入门NLP-3-基于机器学习的文本分类
入门NLP-基于机器学习的文本分类
- 综述
- 传统文本分类方法
-
- 文本预处理:
-
- 中文分词
- 英文分词
- 文本表示
-
- One hot
- Bag of Words
- Bi-gram and N-gram
- TF-IDF
- 分类器
综述
文本分类在文本处理中是很重要的一个模块,它的应用也非常广泛,比如:垃圾过滤,新闻分类,词性标注等等。它和其他的分类没有本质的区别,核心方法为首先提取分类数据的特征,然后选择最优的匹配,从而分类。但是文本也有自己的特点,根据文本的特点,文本分类的一般流程为:1.预处理;2.文本表示及特征选择;3.构造分类器;4.分类。
通常来讲,文本分类任务是指在给定的分类体系中,将文本指定分到某个或某几个类别中。被分类的对象有短文本,例如句子、标题、商品评论等等,长文本,如文章等。分类体系一般人工划分,例如:1)政治、体育、军事 2)正能量、负能量 3)好评、中性、差评。因此,对应的分类模式可以分为:二分类与多分类问题。
经典的机器学习方法采用tf-idf等方法获取文本特征,分别喂入logistic regression、随机森林等分类器的思路,
传统文本分类方法
传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,此外需要人工进行特征工程,成本很高。而深度学习在图像和语音取得巨大成功,也相应的推动了深度学习在NLP上的发展,使得深度学习的模型在文本分类上也取得了不错的效果。
传统的机器学习分类方法将整个文本分类问题就拆分成了特征工程和分类器两部分。特征工程分为文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。
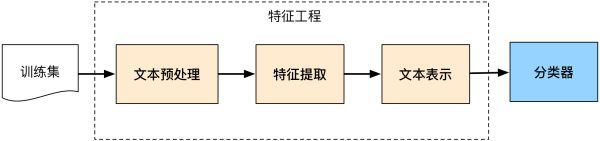
文本预处理:
文本预处理过程是在文本中提取关键词表示文本的过程,中文文本处理中主要包括文本分词和去停用词两个阶段。之所以进行分词,是因为很多研究表明特征粒度为词粒度远好于字粒度,其实很好理解,因为大部分分类算法不考虑词序信息。
中文分词
现有的分词方法可分为三大类:
- 基于字符串匹配的分词方法;
- 基于理解的分词方法;
- 基于统计的分词方法。
英文分词
英文分词技术:
英文分词相比中文分词要简单得多,可以根据空格和标点符号来分词,然后对每一个单词进行词干还原和词形还原,去掉停用词和非英文内容
文本表示
One hot
One-hot表示很容易理解。在一个语料库中,给每个字/词编码一个索引,根据索引进行one-hot表示。
John likes to watch movies. Mary likes too.
John also likes to watch football games.
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also":6, "football": 7,
"games": 8, "Mary": 9, "too": 10}
其中的每个单词都可以用one-hot方法表示:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
...
当语料库非常大时,需要建立一个很大的字典对所有单词进行索引编码。比如100W个单词,每个单词就需要表示成100W维的向量,而且这个向量是很稀疏的,只有一个地方为1其他全为0。还有很重要的一点,这种表示方法无法表达单词与单词之间的相似程度,如beautiful和pretty可以表达相似的意思但是ont-hot法无法将之表示出来。
Bag of Words
词袋表示,也称为计数向量表示(Count Vectors)。文档的向量表示可以直接用单词的向量进行求和得到。
John likes to watch movies. Mary likes too. -->> [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
John also likes to watch football games. -->> [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
横向来看我们把每条文本表示成了一个向量,纵向来看,不同文档中单词的个数又可以构成某个单词的词向量。如上文中的"John"纵向表示成[1,1]。
Bi-gram and N-gram
与词袋模型原理类似,Bi-gram将相邻两个单词编上索引,N-gram将相邻N个单词编上索引。
为 Bi-gram建立索引:
{"John likes”: 1,
"likes to”: 2,
"to watch”: 3,
"watch movies”: 4,
"Mary likes”: 5,
"likes too”: 6,
"John also”: 7,
"also likes”: 8,
"watch football": 9,
"football games": 10}
原来的两句话就可以表示为:
John likes to watch movies. Mary likes too. -->> [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
John also likes to watch football games. -->> [0, 1, 1, 0, 0, 0, 1, 1, 1, 1]
这种做法的优点是考虑了词的顺序,但是缺点也很明显,就是造成了词向量的急剧膨胀。
TF-IDF
上面的词袋模型和Bi-gram、N-gram模型是基于计数得到的,而TF-IDF则是基于频率统计得到的。TF-IDF的分数代表了词语在当前文档和整个语料库中的相对重要性。TF-IDF 分数由两部分组成:第一部分是词语频率(Term Frequency),第二部分是逆文档频率(Inverse Document Frequency)。其中计算语料库中文档总数除以含有该词语的文档数量,然后再取对数就是逆文档频率。
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
sklearn中的TfidfVectorizer生成TF-IDF特征。
# word level tf-idf
tfidf_vect = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', max_features=5000)
tfidf_vect.fit(trainDF['text'])
xtrain_tfidf = tfidf_vect.transform(train_x)
# ngram level tf-idf
tfidf_vect_ngram = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}',
ngram_range=(2,3), max_features=5000)
tfidf_vect_ngram.fit(trainDF['text'])
xtrain_tfidf = tfidf_vect.transform(train_x)
分类器
- 朴素贝叶斯
- KNN方法
- 决策树
- 支持向量机
- GBDT/XGBOOST
…
在这里举个例子
Count Vectors + RidgeClassifier(岭回归分类器)
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('train_set.csv', sep='\t', nrows=15000)
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.74
TF-IDF + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('train_set.csv', sep='\t', nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.87