机器学习之金融信贷风控(二)申请评分卡中的数据预处理和特征衍生(未完待续)
申请评分卡中的数据预处理和特征衍生
模型处理的一般流程:
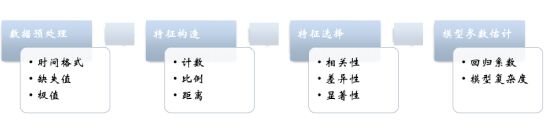
构建信用风险模型的特征
获取数据
链接:https://pan.baidu.com/s/1CsY11ArZ6YK3o1icghWj2w
提取码:znbs

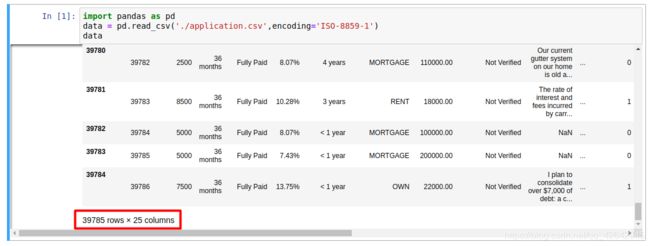
数据预处理
1.基本处理:
原始数据带有一定的格式,需要转换成正确的格式
- 利率方面的处理办法:带%的百分比,需要转化为浮点数
- 工作年限“<1 year”转化为0,“>10 year”的转化为11
- 日期方面:如Nov-10直接转化为标准日期,python能识别的日期格式
- 文本类数据的处理方式
例如:After amassing credit card debt through several years of college, I now have spending under control and a stable job。。。上述文本信息:字段中的desc就是客户申请期间的申请原因等信息,这里处理采用最简单的办法,如果里面有信息,则为1,无信息则为0,即编码处理,其他例如采用NLP的办法,做其他处理,暂时不做,因为涉及分词等等,处理其他麻烦,不是写这次博客的主要目的。
主题提取(NPL自然语言处理)
优点:提取准确、详细的信息,对风险的评估非常有效,
缺点:NPL的模型较为复杂,且需要足够多的的训练样本。
编码处理:
优点:简单
缺点:丢失信息较高
2.缺失值处理:
缺失值的种类情况:
- 完全随机缺失
- 随机缺失
- 完全非随机缺失
处理的办法一般为以下几种:
- 补缺
- 作为一种状态,例如,空的为0,非空为1,处理起来简单,如果缺失值不多,效果不错
- 删除本行的记录,这种处理办法最简单,尤其在数据量较大的情况下,删除部分数据,对整体基本无影响。
3.数据特征构建-特征衍生
因为在原有的特征上面,也就是直接特征方面的信息含量不足以很好的建立申请评分卡模型,所以一般都会去构建新的特征,进行特征的衍生。那么经常接触到的特征衍生办法如下:
- 计数:过去1年内申请贷款的总次数
- 求和:过去1年内的在线上的消费金额
- 比例:贷款申请额度和年收入的占比
- 时间差:第一次开户距离今天的时间长度
- 波动率:过去3年内每份工作的时间的标准差,或者标准差/期望值
以上构建的办法均基于经验的构建,不包含了因子分析等办法
特征的分箱
分箱简单的解释就是:分箱就是为了做到同组之间的差异尽可能的小,不同组之间的差异尽可能的大。
1. 特征分箱的目的:
- 将连续变量离散化
- 将多状态的离散变量合并成少状态
2.分箱的重要性:
- 稳定性:避免了特征中的无意义的波动对评分带来的不好的影响
- 健壮性:避免了模型受到极端值的影响
举个例子:例如未进行分箱之前,样本数据里面没有一个高二年级的学生,那么假定做好分箱之后,高一到高三均属于高中,因此出现一个高二年级的学生后,就会被划入高中这个“箱”,模型的稳定性就得到了加强;在健壮性方面,例如我的收入是1000,在申请贷款的时候给予的评分很低,假定就20分,经过我的不断努力,跳槽7-8次之后,薪水涨到1500左右,这个时候,还是属于低收入的困难人群,那么给予的评分还是20分左右,这样模型的健壮性就得到了体现,模型不需要根据一些小的变化就进行调整。
3.分箱的好处:
- 可以把缺失值作为一个独立的箱带入到模型中去
- 将所有的变量变换到相似的尺度上(例如:一个变量是年龄,一个变量是月收入,不做分箱,2者之间的变化差距太大)
4.分箱的缺点:
- 计算量比较大,处理数据过程较为繁琐。
- 分箱后,数据不能直接被模型使用,需要编码
- 编码之后容易导致信息的丢失。
5.分箱的方法:
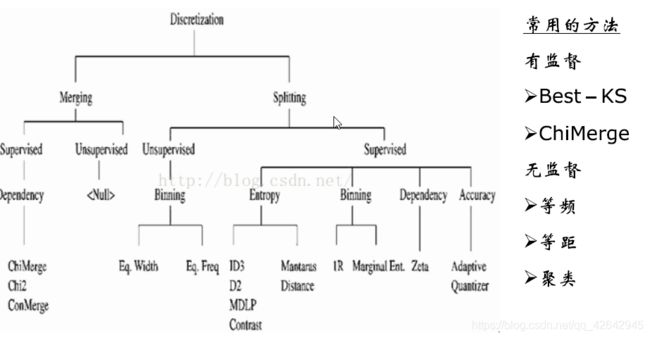
有监督分箱与无监督方法的区别就在于是否有目标变量,有目标变量就是有监督,无目标变量就是无监督。
-
无监督分箱方法(一般不推荐,好不好用,得看人品,一般比卡方和决策树的效果要差点)
-
等距划分: 从最小值到最大值之间,均分为 N 等份, 这样, 如果 A,B 为最小最大值, 则每个区间的长度为 W=(B−A)/N , 则区间边界值为A+W,A+2W,….A+(N−1)W 。这里只考虑边界,每个等份里面的实例数量可能不等。
-
等频分箱: 区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
-
比较: 比如,等宽区间划分,划分为5区间,最高工资为50000,则所有工资低于10000的人都被划分到同一区间。等频区间可能正好相反,所有工资高于50000的人都会被划分到50000这一区间中。这两种算法都忽略了实例所属的类型,落在正确区间里的偶然性很大。
对特征进行分箱后,需要对分箱后的每组(箱)进行woe编码,然后才能放进模型训练。
-
-
有监督分箱方法
-
Best-KS分箱(非常类似决策树的分箱,决策树分箱的标准是基尼指数,这里就只考虑KS值): 让分箱后组别的分布的差异最大化。
-
步骤:对于连续变量
1.排序,x = { x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,… x k x_k xk}
2.计算每一点的KS值
3.选取最大的KS值对应的特征值 x m x_m xm,将x分为{ x i ≤ x m x_i≤x_m xi≤xm}与{ x i > x m x_i>x_m xi>xm}两部分,对于每一部分,循环2、3步骤,直到满足终止条件 -
终止条件,继续回滚到上一步:
1.下一步分箱,最小的箱的占比低于设定的阈值(0.05)
2.下一步分箱后,有一箱数据比较单纯,比如对应的y的类别全部为0或者1
3.下一步分箱后,bad rate不单调 -
对于离散很高的分类变量分箱方法
1.编码(类别变量个数很多,先编码,再分箱。)
2.依据连续变量的方式进行分箱
分箱以后变量必须单调,具体的例子如下图:

-
假定变量被分成了6个箱,假定X轴为年龄,Y轴为坏样本率,这样就可以解释了,年龄越大,坏客户的比例约多。如果分箱之后不单调,那么模型在这个变量上的可解释性就成问题了。所以在分箱期间要注意变量的单调性。
-
-
卡方分箱:
这里copy一段官方解释(比较长):自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。通俗的讲,即让组内成员相似性强,让组间的差异大。
基本思想: 对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。- 忘记上面,直接实践一下,步骤如下:
- 预先我们设定一个卡方的阈值
- 初始化:根据离散化的属性对实例进行排序,每个实例属于一个区间
- 开始合并,具体分2步:
(1). 计算每一对相邻区间的卡方数值
(2)卡方值最小的一对区间直接合并
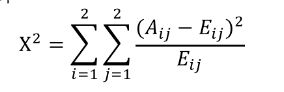
A i j A_{ij} Aij:第i区间第j类的实例的数量
E i j E_{ij} Eij: A i j A_{ij} Aij的期望频率, = ( N i ∗ C j ) / N =(N_i*C_j)/N =(Ni∗Cj)/N,N是总样本, N i N_i Ni是第i组的样本数, C j C_j Cj是第j类样本在全体中的比例




目前一般分箱5个或者6个,置信度在0.95左右,区间为10-15之间。主要是因为分箱太多,操作起来太麻烦,对模型的提高也不大,分箱5个一般就不错。
卡方分箱的终止条件很简单,基本就是2条:- 默认分到多少箱,如果已经分到了这个数值了,那就第2步
- 检查一下单调性,满足就完成分箱了,如果不满足,相邻的箱就合并,直到单调了为止,因为最后合并到2个箱的时候,是一定单调的。
-
和Best-KS分箱相比,ChiMerge卡方分箱可以应用于multi-Class(多分类),而Best-KS分箱多应用于二分类
补充:分箱之前要切分,通常50-100个切分点,看数据量的大小,最最最重要的,千万不要用等距划分,因为比如收入、年龄这些字段成偏态分步,数据没有平均分布,要用等频划分。
类别变量,类别较少,就不用在分箱了,如果有那个类别是全部为坏样本,需要和最小的不是坏样本的合并一下,因为不合并等会WOE不能计算了。
最后补充:在评分卡模型中,能不用热编码就不要用热编码,因为热编码膨胀了数据量,在选择变量是不是进入模型当中去,也是存在问题了,例如逐步回归就不好搞,业务方面的解释性也差,没直接的业务逻辑关系。总之,能不用就不用,要是没变量了,还是可以考虑用一下。
WOE编码
WOE(weight of evidence,证据权重)
WOE编码官方解释:一种有监督的编码方式,将预测类别(目标变量)的集中度的属性作为编码的数值
优点:
- 将特征的值规范到相近的尺度上。(经验上讲,WOE的绝对值波动范围在0.1~3之间,超过2的可能性就已经很小了)
- 具有业务含义
缺点:
- 需要分箱后每箱都同时有好坏样本(预测违约和不违约可是使用WOE编码,如果去预测中度违约、重度违约、轻度违约等等情况,这个时候WOE编码就不行了)
WOE计算公式:

WOE编码的意义:
- 符号与好样本的比例有关;
- 当好样本为分子,坏样本为分母的时候,可以要求回归模型的系数为负。
具体的WOE编码这里就不找材料了,CSDN博客上,有很多写的很好的,这里引用一篇博客在这里,请猛击WOE编码。
这里简单引用一下其他人成熟的比较正式说法,WOE公式如下:
W O E i = l n ( p y 1 p y 0 ) = l n ( B i / B T G i / G T ) WOE_i=ln({p_{y_1}\over p_{y_0}})=ln({B_i/B_T\over G_i/G_T}) WOEi=ln(py0py1)=ln(Gi/GTBi/BT)
例如,以年龄作为一个变量,由于年龄是连续型自变量,需要对其进行离散化处理,假设离散化分为5组(如何分箱,上面已经介绍,后面将继续介绍),#bad和#good表示在这五组中违约用户和正常用户的数量分布,最后一列是woe值的计算,通过后面变化之后的公式可以看出,woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。再加上woe计算形式与logistic回归中目标变量的logistic转换(logist_p=ln(p/1-p))如此相似,因而可以将自变量woe值替代原先的自变量值;具体的计算情况如下:
| Age | bad | good | WOE |
|---|---|---|---|
| 0-10 | 50 | 200 | =ln((50/100)/(200/1000))=ln((50/200)/(100/1000)) |
| 10-18 | 20 | 200 | =ln((20/100)/(200/1000))=ln((20/200)/(100/1000)) |
| 18-35 | 5 | 200 | =ln((5/100)/(200/1000))=ln((5/200)/(100/1000)) |
| 35-50 | 15 | 200 | =ln((15/100)/(200/1000))=ln((15/200)/(100/1000)) |
| 50以上 | 10 | 200 | =ln((10/100)/(200/1000))=ln((10/200)/(100/1000)) |
| 汇总 | 100 | 1000 |
IV值
IV值的官方解释为:IV(Information Value), 衡量特征包含预测变量浓度的一种指标。
计算公式如下:
| Age | bad | good | iv |
|---|---|---|---|
| 0-10 | 50 | 200 | =(50/100-200/1000)*ln((50/100)/(200/1000))= I V 1 IV_1 IV1 |
| 10-18 | 20 | 200 | =(20/100-200/1000)*ln((20/100)/(200/1000))= I V 2 IV_2 IV2 |
| 18-35 | 5 | 200 | =(5/100-200/1000)*ln((5/100)/(200/1000))= I V 3 IV_3 IV3 |
| 35-50 | 15 | 200 | =(25/100-200/1000)*ln((15/100)/(200/1000))= I V 4 IV_4 IV4 |
| 50以上 | 10 | 200 | =(10/100-200/1000)*ln((10/100)/(200/1000))= I V 5 IV_5 IV5 |
| 汇总 | 100 | 1000 | I V i j = I V 1 + I V 2 + I V 3 + I V 4 + I V 5 IV_{ij} =IV_1+IV_2+IV_3+IV_4+ IV_5 IVij=IV1+IV2+IV3+IV4+IV5 |
就得到了这个变量的总体IV值。
下面我们看一下数据集

term 贷款期现需要处理
int_rate 利率是一个字符串,需要处理
emp_length 工作年限需要处理
desc 贷款描述
issue_d 日期需要处理
申请评分卡,卡方分箱、WOE编码通用函数代码:
import numpy as np
import pandas as pd
def SplitData(df, col, numOfSplit, special_attribute=[]):
'''
:param df: 按照col排序后的数据集
:param col: 待分箱的变量
:param numOfSplit: 切分的组别数
:param special_attribute: 在切分数据集的时候,某些特殊值需要排除在外
:return: 在原数据集上增加一列,把原始细粒度的col重新划分成粗粒度的值,便于分箱中的合并处理
'''
df2 = df.copy()
if special_attribute != []:
df2 = df.loc[~df[col].isin(special_attribute)]
N = df2.shape[0]
n = N/numOfSplit
splitPointIndex = [i*n for i in range(1,numOfSplit)]
rawValues = sorted(list(df2[col]))
splitPoint = [rawValues[i] for i in splitPointIndex]
splitPoint = sorted(list(set(splitPoint)))
return splitPoint
def Chi2(df, total_col, bad_col, overallRate):
'''
:param df: 包含全部样本总计与坏样本总计的数据框
:param total_col: 全部样本的个数
:param bad_col: 坏样本的个数
:param overallRate: 全体样本的坏样本占比
:return: 卡方值
'''
df2 = df.copy()
# 期望坏样本个数=全部样本个数*平均坏样本占比
df2['expected'] = df[total_col].apply(lambda x: x*overallRate)
combined = zip(df2['expected'], df2[bad_col])
chi = [(i[0]-i[1])**2/i[0] for i in combined]
chi2 = sum(chi)
return chi2
def BinBadRate(df, col, target, grantRateIndicator=0):
'''
:param df: 需要计算好坏比率的数据集
:param col: 需要计算好坏比率的特征
:param target: 好坏标签
:param grantRateIndicator: 1返回总体的坏样本率,0不返回
:return: 每箱的坏样本率,以及总体的坏样本率(当grantRateIndicator==1时)
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(level=0, inplace=True)
regroup['bad_rate'] = regroup.apply(lambda x: x.bad * 1.0 / x.total, axis=1)
dicts = dict(zip(regroup[col],regroup['bad_rate']))
if grantRateIndicator==0:
return (dicts, regroup)
N = sum(regroup['total'])
B = sum(regroup['bad'])
overallRate = B * 1.0 / N
return (dicts, regroup, overallRate)
### ChiMerge_MaxInterval: split the continuous variable using Chi-square value by specifying the max number of intervals
def ChiMerge(df, col, target, max_interval=5,special_attribute=[],minBinPcnt=0):
'''
:param df: 包含目标变量与分箱属性的数据框
:param col: 需要分箱的属性
:param target: 目标变量,取值0或1
:param max_interval: 最大分箱数。如果原始属性的取值个数低于该参数,不执行这段函数
:param special_attribute: 不参与分箱的属性取值
:param minBinPcnt:最小箱的占比,默认为0
:return: 分箱结果
'''
colLevels = sorted(list(set(df[col])))
N_distinct = len(colLevels)
if N_distinct <= max_interval: #如果原始属性的取值个数低于max_interval,不执行这段函数
print "The number of original levels for {} is less than or equal to max intervals".format(col)
return colLevels[:-1]
else:
if len(special_attribute)>=1:
df1 = df.loc[df[col].isin(special_attribute)]
df2 = df.loc[~df[col].isin(special_attribute)]
else:
df2 = df.copy()
N_distinct = len(list(set(df2[col])))
# 步骤一: 通过col对数据集进行分组,求出每组的总样本数与坏样本数
if N_distinct > 100:
split_x = SplitData(df2, col, 100)
df2['temp'] = df2[col].map(lambda x: AssignGroup(x, split_x))
else:
df2['temp'] = df[col]
# 总体bad rate将被用来计算expected bad count
(binBadRate, regroup, overallRate) = BinBadRate(df2, 'temp', target, grantRateIndicator=1)
# 首先,每个单独的属性值将被分为单独的一组
# 对属性值进行排序,然后两两组别进行合并
colLevels = sorted(list(set(df2['temp'])))
groupIntervals = [[i] for i in colLevels]
# 步骤二:建立循环,不断合并最优的相邻两个组别,直到:
# 1,最终分裂出来的分箱数<=预设的最大分箱数
# 2,每箱的占比不低于预设值(可选)
# 3,每箱同时包含好坏样本
# 如果有特殊属性,那么最终分裂出来的分箱数=预设的最大分箱数-特殊属性的个数
split_intervals = max_interval - len(special_attribute)
while (len(groupIntervals) > split_intervals): # 终止条件: 当前分箱数=预设的分箱数
# 每次循环时, 计算合并相邻组别后的卡方值。具有最小卡方值的合并方案,是最优方案
chisqList = []
for k in range(len(groupIntervals)-1):
temp_group = groupIntervals[k] + groupIntervals[k+1]
df2b = regroup.loc[regroup['temp'].isin(temp_group)]
chisq = Chi2(df2b, 'total', 'bad', overallRate)
chisqList.append(chisq)
best_comnbined = chisqList.index(min(chisqList))
groupIntervals[best_comnbined] = groupIntervals[best_comnbined] + groupIntervals[best_comnbined+1]
# after combining two intervals, we need to remove one of them
groupIntervals.remove(groupIntervals[best_comnbined])
groupIntervals = [sorted(i) for i in groupIntervals]
cutOffPoints = [max(i) for i in groupIntervals[:-1]]
# 检查是否有箱没有好或者坏样本。如果有,需要跟相邻的箱进行合并,直到每箱同时包含好坏样本
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
(binBadRate,regroup) = BinBadRate(df2, 'temp_Bin', target)
[minBadRate, maxBadRate] = [min(binBadRate.values()),max(binBadRate.values())]
while minBadRate ==0 or maxBadRate == 1:
# 找出全部为好/坏样本的箱
indexForBad01 = regroup[regroup['bad_rate'].isin([0,1])].temp_Bin.tolist()
bin=indexForBad01[0]
# 如果是最后一箱,则需要和上一个箱进行合并,也就意味着分裂点cutOffPoints中的最后一个需要移除
if bin == max(regroup.temp_Bin):
cutOffPoints = cutOffPoints[:-1]
# 如果是第一箱,则需要和下一个箱进行合并,也就意味着分裂点cutOffPoints中的第一个需要移除
elif bin == min(regroup.temp_Bin):
cutOffPoints = cutOffPoints[1:]
# 如果是中间的某一箱,则需要和前后中的一个箱进行合并,依据是较小的卡方值
else:
# 和前一箱进行合并,并且计算卡方值
currentIndex = list(regroup.temp_Bin).index(bin)
prevIndex = list(regroup.temp_Bin)[currentIndex - 1]
df3 = df2.loc[df2['temp_Bin'].isin([prevIndex, bin])]
(binBadRate, df2b) = BinBadRate(df3, 'temp_Bin', target)
chisq1 = Chi2(df2b, 'total', 'bad', overallRate)
# 和后一箱进行合并,并且计算卡方值
laterIndex = list(regroup.temp_Bin)[currentIndex + 1]
df3b = df2.loc[df2['temp_Bin'].isin([laterIndex, bin])]
(binBadRate, df2b) = BinBadRate(df3b, 'temp_Bin', target)
chisq2 = Chi2(df2b, 'total', 'bad', overallRate)
if chisq1 < chisq2:
cutOffPoints.remove(cutOffPoints[currentIndex - 1])
else:
cutOffPoints.remove(cutOffPoints[currentIndex])
# 完成合并之后,需要再次计算新的分箱准则下,每箱是否同时包含好坏样本
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
(binBadRate, regroup) = BinBadRate(df2, 'temp_Bin', target)
[minBadRate, maxBadRate] = [min(binBadRate.values()), max(binBadRate.values())]
# 需要检查分箱后的最小占比
if minBinPcnt > 0:
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
valueCounts = groupedvalues.value_counts().to_frame()
valueCounts['pcnt'] = valueCounts['temp'].apply(lambda x: x * 1.0 / N)
valueCounts = valueCounts.sort_index()
minPcnt = min(valueCounts['pcnt'])
while minPcnt < 0.05 and len(cutOffPoints) > 2:
# 找出占比最小的箱
indexForMinPcnt = valueCounts[valueCounts['pcnt'] == minPcnt].index.tolist()[0]
# 如果占比最小的箱是最后一箱,则需要和上一个箱进行合并,也就意味着分裂点cutOffPoints中的最后一个需要移除
if indexForMinPcnt == max(valueCounts.index):
cutOffPoints = cutOffPoints[:-1]
# 如果占比最小的箱是第一箱,则需要和下一个箱进行合并,也就意味着分裂点cutOffPoints中的第一个需要移除
elif indexForMinPcnt == min(valueCounts.index):
cutOffPoints = cutOffPoints[1:]
# 如果占比最小的箱是中间的某一箱,则需要和前后中的一个箱进行合并,依据是较小的卡方值
else:
# 和前一箱进行合并,并且计算卡方值
currentIndex = list(valueCounts.index).index(indexForMinPcnt)
prevIndex = list(valueCounts.index)[currentIndex - 1]
df3 = df2.loc[df2['temp_Bin'].isin([prevIndex, indexForMinPcnt])]
(binBadRate, df2b) = BinBadRate(df3, 'temp_Bin', target)
chisq1 = Chi2(df2b, 'total', 'bad', overallRate)
# 和后一箱进行合并,并且计算卡方值
laterIndex = list(valueCounts.index)[currentIndex + 1]
df3b = df2.loc[df2['temp_Bin'].isin([laterIndex, indexForMinPcnt])]
(binBadRate, df2b) = BinBadRate(df3b, 'temp_Bin', target)
chisq2 = Chi2(df2b, 'total', 'bad', overallRate)
if chisq1 < chisq2:
cutOffPoints.remove(cutOffPoints[currentIndex - 1])
else:
cutOffPoints.remove(cutOffPoints[currentIndex])
cutOffPoints = special_attribute + cutOffPoints
return cutOffPoints
def UnsupervisedSplitBin(df,var,numOfSplit = 5, method = 'equal freq'):
'''
:param df: 数据集
:param var: 需要分箱的变量。仅限数值型。
:param numOfSplit: 需要分箱个数,默认是5
:param method: 分箱方法,'equal freq':,默认是等频,否则是等距
:return:
'''
if method == 'equal freq':
N = df.shape[0]
n = N / numOfSplit
splitPointIndex = [i * n for i in range(1, numOfSplit)]
rawValues = sorted(list(df[col]))
splitPoint = [rawValues[i] for i in splitPointIndex]
splitPoint = sorted(list(set(splitPoint)))
return splitPoint
else:
var_max, var_min = max(df[var]), min(df[var])
interval_len = (var_max - var_min)*1.0/numOfSplit
splitPoint = [var_min + i*interval_len for i in range(1,numOfSplit)]
return splitPoint
def AssignGroup(x, bin):
N = len(bin)
if x<=min(bin):
return min(bin)
elif x>max(bin):
return 10e10
else:
for i in range(N-1):
if bin[i] < x <= bin[i+1]:
return bin[i+1]
def BadRateEncoding(df, col, target):
'''
:param df: dataframe containing feature and target
:param col: the feature that needs to be encoded with bad rate, usually categorical type
:param target: good/bad indicator
:return: the assigned bad rate to encode the categorical feature
'''
regroup = BinBadRate(df, col, target, grantRateIndicator=0)[1]
br_dict = regroup[[col,'bad_rate']].set_index([col]).to_dict(orient='index')
for k, v in br_dict.items():
br_dict[k] = v['bad_rate']
badRateEnconding = df[col].map(lambda x: br_dict[x])
return {'encoding':badRateEnconding, 'bad_rate':br_dict}
def AssignBin(x, cutOffPoints,special_attribute=[]):
'''
:param x: the value of variable
:param cutOffPoints: the ChiMerge result for continous variable
:param special_attribute: the special attribute which should be assigned separately
:return: bin number, indexing from 0
for example, if cutOffPoints = [10,20,30], if x = 7, return Bin 0. If x = 35, return Bin 3
'''
numBin = len(cutOffPoints) + 1 + len(special_attribute)
if x in special_attribute:
i = special_attribute.index(x)+1
return 'Bin {}'.format(0-i)
if x<=cutOffPoints[0]:
return 'Bin 0'
elif x > cutOffPoints[-1]:
return 'Bin {}'.format(numBin-1)
else:
for i in range(0,numBin-1):
if cutOffPoints[i] < x <= cutOffPoints[i+1]:
return 'Bin {}'.format(i+1)
def MaximumBinPcnt(df,col):
N = df.shape[0]
total = df.groupby([col])[col].count()
pcnt = total*1.0/N
return max(pcnt)
def BinPcnt(df,col):
N = df.shape[0]
total = df.groupby([col])[col].count()
pcnt = total*1.0/N
return {'min':min(pcnt),'max':max(pcnt), 'each pcnt': pcnt.to_dict()}
def MergeByCondition(x,condition_list):
#condition_list是条件列表。满足第几个condition,就输出几
s = 0
for condition in condition_list:
if eval(str(x)+condition):
return s
else:
s+=1
def CalcWOE(df, col, target):
'''
:param df: dataframe containing feature and target
:param col: the feature that needs to be calculated the WOE and iv, usually categorical type
:param target: good/bad indicator
:return: WOE and IV in a dictionary
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(level=0, inplace=True)
N = sum(regroup['total'])
B = sum(regroup['bad'])
regroup['good'] = regroup['total'] - regroup['bad']
G = N - B
regroup['bad_pcnt'] = regroup['bad'].map(lambda x: x*1.0/B)
regroup['good_pcnt'] = regroup['good'].map(lambda x: x * 1.0 / G)
regroup['WOE'] = regroup.apply(lambda x: np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
WOE_dict = regroup[[col,'WOE']].set_index(col).to_dict(orient='index')
for k, v in WOE_dict.items():
WOE_dict[k] = v['WOE']
IV = regroup.apply(lambda x: (x.good_pcnt-x.bad_pcnt)*np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
IV = sum(IV)
return {"WOE": WOE_dict, 'IV':IV}
## determine whether the bad rate is monotone along the sortByVar
def BadRateMonotone(df, sortByVar, target,special_attribute = []):
'''
:param df: the dataset contains the column which should be monotone with the bad rate and bad column
:param sortByVar: the column which should be monotone with the bad rate
:param target: the bad column
:param special_attribute: some attributes should be excluded when checking monotone
:return:
'''
df2 = df.loc[~df[sortByVar].isin(special_attribute)]
if len(set(df2[sortByVar])) <= 2:
return True
regroup = BinBadRate(df2, sortByVar, target)[1]
combined = zip(regroup['total'],regroup['bad'])
badRate = [x[1]*1.0/x[0] for x in combined]
badRateMonotone = [badRate[i]<badRate[i+1] and badRate[i] < badRate[i-1] or badRate[i]>badRate[i+1] and badRate[i] > badRate[i-1]
for i in range(1,len(badRate)-1)]
Monotone = len(set(badRateMonotone))
if Monotone == 1:
return True
else:
return False
### If we find any categories with 0 bad, then we combine these categories with that having smallest non-zero bad rate
def MergeBad0(df,col,target):
'''
:param df: dataframe containing feature and target
:param col: the feature that needs to be calculated the WOE and iv, usually categorical type
:param target: good/bad indicator
:return: WOE and IV in a dictionary
'''
regroup = BinBadRate(df, col, target)[1]
regroup = regroup.sort_values(by = 'bad_rate')
col_regroup = [[i] for i in regroup[col]]
for i in range(regroup.shape[0]-1):
col_regroup[i+1] = col_regroup[i] + col_regroup[i+1]
col_regroup.pop(i)
if regroup['bad_rate'][i+1] > 0:
break
newGroup = {}
for i in range(len(col_regroup)):
for g2 in col_regroup[i]:
newGroup[g2] = 'Bin '+str(i)
return newGroup
### Calculate the KS and AR for the socrecard model
def KS_AR(df, score, target):
'''
:param df: the dataset containing probability and bad indicator
:param score:
:param target:
:return:
'''
total = df.groupby([score])[target].count()
bad = df.groupby([score])[target].sum()
all = pd.DataFrame({'total':total, 'bad':bad})
all['good'] = all['total'] - all['bad']
all[score] = all.index
all = all.sort_values(by=score,ascending=False)
all.index = range(len(all))
all['badCumRate'] = all['bad'].cumsum() / all['bad'].sum()
all['goodCumRate'] = all['good'].cumsum() / all['good'].sum()
all['totalPcnt'] = all['total'] / all['total'].sum()
arList = [0.5 * all.loc[0, 'badCumRate'] * all.loc[0, 'totalPcnt']]
for j in range(1, len(all)):
ar0 = 0.5 * sum(all.loc[j - 1:j, 'badCumRate']) * all.loc[j, 'totalPcnt']
arList.append(ar0)
arIndex = (2 * sum(arList) - 1) / (all['good'].sum() * 1.0 / all['total'].sum())
KS = all.apply(lambda x: x.badCumRate - x.goodCumRate, axis=1)
return {'AR':arIndex, 'KS': max(KS)}
def Predict_LR(x, var_list, coef_dict, prob=False):
'''
:param x: WOE编码后的变量
:param var_list: 入模变量列表
:param coef_dict: 逻辑回归系数列表
:param prob: 如果返回概率,则设定为True。默认是返回log odds
:return: 返回概率或者log odds
'''
s = coef_dict['intercept']
for var in var_list:
s += x[var]*coef_dict[var]
if prob == True:
y = 1.0/(1+np.exp(-s))
return y
else:
return s
数据预处理完整代码如下:
import pandas as pd
import re
import time
import datetime
from dateutil.relativedelta import relativedelta
from sklearn.model_selection import train_test_split
def CareerYear(x):
if x.find('n/a') > -1:
return -1
elif x.find("10+")>-1:
return 11
elif x.find('< 1') > -1:
return 0
else:
return int(re.sub("\D", "", x))
def DescExisting(x):
x2 = str(x)
if x2 == 'nan':
return 'no desc'
else:
return 'desc'
def ConvertDateStr(x,format):
if str(x) == 'nan':
return datetime.datetime.fromtimestamp(time.mktime(time.strptime('9900-1','%Y-%m')))
else:
return datetime.datetime.fromtimestamp(time.mktime(time.strptime(x,format)))
def MonthGap(earlyDate, lateDate):
if lateDate > earlyDate:
gap = relativedelta(lateDate,earlyDate)
yr = gap.years
mth = gap.months
return yr*12+mth
else:
return 0
def MakeupMissing(x):
if np.isnan(x):
return -1
else:
return x
# 数据预处理
# 1,读入数据
# 2,选择合适的建模样本
# 3,数据集划分成训练集和测试集
allData = pd.read_csv('C:/Users/OkO/Desktop/Financial Data Analsys/3nd Series/Data/application.csv',header = 0)
allData['term'] = allData['term'].apply(lambda x: int(x.replace(' months','')))
# 处理标签:Fully Paid是正常用户;Charged Off是违约用户
allData['y'] = allData['loan_status'].map(lambda x: int(x == 'Charged Off'))
'''
由于存在不同的贷款期限(term),申请评分卡模型评估的违约概率必须要在统一的期限中,且不宜太长,所以选取term=36months的行本
'''
allData1 = allData.loc[allData.term == 36]
trainData, testData = train_test_split(allData1,test_size=0.4)
'''
第一步:数据预处理,包括
(1)数据清洗
(2)格式转换
(3)确实值填补
'''
# 将带%的百分比变为浮点数
trainData['int_rate_clean'] = trainData['int_rate'].map(lambda x: float(x.replace('%',''))/100)
# 将工作年限进行转化,否则影响排序
trainData['emp_length_clean'] = trainData['emp_length'].map(CareerYear)
# 将desc的缺失作为一种状态,非缺失作为另一种状态
trainData['desc_clean'] = trainData['desc'].map(DescExisting)
# 处理日期。earliest_cr_line的格式不统一,需要统一格式且转换成python的日期
trainData['app_date_clean'] = trainData['issue_d'].map(lambda x: ConvertDateStr(x,'%b-%y'))
trainData['earliest_cr_line_clean'] = trainData['earliest_cr_line'].map(lambda x: ConvertDateStr(x,'%b-%y'))
# 处理mths_since_last_delinq。注意原始值中有0,所以用-1代替缺失
trainData['mths_since_last_delinq_clean'] = trainData['mths_since_last_delinq'].map(lambda x:MakeupMissing(x))
trainData['mths_since_last_record_clean'] = trainData['mths_since_last_record'].map(lambda x:MakeupMissing(x))
trainData['pub_rec_bankruptcies_clean'] = trainData['pub_rec_bankruptcies'].map(lambda x:MakeupMissing(x))
'''
第二步:变量衍生
'''
# 考虑申请额度与收入的占比
trainData['limit_income'] = trainData.apply(lambda x: x.loan_amnt / x.annual_inc, axis = 1)
# 考虑earliest_cr_line到申请日期的跨度,以月份记
trainData['earliest_cr_to_app'] = trainData.apply(lambda x: MonthGap(x.earliest_cr_line_clean,x.app_date_clean), axis = 1)
'''
第三步:分箱,采用ChiMerge,要求分箱完之后:
(1)不超过5箱
(2)Bad Rate单调
(3)每箱同时包含好坏样本
(4)特殊值如-1,单独成一箱
连续型变量可直接分箱
类别型变量:
(a)当取值较多时,先用bad rate编码,再用连续型分箱的方式进行分箱
(b)当取值较少时:
(b1)如果每种类别同时包含好坏样本,无需分箱
(b2)如果有类别只包含好坏样本的一种,需要合并
'''
num_features = ['int_rate_clean','emp_length_clean','annual_inc', 'dti', 'delinq_2yrs', 'earliest_cr_to_app','inq_last_6mths', \
'mths_since_last_record_clean', 'mths_since_last_delinq_clean','open_acc','pub_rec','total_acc']
cat_features = ['home_ownership', 'verification_status','desc_clean', 'purpose', 'zip_code','addr_state','pub_rec_bankruptcies_clean']
more_value_features = []
less_value_features = []
# 第一步,检查类别型变量中,哪些变量取值超过5
for var in cat_features:
valueCounts = len(set(trainData[var]))
print valueCounts
if valueCounts > 5:
more_value_features.append(var)
else:
less_value_features.append(var)
# (i)当取值<5时:如果每种类别同时包含好坏样本,无需分箱;如果有类别只包含好坏样本的一种,需要合并
merge_bin = {}
for col in less_value_features:
binBadRate = BinBadRate(trainData, col, 'y')[0]
if min(binBadRate.values()) == 0 or max(binBadRate.values()) == 1:
print '{} need to be combined'.format(col)
combine_bin = MergeBad0(trainData, col, 'y')
merge_bin[col] = combine_bin
# (ii)当取值>5时:用bad rate进行编码,放入连续型变量里
br_encoding_dict = {}
for col in more_value_features:
br_encoding = BadRateEncoding(df, col, target)
trainData[col+'_br_encoding'] = br_encoding['encoding']
br_encoding_dict[col] = br_encoding['bad_rate']
num_features.append(col+'_br_encoding')
# (iii)对连续型变量进行分箱,包括(ii)中的变量
for col in num_features:
print "{} is in processing".format(col)
if -1 not in set(trainData[col]):
max_interval = 5
cutOff = ChiMerge(trainData, col, target, max_interval=max_interval,special_attribute=[],minBinPcnt=0)
trainData[col+'_Bin'] = trainData[col].map(lambda x: AssignBin(x, cutOff,special_attribute=[]))
monotone = BadRateMonotone(trainData, col+'_Bin', 'y')
while(not monotone):
max_interval -= 1
cutOff = ChiMerge(trainData, col, target, max_interval=max_interval, special_attribute=[],
minBinPcnt=0)
trainData[col + '_Bin'] = trainData[col].map(lambda x: AssignBin(x, cutOff, special_attribute=[]))
if max_interval == 2:
# 当分箱数为2时,必然单调
break
monotone = BadRateMonotone(trainData, col + '_Bin', 'y')
else:
max_interval = 5
cutOff = ChiMerge(trainData, col, target, max_interval=max_interval, special_attribute=[-1],
minBinPcnt=0)
trainData[col + '_Bin'] = trainData[col].map(lambda x: AssignBin(x, cutOff, special_attribute=[-1]))
monotone = BadRateMonotone(trainData, col + '_Bin', 'y')
while (not monotone):
max_interval -= 1
cutOff = ChiMerge(trainData, col, target, max_interval=max_interval, special_attribute=[-1],
minBinPcnt=0)
trainData[col + '_Bin'] = trainData[col].map(lambda x: AssignBin(x, cutOff, special_attribute=[-1]))
if max_interval == 2:
# 当分箱数为2时,必然单调
break
monotone = BadRateMonotone(trainData, col + '_Bin', 'y')
具体代码解析,请参照下面链接:https://blog.csdn.net/qq_42642945/article/details/88688049
版权声明:
笔者博客文章主要用来作为学习笔记使用,内容大部分来自于自互联网,并加以归档整理或修改,以方便学习查询使用,只有少许原创,如有侵权,请联系博主删除!