匹配位置处的索引值最满足方程abs(index [indexer]-target) |
df.reindex(range(len(df)))
7)df.set_index()
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数说明:
| 参数 | 说明 |
|---|---|
| keys | 列标签或列标签/数组列表,需要设置为索引的列 |
| drop | 默认为True,删除用作新索引的列 |
| append | 是否将列附加到现有索引,默认为False。 |
| inplace | 输入布尔值,表示当前操作是否对原数据生效,默认为False。True:即改变原来的索引 |
| verify_integrity | 检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。 |
#将PassengerId设置为索引
df.set_index('PassengerId')
3、查看数据
1)df.head(n)
2)df.tail(n)
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5)
3)df.index
下标使用index属性查看
4)df.columns
列标使用columns属性查看
5)df.values
数据值使用values查看
6) df.iloc[索引/切片]
显示行,左闭右开
7)df.loc[[行],[列]]
选择数据,左闭右闭
8)df.shape
显示现状
9)df.ndim
显示维度
10)df[列].dtype
列数据类型
11)df.info()
相关信息概览
12)df.describe()
综合统计结果
13)df.loc[a1,a2]
标签索引:只能是定标签名字,即自定义索引
参数说明:
| 参数 | 说明 |
|---|---|
| a1 | 行标签,可以切片,也可以为一个列表 |
| a2 | 列标签,可以切片,也可以为一个列表 |
14)df.iloc[a1,a2]
位置索引:只能通过原始的索引,不能使用自定义索引
参数说明:
| 参数 | 说明 |
|---|---|
| a1 | 行标签,可以切片,也可以为一个列表 |
| a2 | 列标签,可以切片,也可以为一个列表 |
15)df.ix[a1,a2]
混合索引:即可用位置索引,也可以用户标签索引
16)df.query()
df.query(expr, inplace = False, **kwargs)
参数说明:
| 参数 | 说明 |
|---|---|
| expr | 要评估的查询字符串; 可以在环境中引用变量,在变量前面加上@字符(@a+b); 也可以通过在反引号中将空格或运算符括起来来引用它们 |
| inplace | 查询是应该修改数据还是返回修改后的副本 |
1 # 查询B列中数值为2的行记录
print(df.query('B == 2'))
2 #查询A列数值小于B列的行记录
print(df.query('A < B'))
# 等价于
print(df[df.A < df.B])
3 #查询B列数值和C C列相等的行记录
#注:对于名称中带有空格的列名,python2可以用反引号引用,但是python3已经取消了,所以可以用下面的方法
print(df[df.B == df['C C']])
4 #查询A列小于B列,且A列小于C C列的数据
#注意对于C C列的列名中间有空格或运算符等其他特殊符号的情况,上文提到,要用反引号(就是键盘上第二排第一个按键,有‘~’这个符号的按键)。
df.query('A < B & A < `C C`')
17)df.dtypes
查看各列(Series)类型
#查看每个列的数据类型
pokemon.dtypes
18)s.unique()
获取唯一值,返回一个列表
df['item_name'].unique()#返回该列所有唯一值,一个列表
19)s.nunique()
获取唯一值的个数,返回一个数字,可用于DataFrame
df['item_name'].nunique()#返回一个数字
df.nunique()#作用于dataframe,返回各列唯一值的数量
out:order_id 1834
quantity 9
item_name 50
choice_description 1043
item_price 78
dtype: int
20)s.vlaue_counts()
计算每个唯一值的频率计数。
value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用
默认是会降序的
df['年代'].value_counts()[:10]#计算列取重后的值数量
#在choice_description中,下单次数最多的商品是什么?
df['choice_description'].value_counts().head(1)
21)df.filter()
df.filter(items=None, like=None, regex=None, axis=None)
参数说明:
| 参数 | 说明 |
|---|---|
| item | 对列进行筛选 |
| like | 表示用正则进行匹配 |
| regex | 进行筛选 |
| axis | axis=0表示对行操作,axis=1表示对列操作 |
其中的参数 items, like, 和 regex parameters 被强制执行为相互排斥,即只能有一个存在
22)df.any() and df.all()
1、df.all(axis=0, bool_only=None, skipna=True, level=None)
返回是否所有元素都为真(可能在轴上),即都为镇才返回
参数说明:
| 参数 | 说明 |
|---|---|
| axis | 0或’index’;1或’columns’;None。默认为0。指出哪个轴应该减少。0或’index’:减少索引,返回索引为原始列标签的Series。1或’columns’:减少列,返回一个索引为原始索引的Series。None:减少所有轴,返回一个标量。 |
| skipna | 默认 True,排除NA/null值。如果整个row/column为NA,并且skipna为True,那么对于空row/column,结果将为True。如果skipna是False,那么NA就被当作True,因为它们不等于零。 |
2、df.any(axis=0, bool_only=None, skipna=True, level=None)
返回是否至少一个元素为真,即有一个为真则返回
23)s.diff()
计算相对于当前的前一个值的差,本行与前一行的差
#计算前一天与后一天收盘价的差值
df['收盘价(元)'].diff()
#等价于
df['收盘价(元)']-df.shift()['收盘价(元)']
24)s.pct_chang()
计算与前一行的变化量
#计算前一天与后一天收盘价变化率
df['收盘价(元)'].pct_change()
#计算前两天的收盘价变化率
df['收盘价(元)'].pct_change(2)
3、数据操作
1)行的 操作
1、查看行数据
df_mv.iloc[0]
df_mv.iloc[0:5]#左闭又开
df_mv.loc[0:5]#左闭右闭
2、添加一行
dit={'名字':'复仇者联盟3',
'投票人数':123456,
'类型':'剧情/科幻',
'产地':'美国',
'上映时间':'2017-05-04 00:00:00',
'时长':142,
'年代':2017,
'评分':8.7,
'首映地点':'美国'}
s=pd.Series(dit)
s.name=38738
df_mv=df_mv.append(s)
3、删除一行
df_mv=df_mv.drop([行号])
4、df.drop()
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise’)
参数说明:
| 参数 | 说明 |
|---|---|
| labels | 待删除的行名or列名; |
| axis | 删除时所参考的轴,0为行,1为列;默认是0 |
| index | 待删除的行名 |
| columns | 待删除的列名 |
| level | 多级列表时使用,暂时不作说明 |
| inplace | 布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本 |
2)列的操作
1、查看列数据
df_mv['列名'][0:5]
df_mv[['列1','列2']][:5]
2、增加一列
df_mv['列名']=range(1,len(df_mv)+1)列每行的内容
3、插入一列 df.insert()
DataFrame.insert(loc, column, value, allow_duplicates=False)
| 参数 | 说明 |
|---|---|
| loc | 参数column插入的位置,如果想插入到第一例则为0,取值范围: 0 <= loc <= len(columns),其中len(columns)为Dataframe的列数 |
| column | 给 插入数据value取列名,可为数字,字符串等 |
| value | 可以是整数,Series或者数组等 |
| allow_duplicates | 默认 False,如果想完成重复值的插入需要把allow_duplicates设置为True |
df.insert(想要插入的索引,列名,数据) # 数据可以为数组或Series
frame.insert(0, 'num', np.ones(5))
4、删除一列
df_mv=df_mv.drop('序号',axis=1)
3)移动行或列
df.shift()
df.shift()#整体向下移动一行,顶行填充nan
df.shift(3)#整体向下移动三行,顶部填充nan
df.shift(-1)#向上移动一行
df.shift(1,axis=1)#向右移动一列
df.shift(-1,asis=1)#向左移动一列
df['收盘价(元)']-df.shift()['收盘价(元)']#实现了df['收盘价(元)'].diff()
4、对齐运算
使用后df+df默认的是有相同标签的会相加,没有则以nan填充,其他也类似
单词:
| 单词 | 意思 |
|---|---|
| add | 加 |
| subtract | 减 |
| multiply | 乘 |
| divide | 除 |
| power | 乘方 |
算术运算表:
| 方法 | 描述 |
|---|---|
| add,radd | 加法(+) |
| sub,rsub | 减法(-) |
| div,rdiv | 除法(/) |
| floordiv,rfloordiv | 整除(//) |
| mul,rmul | 乘法(*) |
| pow,rpow | 幂次方(**) |
| 注释: | 带有r开头的表示它运算会翻转,后面的算数前面的,如df1.div(df2)表示df1/df2,而df1.rdiv(df2)表示df2/df1 |
df1.add(df2,)
df1.add(df2,level=None, fill_value=None, axis=0)
返回算数运算的结果
参数说明:
| 参数 | 说明 |
|---|---|
| fill_value | 添加前要在系列/列表中用NaN替换的值,如果两个df对应的行列都为nan则返回nan |
| level | 多索引时级别的整数值 |
df1.add(df2,fill_value=0) # df1加df2,如果有nan则填充为0运算
df1.sub(df2,fill_value=0) # df1减df2,如果有nan则填充为0运算
df1.mul(df2,fill_value=0) # df1乘df2,如果有nan则填充为0运算
df1.div(df2,fill_value=0) # df1除df2,如果有nan则填充为0运算
三、数据清洗
| 函数 | 描述 |
|---|---|
| df.isnull | 返回一个布尔值对象,判断哪些值是缺失值 |
| df.notnull | isnull的否定式 |
| df.fillna | 对缺失值进行填充 |
| df.dropna | 根据标签中的缺失值进行过滤,删除缺失值 |
1、缺失值处理
1)判断缺失值
df.isnull()
df_mv[df_mv['名字'].isnull()].head()
df.isnull().sum().sort_values(ascending=False)#判断每一列的缺失值个数,并降序排序
2)填充缺失值
df.fillna()
fillna参数说明:
| 参数 | 说明 |
|---|---|
| inplace | True:直接修改原对象,False:创建一个副本,修改副本,原对象不变(缺省默认) |
| method | 取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None, pad/ffill:用前一个非缺失值去填充该缺失值,向前填充, backfill/bfill:用下一个非缺失值填充该缺失值,向后填充 None:指定一个值去替换缺失值(缺省默认这种方式) |
| limit | 限制填充个数 |
| axis | 修改填充方向 |
df_mv['名字'].fillna('未知电影',inplace=True)
3)删除缺失值
df.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
dripna参数说明:
| 参数 | 说明 |
|---|---|
| axis | {0 or ‘index’, 1 or ‘columns’}, default 0,0 or ‘index’:删除包含丢失值的行, 1, or ‘columns’:删除包含丢失值的列 |
| how | {‘any’, ‘all’}, default ‘any’,‘any’: 只要有缺失值出现,就删除,‘all’: 所有的值都缺失,才删除 |
| thresh | int,保留含有int个非空值的行,如果缺失值(NaN)的数量大于thresh,将删除 |
| subset | 对特定的列进行缺失值删除处理,传入列表 |
| inplace | True:直接修改原对象,False:创建一个副本,修改副本,原对象不变(缺省默认) |
df_mv1=df_mv.dropna()
4)插值填充
1、df.interpolate()
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)
参数说明:
| 参数 | 说明 |
|---|---|
| method | str,默认为‘linear’使用插值方法。 ‘linear’:忽略索引,线性等距插值。这是MultiIndexes支持的唯一方法。 ‘time’: 在以天或者更高频率的数据上插入给定的时间间隔长度数据。 ‘index’, ‘values’: 使用索引的实际数值。 ‘pad’:使用现有值填写NaN。 ‘nearest’, ‘zero’, ‘slinear’, ‘quadratic’, ‘cubic’, ‘spline’, ‘barycentric’, ‘polynomial’: 传递给 scipy.interpolate.interp1d。这些方法使用索引的数值。‘polynomial’ 和 ‘spline’ 都要求您还指定一个顺序(int),例如 ,df.interpolate(method=‘polynomial’, order=5) ‘krogh’,‘piecewise_polynomial’,‘spline’,‘pchip’,‘akima’:包括类似名称的SciPy插值方法。 ‘from_derivatives’:指 scipy.interpolate.BPoly.from_derivatives,它替换了scipy 0.18中的’piecewise_polynomial’插值方法。 |
| axis | {0或’index’,1或’columns’,None},默认为None;沿轴进行interpolate。 |
| limit | int;要填充的连续NaN的最大数量。必须大于0。 |
| inplace | bool,默认为False;如果可以,更新现有数据。 |
| limit_direction | {‘forward’,‘backward’,‘both’},默认为’forward’;如果指定了限制,则将沿该方向填充连续的NaN。 |
| limit_area | {None, ‘inside’, ‘outside’}, 默认为None;如果指定了限制,则连续的NaN将填充此限制。 None:无填充限制。 ‘inside’:仅填充有效值包围的NaN。 ‘outside’: 仅在有效值之外填充NaN。 |
s = pd.Series([0, 1, np.nan, 3])
s.interpolate()#线性等距插nan值
5)异常值处理
对于异常值,一般来说数量都会很少,在不影响整体数据分布的情况下,我们直接删除就可以了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XZ35DDk6-1640316998300)(图片\屏幕截图 2021-09-30 094301.png)]
6)重复值判断
df.duplicated(subset=None, keep=‘first’)
返回Boolean
参数说明:
| subset=None | 列标签或标签序列,可选# 只考虑某些列来识别重复项;默认使用所有列 |
| keep | {‘first’,‘last’,False} # - first:将第一次出现重复值标记为True # - last:将最后一次出现重复值标记为True # - False:将所有重复项标记为True |
7)删除重复值
data.drop_duplicates(subset=[‘A’,‘B’],keep=‘first’,inplace=True)
参数说明:
| 参数 | 说明 |
|---|---|
| subset | 列名,可选,默认为None |
| keep | {‘first’, ‘last’, False}, 默认值 ‘first’ first: 保留第一次出现的重复行,删除后面的重复行。 last: 删除重复项,除了最后一次出现。 False: 删除所有重复项。 |
| inplace | 布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。 (inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。) |
单词:
| 单词 | 意思 |
|---|---|
| replication | 复制 |
| duplicate | 无关要的)重复(某事),复制 |
| inplace | 原地 |
| keep | 保持,处于 |
8)替换
df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method=‘pad’,)
参数说明:
| 参数 | 说明 |
|---|---|
| to_replace | 被替换的值 |
| value | 替换后的值 |
| inplace | 是否要改变原数据,False是不改变,True是改变,默认是False |
| limit | 控制填充次数 |
| regex | 是否使用正则,False是不使用,True是使用,默认是False |
| method | 填充方式,pad,ffill,bfill分别是向前、向前、向后填充 |
df['priority']=df['priority'].replace(to_replace=['yes','no'],value=[True,False])
#将priority列的yes和no用True和False替换
df.replace({'A': r'^ba.$'}, {'A': 'new'}, regex=True)
#使用正则表达式,不同的值替换不同的内容
9)映射
Pandas对DataFrame单列/多列进行运算(map,apply,transform,agg)
1.单列运算map
Series.map(arg, na_action=None)
参数说明:
| 参数 | 说明 |
|---|---|
| arg | 函数, 字典或系列。 |
| na_action | {无, ‘忽略’}, 默认值无。如果忽略, 它将返回空值, 而不将其传递给映射对应关系。 |
在Pandas中,DataFrame的一列就是一个Series, 可以通过map来对一列进行操作:
df['col2'] = df['col1'].map(lambda x: x**2)
data["gender"] = data["gender"].map({"男":1, "女":0})#①使用字典进行映射
2.多列运算apply
1)Series.apply()
该函数的功能是在序列的每一个元素上应用自定义函数,函数的格式如下:
Series.apply(func, convert_dtype=True, args=(), **kwds)
参数说明:
| 参数 | 说明 |
|---|---|
| func | 要应用到序列上每一个元素的函数; |
| convert_dtype | 布尔数据类型,默认为 True,表示寻找到最合适的结果类型; |
| args=() | 元组数据类型,表示传入 func 函数的参数; |
| **kwds | 表示传入 func 函数的参数。 |
2)DataFrame.apply()
该函数的功能是在 DataFrame 对象指定的轴方向应用自定义函数,函数的格式如下:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
参数说明:
| 参数 | 说明 |
|---|---|
| func | 要应用在 DataFrame 对象的行或列的函数; |
| axis | 用于控制是将 DataFrame 对象的行数据,还是列数据传入 func 函数。 如果 axis=1 则将 DataFrame 对象的行数据作为 Series 的数据结构传入 func 函数。它的默认值是 0,列; |
| broadcast | 布尔数据类型,默认为 False。对于聚合函数,返回具有传播值的相同大小的对象; |
| row | 布尔数据类型,默认为 False。其作用是将每行或每列转换为一个系列。如果 row=True,则传递的函数将接收 ndarray 对象; |
| reduce | 默认为 None,表示尽量减少应用程序; |
| args=() | 元组数据类型,表示传入 func 函数的参数; |
| **kwds | 表示传入 func 函数的参数。 |
要对DataFrame的多个列同时进行运算,可以使用apply,例如col3 = col1 + 2 * col2:
df['col3'] = df.apply(lambda x: x['col1'] + 2 * x['col2'], axis=1)
3.applymap
applymap()使用 applymap 函数可以格式化 DataFrame,
函数的功能是将自定义函数作用于DataFrame的所有元素
df.applymap(lambda x:"%.2f" % x)
#将DataFrame中所有的值保留两位小数显示
10)管道
1、df.pipe()
语法结构:df.pipe(<函数名>, <传给函数的参数列表>)
df.pipe(lambda x,a,b:x[(x['A']>a)&(x['B']<b)],1,30) #x:传入的df,a:定义的一个变量有后面参数列表传入,b:定义的一个变量有后面参数列表传入
11)合并
1、df.merge(合并)
pd.merge(df1,df2,on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True)
参数说明:
| 参数 | 说明 |
|---|---|
| on | 列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。 |
| left_on | 左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| right_on | 右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| left_index/ right_index | 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。 |
| how | 数据融合的方法。left,right,outer,inner,默认为inner |
| sort | 根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。 |
2、交集
how='inner’内连
pd.merge(df1,df2,on=['name','age','gender'])
3、并集
how='outer’外联
pd.merge(df1,df2,how='outer')
4、差集
先添加,在去重,不保留重复
df1=df1.append(df2)
df1.drop_duplicates(keep=False)
5、series的交并
可以将series转为set集合,用set的交并方法来获得,如果返回结果要为Series,可在转list后转Series
| set中的方法 | 描述 |
|---|---|
| intersection | 交集 |
| union | 并集 |
#un_id1,un_id2 为两个 Series 对象:
un_id1 = set(un_id1)
un_id2 = set(un_id2)
tmp = un_id1.intersection(un_id2) #交集
s1 = pd.Series([4,5,6,20,42])
s2 = pd.Series([1,2,3,5,42])
#如果返回结果要为Series,可在转list后转Series
# 求交集 #
pd.Series(list(set(s1).intersection(set(s2))))
# 求并集 #
pd.Series(list(set(s1).union(set(s2))))
ser1 = pd.Series([1, 2, 3, 4, 5])
ser2 = pd.Series([4, 5, 6, 7, 8])
jiao=pd.Series(list(set(ser1).intersection(set(ser2))))#交集
bing=pd.Series(list(set(ser1).union(set(ser2))))#并集
bing[~bing.isin(jiao)]#ser1ser2不共同集
6、df.append(追加)
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
功能说明:向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
参数说明:
| 参数 | 说明 |
|---|---|
| other | DataFrame、series、dict、list这样的数据结构 |
| ignore_index | 默认值为False,如果为True则不使用index标签 |
| verify_integrity | 默认值为False,如果为True当创建相同的index时会抛出ValueError的异常 |
| sort | boolean,默认是None,该属性在pandas的0.23.0的版本才存在。 |
1)添加字典
import pandas as pd
data = pd.DataFrame()
a = {"x":1,"y":2}
data = data.append(a,ignore_index=True)
print(data)
2)添加Series
import pandas as pd
data = pd.DataFrame()
series = pd.Series({"x":1,"y":2},name="a") # 不指定ignore_index参数,是指定name
data = data.append(series) # 不指定ignore_index参数
print(data)
3)添加list
data = pd.DataFrame()
a = [1,2,3] # 一维的
data = data.append(a) #以列的形式添加
print(data)
data = pd.DataFrame()
a = [[[1,2,3]]] # 二维的
data = data.append(a) # 以行的形式添加
print(data)
data = pd.DataFrame()
a = [[1,2,3],[4,5,6]]
data = data.append(a,ignore_index=True)
a = [[7,8,9],[10,11,12]]
data = data.append(a,ignore_index=True) #多次append追加数据时会出现相同索引,用ignore_index=True
print(data)
fname=r'd:/data/九江招聘_{0}.csv'
xueli=['本科', '中专', '高中', '大专', '初中及以下', '中技', '硕士', '博士']
dftmp=pd.DataFrame(columns=['count','学历'])
for xl in xueli:
df1=pd.read_csv(fname.format(xl),sep=',',encoding='gbk')
df1['发布时间']=pd.to_datetime(df1['发布时间'],format='%Y-%m-%d')
df1.set_index(df1['发布时间'],inplace=True)
df1['月份']=df1.index.month
count=df1[df1['月份']==9].size
s=pd.Series({'count':count,'学历':xl})
dftmp=dftmp.append(s,ignore_index=True)
dftmp
四、离散处理
再实际的数据分析项目中,对有的数据属性,我们往往并不关注数据的绝对取值,只关注它所处的区间或等级。
比如我们可以把评分9分及以上定义为A,7-9分为B,5-7分为C,3-5分为D,小于3分的为E。
离散化也可以称为分组、区间化
1、pd.cut()
pd.cut (x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False,duplicates=‘raise’)
| 参数 | 说明 |
|---|---|
| x | 被切分的类数组(array-like)数据,必须是1维的(不能用DataFrame); |
| bins | bins是被切割后的区间(或者叫“桶”、“箱”、“面元”),有3中形式: 一个int型的标量、标量序列(数组)或者pandas.IntervalIndex 。 |
| right | bool型参数,默认为True,表示是否包含区间右部。 比如如果bins=[1,2,3],right=True,则区间为(1,2],(2,3];right=False,则区间为(1,2),(2,3)。 |
| labels | 给分割后的bins打标签,比如把年龄x分割成年龄段bins后,可以给年龄段打上诸如青年、中年的标签。labels的长度必须和划分后的区间长度相等,比如bins=[1,2,3],划分后有2个区间(1,2],(2,3],则labels的长度必须为2。如果指定labels=False,则返回x中的数据在第几个bin中(从0开始)。分组标签必须比分组序列少一个,也就是必须要与组数相同 |
| retbins | bool型的参数,表示是否将分割后的bins返回,当bins为一个int型的标量时比较有用,这样可以得到划分后的区间,默认为False。 |
| precision | 保留区间小数点的位数,默认为3. |
| include_lowest | bool型的参数,表示区间的左边是开还是闭的,默认为false,也就是不包含区间左部(闭)。 |
| duplicates | 是否允许重复区间。有两种选择:raise:不允许,drop:允许。 |
df['评分等级']=pd.cut(df['评分'],[0,3,5,7,9,10],labels=['E','D','C','B','A'])
#把评分9分及以上定义为A,7-9分为B,5-7分为C,3-5分为D,小于3分的为E
bins=np.percentile(df['投票人数'],[0,20,40,60,80,100])#使用 np.percentile 进行分位数计算
df['热门程度']=pd.cut(df['投票人数'],bins,labels=['E','D','C','B','A']) #
2、pd.qcut()
pd.qcut(x,q,labels=None,retbins=False,precision=3,duplicates=‘raise’)
pandas的qcut可以把一组数字按大小区间进行分区,相当于cut的bin做了np.percentile()分位数操作
常用参数说明:
| 参数 | 说明 |
|---|---|
| x | 要进行分组的数据,数据类型为一维数组,或Series对象 |
| q | 组数,即要将数据分成几组,后边举例说明,列表,0~1 |
| labels | 可以理解为组标签,这里注意标签个数要和组数相等,分组标签必须比分组序列少一个,也就是必须要与组数相同 |
| retbins | 默认为False,当为False时,返回值是Categorical类型(具有value_counts()方法),为True是返回值是元组 |
#11将系列ser分成 10 个相等的十分位数,并用 bin 名称替换这些值。
ser = pd.Series(np.random.random(20))
#bins=np.percentile(ser,q=[0,10,20,30,50,70,80,90,100])
#print(bins)
#pd.cut(ser,bins)
pd.qcut(ser,[0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1],labels=['1th','2th','3th','4th','5th','6th','7th','8th','9th','10th'])
df['热门等级']=pd.qcut(df['评分人数'],[0,0.33,0.66,1],labels=['C','B','A'])
qcut与cut的主要区别:
qcut:传入参数,要将数据分成多少组,即组的个数,具体的组距是由代码计算
cut:传入参数,是分组依据。具体见示例
五、排序
1)索引排序
obj.sort_index(aixs,ascending)
2)Series的排序:
Series.sort_values(ascending=True, inplace=Flase)
参数说明:
| 参数 | 说明 |
|---|---|
| ascending | 默认为True升序排列,为Flase降序排序 |
| inplace | 是否修改原始的Series |
3)DataFrame的排序
DataFrame.sort_values(by, ascending=True, inplace=Flase )
参数说明:
| 参数 | 说明 |
|---|---|
| by | 字符串或者List<字符串>,单列排序或者多列排序 |
| ascending | bool或者list,升序还是降序,如果是list对应by的多列 |
| inplace | 是否修改原始的DataFrame |
1、按指定列排序
df.sort_values(by='列')[:5] ## 默认升序排列df.sort_values(by='投票人数',ascending=False)[:5] ##降序排序
2、多值排序
df.sort_values(by=['列1','列2'],ascending=False)[:5]
df.sort_values(by=['评分','投票人数'],ascending=[False,True])[:5]
4)自定义排序
使用CategoricalDtype将数据强制转换为具有有序性的类别类型
CategoricalDtype是具有类别和顺序的分类数据的类型[1]。它对于创建自定义排序非常有用[2]。让我们通过一个例子来看看这是如何工作的。
第一步,让我们导入CategoricalDtype。
from pandas.api.types import CategoricalDtype
第二步,创建一个自定义类别类型
自定义类型= CategoricalDtype( [排序的规则], ordered=True )
xueli_order=CategoricalDtype(['博士','硕士','本科','大专','高中','中专','中技','初中及以下'],ordered=True)
#第一个参数设置为['博士','硕士','本科','大专','高中','中专','中技','初中及以下']作为学历的唯一值。
#第二个参数ordered=True,将此变量视为有序。
#['博士' < '硕士' < '本科' < '大专' < '高中' < '中专' < '中技' < '初中及以下']
第三步,将要自定义排序的字段转为自定义类型
#调用astype(xueli_order)将大小数据强制转换为自定义类别类型
df['学历要求']=df['学历要求'].astype(xueli_order)
第四步,对该字段进行正常的排序
#调用相同的方法对值进行排序。
df.sort_values('学历要求')
from pandas.api.types import CategoricalDtype
xueli_order=CategoricalDtype(['博士','硕士','本科','大专','高中','中专','中技','初中及以下'],ordered=True)
df['学历要求']=df['学历要求'].astype(xueli_order)
df.sort_values('学历要求')
5)排名
s.rank(method=‘first’)
对series的值进行升序排名,输出为排名,当排名相同时,输出平均排名,method=‘first’排名相同时按照值在数组中出现的顺序排序
method取值说明:
| method取值 | 说明 |
|---|---|
| average | 默认,在相等分组中,为各个值分配平均排名 |
| first | 按值在原始数据中出现顺序分配排名 |
| min | 使用整个分组的最小排名 |
| max | 使用整个分组的最大排名 |
六、分组
1、df.groupby()
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表
参数说明:
| 参数 | 说明 |
|---|---|
1)单值分组
df.groupby(by=df[列])
group=df.groupby(df['产地'])先定义一个分组变量group
group.mean()可以计算分组后的各个统计量
分组内排序
df.groupby('B').apply(lambda x: x.sort_values('C', ascending=False))
df[['电影名称','制片国家/地区','评分']].groupby('制片国家/地区').apply(lambda x:x.sort_values('评分',ascending=False)).head(3)
2)多值分组
df.groupby(df[列1],df[列2])
df.groupby([df['产地'],df['年代']]).mean().head()
我们也可以传入多个分组变量
3)查看分组
通过调用groups属性查看分组结果,以一个字典的形式:
df.groupby('地区').groups
## 返回一个字典,keys是组名,values是同一组的索引,是一个列表存在
通过get_group()获得指定分组
df.groupby('收货地址').get_group('江西') # 获取江西分组
4)常见的聚合方法
| 方法 | 说明 |
|---|---|
| grouped.first() | 第一个值,默认为分组字段排序后的最小值 |
| grouped.last() | 最后个值,默认为分组字段排序后的最大值 |
| grouped.sum() | 和 |
| grouped.mean() | 平均值 |
| grouped.median() | 中位数 |
| grouped.count() | 个数 |
| grouped.min() | 最小值 |
| grouped.max() | 最大值 |
| grouped.std() | 标准差 |
| grouped.var() | 方差 |
| grouped.prod() | 积 |
| grouped.size() | 长度 |
s = pd.Series([1, 2, 3, 10, 20, 30], index = [1, 2, 3, 1, 2, 3])
grouped = s.groupby(level=0) # 唯一索引用.groupby(level=0),将同一个index的分为一组
print(grouped)
print(grouped.first(),'→ first:非NaN的第一个值\n')
print(grouped.last(),'→ last:非NaN的最后一个值\n')
print(grouped.sum(),'→ sum:非NaN的和\n')
print(grouped.mean(),'→ mean:非NaN的平均值\n')
print(grouped.median(),'→ median:非NaN的算术中位数\n')
print(grouped.count(),'→ count:非NaN的值\n')
print(grouped.min(),'→ min、max:非NaN的最小值、最大值\n')
print(grouped.std(),'→ std,var:非NaN的标准差和方差\n')
print(grouped.prod(),'→ prod:非NaN的积\n')
5)组的过滤操作
DataFrameGroupBy.filter(func, dropna=True,*args, **kwargs)
参数说明:
| 参数 | 说明 |
|---|---|
| func | 函数,函数应用于每个分组的子帧,应该返回 True 或 False。 |
| dropna | 删除未通过筛选器的组。默认为 True,如果为 False,则评估为 False 的组将填充 NaN |
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集。
- filter和匿名函数的使用,用来筛选groupby之后的数据。
- 注意:filter内函数传的是每个分组的数据表
df.groupby('地区').filter(lambda x:len(x)==2)#查询地区只有两个的
df1=df.groupby('district').filter(lambda x: x['age'].mean()>20)
#结果会将所有age>20的district的行选掉,返回所有其他值。
6)组的选择操作
有了 GroupBy 对象,可能希望对每个列进行不同的操作,使用类似于 [] 从 DataFrame 获取列:
groups=df.groupby('收货地址') # 得到一个分组对象
groups['买家实际支付金额'].sum() # 只选取列进行聚合
7)迭代
一个分组对象由组名,和分组后的df组成
groups=df.groupby('收货地址')
for name,group in groups: # name是分组的组名,group是分组后的df
print(name,group)
2、df.agg()
df.agg(func,axis = 0,** args,**kwargs )
| 参数 | 说明 |
|---|---|
| func | 函数,函数名称,函数列表,字典{‘行名/列名’:‘函数名’} |
| axis | 默认0 |
df_arows=df.agg(['max','min','mean'])
df_columns=df.agg({'col1':['sum','min'],'col2':['max','min'],'col3':['sum','min']})
df.groupby(['order_id','product_id']).agg(buy_cnt=('user_id','count'))#指定列名,列表是原列名和方法
agg内常用聚合函数
//求和; //; //; //; //; //;//;//;//; //; //; //; //;//;//
| 函数 | 说明 |
|---|---|
| np.sum() | 求和 |
| np.prod() | 所有元素相乘 |
| np.mean() | 平均值 |
| np.std() | 标准差 |
| np.var() | 方差 |
| np.median() | 中数 |
| np.power() | 幂运算 |
| np.sqrt() | 开方 |
| np.min() | 最小值 |
| np.max() | 最大值 |
| np.argmin() | 最小值的下标 |
| np.argmax() | 最大值的下标 |
| np.inf | 无穷大 |
| np.exp(10) | 以e为底的指数 |
| np.log(10) | 对数 |
#1) 运行代码,统计各城市的酒店数量和房间数量,以城市房间数量降序排列, 并打印输出前 10 条统计结果。
df[['酒店','城市','房间数']].groupby('城市').agg({'酒店':'count','房间数':'sum'}).sort_values('房间数',ascending=False).head(10)
3、pd.Grouper()
pandas.Grouper ( key = None,level = None,freq = None,axis = 0,sort = False ) [source]
Grouper允许用户为目标对象指定groupby指令
此规范将通过key参数选择列,或者如果给出了level或axis参数,则指定了目标对象的索引级别。
这些是本地设置,将覆盖“全局”设置,即传递给groupby本身的轴参数和level。
分组器
df.groupby(pd.Grouper(key='date', freq='60s'))
df.groupby(pd.Grouper(freq='4M'))#每连续四个月为一组
七、窗口函数
1、窗口函数可以与聚合函数一起使用,聚合函数指的是对一组数据求总和、最大值、最小值以及平均值的操作
2、可以与groupby配合使用
3、可以和聚合函数agg一起使用
1、移动窗口
df.rolling(window=n, min_periods=None, center=False)
常用参数说明:
| 参数 | 说明 |
|---|---|
| window | 默认值为1,表示窗口的大小,也就是观测值的数量 |
| min_periods | 表示窗口的最小观察值,默认于window的参数值相等 |
| center | 是否把中间值作为窗口标准,默认值为False |
window=3表示是每一列中依次紧邻的每 3 个数求一次均值。当不满足 3 个数时,所求值均为 NaN
#每3个数求求一次均值
print(df.rolling(window=3).mean())#(index1+index2+index3)/3
dft=pd.DataFrame(np.random.randint(1,100,50).reshape(10,5),columns=list('ABCDE'))
dft['sum_A']=dft['A'].rolling(3).sum()
dft['sum_A']=dft['A'].rolling(3,center=True).sum() # 以中间值为窗口中心
2、扩展窗口(滚动窗口)
df.expanding(min_periods=)
参数说明:
| 参数 | 说明 |
|---|---|
| min_periods | 指定最小观察值 |
扩展是指由序列的第一个元素开始,逐个向后计算元素的聚合值。设置 min_periods=3,表示至少 3 个数求一次均值
dft['exp_sum_A']=dft['A'].expanding().sum()#滚动累加
dft['exp_sum_A']=dft['A'].expanding(3).sum()#最少三个数累加
注意:
但rowling函数的窗口大小为df的长度时,指定min_periods=1后的效果与expanding()的效果一致
dft['rolling_sum_A']=dft['A'].rolling(len(dft),min_periods=1).sum()
#等价于
dft['exp_sum_A']=dft['A'].expanding().sum()#滚动累加
八、时间序列
1、pd.data_range(参数)
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
常用参数为start、end、periods、freq。说明:
| 参数 | 说明 |
|---|---|
| start | 指定生成时间序列的开始时间 |
| end | 指定生成时间序列的结束时间 |
| periods | 指定生成时间序列的数量 |
| freq | 生成频率,默认‘D’,可以是’H’、‘D’、‘M’、‘5H’、‘10D’、… |
频率说明:
| 别号 | 描述 |
|---|---|
| S | 秒 |
| T | 分 |
| H | 没小时频率 |
| D | 日历日频率,天 |
| M | 月结束频率,月 |
| Y | 年终频率 |
| 5H | 5小时 |
| 10D | 10天 |
| BM | 每个月的最后一天 |
| MS | 每个月的第一天 |
| W | 每周 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J47AejK9-1640316998302)(C:\Users\GJS\Desktop\markdown\python数据分析\图片\20191101162048218.png)]
还可以根据closed参数选择是否包含开始和结束时间,left包含开始时间,不包含结束时间,right与之相反。默认同时包含开始时间和结束时间。
函数调用时至少要指定参数start、end、periods中的两个。
pd.date_range('20200101','20200110')
pd.date_range('20200101',periods=10)
pd.date_range(end='20200110',periods=10)
2、pd.to_datetime()
pd.to_datetime(arg,format=)
将给定的数据按照指定格式转换成日期格式
| 参数 | 说明 |
|---|---|
| arg | 输入 |
| format | 日期格式 |
#将date列转化为datetime类型
data["Date"]= pd.to_datetime(data["Date"])
3、df.resample(freq)
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention=‘start’,kind=None, loffset=None, limit=None, base=0)
重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。得到的是一个分组,可用于对时间分组聚合
降采样:高频数据到低频数据
升采样:低频数据到高频数据
参数说明:
| 参数 | 说明 |
|---|---|
| 参数 | 说明 |
| freq | 表示重采样频率,例如‘M’、‘5min’,Second(15) |
| how=‘mean’ | 用于产生聚合值的函数名或数组函数,例如‘mean’、‘ohlc’、np.max等,默认是‘mean’,其他常用的值由:‘first’、‘last’、‘median’、‘max’、‘min’ |
| axis=0 | 默认是纵轴,横轴设置axis=1 |
| fill_method = None | 升采样时如何插值,比如‘ffill’、‘bfill’等 |
| closed = ‘right’ | 在降采样时,各时间段的哪一段是闭合的,‘right’或‘left’,默认‘right’ |
| label= ‘right’ | 在降采样时,如何设置聚合值的标签,例如,9:30-9:35会被标记成9:30还是9:35,默认9:35 |
| loffset = None | 面元标签的时间校正值,比如‘-1s’或Second(-1)用于将聚合标签调早1秒 |
| limit=None | 在向前或向后填充时,允许填充的最大时期数 |
series.resample('3T').sum()#降低采样频率为三分钟
4、时间的属性attributes
| 属性 | 描述 |
|---|---|
| time.year | 年 |
| time.month | 月 |
| time.day | 日 |
| time.hour | 时 |
| time.minute | 分 |
| time.second | 秒 |
5、s.dt 时间访问器
| 形式 | 描述 |
|---|---|
| s.dt.date | 日期 |
| s.dt.time | 时间 |
| s.dt.year | 年 |
| s.dt.month | 月 |
| s.dt.day | 日 |
| s.dt.hour | 时 |
| s.dt.minute | 分 |
| s.dt.second | 秒 |
| s.dt.strftime(date_format) | 格式化字符串的索引 |
df['time'].dt.strftime('%m-%d') # 获取月-日
df['time'].dt.year # 获取年
5、datetime.datetime
df['上映日期']
import re
import datetime
def parse(x):
time=re.findall('(\d{4}-\d{2}-\d{2})',x)
etime=datetime.datetime.strptime(time[0],'%Y-%m-%d').date()
for t in time:
ttime=datetime.datetime.strptime(t,'%Y-%m-%d').date()
if ttime<etime:
etime=ttime
return etime
df['上映日期'].map(lambda x:parse(x))
#时间的差
a=datetime.now()-datetime.strptime('2021-9-1','%Y-%m-%d')
print(a.days) # 获取差后的天数
print(a.seconds) # 获取毫秒数
九、样式
1、数字格式化
df.style.format()
Styler.format(self, formatter,subset=None,na_rep: Union[str, NoneType]=None)
formatter一般为一个字典形式,由列名和格式组成
参数说明
| 参数 | 说明 |
|---|---|
| formatter | 格式 |
| subset | |
| na_rep | 控制替换 |
# 所有列格式化为2位小数,并转为百分数
df.style.format("{:.2%}")
#指定列
df.style.format({'random':"{:.2%}"})
# 缺失值的显示格式
df.style.format("{:.2%}", na_rep="-")
常见的数字格式:
| 格式 | 描述 |
|---|---|
| {:2f} | 保留两位小数 |
| {:+2f} | 带符号保留两位小数 |
| {:0f} | 不保留小数 |
| {:,} | 以逗号分隔的数字格式 |
| {:.2%} | 百分比格式 |
2、数值高亮显示
| 样式 | 描述 |
|---|---|
| df.style.highlight_null | 高亮显示空值 |
| df.style.highlight_max | 高亮显示最大值 |
| df.style.highlight_min | 高亮显示最小值 |
| df.style.highlight_between(left=,right=,subset=) | 高亮显示区间,subset指定列 |
十、数据透视表
1、数据透视
2、数据透视表
pd.pivot_table(df,index=,columns=,values=,aggfunc)
参数说明:
| 参数 | 说明 |
|---|---|
| df | 要透视的DataFrame对象 |
| values | 要聚合的列或多个列 |
| index | 在数据透视表索引上进行分组的键 |
| columns | 在数据透视表列上进行分组的键 |
| aggfunc | 用于聚合的函数,默认是np.mean |
| margins | =True,计算总合数据,默认=False |
| fill_value | 空值处理,=0将空值视为0 |
#1、设置显示最大行列
pd.set_option('max_columns',100) ##设置显示的最大列
pd.set_option('max_rows',500) ##设置显示的最大行
pd.pivot_table(df,index=['列']) # 基本形式
pd.pivot_table(df,index=['列1','列2'])#多个索引index,即多个分组键
pd.pivot_table(df,index=['列1','列2'],values=['列'])#指定需要统计汇总的数据values
pd.pivot_table(df,index=['列1','列2'],values=['列'],aggfunc=np.sum)#指定计算函数
pd.pivot_table(df,index=['列'],values=['列1','列2'],aggfunc=[np.sum,np.mean])#计算多个指标
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],aggfunc={'D': np.mean,'E': [min, max, np.mean]})#对不同的values执行不同的函数
pd.pivot_table(df,index=['列'],aggfunc=[np.sum,np.mean],fill_value=0,margins=True)#计算综合
十一、数据炸裂
1、series的炸裂
s.explode()
df['A'].explode()#对A列数据进行炸裂
2、dataframe的炸裂
df.explode(column)
炸开column列,标量将保持不变。空的类似列表将导致该行的np.nan。
explode这个爆炸方法只能处理列表、元组、Series和numpy的ndarray的类型。
参数说明:
| 参数 | 说明 |
|---|---|
| column | 要爆炸的列 |
将类似列表的每个元素转换为一行,从而复制索引值。
df=df.explode('A').drop_duplicates().reset_index().drop('index',axis=1)#将'A'列的数据炸开,去重后重新排列索引
对于不是列表,元组的,可以先进性分割转为列表在炸裂
df['A']=df['A'].str.split(',')
df=df.explode('A').drop_duplicates().reset_index().drop('index',axis=1)
df.explode('A').explode('C').drop_duplicates().reset_index().drop('index',axis=1)#依次炸开多列
十二、IO操作
1、读取文件
1)使用read_table来读取文本文件
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None,index_col=None, dtype=None, engine=None, nrows=None)
2)使用read_csv函数来读取csv文件
pd.read_csv(filename,sep="",names=[],header=,nrows=…)
常用参数说明:
| 参数 | 说明 |
|---|---|
| filename | 指的是你要读取的数据文件的位置 |
| sep | 指的是你读取的数据的分隔方式,sep=’\t’ |
| names | 指的是你为数据集设置的列名 |
| header | 指的是开始读取的行数 ,header=0开始表示从第一行开始读取 |
| nrows | 指所要读取的总行数,nrows=10,表示读取十行 |
| parse_dates | 解析索引 parse_dates=[1, 2, 3] -> 解析1,2,3列的值作为独立的日期列; parse_dates= [[1, 3]] -> 合并1,3列作为一个日期列使用 |
| encoding | 指定字符编码 |
pandas.read_csv(filepath_or_buffer, sep=’\t’, header=’infer’, names=None,index_col=None, dtype=None, engine=None, nrows=None)
3)使用read_excel读取Excel文件
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None,dtype=None)

4)使用read_sql读取mysql
read_sql(sql,con,index_col=None,coerce_float=True,params=None,parse_dates=None,columns=None,chunksize=None)
我们常用的就是前两个参数:
-
sql 为可执行的sql语句
-
con为数据库的连接
connect建立的第一种:
import pymysql
import pandas
connect = pymysql.Connect(host='localhost',
port=3306,
user='root',
password='Gjs200010',
database='pymysql',
charset='utf8')
df = pd.read_sql('select * from douban',conn)
conect建立的第二种:
import pymysql
from sqlalchemy import create_engine
connect=create_engine('mysql+pymysql://root:Gjs200010@localhost:3306/lian_jia')
df=pd.read_sql('select * from jiujiang_lianxi',connect)
2、保存文件
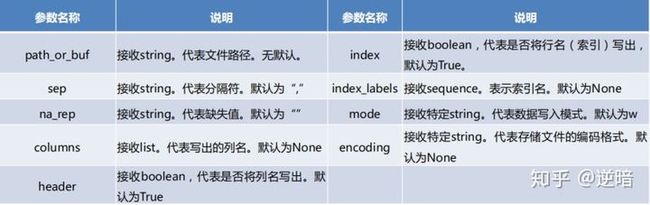
1)使用to_csv函数实现以csv格式存储
DataFrame.to_csv(path_or_buf=None,sep=’,’,na_rep=”,columns=None,header=True,index=True,index_label=None,mode=’w’,encoding=Non)
#分组保存数据
fname=r'd:/data/九江招聘_{0}.csv'
groups=df.groupby('学历要求',as_index=False)
for g,gdf in groups:
gdf.to_csv(fname.format(g),sep=',',index=True,encoding='gbk')
2)使用to_excel函数实现以excel格式存储
DataFrame.to_excel(excel_writer=None, sheetname=None’,na_rep=”,header=True,index=True,index_label=None,mode=’w’,encoding=Non)
3)使用后to_sql保存到数据库
import pymysql from sqlalchemy import create_engine
to_sql(name, con, flavor=None, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
(1)name参数为存储的表名;
(2)con参数为连接数据库,这里和读取有区别,不能用pymysql连接;
(3)if_exists参数用于判断是否有重复表名。填写fail表示:如果有重复表名,就不保存。填写replace用作替换。填写 append,就在该表中继续插入数据。
create_engine(“数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口/数据库”,其他参数)
import pymysql
from sqlalchemy import create_engine
connect=create_engine('mysql+pymysql://root:Gjs200010@localhost:3306/lian_jia')
df=pd.read_sql('select * from jiujiang_lianxi',connect)
df1=df[df['jiage']>7539].sort_values(by='jiage',ascending=False)[:10]
df1.to_sql('jiujiang_gaojia',con=connect,index=False,if_exists='fail')
to_sql(‘表名’,con=链接,index=不写入,if_exists=存在时执行)
index=False表示不写入索引,
if_exists = ‘append’or’replace’or’fail’:分别表示:表存在时,追加,替代和默认的什么都不做
八、pandas操纵
1、数据格式转换
1)df[列].dtype
查看格式
2)df[列].astype(‘类型’)
将年代格式转化为整型
2、排序
1)单值排序
1、默认排序
df[:10] ##根据index进行排序
2、按指定列排序
df.sort_values(by='列')[:5] ## 默认升序排列df.sort_values(by='投票人数',ascending=False)[:5] ##降序排序
2)多值排序
df.sort_values(by=['列1','列2'],ascending=False)[:5]
df.sort_values(by=['评分','投票人数'],ascending=[False,True])[:5]
九、基本统计分析
1、描述性统计 df.describe()
dataframe.describe():
对dataframe中的数值数据进行描述性统计过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的
2、常用的统计函数
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和,axis=0 表示按垂直方向进行计算,而 axis=1 则表示按水平方向 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| var() | 方差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强 |
| cov() | 协方差 |
特殊说明
3、计数
1) len(df)
len(df)dataframe行数
2)df[列].unique()
#某列的所有取值
df['产地'].unique()
len(df['产地'].unique())
3)df[列].value_counts()
df['年代'].value_counts()[:10]#计算列取重后的值数量
8、数据替换
df['产地'].replace('USA','美国',inplace=True)
df['产地'].replace(['西德','苏联'],['德国','俄罗斯'],inplace=True)
len(df['产地'].unique())
十一、数据重塑和轴向旋转
1、层次化索引
1)Series的层次化索引
s=pd.Series(np.arange(1,10),index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,3]])
层次化索引是pandas的一项重要功能,他能使我们再一个轴上拥有多个索引
注意:创建索引时,第一层索引和第二层索引的个数要和data的个数一至
1、选取数据
import numpy as np
import pandas as pd
data=['张三','李四','王五','老刘']
df_test=pd.Series(data,index=[['a','a','b','b'],['男','女','女','男']])
df_test['a','男']#选取内部
df_test['a':'b']#全取外部
2)DataFrame的层次化索引
data=pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]])对于DataFrame来说,行和列都能够进行层次化索引。data=pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['A','A','B'],['Z','X','C']])
1、设置名称
data.index.names=['row1','row2']data.columns.names=['column1','column2']
2、行顺序调整
df.swaplevel('row1','row2')
3、Series和DataFrame互转
s.unstack() #将Series转为DataFrame
s.stack() #将DataFrame转为Series
2、列和索引互相转换层次化
1)df.set_index(列…])
df=df.set_index(['产地','年代'])
可以把列变成索引
把产地和年代同时设置成索引,产地是外层索引,年代是内层索引
2)df.reset_index()
df=df.reset_index()把索引变成列
3、数据旋转 df.T
data.T T 可以直接让数据的行和列进行交换
十二、数据分组,分组运算
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=<no_default>, observed=False, dropna=True)
1、df.groupby(by=df[列])
group=df.groupby(df['产地'])先定义一个分组变量group
group.mean()可以计算分组后的各个统计量
2、df.groupby(df[列1],df[列2])
df.groupby([df['产地'],df['年代']]).mean().head()
我们也可以传入多个分组变量
十四、合并数据集
1、append
df1.append(df2)
2、merge
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(’_x’,’_y’), copy=True, indicator=False)
| 参数 | 说明 |
|---|---|
| left | 对象 |
| right | 另一个对象 |
| on | 要加入的列。必须在左、右综合对象中找到。如果不能通过,left_index和right_index是假,将推断DataFrame中的列的交叉点为连接键,连接键 |
| left_on | 从左边的综合使用作为键列。可以是列名或数组的长度等于长度综合。 |
| right_on | 从右边的综合使用作为键列。可以是列名或数组的长度等于长度综合。 |
| left_index | 如果为True,则使用索引(行标签)从左综合作为其连接键。在与多重(层次)的综合,级别数必须匹配连接键从右综合的数目。 |
| right_index | 先沟通用法作为正确综合left_index。 |
| how | 之一‘左’,‘右’,‘外在’,‘内部’。默认为内联。 |
| suffixes | 字符串后缀并不适用于重叠列的元组。默认为(’_x’,’_y’) |
| copy | 即使重新索引是不必要总是从传递的综合对象,赋值的数据(默认为True)。在许多情况下不能避免,但可能会提高性能/内存使用情况,可以避免赋值上述案件有些病理,但尽管如此提供此选项。 |
| indicator | 将列添加到输出综合呼吁_merge与信息源的每一行。_merge是绝对类型,并对观测其合并键只出现在‘左’的综合,关策其合并键只会出现在‘正确’的综合,和两个如果观测合并关键发现在两个 right_only left_only 的值。 |
pd.merge(df1,df2,how='inner',on='名字')
3、concat
dff=pd.concat([df1,df2,df3],axis=0) ##默认axis=0 增加行数,axis=1增加列数
import pandas as pd
pd.concat(object,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False)
参数说明
object:series,dataframe或则是panel构成的序列list
axis:需要合并连接的轴,0是行,1是列
join:连接的方式inner,或者outer
!(map,apply,applymap,transform,agg)
3.分组运算
可以结合groupby与transform来方便地实现类似SQL中的聚合运算的操作:
df['col3'] = df.groupby('col1')['col2'].transform(lambda x: (x.sum() - x) / x.count())
4.聚合函数
结合groupby与agg实现SQL中的分组聚合运算操作,需要使用相应的聚合函数:
df['col2'] = df.groupby('col1').agg({'col1':{'col1_mean': mean, 'col1_sum‘’: sum}, 'col2': {'col2_count': count}})
#打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
df.groupby('continent')['spirit_servings'].agg(['mean','min','max'])
常用函数
2、series.str.contains()
Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)
返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
参数说明:
| 参数 | 说明 |
|---|---|
| pat | str类型 字符序列或正则表达式。 |
| case | bool,默认为True 如果为True,区分大小写。 |
| flags | int,默认为0(无标志) 标志传递到re模块,例如re.IGNORECASE。 |
| na | 默认NaN 填写缺失值的值。na=False的意思就是,遇到非字符串的情况,直接忽略。你也可以写na=True,意思就是遇到非字符串的情况,计为筛选有效。 |
| regex | bool,默认为True 如果为True,则假定pat是正则表达式。如果为False,则将pat视为文字字符串。 |
3、series.isin(列表)和~isin()
isin()接受一个列表,判断该列中元素是否在列表中。
df[df[某列].isin(条件)&df[某列].isin(条件)]
告诉你没有isnotin,它的反函数就是在前面加上 ~ ,其他用法同上。
ser1[~ser1.isin(ser2)]ser1中不在ser2中的元素
4、series.values()
pandas.Series.values 将Series内的数值以ndarray或ndarray-like的形式返回,取决于原Seires的数据类型
5、pd.data_range(参数)
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
常用参数为start、end、periods、freq。
start:指定生成时间序列的开始时间
end:指定生成时间序列的结束时间
periods:指定生成时间序列的数量
freq:生成频率,默认‘D’,可以是’H’、‘D’、‘M’、‘5H’、‘10D’、…
还可以根据closed参数选择是否包含开始和结束时间,left包含开始时间,不包含结束时间,right与之相反。默认同时包含开始时间和结束时间。
函数调用时至少要指定参数start、end、periods中的两个。
pd.date_range('20200101','20200110')
pd.date_range('20200101',periods=10)
pd.date_range(end='20200110',periods=10)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GVXMSUG6-1640316998304)(图片\20191101162048218.png)]
5、df.resample(freq)
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',kind=None, loffset=None, limit=None, base=0)
series.resample('3T').sum()#降低采样频率为三分钟
6、pd.Grouper()
pandas.Grouper ( key = None,level = None,freq = None,axis = 0,sort = False ) [source]
Grouper允许用户为目标对象指定groupby指令
此规范将通过key参数选择列,或者如果给出了level或axis参数,则指定了目标对象的索引级别。
这些是本地设置,将覆盖“全局”设置,即传递给groupby本身的轴参数和level。
df.groupby(pd.Grouper(key='date', freq='60s'))
df.groupby(pd.Grouper(freq='4M'))#每连续四个月为一组
7、df.interpolate()
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)
参数说明:
| 参数 | 说明 |
|---|---|
| method | str,默认为‘linear’使用插值方法。 ‘linear’:忽略索引,线性等距插值。这是MultiIndexes支持的唯一方法。 ‘time’: 在以天或者更高频率的数据上插入给定的时间间隔长度数据。 ‘index’, ‘values’: 使用索引的实际数值。 ‘pad’:使用现有值填写NaN。 ‘nearest’, ‘zero’, ‘slinear’, ‘quadratic’, ‘cubic’, ‘spline’, ‘barycentric’, ‘polynomial’: 传递给 scipy.interpolate.interp1d。这些方法使用索引的数值。‘polynomial’ 和 ‘spline’ 都要求您还指定一个顺序(int),例如 ,df.interpolate(method=‘polynomial’, order=5) ‘krogh’,‘piecewise_polynomial’,‘spline’,‘pchip’,‘akima’:包括类似名称的SciPy插值方法。 ‘from_derivatives’:指 scipy.interpolate.BPoly.from_derivatives,它替换了scipy 0.18中的’piecewise_polynomial’插值方法。 |
| axis | {0或’index’,1或’columns’,None},默认为None;沿轴进行interpolate。 |
| limit | int;要填充的连续NaN的最大数量。必须大于0。 |
| inplace | bool,默认为False;如果可以,更新现有数据。 |
| limit_direction | {‘forward’,‘backward’,‘both’},默认为’forward’;如果指定了限制,则将沿该方向填充连续的NaN。 |
| limit_area | {None, ‘inside’, ‘outside’}, 默认为None;如果指定了限制,则连续的NaN将填充此限制。 None:无填充限制。 ‘inside’:仅填充有效值包围的NaN。 ‘outside’: 仅在有效值之外填充NaN。 |
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)
method : str,默认为‘linear’使用插值方法。
axis : {0或’index’,1或’columns’,None},默认为None;沿轴进行interpolate。
limit: int;要填充的连续NaN的最大数量。必须大于0。
inplace : bool,默认为False;如果可以,更新现有数据。
limit_direction : {‘forward’,‘backward’,‘both’},默认为’forward’;如果指定了限制,则将沿该方向填充连续的NaN。
limit_area : {None, ‘inside’, ‘outside’}, 默认为None;如果指定了限制,则连续的NaN将填充此限制。
None:无填充限制。
‘inside’:仅填充有效值包围的NaN。
‘outside’: 仅在有效值之外填充NaN。
返回与调用方相同的对象类型,
并以部分或全部NaN值进行插值。
例如:
s = pd.Series([0, 1, np.nan, 3])
s.interpolate()#线性等距插nan值
Series.str常用方法
1. cat(和指定字符进行拼接)
print(df["name"].str.cat())
"""
莫伊拉士兵76死神托比昂安娜aaa
"""
# 可以看到如果cat里面不指定参数,是将所有字段拼接在一起了
print(df["name"].str.cat(sep='-'))
"""
莫伊拉-士兵76-死神-托比昂-安娜-aaa
"""
# 可以指定sep分隔符,会自动用sep连接
print(df["name"].str.cat(['xx'] * len(df)))
"""
0 莫伊拉xx
1 士兵76xx
2 死神xx
3 托比昂xx
4 安娜xx
5 aaaxx
Name: name, dtype: object
"""
# 第一个参数要么不传,要么是一个与之等长的序列
# 会按照索引顺序将元素组合起来,得到一个新的Series
print(df["name"].str.cat(['xx'] * len(df), sep="@"))
"""
0 莫伊拉@xx
1 士兵76@xx
2 死神@xx
3 托比昂@xx
4 安娜@xx
5 aaa@xx
Name: name, dtype: object
"""
# 当然此时也是可以指定分隔符的
print(df["attack"].str.cat(['xx'] * len(df), sep="@"))
"""
0 近距离@xx
1 远距离@xx
2 近距离@xx
3 中远距离@xx
4 远距离@xx
5 NaN
Name: attack, dtype: object
"""
print(df["attack"].str.cat(['xx'] * len(df), sep="@", na_rep="-"))
"""
0 近距离@xx
1 远距离@xx
2 近距离@xx
3 中远距离@xx
4 远距离@xx
5 -@xx
Name: attack, dtype: object
"""
# 可以看到如果一方为NaN,name结果也为NaN,因此我们可以指定na_rep,表示将NaN用na_rep替换
2. split(按照指定字符串分隔)
df.str.split(self, pat=None, n=-1, expand=False) 从左边开始分割
参数详解:
| 参数 | 说明 |
|---|---|
| pat | 分列的依据,可以是空格,符号,字符串等等。支持正则表达式 |
| n | 分列的次数,不指定的话就会根据符号的个数全部分列。 |
| expand | 为True可以直接将分列后的结果转换成DataFrame。扩大 |
df.str.rsplit(self,pat=None,n=-1,expand=False) 从右边开始分割
tmp_df=df['薪资'].str.split(',',expand=True)#将薪资以逗号隔开,expand为True转为dataframe
tmp_df.columns=['最低薪资','最高薪资']
pd.merge(df,tmp_df,how='left',left_index=True,right_index=True)
df.merge(合并)
pd.marge(df1,df2,on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True)
参数说明:
| 参数 | 说明 |
|---|---|
| on | 列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。 |
| left_on | 左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| right_on | 右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| left_index/ right_index | 如果是True的haunted以index作为对齐的key |
| how | 数据融合的方法。left,right,outer,inner,默认为inner |
| sort | 根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。 |
11. startswith(是否某个子串开头)
print(df["attack"].str.startswith("近"))
"""
0 True
1 False
2 True
3 False
4 False
5 None
Name: attack, dtype: object
"""
12. endswith(判断是否以某个子串结尾)
print(df["attack"].str.endswith("离"))
"""
0 True
1 True
2 True
3 True
4 True
5 None
Name: attack, dtype: object
"""
19. strip(按照指定内容,从两边去除,和python字符串内置的strip一样)
print(df["attack"].str.strip("中远近离"))
"""
0 距
1 距
2 距
3 距
4 距
5 None
Name: attack, dtype: object
"""
22. find(查找指定字符第一次出现的位置)
print(df["date"].str.find("-"))
"""
0 4
1 4
2 4
3 4
4 4
5 4
Name: date, dtype: int64
"""
# 当然可以指定范围,包括起始和结束
print(df["date"].str.find("-", 5))
"""
0 7
1 7
2 7
3 7
4 7
5 7
Name: date, dtype: int64
"""
print(df["date"].str.find("蛤"))
"""
0 -1
1 -1
2 -1
3 -1
4 -1
5 -1
Name: date, dtype: int64
"""
# 找不到的话,返回-1
print(df["attack"].str.strip("中远近离"))
"""
0 距
1 距
2 距
3 距
4 距
5 None
Name: attack, dtype: object
"""
Series.str.capitalize()
将给定系列的第一个字母转为大写字母,并使所有的字符在特定字符串中保持不变
21. extract(分组捕获)
提取
extract(正则匹配)
print(df["date"].str.extract("\d{4}-(\d{2})-(\d{2})"))
"""
0 1
0 11 23
1 11 23
2 11 23
3 11 23
4 11 23
5 11 23
"""
# 必须匹配指定pattern,否则为NaN
# 而且必须要有分组,否则报错,结果是一个DataFrame,每一个分组对应一列
print(df["date"].str.extract("\d{4}-(?P<月>\d{2})-(?P<日>\d{2})"))
"""
月 日
0 11 23
1 11 23
2 11 23
3 11 23
4 11 23
5 11 23
"""
# 指定分组名,会变成列名
pandas SQL操作
| 操作 | sql | pandas |
|---|---|---|
| 基础查询 | select ‘字段’,… from ‘表’ | 表**[[‘字段’,…]]** |
| 去重 | select distinct ‘字段’ from ‘表’ | 表[[‘字段’]].drop_duplicates() |
| 条件查询 | select 字段 from 表 where 条件 | 表[条件] |
| 排序查询 | select 字段 from 表 where 条件 order by 排序字段 [asc/desc] | 表[条件][[‘字段’]].sort_values(‘排序字段’,ascending=True/False) |
| 分组查询 | select 聚合函数,字段 from 表 where 条件 group by 分组字段 order by 排序字段 | 表[条件][[‘字段’]].groupby(‘分组字段’).聚合函数.sort_values(‘排序字段’) |
| 聚合 | select 聚合函数,字段 from 表 where 条件 group by 分组字段 order by 排序字段 | 表[条件][[‘字段’]].groupby(‘分组字段’).agg({‘字段’:函数}).sort_values(‘排序字段’) |
| 分组后筛选 | select 字段 from 表 where 条件 group by 分组字段 having 分组和条件 order by 排序字段 | 表[条件]/[[‘字段’]].groupby(‘分组字段’).query(‘条件’).sort_values() |
| limit | select 字段 from 表 where 条件 group by 分组字段 having 分组和条件 order by 排序字段 limit 条 | 表[条件]/[[‘字段’]].groupby(‘分组字段’).filter(条件).sort_values(‘排序字段’).head(条数) |
| 连接查询 | ||
| 内连接 | select 查询列表 from 表1 别名 【inner】 join 表2 别名 on 连接条件 where 筛选条件 group by 分组列表 having 分组后的筛选 order by 排序列表 limit 子句; |
表1.merge(表2) |
| 外连接 | select 查询列表 from 表1 别名 left|right|full[outer] join 表2 别名 on 连接条件 where 筛选条件 group by 分组列表 having 分组后的筛选 order by 排序列表 limit 子句; |
表1.merage(表2,how=‘outer’) |
数据分析模型:
1、RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。该机械模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
最近一次消费 (Recency)
消费频率 (Frequency)
消费金额 (Monetary)
计算:
最近一次消费:当前时间-消费时间
消费频率:消费次数的总和
消费金额:及每次消费的金额
指标表示
| 客户类型 | R(最近一次消费 值越高,价值越低) |
F(消费频率 值越高,价值越高) |
M(消费金额 值越高,价值越高) |
|---|---|---|---|
| 重要价值客户(111) | 高 | 高 | 高 |
| 一般价值客户(110) | 高 | 高 | 低 |
| 重要保持客户(011) | r低 | 高 | 高 |
| 一般保持客户(010) | 低 | 高 | 低 |
| 重要发展客户(101) | 高 | 低 | 高 |
| 一般发展客户(100) | 高 | 低 | 低 |
| 重要挽留客户(001) | 低 | 低 | 高 |
| 一般挽留客户(000) | 低 | 低 | 低 |
价值:最近一次消费和频率都高
保持:最近一次消费价值低
发展:消费频率低
挽留:最近一次消费和频率都低
#计算最后消费日期,消费金额,消费频率
df=df.groupby('user_id').agg(最后消费日期=('date','max'),
M=('消费金额','sum'),
F=('user_id','count')).reset_index()
#计算最近依次消费时间间隔
rq_max=df['最后消费日期'].max()
df['R']=df['最后消费日期'].map(lambda x:rq_max-x)
df['R']=df['R'].dt.days
df=df[['user_id','R','F','M']]
#对R进行打分
r_min=df['R'].min()
r_max=df['R'].max()
df['R']=pd.cut(df['R'],bins=[r_min-1,30,60,90,120,r_max+1],labels=[5,4,3,2,1])
#对F进行打分
f_min=df['F'].min()
f_max=df['F'].max()
df['F']=pd.cut(df['F'],bins=[f_min-1,1,2,3,4,f_max+1],labels=[1,2,3,4,5])
#对M进行打分
m_min=df['M'].min()
m_max=df['M'].max()
df['M']=pd.cut(df['M'],bins=[m_min-1,200,500,1000,2000,m_max+1],labels=[1,2,3,4,5])
#如果大于均值则标记1,否则标记0
r_mean=df['R'].mean()
f_mean=df['F'].mean()
m_mean=df['M'].mean()
df['R']=df['R'].map(lambda x:'1' if x<r_mean else '0')
df['F']=df['F'].map(lambda x:'1' if x>f_mean else '0')
df['M']=df['M'].map(lambda x:'1' if x>m_mean else '0')
#分析各户价值
def jiazhi(x):
if x=='111':
return '重要价值客户'
elif x=='101':
return '重要发展客户'
elif x=='011':
return '重要保持客户'
elif x=='001':
return '重要挽留客户'
elif x=='110':
return '一般价值客户'
elif x=='100':
return '一般发展客户'
elif x=='010':
return '一般保持客户'
elif x=='000':
return '一般挽留客户'
df['result']=df['result'].map(lambda x:jiazhi(x))
2、波斯顿矩阵
波士顿矩阵(BCG Matrix),又称市场增长率-相对市场份额矩阵、波士顿咨询集团法、四象限分析法、产品系列结构管理法等。
本法将企业所有产品从销售增长率和市场占有率角度进行再组合。在坐标图上,以纵轴表示企业销售增长率,横轴表示市场占有率,各以10%和20%作为区分高、低的中点,将坐标图划分为四个象限,依次为“明星类产品(★)”、“问题类产品(。)”、金牛类产品(¥)”、“瘦狗类产品(×)”。其目的在于通过产品所处不同象限的划分,使企业采取不同决策,以保证其不断地淘汰无发展前景的产品,保持“问题”、“明星”、“金牛”产品的合理组合,实现产品及资源分配结构的良性循环。
计算:
占有率=个体销量 / 总体销量
增长率=(当年销量-上一年销量)/ 上一年销量 或 当年销量 / 上一年销量 - 1
指标表示:
通过以上两个因素相互作用,会出现四种不同性质的产品类型,形成不同的产品发展前景:
①销售增长率和市场占有率“双高”的产品群(明星类产品);
②销售增长率和市场占有率“双低”的产品群(瘦狗类产品);
③销售增长率高、市场占有率低的产品群(问题类产品);
④销售增长率低、市场占有率高的产品群(金牛类产品)。

| 增长率高、占有率高(双高) | 明星类产品(生长期)发展 |
| 增长率低、占有率低(双低) | 廋狗类产品(衰退期)放弃 |
| 增长率高、占有率低 | 问题类产品(导入期)收割 |
| 增长率低、占有率高 | 金牛类产品(成熟期)保持 |
| 战略 | 说明 | 运用 |
|---|---|---|
| 发展 | 以提高经营单位的相对市场占有率为目标.甚至不惜放弃短期收益。要使问题类业务想尽快成为“明星”,就要增加资金投入。 | 明星 |
| 保持 | 投资维持现状,目标是保持业务单位现有的市场份额、对于较大的“金牛”可以此为目标,以使它们产生更多的收益。 | 金牛 |
| 收割 | 这种战略主要是为了获得短期收益,目标是在短期内尽可能地得到最大限度的现金收入。对处境不佳的金牛类业务及没有发展前途的问题类业务和瘦狗类业务应视具体情况采取这种策略。 | 问题 |
| 放弃 | 目标在于清理和撤销某些业务,减轻负担,以便将有限的资源用于效益较高的业务。这种目标适用于无利可图的瘦狗类和问题类业务。一个公司必须对其业务加以调整,以使其投资组合趋于合理。 | 廋狗 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oOOJjLeM-1640316998305)(C:\Users\GJS\Desktop\markdown\python数据分析\图片\波士顿矩阵1.png)]
3、布林指标
布林线指标,即BOLL指标,其英文全称是“Bollinger Bands”,布林线(BOLL)由约翰·布林先生创造,其利用统计原理,求出股价的标准差及其信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位,因而也被称为布林带。其上下限范围不固定,随股价的滚动而变化。布林指标和麦克指标MIKE一样同属路径指标,股价波动在上限和下限的区间之内,这条带状区的宽窄,随着股价波动幅度的大小而变化,股价涨跌幅度加大时,带状区变宽,涨跌幅度狭小盘整时,带状区则变窄。
计算:
一般至少二十天
中轨线=N日的移动平均线
上轨线=中轨线+两倍的标准差
下轨线=中轨线-两倍的标准差
指标表示
在股市分析软件中,BOLL指标一共由四条线组成,即上轨线UP 、中轨线MB、下轨线DN和价格线。
其中上轨线UP是UP数值的连线,用黄色线表示;
中轨线MB是MB数值的连线,用白色线表示;
下轨线DN是DN数值的连线,用紫色线表示;
价格线是以美国线表示,颜色为浅蓝色。和其他技术指标一样,在实战中,投资者不需要进行BOLL指标的计算,主要是了解BOLL的计算方法和过程,以便更加深入地掌握BOLL指标的实质,为运用指标打下基础。
| 上轨线 | 中轨线 | 下轨线 | 说明 | 建议 |
|---|---|---|---|---|
| 上 | 上 | 上 | 股价强势明显,短期内上涨 | 持股待涨,逢低买入 |
| 下 | 下 | 下 | 股价弱势明显,短期内下跌 | 持币观望,逢高卖出 |
| 下 | 上 | 上 | 处于长期上升:强势整理; 处于长期下跌:弱势整理 |
处于长期上升:持股观望,逢低买入; 处于长期下跌:持币观望,逢高卖出 |
| 上 | 下 | 下 | 股价将下跌 | |
| 上 | 上 | 下 | 股价将上涨 |
4、关联规则
顾名思义,关联规则就是发现数据背后存在的某种规则或者联系。
概念:
| 指标 | 说明 |
|---|---|
| 项目 | 交易数据库中的一个字段,对超市的交易来说一般是指一次交易中的一个物品,如:牛奶 |
| 事务 | 某个客户在一次交易中,发生的所有项目的集合:如{牛奶,面包,啤酒} |
| 项集 | 包含若干个项目的集合(一次事务中的),一般会大于0个 |
| 支持度 | 项集{X,Y}在总项集中出现的概率(见下面的例子) |
| 置信度 | 在先决条件X发生的条件下,由关联规则{X->Y }推出Y的概率(见下面的例子) |
| 提升度 | 表示含有X的条件下同时含有Y的概率,与无论含不含X含有Y的概率之比。 |
| 频繁项集 | 某个项集的支持度大于设定阈值(人为设定或者根据数据分布和经验来设定),即称这个项集为频繁项集。 |
计算:
A->B
| 字母 | 说明 |
|---|---|
| A | 买A的人数 |
| B | 买B的人数 |
| AB | 既买A又买B的人数 |
| S | 总共的人数 |
| 指标 | 计算公式 |
|---|---|
| 支持度 | AB/S |
| 置信度 | AB/A |
| 提升度 | AB/A / B/A |
指标说明:
提升度说明:
| 提升度 | 关系 |
|---|---|
| >1 | 有效的强关联关系 |
| <=1 | 无效的强关联光系 |
| =1 | A与B相互独立,即是否有A对于B的出现没有影响 |
使用mlxtend计算
通过mlxtend库的frequent_patterns模块计算频繁项集和关联规则
导入函数
from mlxtend.frequent_patterns import apriori 计算频繁项集
from mlxtend.frequent_patterns import association_rules 计算相关规则
from mlxtend.prequent_patterns import TransactionEncoder 接口规范
from mlxtend.frequent_patterns import apriori #计算频繁项集
from mlxtend.frequent_patterns import association_rules #计算相关规则
from mlxtend.prequent_patterns import TransactionEncoder #接口规范
1、TransactionEncoder()
传入参数需要符合人家的要求,也就是接口规范,我们需要用到
TransactionEncoder有两个方法:
| 方法 | 说明 |
|---|---|
| fit(dataset) | 先fit之后,mlxtend就可以知道有多少个唯一值,有了所有的唯一值,就可以转换成one-hot code了 |
| transform() |
| 属性 | 说明 |
|---|---|
| columns_ |
#将同一个客户购买的所有商品放入同一个购物篮
baskets=df.groupby('OrderNumber')['Model'].apply(lambda x:x.tolist())
te=TransactionEncoder()
basked_tf=te.fit_transform(baskets)#转换算法可以接受的模型(bool)
df=pd.DataFrame(basked_tf,columns=te.columns_)
df.head()
2、pariori()
apriori(df,min_support=0.6,use_colnames=True)
计算频繁项集
参数说明:
| 参数 | 说明 |
|---|---|
| df | 候选项集 |
| min_support | 最小支持度 |
| use_colnames | 使用列名 |
#计算频繁项集,需指定最小支持度,返回DataFrame类型,(support,itemsets)
frequent_itemsets=apriori(df,min_support=0.01,use_colnames=True)
3、association()
association_rules(df, metric=“confidence”,min_threshold=0.8,support_only=False)
计算关联规则
参数说明:
| 参数 | 说明 |
|---|---|
| df | 频繁项集 |
| metric | 可选值: support :支持度 confidence :置信度 lift :提升度 leverage conviction |
| min_threshold | 最小度,参数类型是浮点型,根据 metric 不同可选值有不同的范围 metric = ‘support’ => 取值范围 [0,1] metric = ‘confidence’ => 取值范围 [0,1] metric = ‘lift’ => 取值范围 [0, inf] |
| support_only | 默认是 False。仅计算有支持度的项集,若缺失支持度则用 NaNs 填充。 |
#求关联规则,设置最小置信度为0.1
rules=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.1)